📌 Notice
Kubernetes Advanced Networking Study (=KANS)
k8s 네트워크 장애 시, 네트워크 상세 동작 원리를 기반으로 원인을 찾고 해결하는 내용을 정리한 블로그입니다.
CloudNetaStudy그룹에서 스터디를 진행하고 있습니다.
Gasida님께 다시한번 🙇 감사드립니다.
EKS 관련 이전 스터디 내용은 아래 링크를 통해 확인할 수 있습니다.
📌 Summary
-
Docker 컨테이너는 리눅스 네임스페이스와 cgroups를 활용하여 프로세스 격리 및 자원 관리를 제공합니다.
-
네트워크 네임스페이스를 통해 컨테이너는 독립적인 네트워크 환경을 가지며, 가상 이더넷 장치(veth)와 브리지를 통해 통신합니다.
-
Docker는 기본적으로 브리지, 호스트, 논 네트워크 모델을 제공하며, Sysbox와 같은 고급 컨테이너 런타임은 보안을 강화합니다.
📌 Review
쿠버네티스를 이용하여 프로덕션을 운영하고 있습니다.
기초 지식 습득에서 더 나아가, 네트워크 수준에서 k8s 문제점을 트러블슈팅 하고, 안정적인 인프라를 운영하기 위해서 KANS 스터디를 지원했습니다.
이제 첫주차를 시작했지만, 스터디의 내용을 한짤로 요약하면

그동안의 스터디는 쿠버네티스를 어떻게 구축하고, 운영해 나가는지에 대해서 큰 범위에서 하나씩 진행했지만, 이번 스터디는 네트워크라는 조금더 전문적인 분야로의 탐방이므로, 첫주차 부터 굉장히 많은 내용을 스터디했습니다.
📌 Study
👉 Step 01. 도커 컨테이너 격리
쿠버네티스 네트워크를 알기 위해서는 우선, Docker에 대해서 알아야 합니다.
✅ Docker 소개
도커(Docker)는 가상실행 환경을 제공해주는 오픈소스 플랫폼입니다.
도커에서는 이 가상실행 환경을 컨테이너(Container)라고 부릅니다.
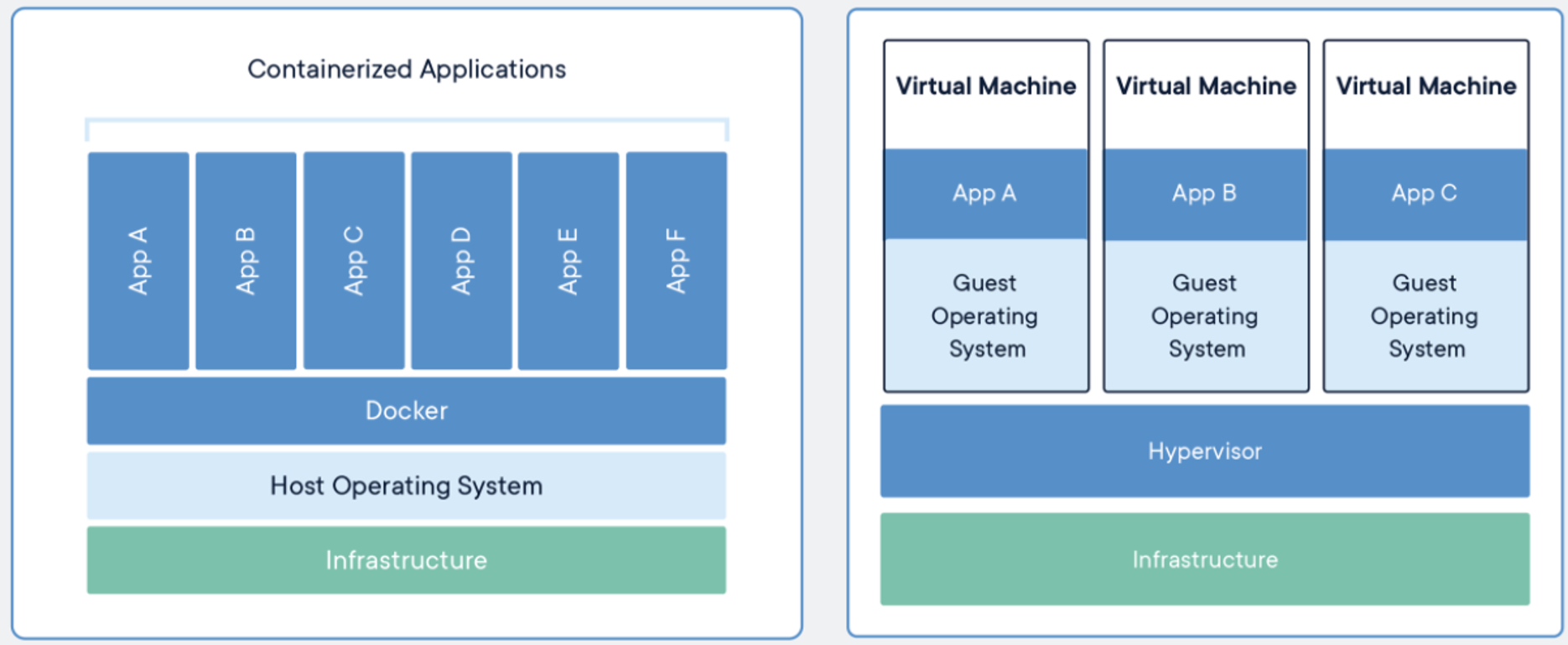 출처 - https://www.docker.com/resources/what-container/
출처 - https://www.docker.com/resources/what-container/
가상머신은 운영체제 위에 하드웨어를 에뮬레이션하고 그 위에 운영체제를 올리고 프로세스를 실행하는 반면에,
도커 컨테이너는 하드웨어 에뮬레이션 없이 리눅스 커널을 공유해서 바로 프로세스를 실행합니다.
✅ Docker 기본 사용
사전 준비 사항
보안을 위해서 root 계정을 사용을 최소화해야합니다.
다만, 스터디 실습 환경에서만 좀 더 편하게 사용하기 위해서 일부 실습에서 root 계정을 사용합니다.
Linux Process 이해
- 프로세스는 실행 중인 프로그램의 인스턴스를 의미. OS에서 프로세스를 관리하며, 각 프로세스는 고유한 ID(PID)
- 프로세스는 CPU와 메모리를 사용하는 기본 단위로, OS 커널(Cgroup)에서 각 프로세스의 자원을 관리
Docker 설치
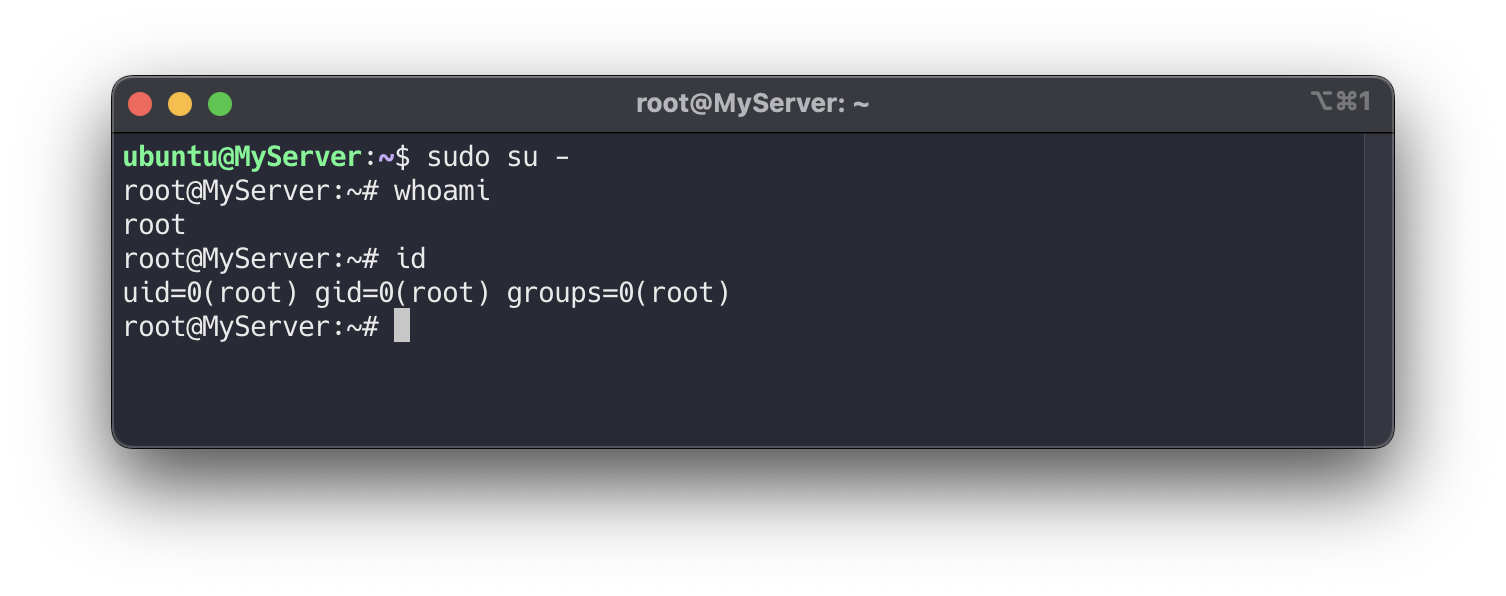
root 계정으로 전환하고, 유저의 정보를 확인합니다
# [터미널1] 관리자 전환 sudo su - whoami id
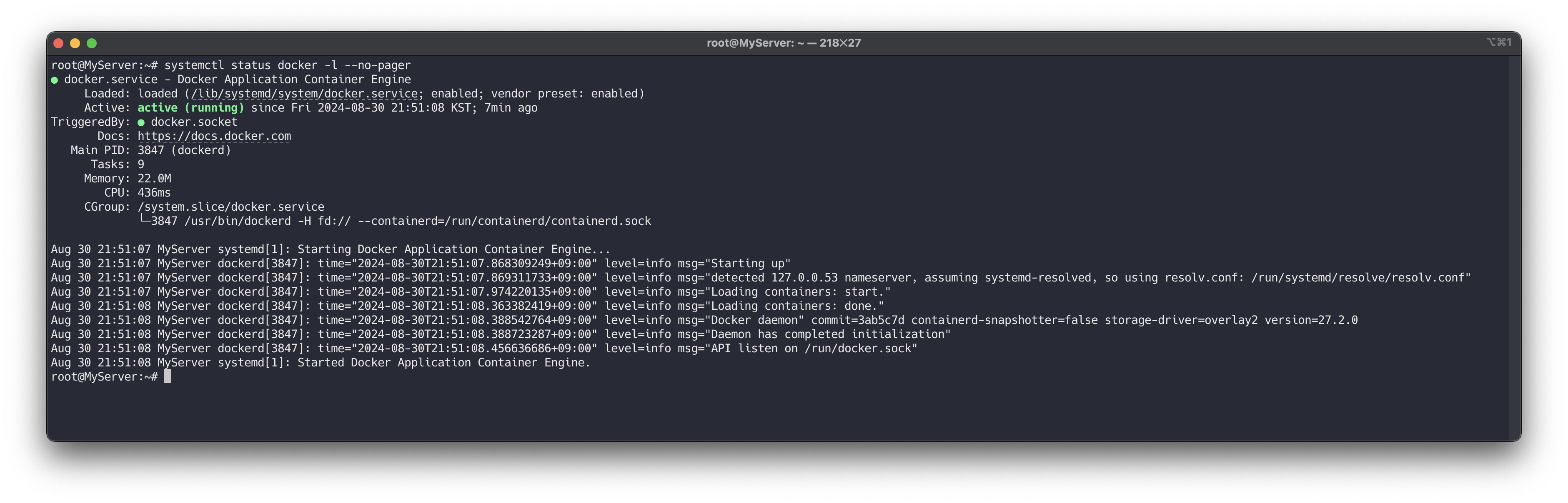
도커를 설치하고 아래 명령어를 이용하여 docker에 대한 기본 정보를 확인합니다.
