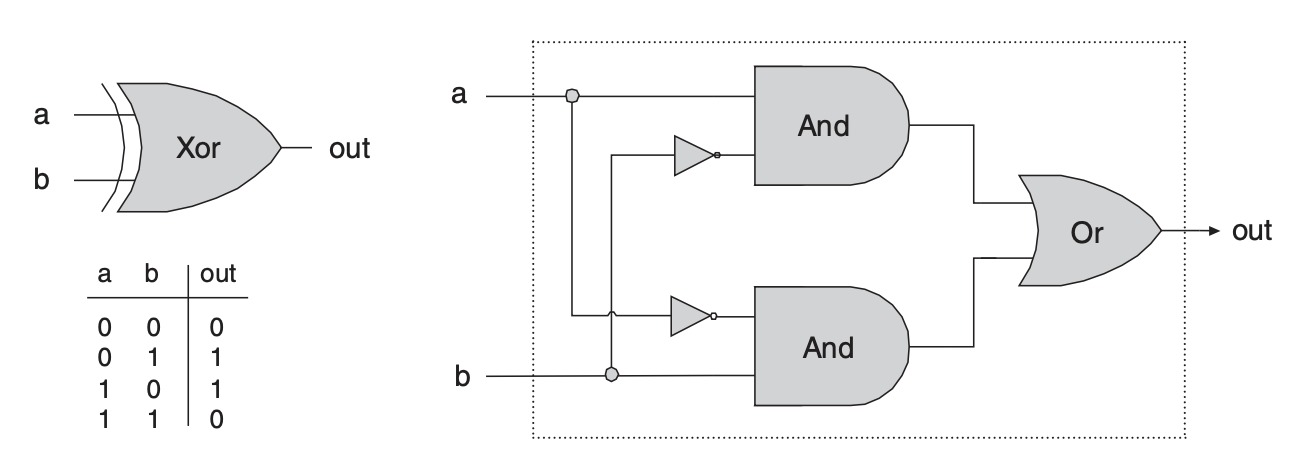
출처: https://roseline.oopy.io/dev/logic-gate-xor
0. 개요
python을 활용하여 XOR gate를 구현하는 내용임.
- '24. 2. 13. loss 시각화 추가
1. 전체 코드
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(a):
return 1 / (1 + np.exp(-a))
class Logit_gate():
def __init__(self, learning_rate = 1e-1, activation = 'sigmoid', loss = 'MSE', opt = 'gradient', epochs = 1000) -> None:
def weight_init():
W = np.random.randn(2, 1)
b = np.random.randn(1)
return W, b
self.W, self.b = weight_init()
self.lr = learning_rate
self.act_f = activation
self.loss_f = loss
self.opt = opt
self.epochs = epochs
def forpass(self, x):
return self.activation_funtion(self.linear_combination(x))
def backprop(self, x, err):
m = len(x)
w_grad = np.dot(x.T, err) / m
b_grad = np.sum(err) / m
return w_grad, b_grad
def linear_combination(self, X):
a = np.dot(X, self.W) + self.b
return a
def activation_funtion(self, a): # sigmoid
