
📌 Summary
-
쿠버네티스 Service와 EndPointSlice에 대해 이해할 수 있습니다.
-
Endpoint와 EndPointSlice의 관계를 확인합니다.
-
readiness probe에 대한 헬스체크 실패시, 트래픽이 서비스에서 어떻게 전달되는지 확인할 수 있습니다.
📌 EndpointSlice
Endpoint의 동작원리를 알아보고자 한 것이 이 글을 포스팅하게된 주요한 이유였습니다.
이때까지만 해도,
→ 헬스체크가 실패한다.
→ 엔드포인트에서 실패한 파드의 ip가 제거된다.
→ 서비스에서 파드로 트래픽을 전달하지 않게 된다.
로만 알고 있었던 동작에서 EndpointSlice라는 개념을 새로 알게 되었습니다.
아래는 쿠버네티스 문서의 일부분 입니다.

Docs
기존 Endpoints와 비교했을 때, EndpointSlices는 네트워크 성능과 확장성을 크게 개선합니다.Endpoints는 단일 리소스로 모든 엔드포인트를 관리했지만, 이는 대규모 클러스터에서 성능 문제를 유발할 수 있었습니다.
EndpointSlices는 이를 여러 작은 조각으로 나누어 관리함으로써 확장성과 성능을 향상시킵니다.
🔥 In Kubernetes
1.19this feature is enabled by default with kube-proxy reading from EndpointSlices instead of Endpoints.
👉 주요 기능
-
확장성 향상:
-
Endpoints:
모든 엔드포인트가 하나의 리소스에 포함되어 있어 대규모 클러스터에서 성능 저하 발생. -
EndpointSlices:
엔드포인트를 여러 작은 조각으로 나누어 관리하여 확장성과 성능 향상.
-
-
자동화:
- 동작 원리:
클러스터에서 엔드포인트가 추가되거나 제거될 때 자동으로 EndpointSlice가 생성, 업데이트, 삭제됩니다. 이는 kube-proxy와 같은 네트워킹 컴포넌트가 최신 엔드포인트 정보를 효율적으로 가져올 수 있게 합니다.
- 동작 원리:
-
네트워크 토폴로지 및 IPv6 지원:
-
네트워크 토폴로지:
EndpointSlice는 노드와의 물리적 또는 논리적 위치를 기반으로 트래픽을 분배할 수 있습니다. 이를 통해 네트워크 지연 시간과 대역폭 사용을 최적화할 수 있습니다. -
IPv6 지원:
IPv4와 IPv6 주소를 모두 지원하여 이중 스택 클러스터 환경에서 유연성을 제공합니다.
-
👉 동작 원리
엔드포인트와 엔드포인트 슬라이스의 관계는 뭘까??? 로 시작되어 상호 보완적으로 동작하고 있는줄 알았습니다.
엔드포인트 슬라이스의 상태가 변경되면 엔드포인트의 내용이 바뀌는 건가??와 같이 서로 연계되어 서비스 구성을 맡게 되는것으로 알고 있었는데, 동작 원리가 어떻게 되는지 소스코드를 확인하였습니다.
그 과정에서 재미있는 내용을 확인할 수 있었습니다.
Endpoint는 less preferred 상태
Endpoint와EndpointSlice는 비슷한 목적을 가지고 있지만, 완벽하게 별개의 리소스로서 동작하고 있습니다.
deprecate가 아닌less preferred라고 정의한 이유는, 아직까지도Endpoint컨트롤러 및 기능은 여전히 동작하고 있습니다.다만, 소스코드의 상당 부분이
Endpoint를 사용하는것에서EndpointSlice를 사용하는 구조로 마이그레이션 됨을 확인할 수 있었습니다.특히 v1.27부터는
pkg/proxy/config/config.go항목에서EndpointsHandler사라진 것을 확인할 수 있습니다.
이를 소스코드 레벨에서 가볍게 다루어 보도록 하겠습니다.
📕 1. Controller 확인
Endpoint와 엔드포인트슬라이스는 여전히 각각의 컨트롤러를 통해 관리되고 있습니다.