# 도커 설치 curl -fsSL https://get.docker.com | sh # 도커 정보 확인 : Client 와 Server , Storage Driver(overlay2), Cgroup Version(2), Default Runtime(runc) docker info docker version # 도커 서비스 상태 확인 systemctl status docker -l --no-pager
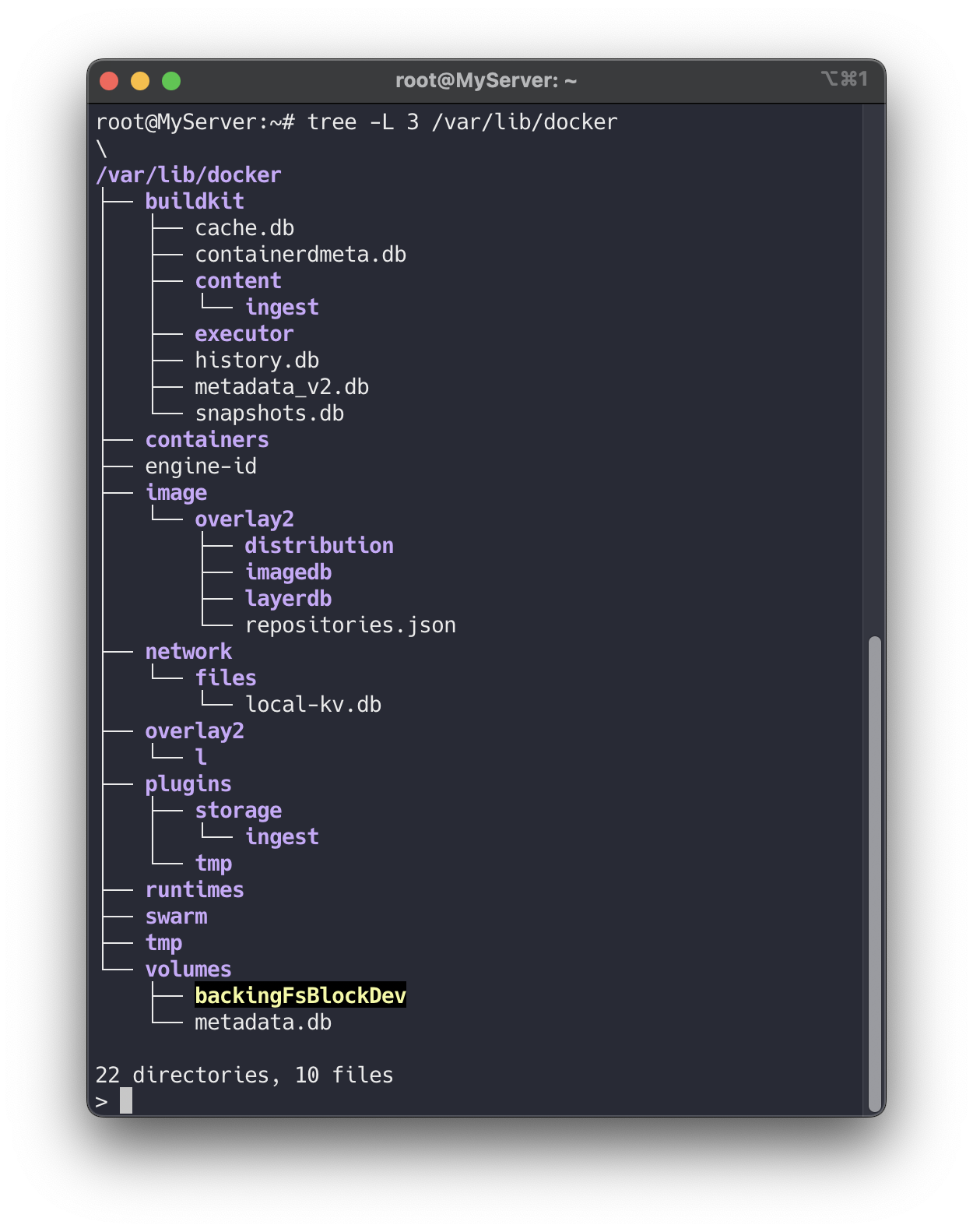
도커의 기본 루트 디렉토리를 확인합니다.
# 모든 서비스의 상태 표시 - 링크 systemctl list-units --type=service # 도커 루트 디렉터리 확인 : Docker Root Dir(/var/lib/docker) tree -L 3 /var/lib/docker
Manage Docker as a non-root user
도커를 root가 아닌 유저를 이용하여 관리할 수 있습니다.
# [터미널2] 일반 유저 ubuntu 로 실습 진행 whoami # Create the docker group : 도커 스크립트 생성 시 자동 생성되어 그룹 확인만 진행 sudo groupadd docker getent group | tail -n 3 # Add your user to the docker group. echo $USER sudo usermod -aG docker $USER # ssh logout exit
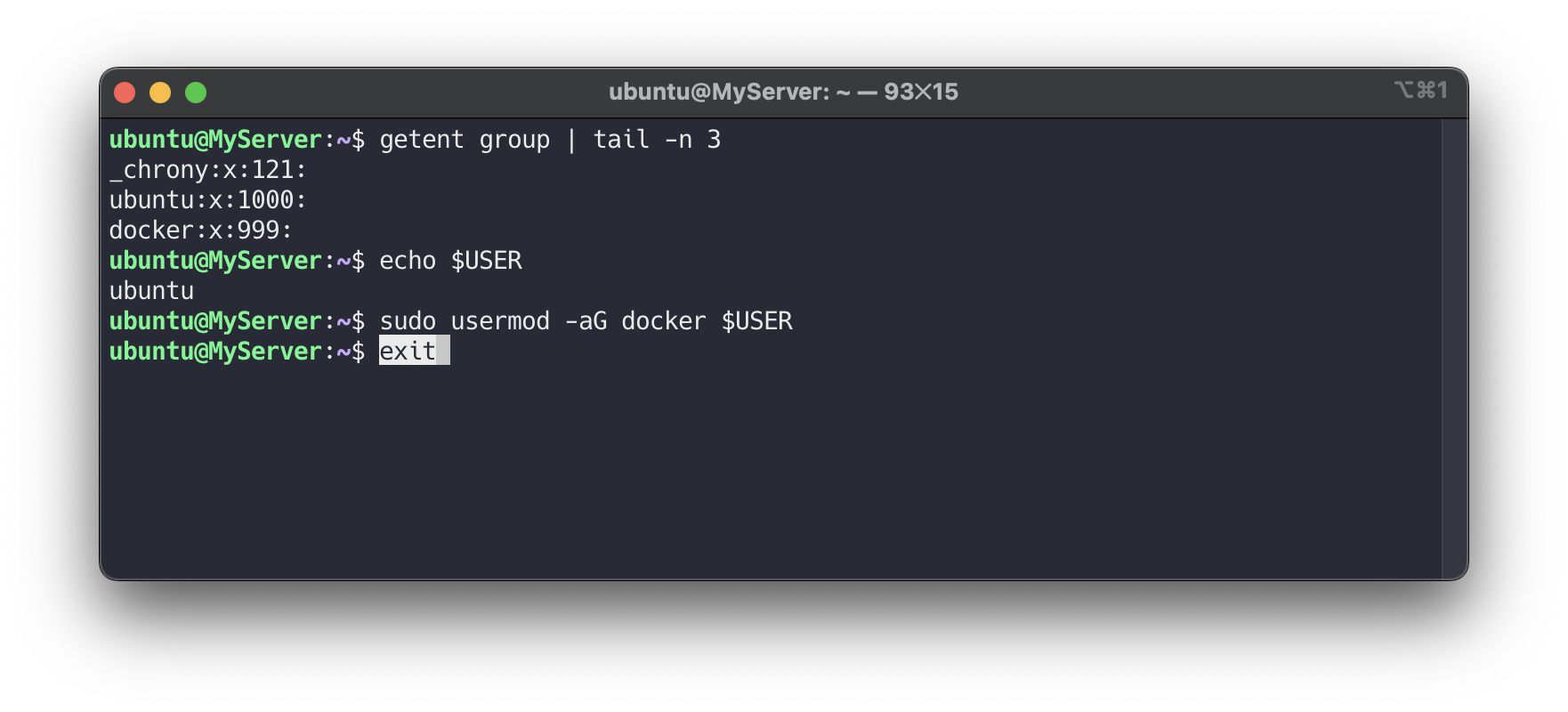
일반 유저권한으로 Docker의 기능을 사용할 수 있는지 확인합니다.
# ssh 재접속 후 확인 # docker 정보 확인 docker info # 컨테이너 실행 docker run hello-world # 도커 컨테이너 프로세스 확인 docker ps docker ps -a docker images # 중지된 컨테이너 삭제 docker ps -aq docker rm -f $(docker ps -aq) docker ps -a
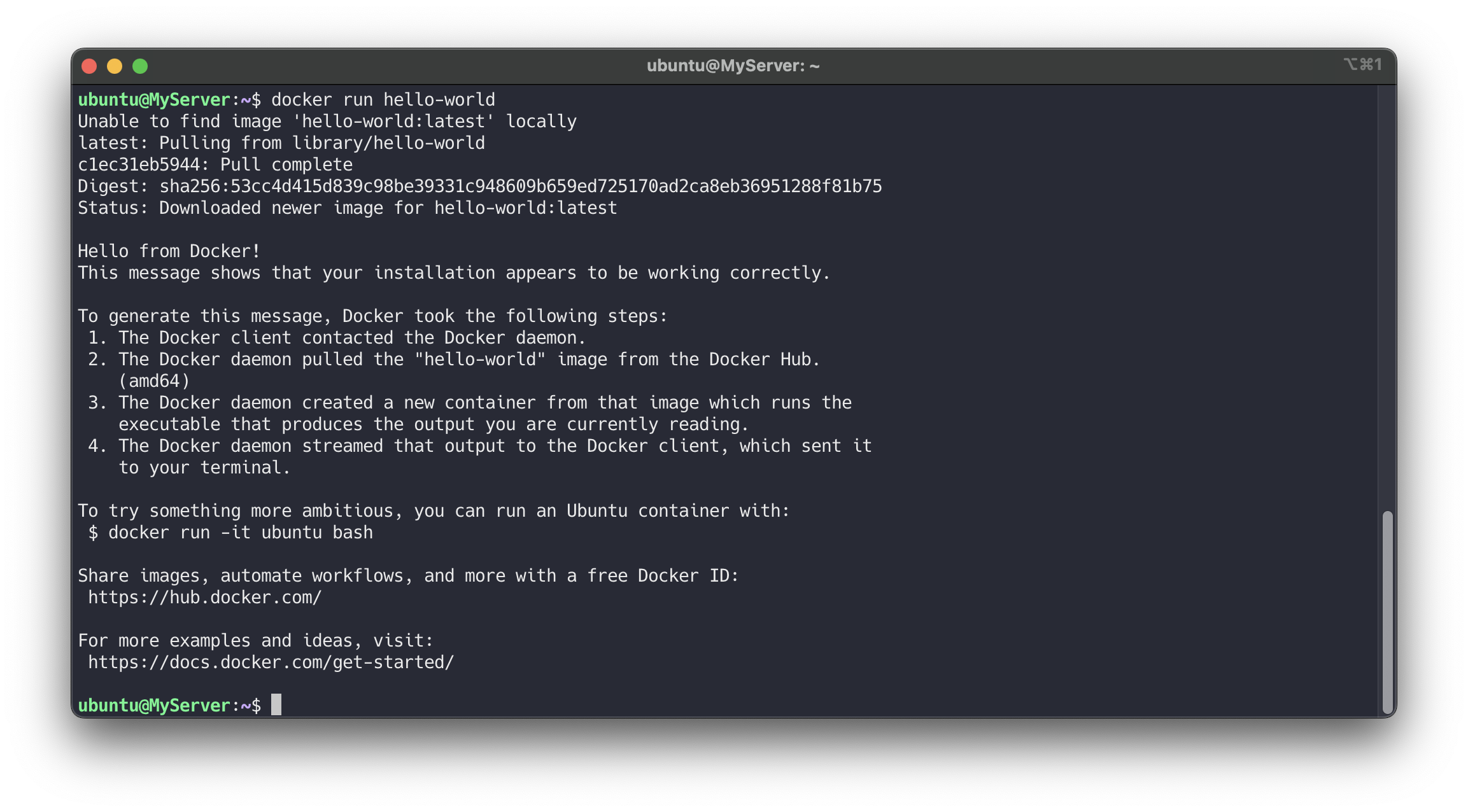
✅ 컨테이너 격리
리눅스 컨테이너는 애플리케이션을 효율적으로 배포하고 관리할 수 있는 강력한 도구입니다. 이 도구의 핵심은 시스템 자원에 대한 격리(isolation) 입니다.