if self.act_f == 'sigmoid':
return sigmoid(a)
def loss_funtion(self, x, y): # MSE
if self.loss_f == 'MSE':
return 0.5 * np.mean(np.sum((y - self.forpass(x))**2))
def optimization(self, x, y): # gradient descent
if self.opt == 'gradient':
loss_history = []
for i in range(self.epochs):
loss = self.loss_funtion(x, y)
loss_history.append(loss)
if i%100==0:
print(f"epoch: {i} Loss: {loss:.8f}")
err = -(y - self.forpass(x))
w_gard, b_gard = self.backprop(x, err)
self.W -= w_gard * self.lr
self.b -= b_gard * self.lr
plt.title('Loss history')
plt.plot(list(range(len(loss_history))),loss_history)
def fit(self, X, y):
self.optimization(X, y)
def prediction(self, X):
return self.activation_funtion(np.dot(X, self.W) + self.b)1-a. OR/NOR gate
OR
OR = Logit_gate()
x_or = np.array([[0,0], [0,1], [1,0], [1,1]])
y_or = np.array([[0], [1], [1], [1]])
OR.fit(x_or, y_or)
OR.prediction(x_or)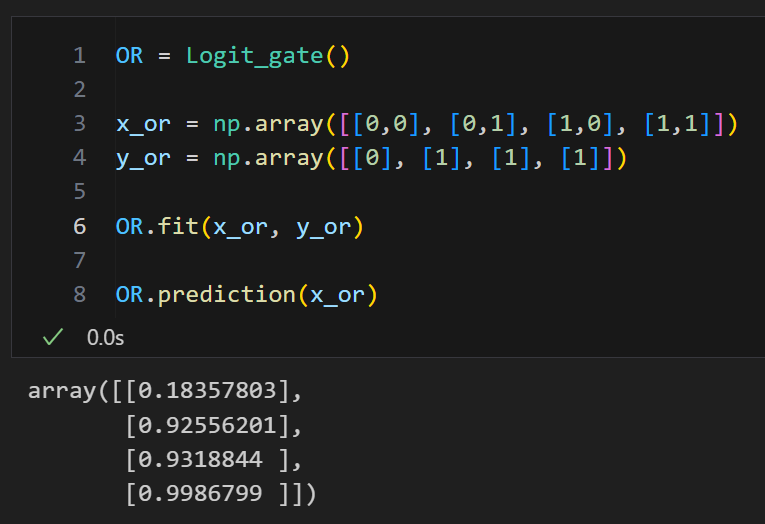
NOR
NOR = Logit_gate()
x_nor = np.array([[0,0], [0,1], [1,0], [1,1]])
y_nor = np.array([[1], [0], [0], [0]])
NOR.fit(x_nor, y_nor)
NOR.prediction(x_nor)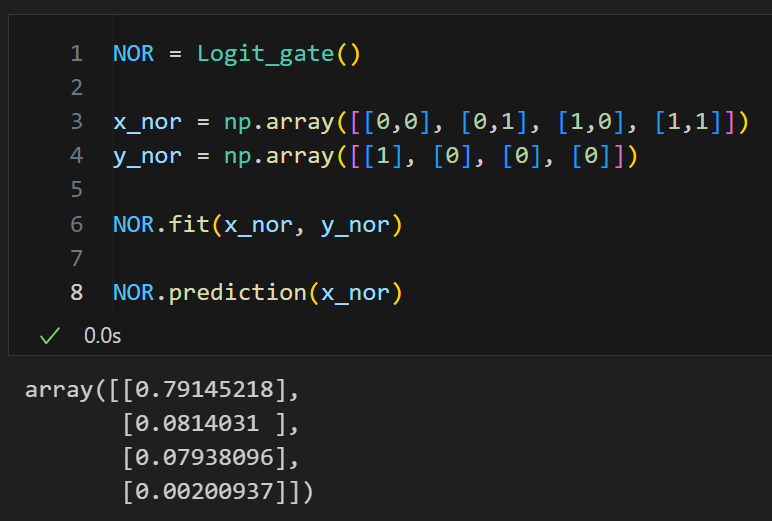
1-b. AND/NAND gate
AND
AND = Logit_gate()
x_and = np.array([[0,0], [0,1], [1,0], [1,1]])
y_and = np.array([[0], [0], [0], [1]])
AND.fit(x_and, y_and)
AND.prediction(x_and)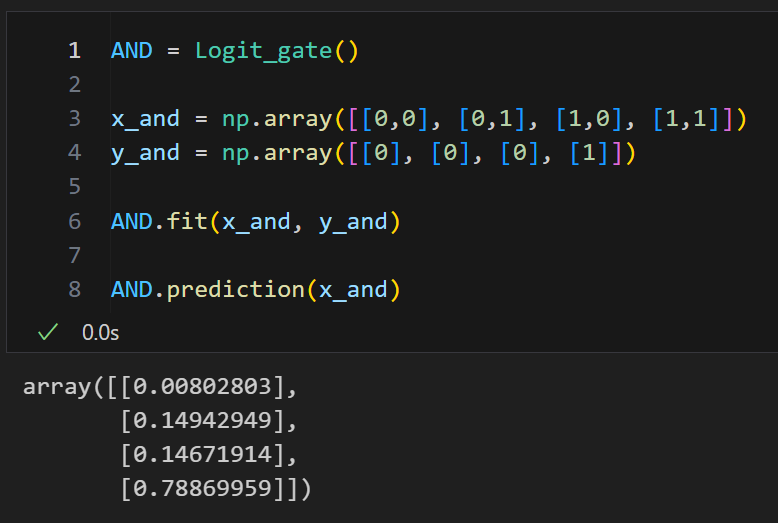
NAND
NAND = Logit_gate()
x_nand = np.array([[0,0], [0,1], [1,0], [1,1]])
y_nand = np.array([[1], [1], [1], [0]])
NAND.fit(x_nand, y_nand)
NAND.prediction(x_nand)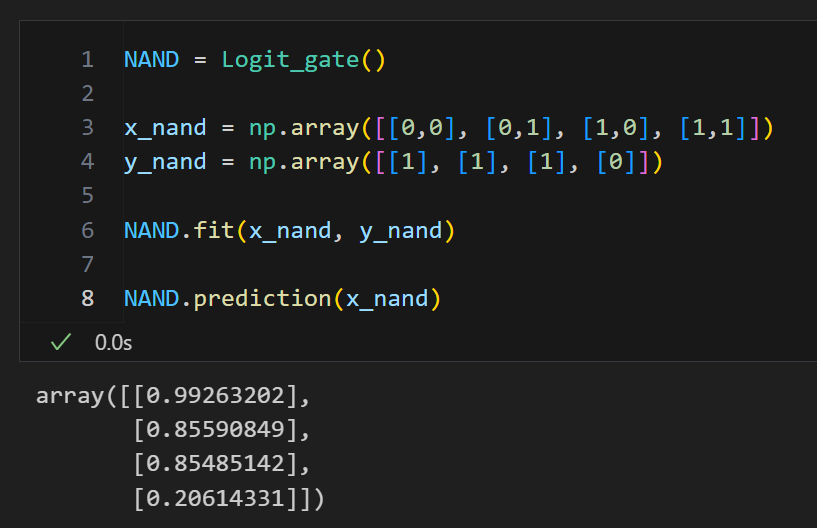
1-c. XOR gate
XOR
# XOR gate
x = np.array([[0,0], [0,1], [1,0], [1,1]])
x_by_nand = NAND.prediction(x)
x_by_or = OR.prediction(x)
x_xor = np.array([x_by_nand, x_by_or]).T.reshape(-1, 2)
AND.prediction(x_xor)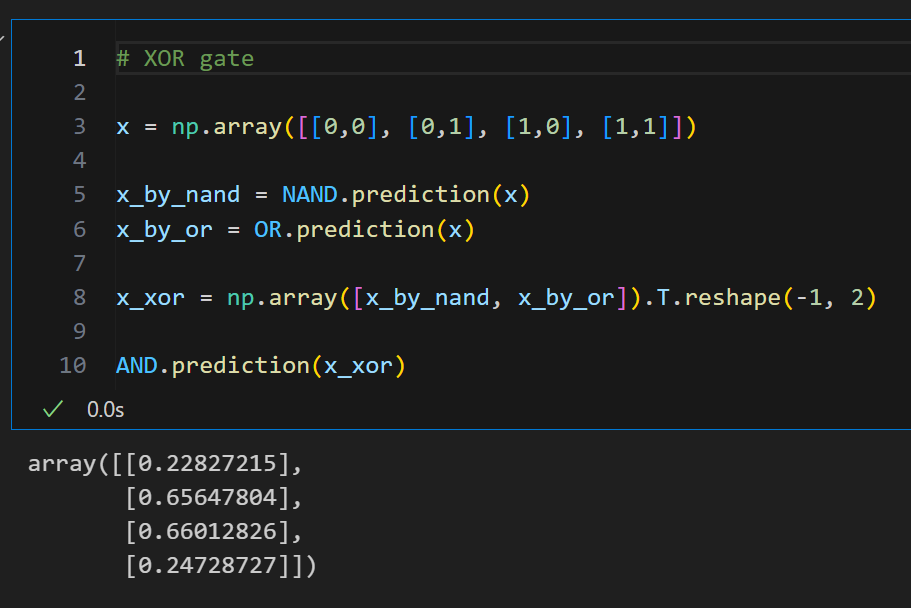
참고

어디로 가야하오