- pkg/controller/endpoint/endpoints_controller.go
- pkg/controller/endpointslice/endpointslice_controller.go
해당 소스코드의
syncService에서 아래와 같은 동작을 확인할 수 있습니다.// pkg/controller/endpointslice/endpointslice_controller.go func (c *Controller) syncService(logger klog.Logger, key string) error { ... }서비스가 생성되는 경우,
ExternalName및셀렉터가 존재하지 않는 경우를 제외하면 항상 Endpoint와 엔드포인트슬라이스가 동기화되어 리소스가 생성됩니다.... if service.Spec.Type == v1.ServiceTypeExternalName { return nil } if service.Spec.Selector == nil { return nil } ... }서비스에서 선언된 Selector의 파드 라벨을 이용해서, 동일한 라벨을 가진 파드의 IP를 리스트업 합니다.
... podLabelSelector := labels.Set(service.Spec.Selector).AsSelectorPreValidated() pods, err := c.podLister.Pods(service.Namespace).List(podLabelSelector) if err != nil { // Since we're getting stuff from a local cache, it is basically // impossible to get this error. c.eventRecorder.Eventf(service, v1.EventTypeWarning, "FailedToListPods", "Error listing Pods for Service %s/%s: %v", service.Namespace, service.Name, err) return err } ...그 이후 서비스, 파드, 기존 엔드포인트 슬라이스 정보를 사용하여 조정 작업을 수행합니다.
err = c.reconciler.Reconcile(logger, service, pods, endpointSlices, lastChangeTriggerTime) if err != nil { c.eventRecorder.Eventf(service, v1.EventTypeWarning, "FailedToUpdateEndpointSlices", "Error updating Endpoint Slices for Service %s/%s: %v", service.Namespace, service.Name, err) return err }
📘 2. Proxy 설정
kubernetes/pkg/proxy/config/config.go
kube-proxy가 Endpoints를 감시하는지 EndpointSlices를 감시하는지 확인하기 위해서 kube-proxy의 소스 코드를 살펴보았습니다.
내부를 살표보면, EndpointSlice 객체를 이용해서 로직을 처리하는 구조임을 확인할 수 있습니다.
type EndpointSliceConfig struct {
listerSynced cache.InformerSynced
eventHandlers []EndpointSliceHandler
logger klog.Logger
}
func NewEndpointSliceConfig(ctx context.Context, endpointSliceInformer discoveryv1informers.EndpointSliceInformer, resyncPeriod time.Duration) *EndpointSliceConfig {
// ...
}
func (c *EndpointSliceConfig) RegisterEventHandler(handler EndpointSliceHandler) {
// ...
}
func (c *EndpointSliceConfig) Run(stopCh <-chan struct{}) {
// ...
}v1.27부터는 pkg/proxy/config/config.go 항목에서 EndpointsHandler 사라진 것을 확인할 수 있습니다.
📗 3. Endpoint 업데이트
EndpointsMap이 정의되어 있습니다.
이는 ServicePortName을 키로 하고, Endpoint 슬라이스를 값으로 가지는 맵입니다.// EndpointsMap maps a service name to a list of all its Endpoints. type EndpointsMap map[ServicePortName][]Endpoint
EndpointsMap을 통해 엔드포인트가 업데이트 될때, checkoutChanges 함수를 호출하게 됩니다.
func (em EndpointsMap) Update(ect *EndpointChangeTracker) UpdateResult { // ... changes := ect.checkoutChanges() for _, change := range changes { em.unmerge(change.previous) em.merge(change.current) } // ... }
내용을 살펴보면 EndpointSlice에서 가져온 정보로 채워지고 있는것을 확인할 수 있습니다.
func NewEndpointsChangeTracker(hostname string, makeEndpointInfo makeEndpointFunc, ipFamily v1.IPFamily, recorder events.EventRecorder, processEndpointsMapChange processEndpointsMapChangeFunc) *EndpointsChangeTracker { return &EndpointsChangeTracker{ lastChangeTriggerTimes: make(map[types.NamespacedName][]time.Time), trackerStartTime: time.Now(), processEndpointsMapChange: processEndpointsMapChange, endpointSliceCache: NewEndpointSliceCache(hostname, ipFamily, recorder, makeEndpointInfo), } }
updatePending 함수는 EndpointSlice의 변경사항을 추적합니다.