리눅스 컨테이너의 격리 기술이 어떻게 발전해왔는지 알아보겠습니다.
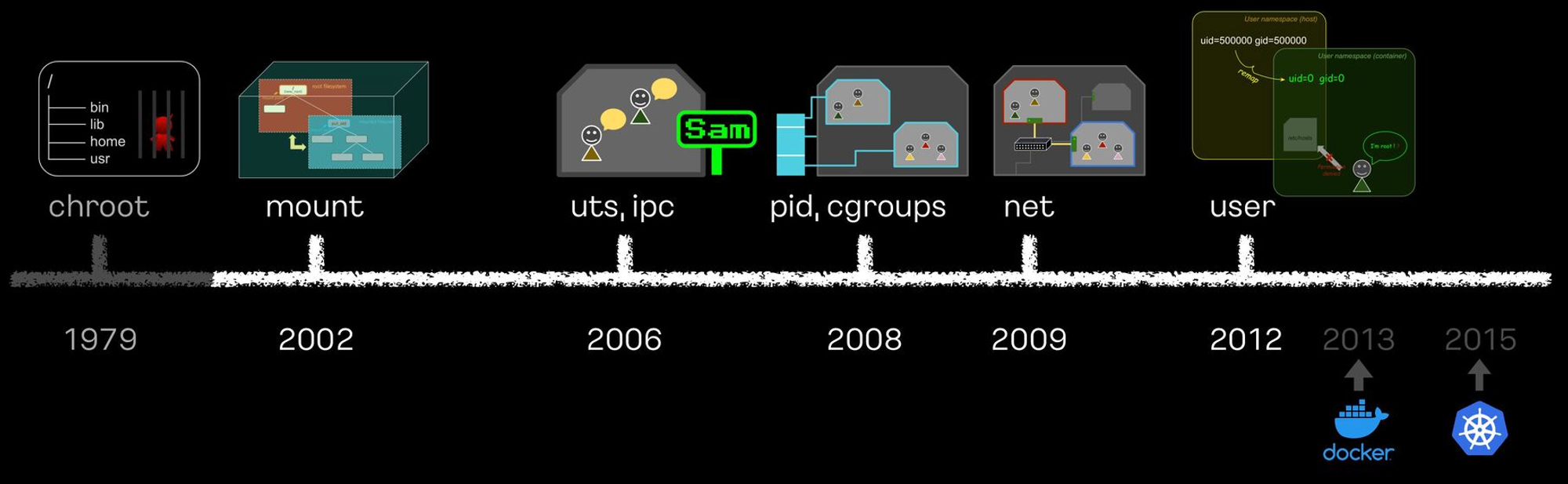
출처 - https://speakerdeck.com/kakao/ige-dwaeyo-dokeo-eobsi-keonteineo-mandeulgi?slide=200
chroot
chroot는 프로세스의 루트 디렉토리를 변경하여 파일 시스템 격리를 제공합니다.초기 컨테이너 격리 기술이지만, 프로세스 간 완전한 분리를 제공하지는 못했습니다. 현재는 더 발전된 방법으로 대체되었습니다.
Mount 네임스페이스
Mount 네임스페이스는 파일 시스템을 독립된 네임스페이스로 분리하여 각 컨테이너가 고유한 파일 시스템을 갖도록 합니다. 이를 통해 파일 시스템의 고립성을 더욱 강화할 수 있습니다.
UTS, IPC 네임스페이스
UTS와 IPC 네임스페이스는 시스템 식별자와 프로세스 간 통신을 각각 분리합니다. 이를 통해 컨테이너 내의 시스템 설정과 통신을 외부와 독립적으로 유지할 수 있습니다.
PID와 cgroups
PID 네임스페이스는 프로세스 ID를 컨테이너 내에서만 유효하게 하여 프로세스를 독립적으로 관리합니다.
cgroups는 시스템 자원의 사용을 제한하고 관리하는 기능을 제공하여 자원 할당을 세밀하게 조절할 수 있습니다.
네트워크 네임스페이스
네트워크 네임스페이스는 네트워크 스택을 분리하여 각 컨테이너가 고유한 네트워크 환경을 가지게 합니다. 이를 통해 네트워크 격리가 가능하며 보안성이 크게 향상되었습니다.
사용자 네임스페이스
사용자 네임스페이스는 컨테이너 내에서 루트 권한을 가진 사용자라도 호스트 시스템에서는 제한된 권한만 가지도록 설정할 수 있습니다. 이는 호스트 시스템의 보안을 크게 강화하는 중요한 기능입니다.
이러한 기술들을 통해 각각 컨테이너의 독립성과 보안을 강화하여 현대의 도커(Docker)와 쿠버네티스(Kubernetes)와 같은 컨테이너 오케스트레이션 도구의 기초가 되었습니다
👉 Step 02. 컨테이너 네트워크
요약
컨테이너는 네트워크 네임스페이스로 호스트와 네트워크 격리 환경을 구성됩니다.
리눅스에서 방화벽 기능을 제공하는 IPtables 는 호스트와 컨테이너의 통신에 관여를 합니다.
✅ 도커 없이 네트워크 네임스페이스 환경에서 통신 구성
네트워크 네임스페이스(Network Namespace)는 리눅스 커널이 제공하는 기능으로, 서로 독립된 네트워크 환경을 구성할 수 있게 해줍니다.
주로 컨테이너 환경에서 사용되지만, 도커 없이도 네트워크 네임스페이스를 활용해 독립적인 네트워크를 설정하고 통신을 구성할 수 있습니다.
이번 과정에서는 도커 없이 네트워크 네임스페이스를 사용해 네트워크 격리 및 통신을 설정하는 방법을 간단히 살펴보겠습니다.
RED ↔ BLUE 네트워크 네임스페이스 간 통신
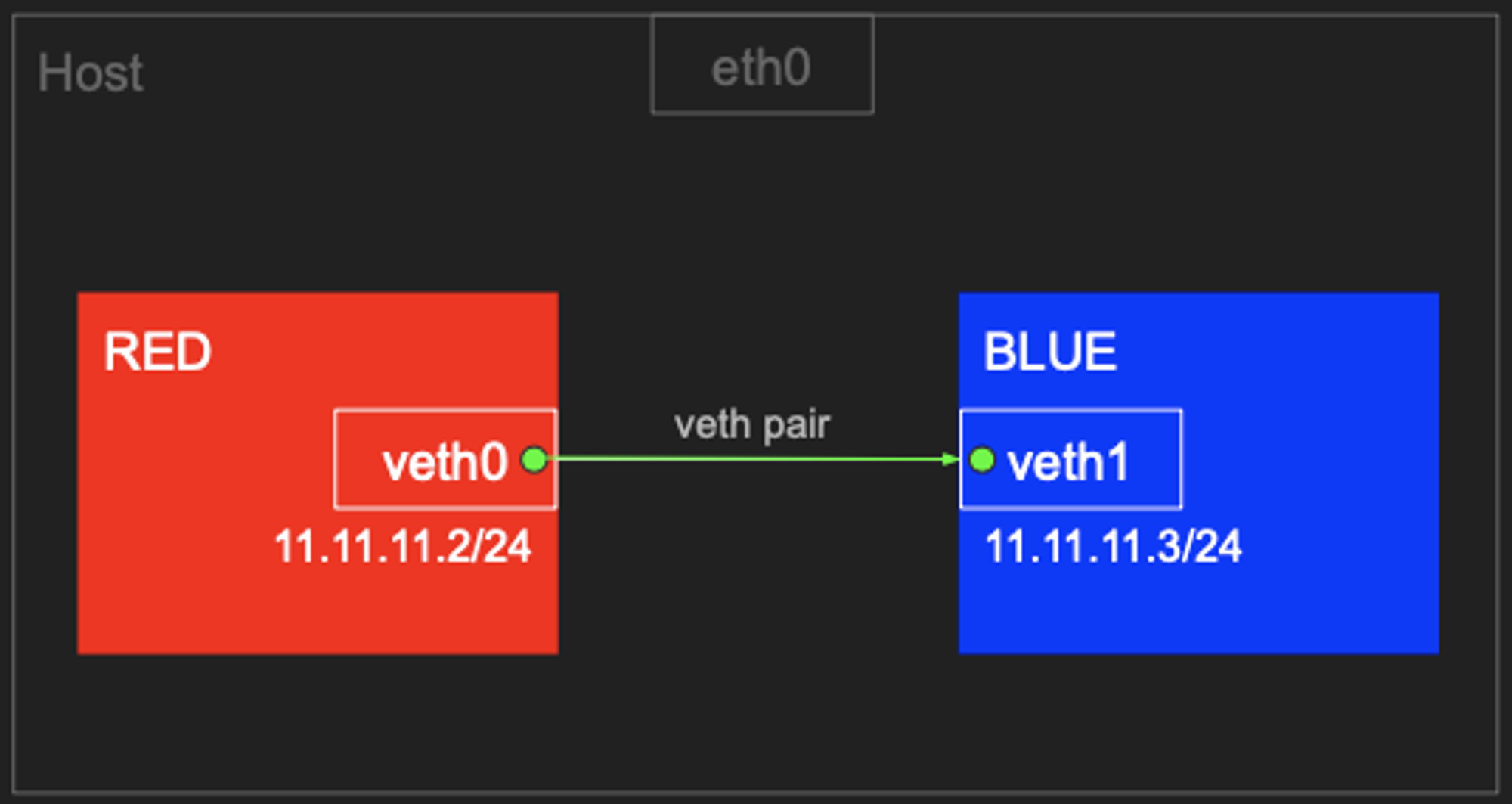
Docker를 사용하지 않고 네트워크 네임스페이스간 통신을 하는 방법을 실습합니다.
