
📌 Notice
본 블로깅은 아래의
24단계 실습으로 정복하는 쿠버네티스책을 기준하여 정리하였습니다.
출처 - https://wikibook.co.kr/kubepractice
CloudNetaStudy그룹에서 스터디한 내용입니다.
책의 저자이신이정훈-Jerry님과 함께 스터디 하고 있습니다. 🙏
Gasida님과Jerry님께 다시한번 🙇 감사드립니다.
📌 Summary
- PLG 스택을 통해 시스템 및 애플리케이션을 모니터링하고 문제 발생 시 적절한 알림을 받을 수 있습니다.
- Alert Manager를 이용하여 Prometheus에서 발생한 Alert을 수집하고 관리합니다.
📌 Architecture
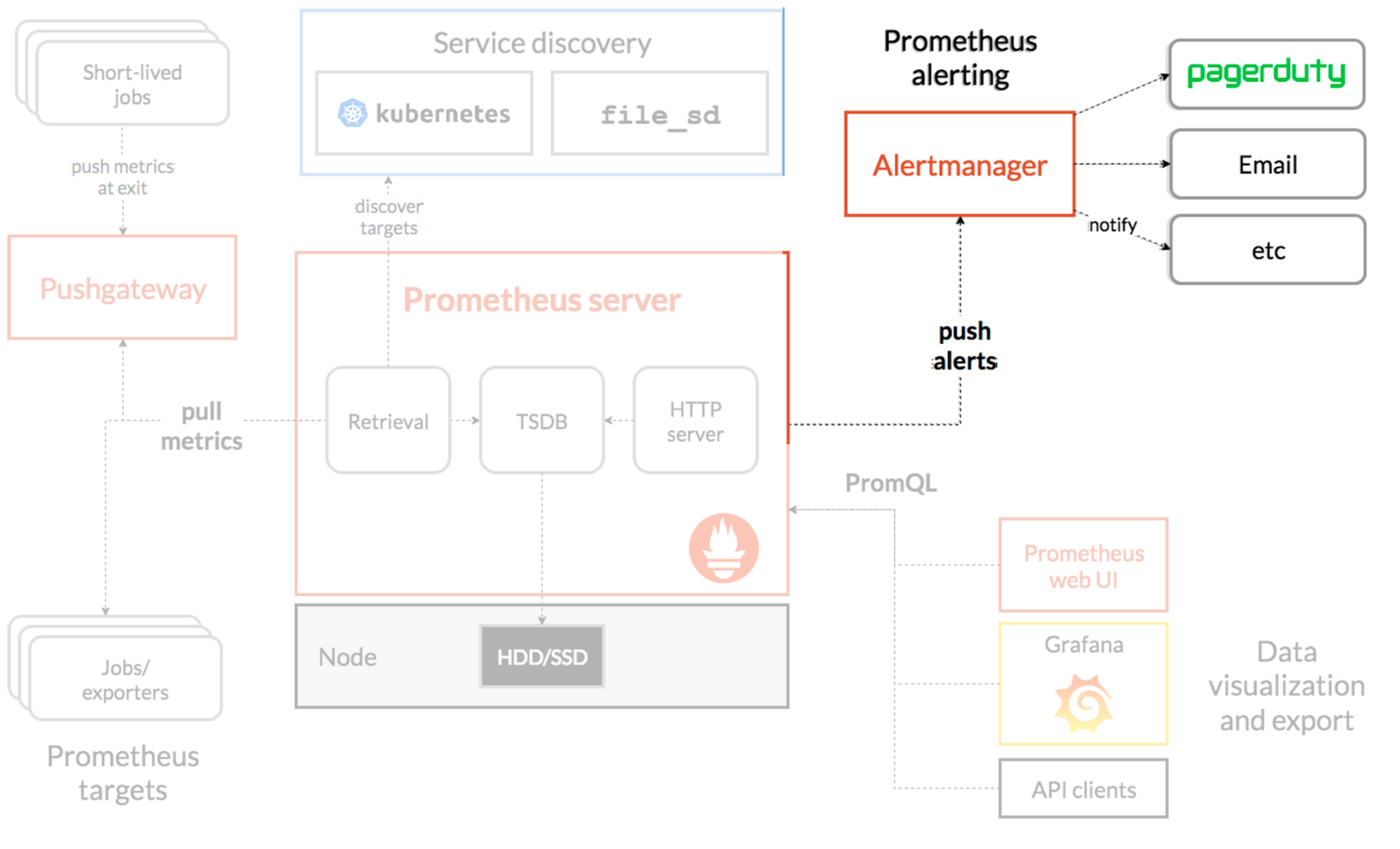
📌 Study Notes
👉 Step 01. 실습 환경 배포
✅ 프로메테우스 스택 설치
모니터링에 필요한 여러 요소를 단일 차트(스택)으로 제공하고 있습니다. ← 시각화(그라파나), 이벤트 메시지 정책(경고 임계값, 경고 수준) 등 - Helm
이를 이용하여 간편하게 관련된 리소스를 설치하여 운영할 수 있습니다.