// pkg/proxy/endpointslicecache.go func (cache *EndpointSliceCache) updatePending(endpointSlice *discovery.EndpointSlice, remove bool) bool { // ... esInfo := cache.getOrCreateEndpointSliceInfo(endpointSlice) if remove { esInfo.pending = &endpointSliceInfo{} } else { esInfo.pending = generateEndpointSliceInfo(endpointSlice, cache.hostname, cache.isLocal) } // ... }
generateEndpointSliceInfo 함수는 EndpointSlice의 각 엔드포인트를 처리합니다.
func generateEndpointSliceInfo(endpointSlice *discovery.EndpointSlice, hostname string, isLocal func(*discovery.EndpointSlice, string) bool) *endpointSliceInfo { esInfo := &endpointSliceInfo{} // ... for _, endpoint := range endpointSlice.Endpoints { if !endpointReady(endpoint) { continue } // ... epInfo := &BaseEndpointInfo{ Endpoint: net.JoinHostPort(ipStr, strconv.Itoa(int(port))), IsLocal: isLocal(endpointSlice, hostname), Ready: true, Serving: true, Terminating: false, } esInfo.endpoints = append(esInfo.endpoints, epInfo) } return esInfo }
endpointReady 함수는 엔드포인트의 Ready 상태를 확인합니다.
func endpointReady(endpoint discovery.Endpoint) bool { return endpoint.Conditions.Ready == nil || *endpoint.Conditions.Ready }엔드포인트의 condition (Ready, Serving, Terminating)은 BaseEndpointInfo 구조체에 저장됩니다.
최종적으로, 이 정보는 Proxier의