# 터미널1~3 관리자 sudo su - whoami # veth (가상 이더넷 디바이스) 생성, man ip-link ip link add veth0 type veth peer name veth1 # veth 생성 확인(상태 DOWN), ifconfig 에는 peer 정보 확인 안됨 # very pair 정보 확인 : ({iface}@if{pair#N}) ip -c link ip -c addr # 축약 ip -c a ifconfig -a
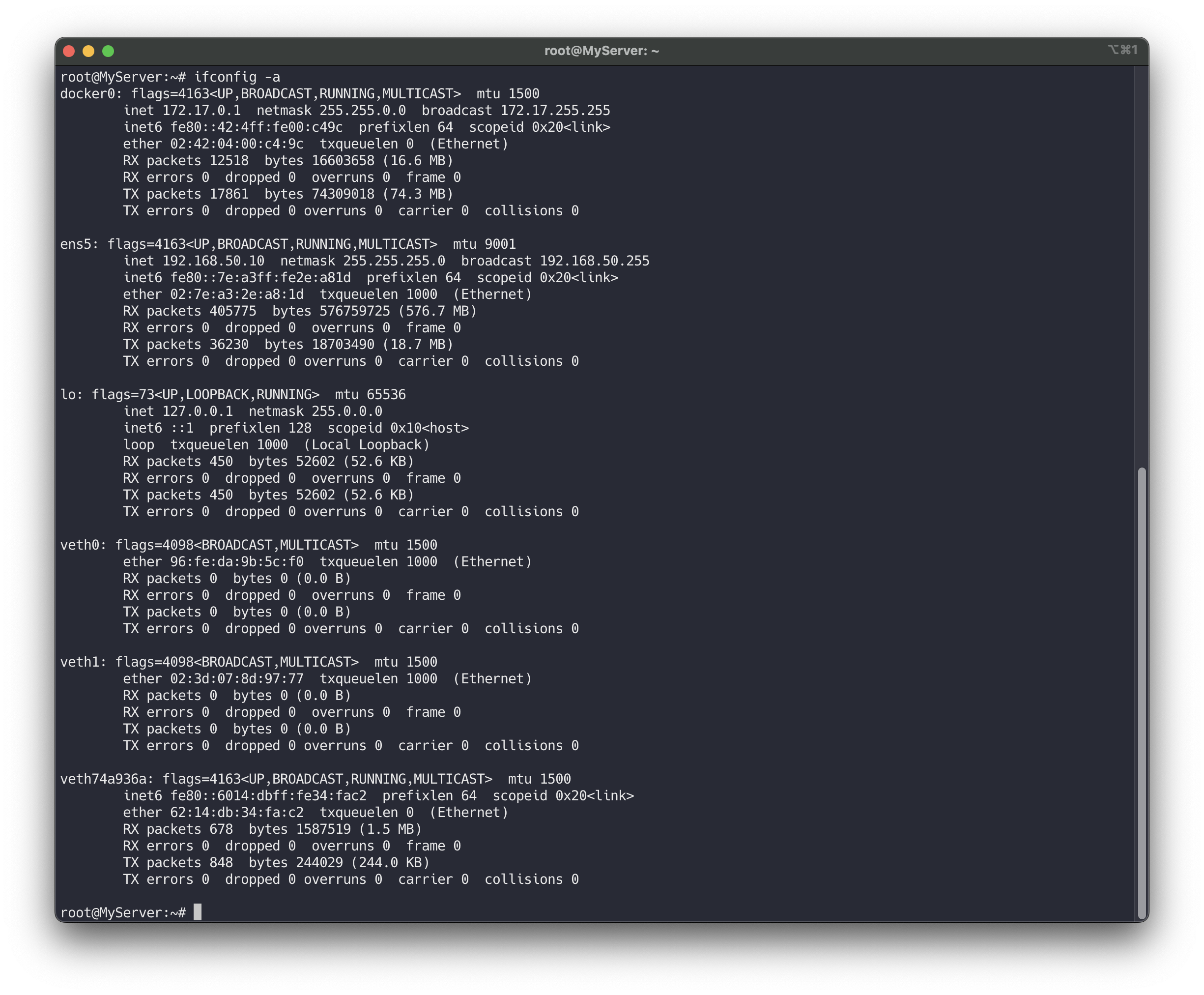
네트워크 네임스페이스를 생성하고 리스트를 확인합니다.
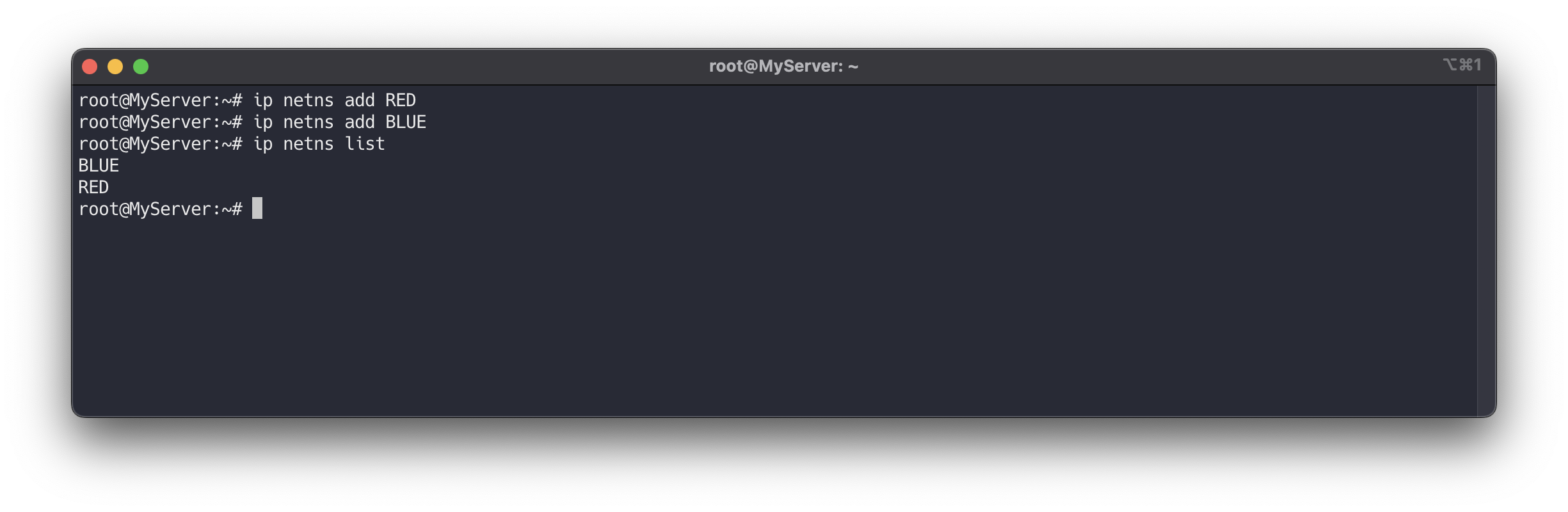
# 네트워크 네임스페이스 생성 , man ip-netns ip netns add RED ip netns add BLUE # 네트워크 네임스페이스 확인 ip netns list
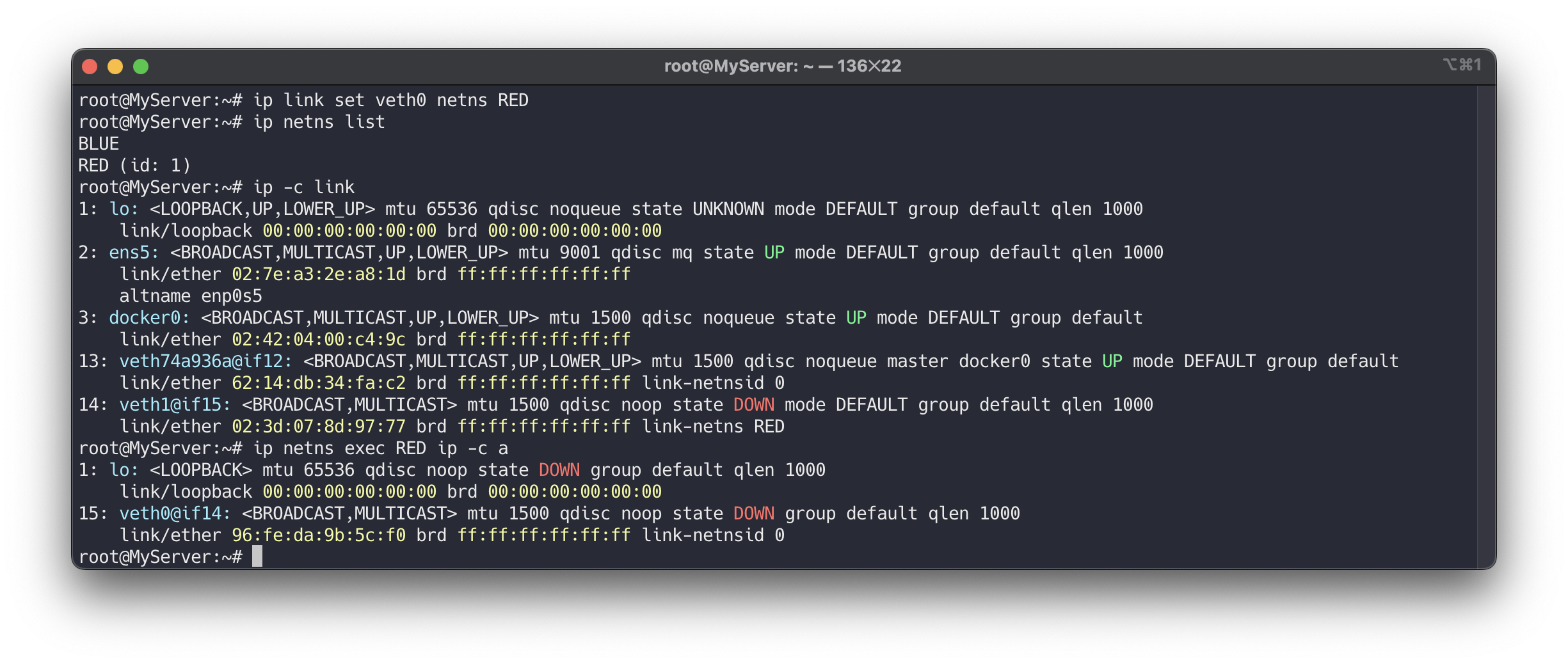
가상 이더넷을 RED 네트워크 네임스페이스로 세팅합니다.
# veth0 을 RED 네트워크 네임스페이스로 옮김 ip link set veth0 netns RED ip netns list ## 호스트의 ip a 목록에서 보이지 않음, veth1의 peer 정보가 변경됨 ip -c link ## RED 네임스페이스에서 ip a 확인됨(상태 DOWN), peer 정보 확인, link-netns RED, man ip-netns ip netns exec RED ip -c a
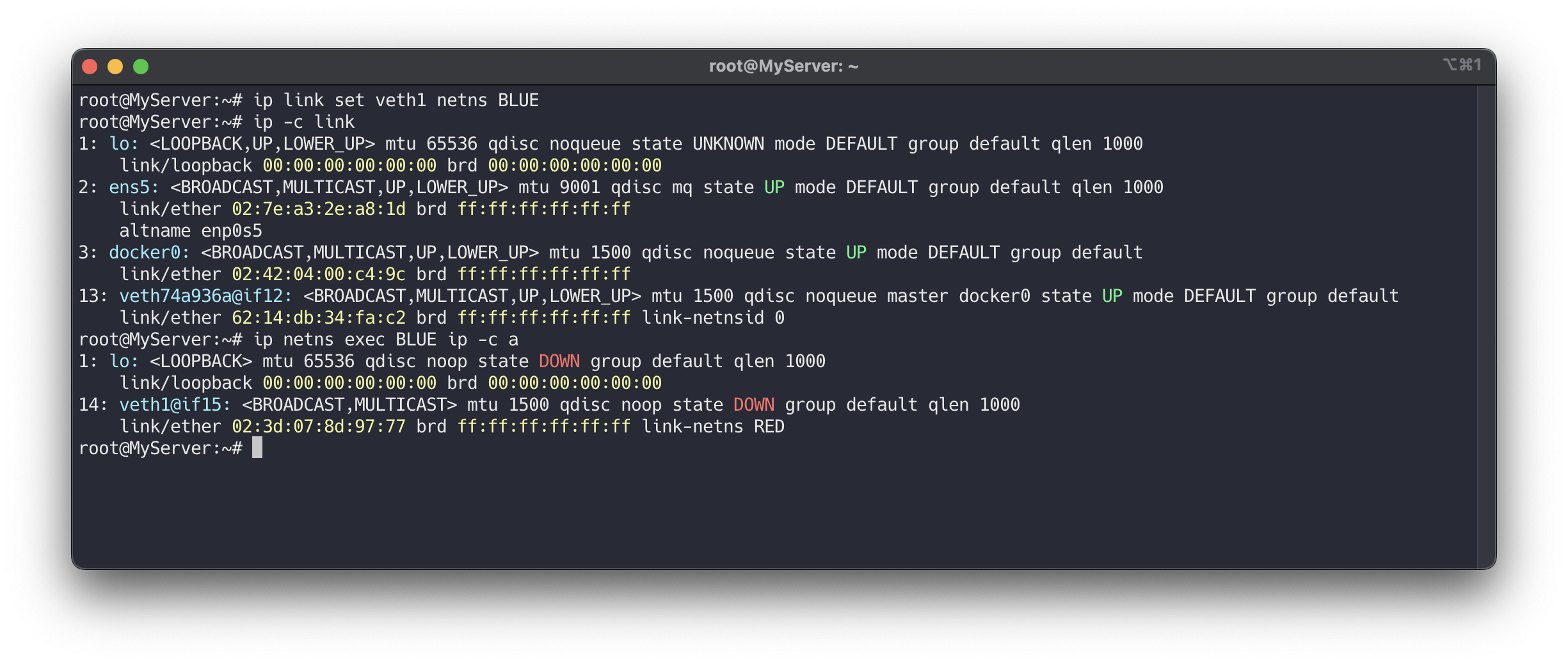
가상 이더넷 veth1을 BLUE 네트워크 네임스페이스로 세팅합니다.