# 사용 리전의 인증서 ARN 확인
CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
# 설치
kubectl create ns monitoring
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > ~/monitor-values.yaml
alertmanager:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- alertmanager.$KOPS_CLUSTER_NAME
paths:
- /*
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- grafana.$KOPS_CLUSTER_NAME
paths:
- /*
prometheus:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- prometheus.$KOPS_CLUSTER_NAME
paths:
- /*
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
EOT
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.0.0 --set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' -f monitor-values.yaml --namespace monitoring
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
helm list -n monitoring
kubectl get-all -n monitoring
kubectl get prometheus,alertmanager -n monitoring
kubectl get prometheusrule -n monitoring
kubectl get servicemonitors -n monitoring✅ 프로메테우스 기본 사용
모니터링 그래프 → 경고 Alert 클릭 확인
# 프로메테우스 ingress 도메인으로 웹 접속
echo -e "Prometheus Web URL = https://prometheus.$KOPS_CLUSTER_NAME"
# 웹 상단 주요 메뉴 설명
1. 경고(Alert) : 사전에 정의한 시스템 경고 정책(Prometheus Rules)에 대한 상황
2. 그래프(Graph) : 프로메테우스 자체 검색 언어 PromQL을 이용하여 메트릭 정보를 조회 -> 단순한 그래프 형태 조회
3. 상태(Status) : 경고 메시지 정책(Rules), 모니터링 대상(Targets) 등 다양한 프로메테우스 설정 내역을 확인
4. 도움말(Help)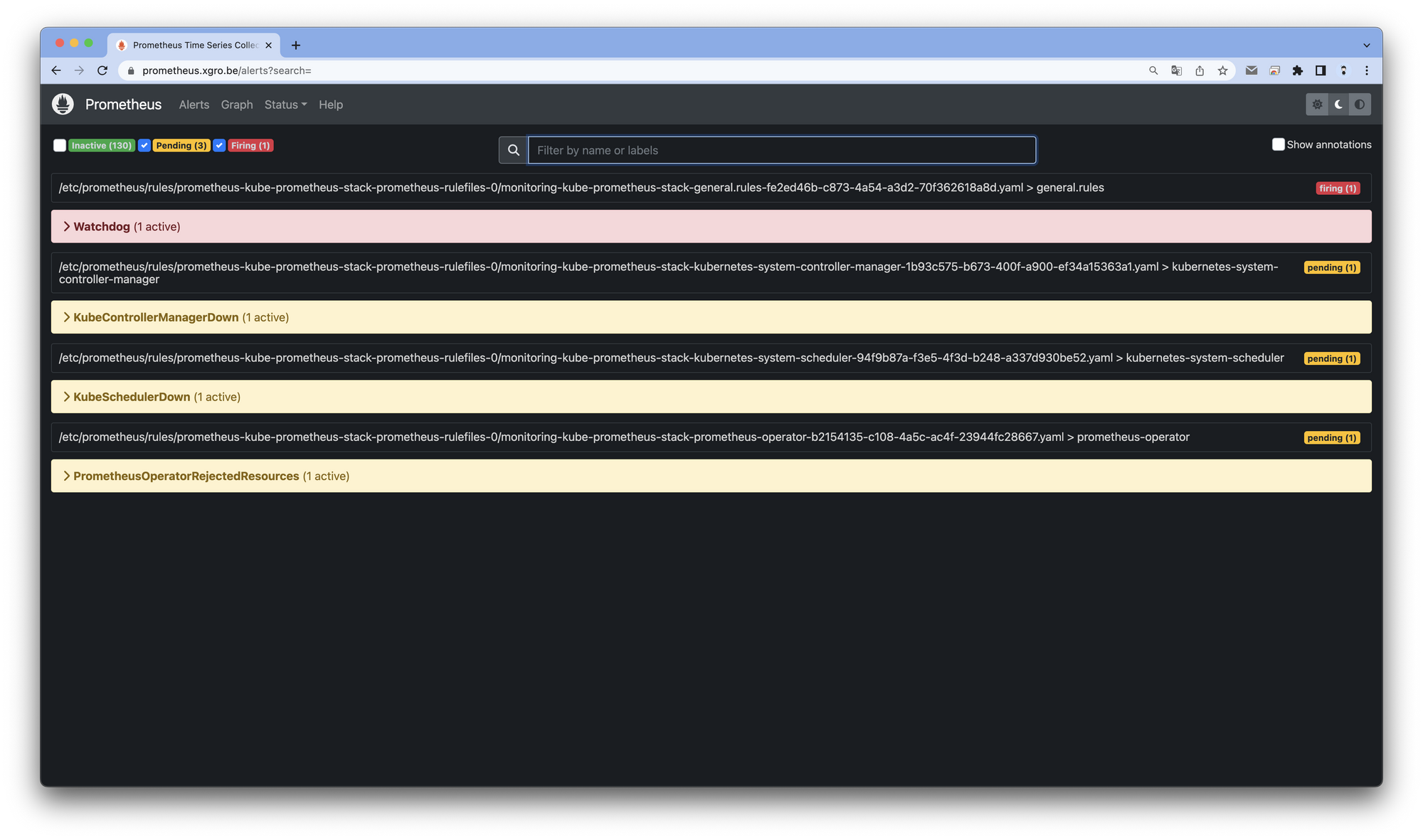
얼럿매니저 웹 접속 - 링크
- 얼럿매니저 웹 접속
# ingress 도메인으로 웹 접속
echo -e "Alertmanager Web URL = https://alertmanager.$KOPS_CLUSTER_NAME"
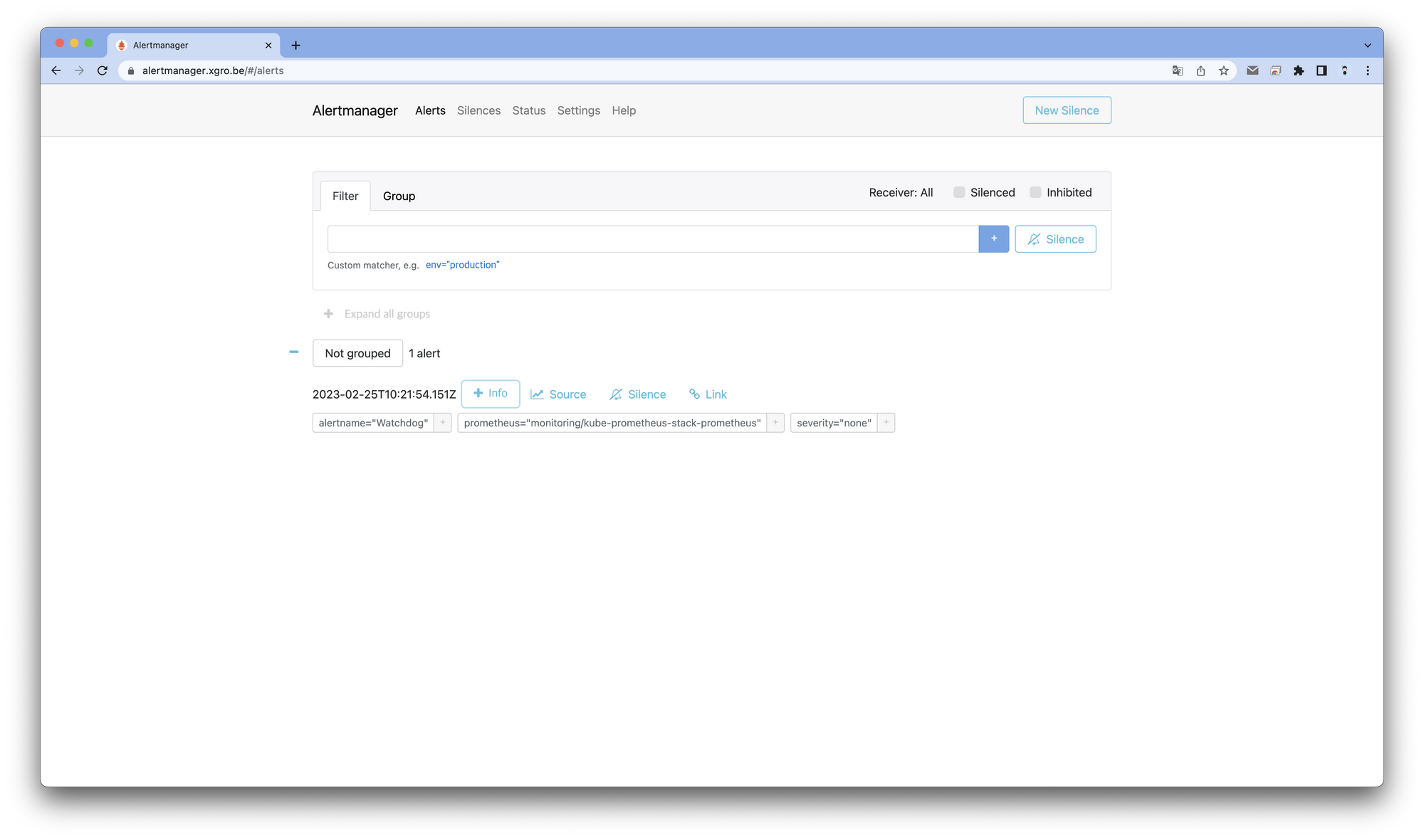
👉 Step 02. Alert Manager
✅ Alert Manager란?