syncProxyRules메서드에서 사용됩니다:// pkg/proxy/iptables/proxier.go func (proxier *Proxier) syncProxyRules() { // ... for svcName, svc := range proxier.svcPortMap { // ... for _, ep := range allLocallyReachableEndpoints { epInfo := ep.(*endpointInfo) if epInfo.Ready() { // Ready 상태의 엔드포인트에 대한 iptables 규칙 생성 } } } // ... }
📌 Healthcheck Fail 시나리오
with Readiness Probe
더 나아가, Readiness Probe 헬스체크가 실패하는 경우 엔드포인트 또는 엔드포인트 슬라이스가 어떻게 동작하게 되는지 확인해보겠습니다.
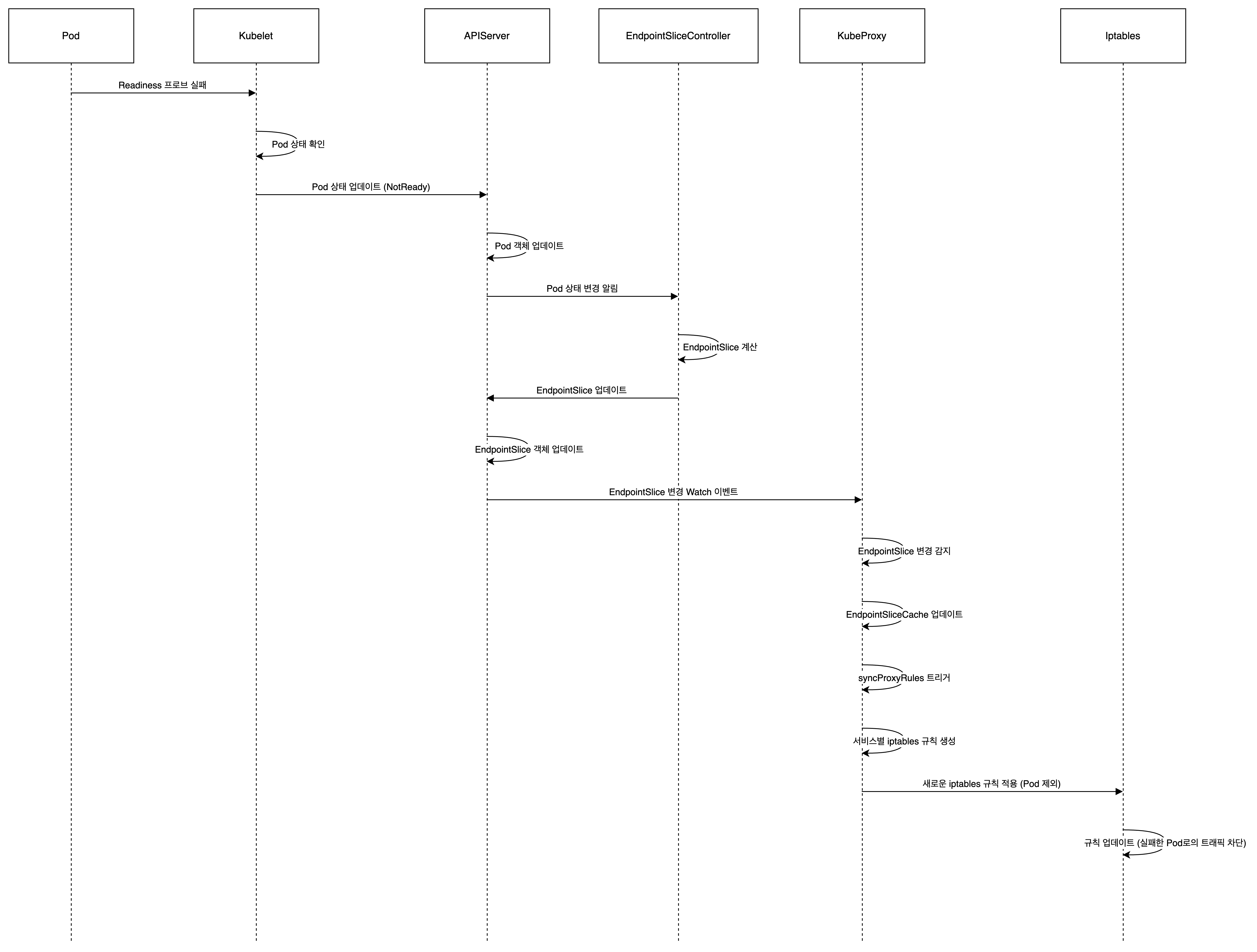
👉 동작 원리
Readiness Probe 헬스체크 실패 시 트래픽이 서비스에 전달되지 않게 되는 동작 흐름을 요약하면 다음과 같습니다:
-
Readiness Probe 실패:
-
kubelet이 파드의 레디니스 프로브를 실행하고 실패를 감지합니다.
-
kubelet은 파드의 상태를 업데이트하여 Ready 조건을 false로 설정합니다.
-
-
EndpointSlice 업데이트:
-
EndpointSlice 컨트롤러가 파드 상태 변경을 감지합니다.
-
컨트롤러는 해당 서비스의 EndpointSlice를 업데이트합니다:
conditions: ready: false serving: false terminating: false
-
-
kube-proxy 감지:
-
kube-proxy의 EndpointsChangeTracker가 EndpointSlice 변경을 감지합니다.
-
EndpointSliceUpdate메서드가 호출되어 변경사항을 처리합니다.
-
-
엔드포인트 정보 업데이트:
-
EndpointSliceCache가 새로운 EndpointSlice 정보로 업데이트됩니다.
-
newEndpointSliceEndpoint함수가 새 엔드포인트 객체를 생성합니다:&endpointSliceEndpoint{ isReady: false, isServing: false, isTerminating: false, }
-
-
프록시 규칙 동기화:
-
kube-proxy의 주기적인 동기화 또는 변경 감지로
syncProxyRules메서드가 호출됩니다. -
EndpointsMap.Update메서드가 호출되어 최신 엔드포인트 정보를 반영합니다.
-
-
트래픽 규칙 적용:
- iptables 모드를 예로 들면:
if ep.IsReady() { // 트래픽 전달 규칙 생성 } else { // 트래픽 전달 규칙 제거 또는 생성하지 않음 } IsReady()가 false를 반환하므로, 이 엔드포인트로의 트래픽 전달 규칙이 제거되거됩니다. 만약 존재하지 않는다면 추가로 생성되지 않습니다.