# veth1 을 BLUE 네트워크 네임스페이스로 옮김 ip link set veth1 netns BLUE ip -c link ip netns exec BLUE ip -c a
veth0, veth1 상태를 활성화 합니다.
# veth0, veth1 상태 활성화(state UP) ip netns exec RED ip link set veth0 up ip netns exec RED ip -c a ip netns exec BLUE ip link set veth1 up ip netns exec BLUE ip -c a
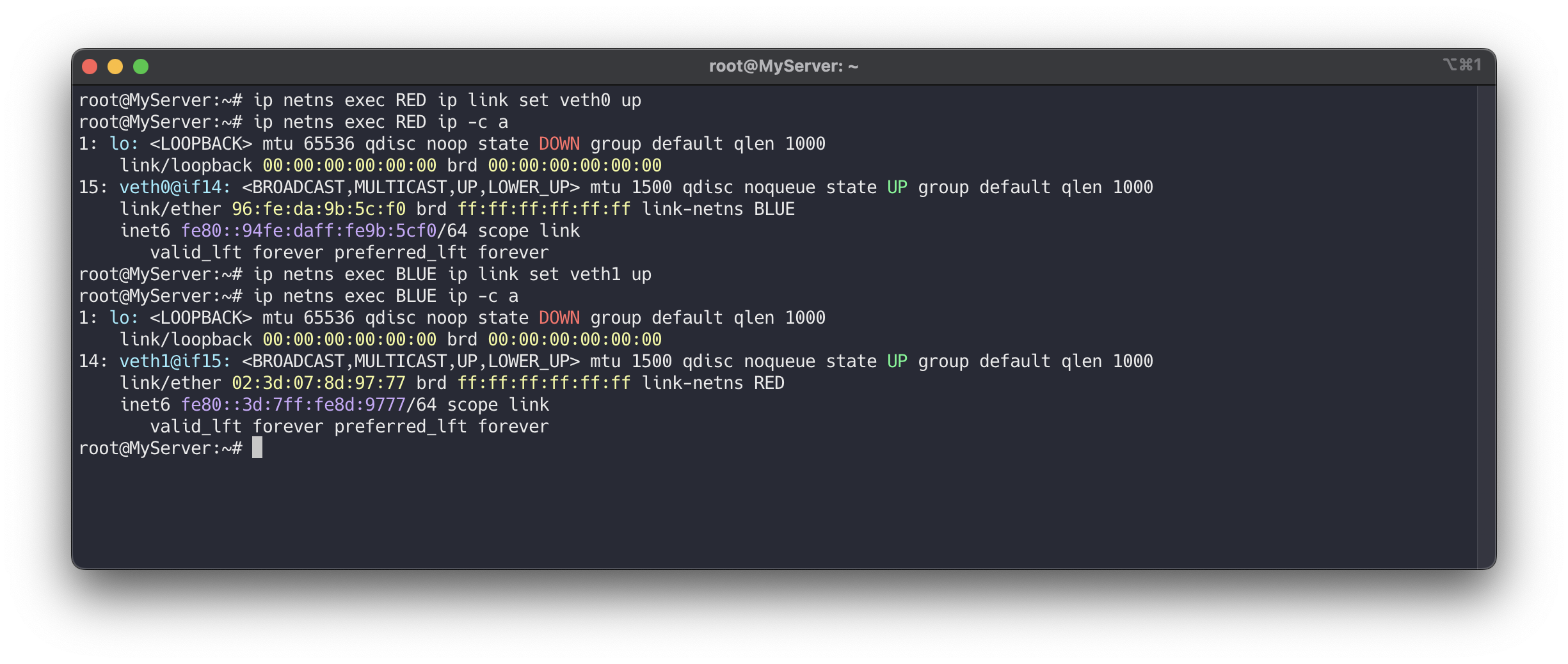
IP 설정을 완료하고, 터미널을 3개 활성화하여 ping 테스트를 진행합니다.
# veth0, veth1 에 IP 설정 ip netns exec RED ip addr add 11.11.11.2/24 dev veth0 ip netns exec RED ip -c a ip netns exec BLUE ip addr add 11.11.11.3/24 dev veth1 ip netns exec BLUE ip -c a # 터미널1 (RED 11.11.11.2) ## nsenter : 네임스페이스에 attach 하여 지정한 프로그램을 실행 tree /var/run/netns nsenter --net=/var/run/netns/RED ip -c a ## neighbour/arp tables management , man ip-neighbour ip -c neigh ## 라우팅 정보, iptables 정보 ip -c route iptables -t filter -S iptables -t nat -S # 터미널2 (호스트) lsns -t net # nsenter 실행 후 TYPE(net) CMD(-bash) 생성 확인 ip -c a ip -c neigh ip -c route iptables -t filter -S iptables -t nat -S # 터미널3 (BLUE 11.11.11.3) nsenter --net=/var/run/netns/BLUE ip -c a ip -c neigh ip -c route iptables -t filter -S iptables -t nat -S # ping 통신 확인 # 터미널3 (BLUE 11.11.11.3) tcpdump -i veth1 ip -c neigh exit # 터미널1 (RED 11.11.11.2) ping 11.11.11.3 -c 1 ip -c neigh exit
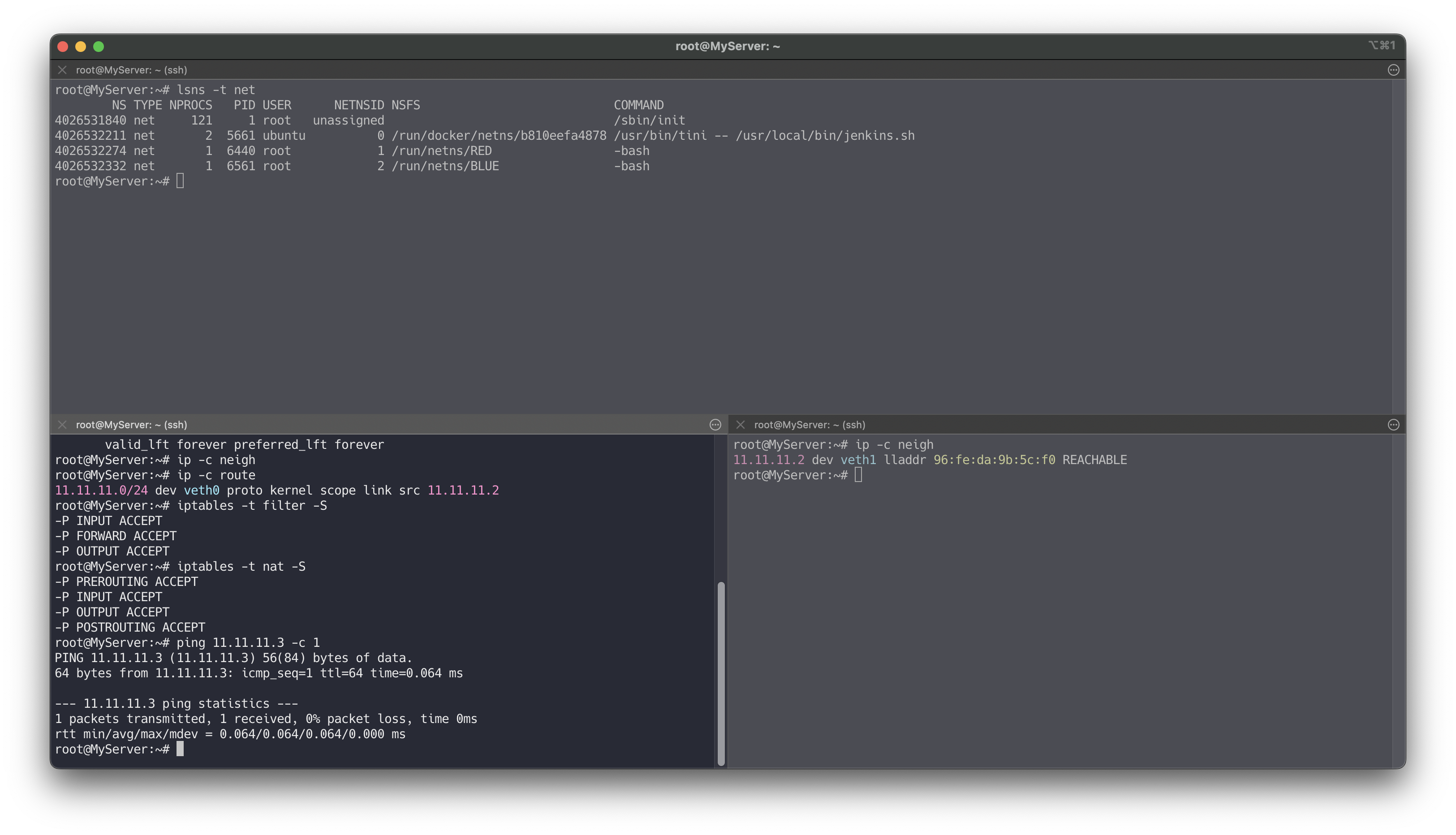
실습을 완료하고 리소스를 정리합니다.
