
기본
| 비교 | mul(요소별 곱) | matmul(행렬 곱) |
|---|---|---|
| In-place연산 | 가능 | 가능 |
| 브로드캐스팅 | 가능 | 가능 |
| 연산자 오버로딩 | * | @ |
- 단,
matmul의 브로드캐스팅은 배치 행렬의 곱셈에서만 적용됨.
ex) A.shape = 1x4x2
B.shape = 3x2x4
A @ B의 경우 A의 batch가 브로드캐스팅 되어 3x4x2로 연산이 진행됨.
연산 결과의 차원
mul
1. tensor * tensor
tensor1 = torch.tensor([1, 2, 3]) # (3, )
tensor2 = torch.tensor([4, 5, 6]) # (3, )
tensor1 * tensor2
>> tensor([4, 10, 18]) # (3, )shape 동일한 두 Tensor의 mul 연산 결과의 차원은
input data shape과 동일함.
2. tensor * R
tensor1 = torch.tensor([1, 2, 3]) # (3, )
tensor1 * 1.4
>> tensor([1.4000, 2.8000, 4.2000]) # (3, )Tensor * real_number 간의 연산 결과 또한
input data의 tensor shape과 동일함.
matmul
1. tensor @ tensor
tensor1 = torch.arange(10).view(2, 5)
tensor2 = torch.arange(10, 20).view(5,2)
tensor1 @ tensor2
>> tensor([[160, 170],
[510, 545]])tensor1 shape = (n, m)
tensor2 shape = (m, k) 일때
결과 tensor의 shape은(n x k)
단, tensor1의 열과 tensor2의 행의 크기가 일치해야 함.
2. batch_tensor @ batch_tensor
batch1 = torch.randn(10, 3, 4) # 10개의 3x4 행렬
batch2 = torch.randn(10, 4, 5) # 10개의 4x5 행렬
torch.matmul(batch1, batch2) # 결과는 10개의 3x5 행렬matmul 메소드의 경우도 브로드캐스팅이 가능한데
위 예시와 같은 batch_matrix 간의 연산에서만 적용된다.
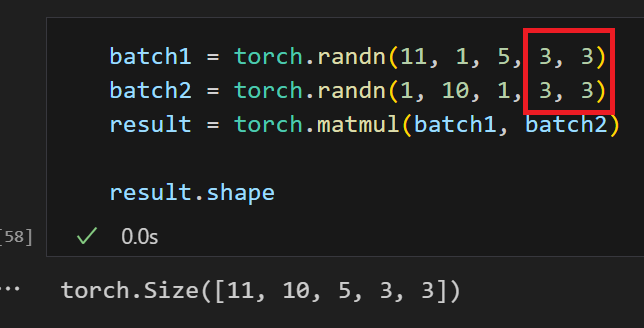
- 빨간색 박스의 차원들이 행렬곱이 가능해야함
( (n x m) @ (m x k) )- 그 외 차원은 크기가 (1 x m)이여야지 브로드캐스팅이 가능
(3 x m 불가능. 브로드 캐스팅이 진행되는 차원은 반드시 크기가 1.)- n-d array @ (n-1)-d array 일 경우 또한 자동으로 브로드캐스팅 적용.
결론
matmul: 행렬 곱mul: 요소별 곱

어디로 가야하오