- iptables 모드를 예로 들면:
-
iptables 규칙 업데이트:
-
생성된 iptables 규칙이 노드의 iptables에 적용됩니다.
-
Readiness Probe 체크에 실패한 엔드포인트로의 트래픽 전달 규칙이 제거됩니다.
-
-
트래픽 처리:
-
클라이언트의 요청이 서비스 IP로 들어옵니다.
-
iptables 규칙에 따라 트래픽이 처리됩니다.
-
레디니스 체크에 실패한 엔드포인트로는 트래픽이 전달되지 않습니다.
-
이 과정을 통해, Readiness 헬스체크에 실패한 파드는 서비스의 로드밸런싱에서 제외되어 트래픽을 받지 않게 됩니다. 이러한 동작을 통해서 서비스의 안정성을 유지하고, 문제가 있는 파드로 트래픽이 전달되는 것을 방지합니다.
🔥 실습
이 Deployment를 사용하여 readiness 헬스체크 실패 시 엔드포인트가 변경되는 과정을 확인할 수 있습니다.
1. Deployment 생성:
제공된 YAML을 사용하여 Deployment를 생성합니다.cat <<EOF | kubectl create -f - apiVersion: apps/v1 kind: Deployment metadata: name: readiness-deployment namespace: default spec: replicas: 3 selector: matchLabels: app: readiness-deployment template: metadata: labels: app: readiness-deployment spec: containers: - name: readiness-deployment image: alpine command: ["sh", "-c", "touch /tmp/healthy && sleep 86400"] readinessProbe: exec: command: - cat - /tmp/healthy initialDelaySeconds: 5 periodSeconds: 3 EOF
2. Pod 및 endpoints, endpointslice 확인:
3개의 Pod가 실행 중이고, 엔드포인트에 3개의 IP가 있는지 확인합니다.
kubectl get pods,endpoints,endpointslice
3. 서비스 생성 (아직 없는 경우):
kubectl expose deployment readiness-deployment --port=80 --target-port=8080
4. 특정 Pod 선택:
출력된 Pod 목록에서 하나를 선택합니다.kubectl get pods
5. 선택한 Pod의 readiness 프로브 실패 유도:
kubectl exec <pod-name> -- rm /tmp/healthy
6. 엔드포인트 변화 관찰:
선택한 Pod의 IP가 엔드포인트에서 제거되는 것을 확인합니다.kubectl get endpoints -w
7. Pod 상태 확인:
선택한 Pod의 READY 상태가 0/1로 변경되었는지 확인합니다.kubectl get pods
8. Readiness 프로브 복구:
kubectl exec <pod-name> -- touch /tmp/healthy
9. 엔드포인트 및 Pod 상태 재확인:
엔드포인트에 Pod의 IP가 다시 추가되고, Pod의 READY 상태가 1/1로 돌아오는지 확인합니다.
이 과정을 통해 readiness 프로브 실패 시 해당 Pod가 서비스 엔드포인트에서 제거되고, 복구 시 다시 추가되는 것을 관찰할 수 있습니다.
Endpoints, Endpointslice 상태 확인
10.244.0.8의 IP가 엔드포인트에서 삭제된것을 확인할 수 있습니다.
실습환경은 minikube 사용하였기에, zone과 같은 정보는 출력되지 않습니다.
kubectl get endpoints,endpointslices NAME ADDRESSTYPE PORTS ENDPOINTS AGE endpointslice.discovery.k8s.io/kubernetes IPv4 8443 192.168.49.2 49m endpointslice.discovery.k8s.io/readiness-deployment-wscv5 IPv4 8080 **10.244.0.8,10.244.0.6,10.244.0.7** 4m30s NAME ENDPOINTS AGE endpoints/kubernetes 192.168.49.2:8443 49m endpoints/readiness-deployment 10.244.0.6:8080,10.244.0.7:8080 4m30s
Endpointslice 상세 확인
endpointslice의 상세내용을 확인하면 다음과 같습니다.