# 삭제 ip netns delete RED ip netns delete BLUE
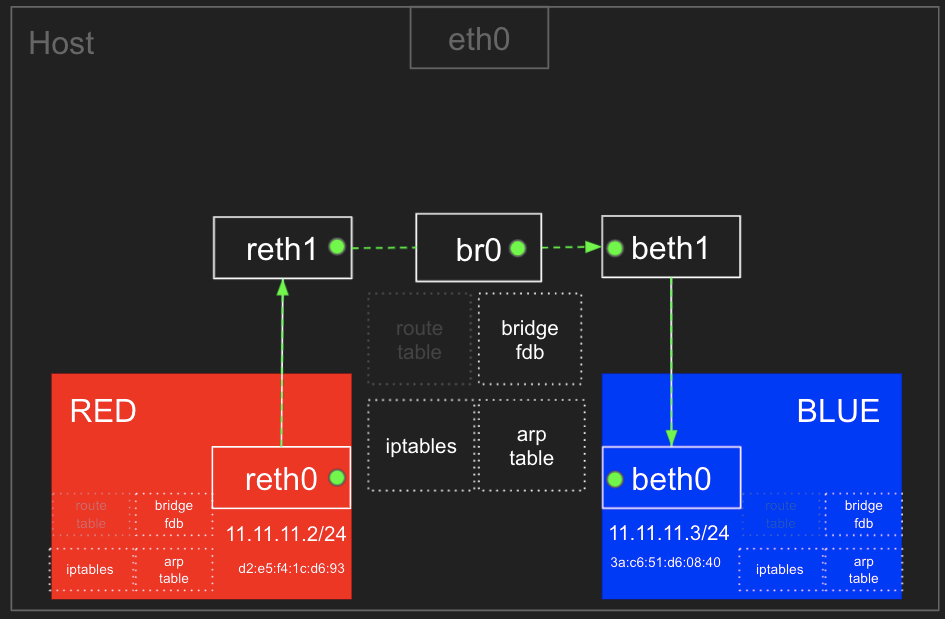
RED ← Bridge(br0) → BLUE 간 통신
arp table, route table, iptables 와 호스트의 bridge fdb 를 통하여 통신
RED/BLUE → 호스트 & 외부(인터넷) 통신
호스트에 RED/BLUE와 통신 가능한 IP 설정 및 라우팅 추가, iptables NAT 를 통하여 통신
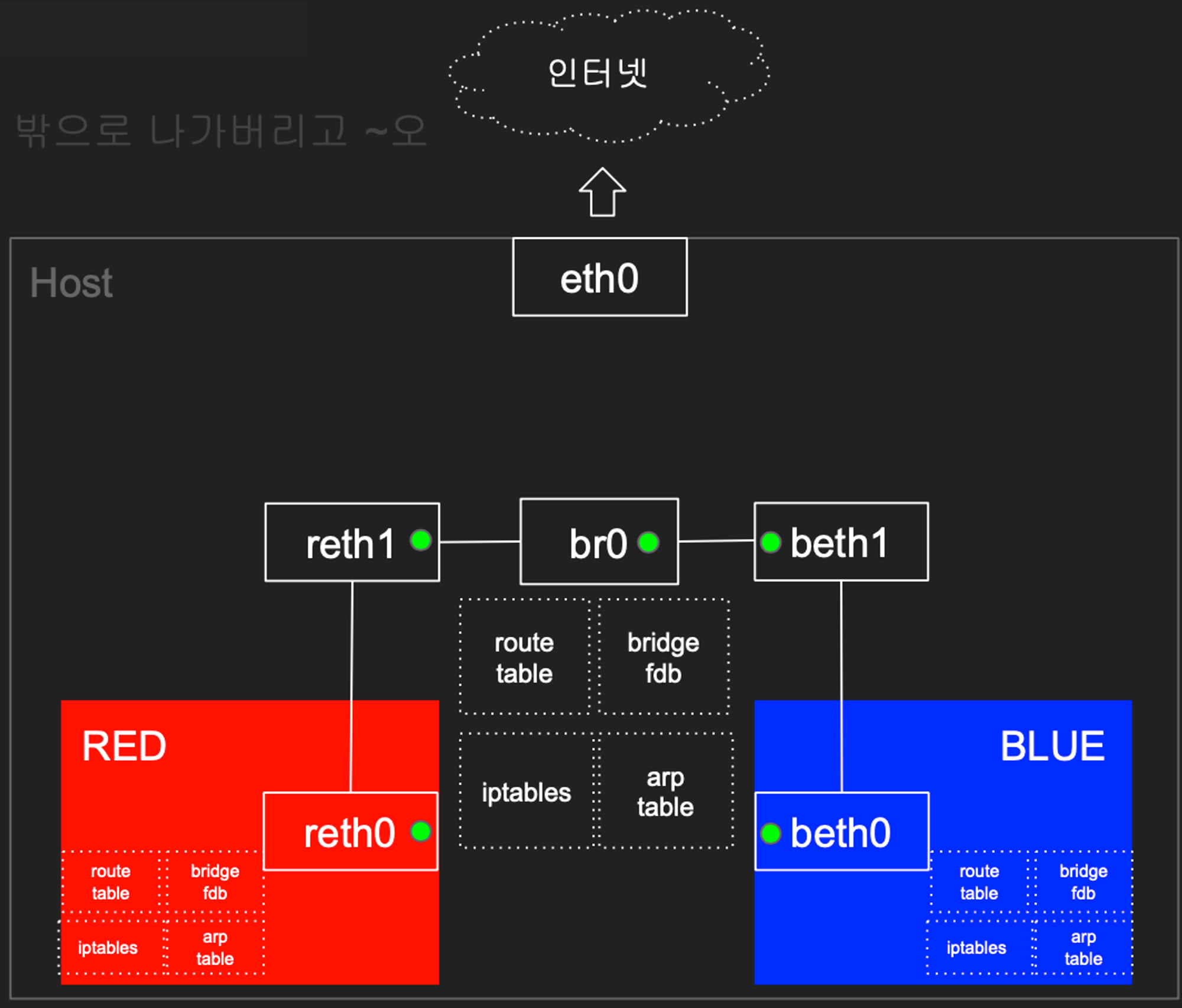
네트워크 네임스페이스만으로도 직접 수동으로 설정할 경우 굉장히 복잡하다는 것을 확인할 수 있습니다.
도커는 컨테이너 실행(run)시 자동으로 해당 컨테이너의 네임스페이스(네트워크, 마운트, PID 등)를 생성(삭제 등)하여 호스트와 격리해줍니다.
✅ 도커 네트워크 모델
도커가 기본적으로 제공하는 네트워크 유형입니다.
도커를 설치하면 기본적으로 사용할 수 있으며, 대부분의 일반적인 사용 사례에 적합합니다.
브리지 네트워크 (Bridge Network)
도커 컨테이너가 동일한 호스트 내에서 통신할 수 있게 하는 기본 네트워크입니다.
기본적으로 도커는 bridge라는 이름의 브리지 네트워크를 생성하며, 각 컨테이너는 이 네트워크를 통해 통신합니다.
출처 - https://dockerlabs.collabnix.com/intermediate/DiffBridgeVsOverlay.html
호스트 네트워크 (Host Network)
컨테이너가 호스트의 네트워크 스택을 직접 사용하는 방식입니다.
이 네트워크를 사용하면 컨테이너는 호스트의 IP 주소를 공유하게 되어 네트워크 오버헤드가 줄어들지만, 보안적인 격리도 감소합니다.
출처 - https://dockerlabs.collabnix.com/intermediate/DiffBridgeVsOverlay.html
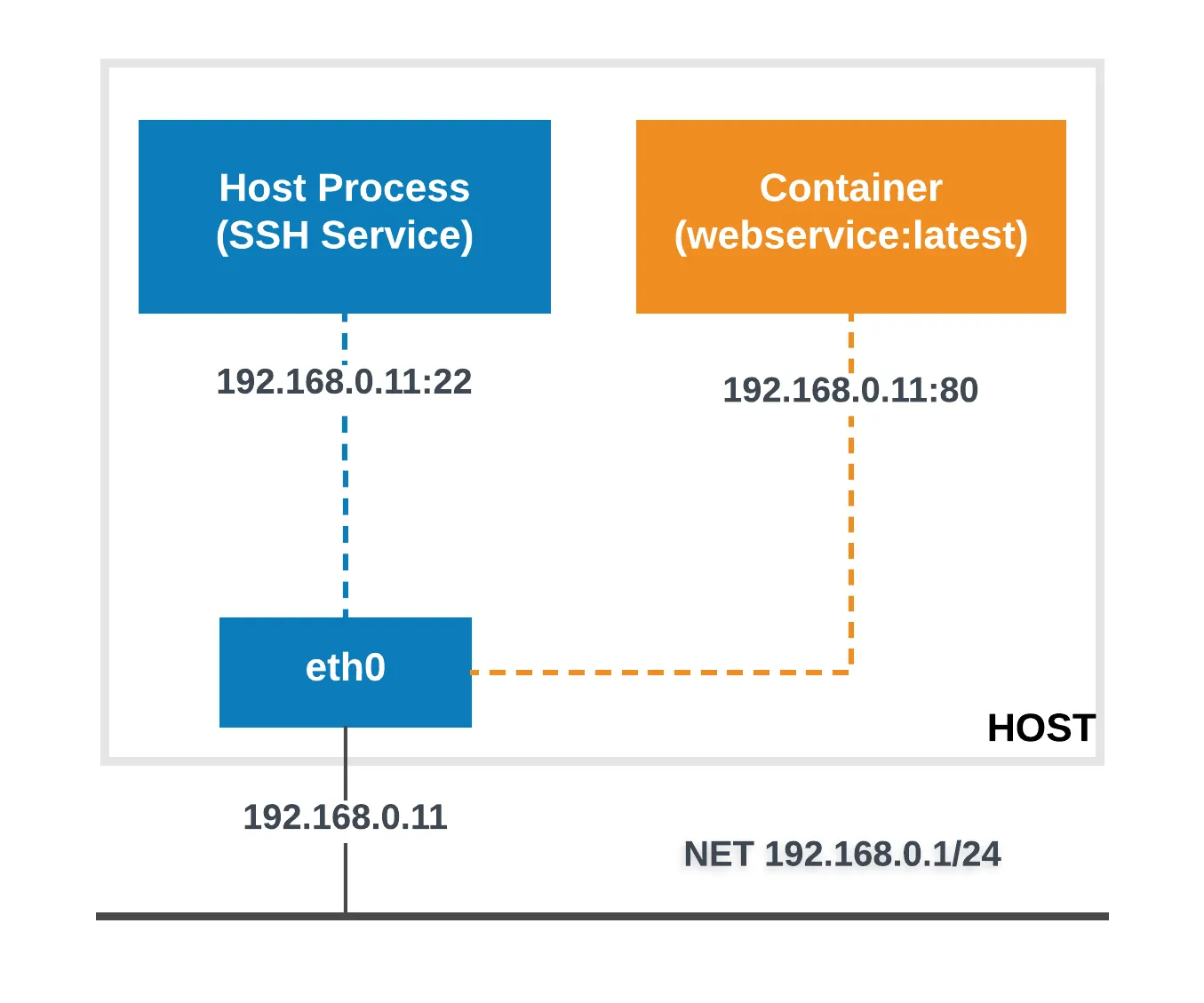
논 네트워크 (None Network)
컨테이너에 네트워크 인터페이스를 할당하지 않는 네트워크 모드입니다.
이 모드를 사용하면 컨테이너는 외부 네트워크와 통신할 수 없으며, 완전히 독립된 상태로 실행됩니다.
👉 Step 03. 보안
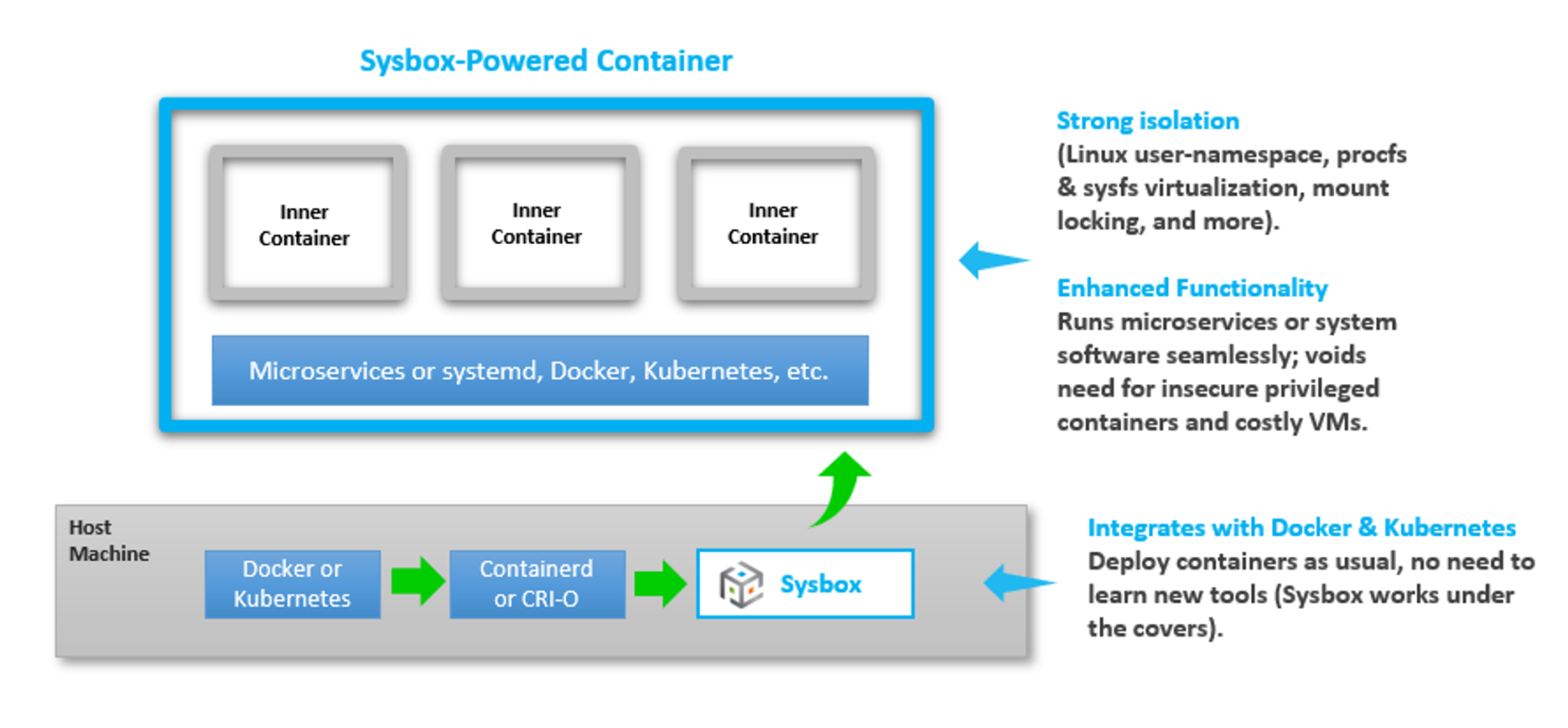
✅ Sysbox Container Runtime
Sysbox는 컨테이너가 VM(가상 머신)과 유사한 방식으로 더 강력한 보안 격리를 유지하면서도, 호스트 리소스에 대한 접근을 제어하는 기능을 제공합니다.