헬스체크에 실패하면 ready, serving의 파라미터가 false로 변경된것을 확인할 수 있습니다.
kubectl get endpointslices readiness-deployment-wscv5 -o yaml# endpointslice addressType: IPv4 apiVersion: discovery.k8s.io/v1 endpoints: - addresses: - 10.244.0.8 conditions: ready: false serving: false terminating: false nodeName: minikube targetRef: kind: Pod name: readiness-deployment-b5d4f7c47-jl97z namespace: default uid: 44ed2e51-961b-49f8-a1b5-3e3206a6c319 - addresses: - 10.244.0.6 conditions: ready: true serving: true terminating: false nodeName: minikube targetRef: kind: Pod name: readiness-deployment-b5d4f7c47-qftwz namespace: default uid: dff7ff87-8ad2-4c00-92b0-2e582a0a7774 - addresses: - 10.244.0.7 conditions: ready: true serving: true terminating: false nodeName: minikube targetRef: kind: Pod name: readiness-deployment-b5d4f7c47-mbcjg namespace: default uid: b1bb45db-f7b5-4f9b-aed7-9ea14ea77b37 kind: EndpointSlice metadata: annotations: endpoints.kubernetes.io/last-change-trigger-time: "2024-07-03T07:59:22Z" creationTimestamp: "2024-07-03T07:58:40Z" generateName: readiness-deployment- generation: 2 labels: endpointslice.kubernetes.io/managed-by: endpointslice-controller.k8s.io kubernetes.io/service-name: readiness-deployment name: readiness-deployment-wscv5 namespace: default ownerReferences: - apiVersion: v1 blockOwnerDeletion: true controller: true kind: Service name: readiness-deployment uid: c1ab2482-7004-467c-9910-d2c33b82a187 resourceVersion: "2687" uid: 9f4b8a92-27aa-41fc-a3b3-f1b7253c5206 ports: - name: "" port: 8080 protocol: TCP
✅ Appendix
iptable 확인
최종적으로 노드의 iptable을 확인하면, 헬스체크에 실패하는 경우 iptable에서 해당되는 파드의 ip에 대한 정보가 사라지는 것을 확인할 수 있습니다.
명령어 -
iptables-save# 헬스체크 정상인경우 (3/3) root@ep-test-control-plane:/# iptables-save | grep readiness --- -A KUBE-SEP-2XOKBYZGBN65M2V3 -s 10.244.0.5/32 -m comment --comment "default/readiness-deployment" -j KUBE-MARK-MASQ -A KUBE-SEP-2XOKBYZGBN65M2V3 -p tcp -m comment --comment "default/readiness-deployment" -m tcp -j DNAT --to-destination 10.244.0.5:8080 -A KUBE-SEP-A4EQCJTEE766DQAW -s 10.244.0.7/32 -m comment --comment "default/readiness-deployment" -j KUBE-MARK-MASQ -A KUBE-SEP-A4EQCJTEE766DQAW -p tcp -m comment --comment "default/readiness-deployment" -m tcp -j DNAT --to-destination 10.244.0.7:8080 -A KUBE-SEP-FBLUIRQWGV5XZRNC -s 10.244.0.6/32 -m comment --comment "default/readiness-deployment" -j KUBE-MARK-MASQ -A KUBE-SEP-FBLUIRQWGV5XZRNC -p tcp -m comment --comment "default/readiness-deployment" -m tcp -j DNAT --to-destination 10.244.0.6:8080 -A KUBE-SERVICES -d 10.96.176.157/32 -p tcp -m comment --comment "default/readiness-deployment cluster IP" -m tcp --dport 80 -j KUBE-SVC-IKYJPMLCKWKD4GAR -A KUBE-SVC-IKYJPMLCKWKD4GAR ! -s 10.244.0.0/16 -d 