Sysbox Container Runtime의 주요 기능
컨테이너 격리 강화 (Improves Container Isolation)
- 모든 컨테이너에서 Linux 사용자 네임스페이스 지원:
컨테이너 내부의 root 사용자가 호스트에서는 권한이 없는 상태로 설정됩니다.
- procfs 및 sysfs의 일부를 가상화:
컨테이너 내부에서 호스트 시스템의 특정 파일 시스템(예: /proc, /sys)에 대한 접근이 제한됩니다.
- 호스트 정보 숨기기:
컨테이너 내부에서 호스트 시스템 정보가 감춰지도록 설정됩니다.
Sysbox가 해결할 수 있는 문제들
컨테이너 내 루트 권한 남용 방지
기본 컨테이너 런타임에서는 컨테이너 내부의 root 사용자가 호스트에서도 root 권한을 가지는 경우가 많아 보안 리스크가 존재합니다. Sysbox는 이를 해결하여 루트 권한 남용을 방지합니다.컨테이너와 호스트 간 정보 노출 최소화
컨테이너가 호스트의 파일 시스템 정보나 기타 민감한 시스템 정보를 노출할 수 있는 문제를 해결합니다.향상된 격리로 인해 강화된 보안
가상 머신과 유사한 격리 수준을 제공하여, 다중 테넌트 환경에서 보다 안전하게 컨테이너를 운영할 수 있게 합니다.
How it Works
강력한 격리 (Strong Isolation):
Sysbox는 Linux 사용자 네임스페이스, procfs 및 sysfs 가상화, 마운트 락킹 등의 기술을 사용하여 컨테이너의 격리 수준을 크게 강화합니다.향상된 기능 (Enhanced Functionality):
Sysbox는 마이크로서비스 또는 시스템 소프트웨어를 원활하게 실행하며, 보안상 위험이 있는 특권 컨테이너나 비용이 많이 드는 가상 머신의 필요성을 제거합니다.Docker 및 Kubernetes와의 통합 (Integrates with Docker & Kubernetes):
Sysbox는 기존의 Docker 및 Kubernetes 환경에 원활하게 통합되며, 별도의 새로운 도구를 배울 필요 없이 컨테이너를 기존과 동일한 방식으로 배포할 수 있습니다.
🔥 Assignment
도전과제 03. 도커 컨테이너에서 USER 네임스페이스 격리 실습 후 정리
Docker 컨테이너는 일반적으로 루트 권한을 사용하여 실행됩니다.
이는 개발과 테스트 과정에서는 편리할 수 있지만, 실제 운영 환경에서는 큰 보안 취약점이 될 수 있습니다.
루트 권한을 가진 컨테이너에서 보안 결함이 발생할 경우, 호스트 시스템 전체가 위험에 노출될 수 있기 때문입니다.
이러한 보안 문제를 해결하기 위해 Docker는 여러 가지 보안 기능을 제공하며, 그 중 하나가 바로 사용자 네임스페이스(User Namespaces) 기능입니다.
userns-remap이라고도 불리는 이 기능은 컨테이너 내부의 사용자를 호스트 시스템의 특정 사용자로 매핑하여, 호스트의 루트 권한을 보호하고, 컨테이너의 보안을 강화하는 데 목적이 있습니다.
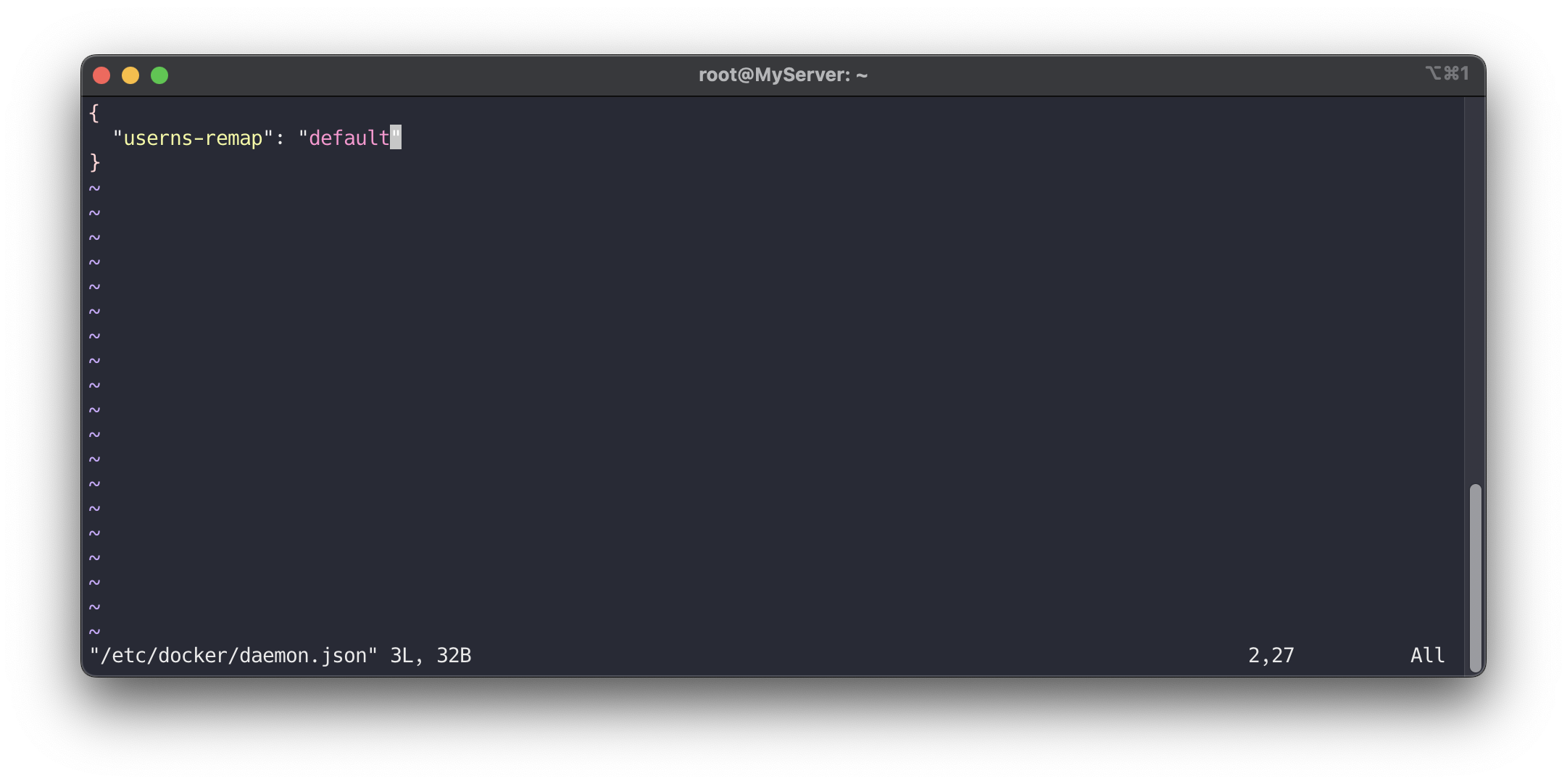
Docker 데몬 설정 파일 편집
/etc/docker/daemon.json파일을 엽니다. 이 파일이 없으면 새로 생성합니다.sudo vi /etc/docker/daemon.json다음 JSON 구성을 추가하여 userns-remap 기능을 testuser로 설정합니다
{ "userns-remap": "default" }
Docker 데몬을 재시작 합니다
sudo systemctl restart docker
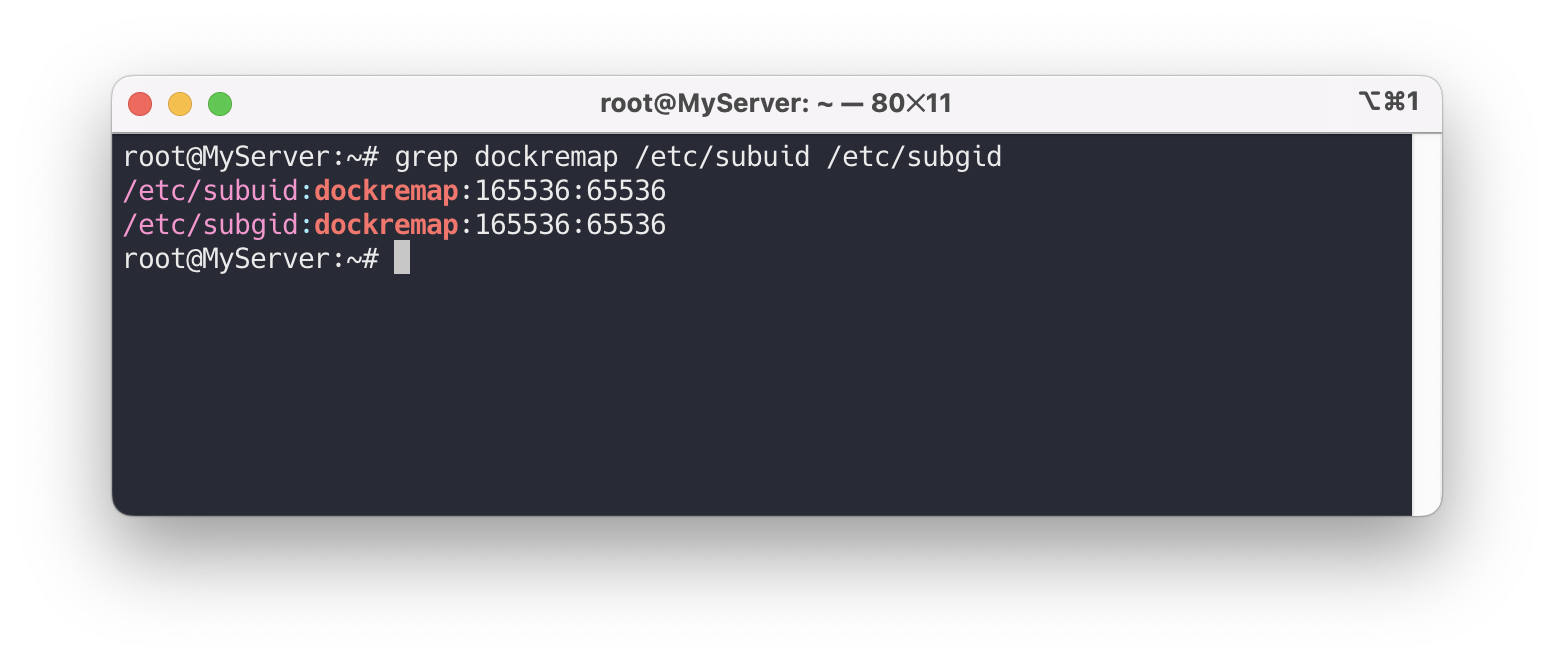
userns-remap이 제대로 활성화되었는지 확인하려면 다음 명령어를 실행합니다
grep dockremap /etc/subuid /etc/subgid --- /etc/subuid:dockremap:165536:65536 /etc/subgid:dockremap:165536:65536
출력 결과에 userns 관련 정보가 나타나야 하며, 이는 기능이 정상적으로 활성화되었음을 의미합니다.