10.96.176.157/32 -p tcp -m comment --comment "default/readiness-deployment cluster IP" -m tcp --dport 80 -j KUBE-MARK-MASQ -A KUBE-SVC-IKYJPMLCKWKD4GAR -m comment --comment "default/readiness-deployment -> 10.244.0.5:8080" -m statistic --mode random --probability 0.33333333349 -j KUBE-SEP-2XOKBYZGBN65M2V3 -A KUBE-SVC-IKYJPMLCKWKD4GAR -m comment --comment "default/readiness-deployment -> 10.244.0.6:8080" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-FBLUIRQWGV5XZRNC -A KUBE-SVC-IKYJPMLCKWKD4GAR -m comment --comment "default/readiness-deployment -> 10.244.0.7:8080" -j KUBE-SEP-A4EQCJTEE766DQAW# 1개의 파드가 헬스체크에 실패한 경우 root@ep-test-control-plane:/# iptables-save | grep readiness --- -A KUBE-SEP-A4EQCJTEE766DQAW -s 10.244.0.7/32 -m comment --comment "default/readiness-deployment" -j KUBE-MARK-MASQ -A KUBE-SEP-A4EQCJTEE766DQAW -p tcp -m comment --comment "default/readiness-deployment" -m tcp -j DNAT --to-destination 10.244.0.7:8080 -A KUBE-SEP-FBLUIRQWGV5XZRNC -s 10.244.0.6/32 -m comment --comment "default/readiness-deployment" -j KUBE-MARK-MASQ -A KUBE-SEP-FBLUIRQWGV5XZRNC -p tcp -m comment --comment "default/readiness-deployment" -m tcp -j DNAT --to-destination 10.244.0.6:8080 -A KUBE-SERVICES -d 10.96.176.157/32 -p tcp -m comment --comment "default/readiness-deployment cluster IP" -m tcp --dport 80 -j KUBE-SVC-IKYJPMLCKWKD4GAR -A KUBE-SVC-IKYJPMLCKWKD4GAR ! -s 10.244.0.0/16 -d 10.96.176.157/32 -p tcp -m comment --comment "default/readiness-deployment cluster IP" -m tcp --dport 80 -j KUBE-MARK-MASQ -A KUBE-SVC-IKYJPMLCKWKD4GAR -m comment --comment "default/readiness-deployment -> 10.244.0.6:8080" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-FBLUIRQWGV5XZRNC -A KUBE-SVC-IKYJPMLCKWKD4GAR -m comment --comment "default/readiness-deployment -> 10.244.0.7:8080" -j KUBE-SEP-A4EQCJTEE766DQAW
📌 Conclusion
이번 글을 통해 쿠버네티스의 Service, Endpoint, EndpointSlice에 대해서 어떻게 서비스에서 트래픽을 전달하는지 조금더 알 수 있었습니다.
처음 생각했던 내용과 달리, 엔드포인트와 엔드포인트서비스가 별개로 동작하며, v1.27 부터는 점차 Endpoint를 less preferred해 나가는 것을 직접 확인할 수 있었습니다.
주요 내용을 정리하면 다음과 같습니다:
-
EndpointSlice는 기존 Endpoints의 확장성 문제를 해결하기 위해 도입되었으며, 쿠버네티스 1.19 버전부터 기본적으로 활성화되었습니다.
-
EndpointSlice는 네트워크 성능과 확장성을 크게 개선하며, 엔드포인트를 여러 작은 조각으로 나누어 관리합니다.
-
kube-proxy는 현재 EndpointSlice를 사용하여 서비스의 엔드포인트 정보를 관리하고 있습니다.
-
Readiness Probe 실패 시, EndpointSlice 컨트롤러가 해당 파드의 상태를 감지하고 EndpointSlice를 업데이트합니다.
-
kube-proxy는 EndpointSlice의 변경을 감지하고, 이를 바탕으로 iptables 규칙을 업데이트하여 트래픽 라우팅을 조정합니다.
또한, 실제 테스트를 통해 Readiness Probe 실패 시 해당 파드가 서비스 엔드포인트에서 제거되고, 복구 시 다시 추가되는 과정을 확인했습니다.
이러한 메커니즘을 통해 쿠버네티스는 서비스의 안정성과 가용성을 유지하며, 문제가 있는 파드로 트래픽이 전달되는 것을 효과적으로 방지합니다.
앞으로 쿠버네티스를 운영하거나 개발할 때, 이러한 동작 원리를 이해하고 활용한다면 보다 더 안정적이고 효율적인 시스템을 구축할 수 있을 것 같습니다.
🔗 Reference

코드 분석부분이 너무 좋네요. 감사합니다!