docker info | grep userns
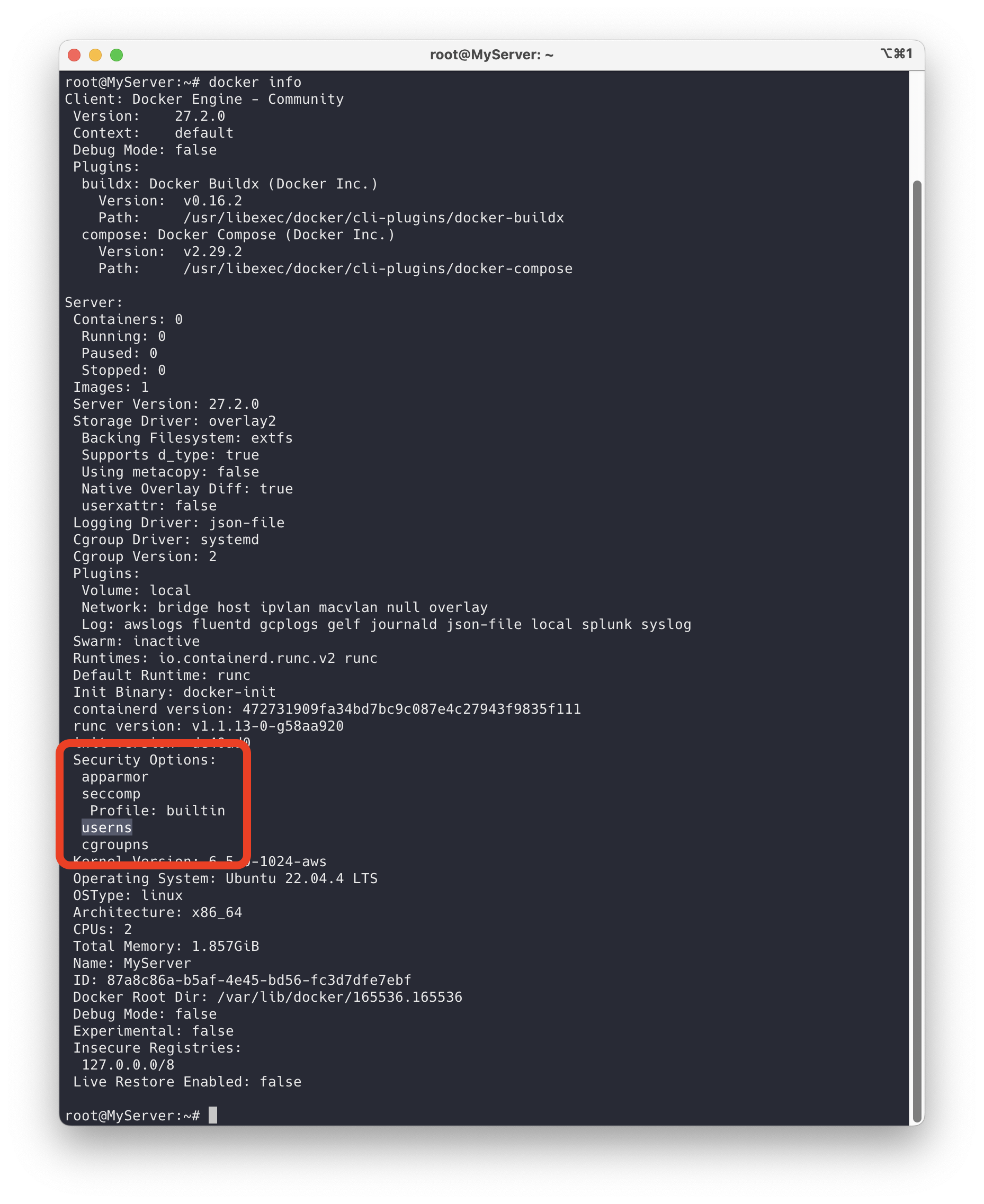
새로운 컨테이너를 실행하고 사용자 ID가 올바르게 매핑되었는지 확인합니다
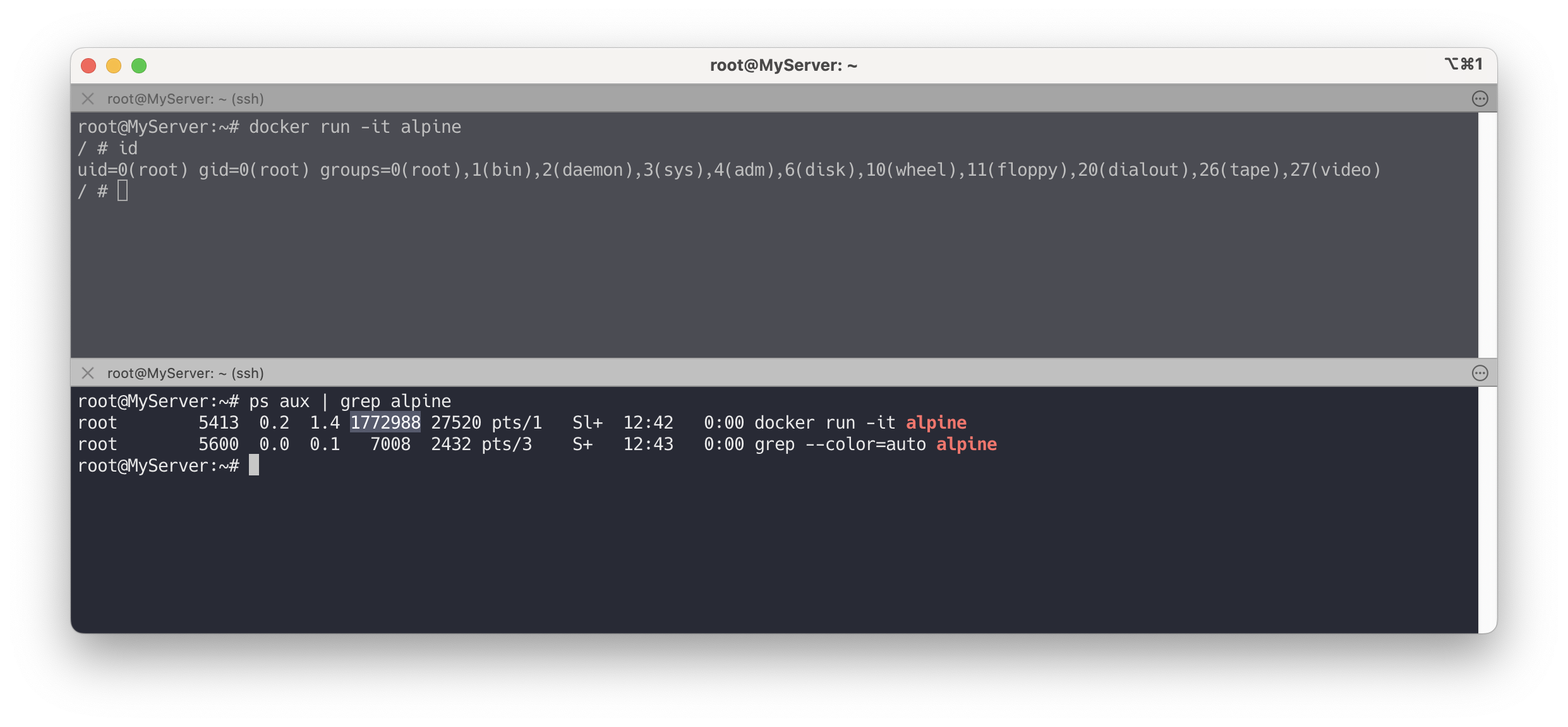
# 터미널 1 docker run -it --rm alpine --- # 컨테이너 내부 id컨테이너 내부에서 보이는 UID와 GID는 0으로 표시되겠지만, 실제로는 호스트 시스템에서 다른 UID/GID로 매핑됩니다.
출력된 결과에서 UID가 100000 이상의 값으로 표시되는 것을 확인할 수 있습니다.
# 터미널 2 ps aux | grep alpine
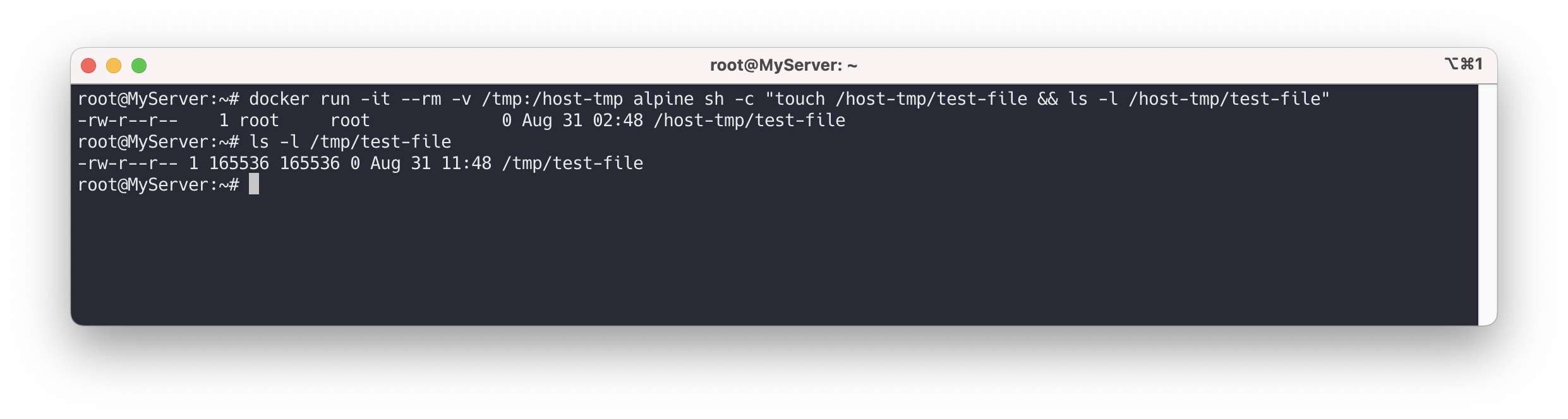
추가로, 컨테이너 내부의 파일 소유권을 확인해볼 수 있습니다
docker run -it --rm -v /tmp:/host-tmp alpine sh -c "touch /host-tmp/test-file && ls -l /host-tmp/test-file"호스트 시스템에서 해당 파일의 소유권을 확인합니다.
이 파일의 소유자 UID가 100000 이상의 값으로 표시되는 것을 확인할 수 있습니다.
ls -l /tmp/test-file
📌 Conclusion
이번 스터디에서 컨테이너 기술의 핵심인 격리와 네트워크 구성에 대해 깊이 있게 살펴보았습니다.
컨테이너 격리의 이해: Docker가 리눅스 네임스페이스와 cgroups를 활용하여 어떻게 프로세스를 격리하고 자원을 관리하는지 배웠습니다. 이는 컨테이너 기술의 근간이 되는 핵심 개념이었고, 앞으로 쿠버네티스를 이해하는 데 큰 도움이 될 것 같습니다.
네트워크 구성의 실제: 네트워크 네임스페이스와 가상 이더넷 장치를 직접 구성해보면서, Docker가 자동으로 처리하는 네트워크 설정의 복잡성을 체감할 수 있었습니다. 이 과정에서 Docker의 편의성과 중요성을 새삼 깨달았습니다.
컨테이너 보안의 중요성: Sysbox와 같은 고급 컨테이너 런타임을 살펴보면서, 컨테이너 환경에서의 보안 강화가 얼마나 중요한지 인식했습니다. 이는 프로덕션 환경에서 컨테이너를 안전하게 운영하는 데 필수적인 요소라고 생각됩니다.
🔗 Reference
- Docker 설치 - https://docs.docker.com/engine/install/ubuntu/
- Docker 유저 네임스페이스 - https://docs.docker.com/engine/security/userns-remap/