Alertmanager는 Prometheus에서 전달된 경고 메시지를 가공한 후 이메일, 슬랙 등의 경보 채널로 전달하는 역할을 수행합니다. - 링크
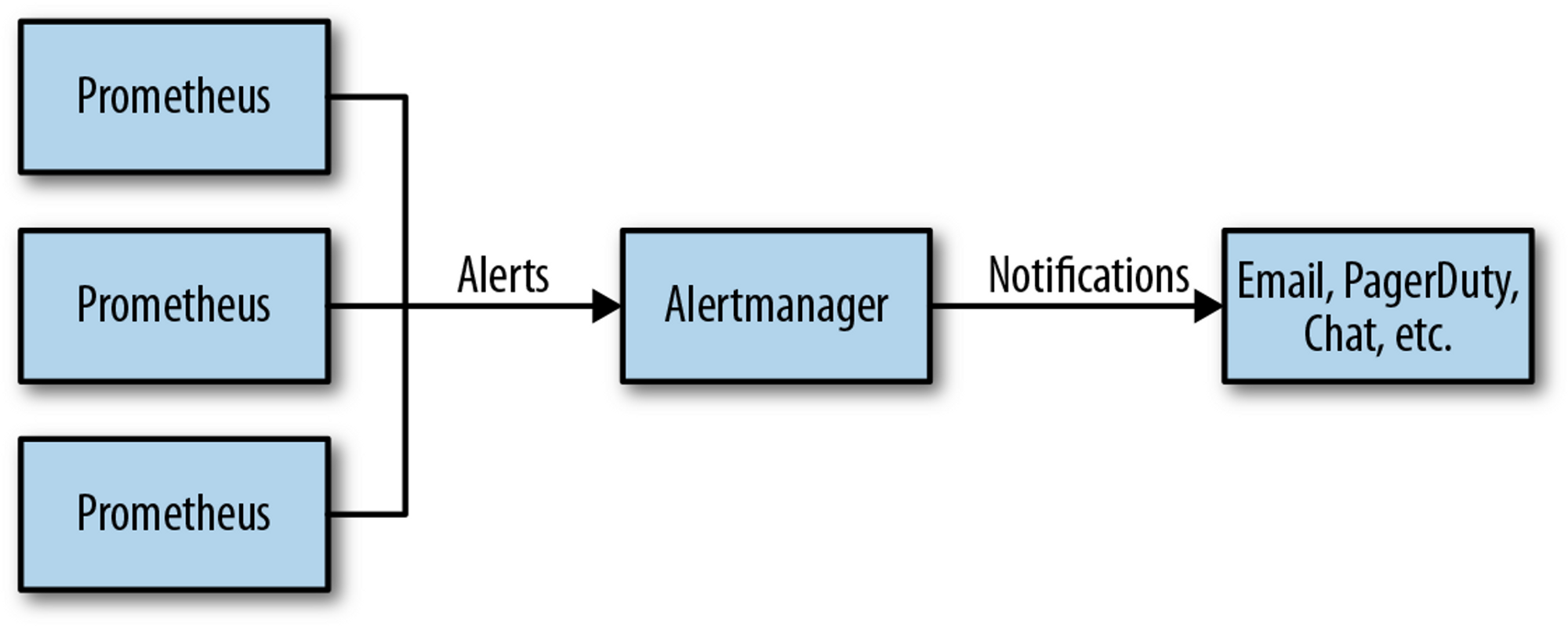
출처 - https://www.oreilly.com/library/view/prometheus-up/9781492034131/ch18.html
✅ Alert Manager의 특징
- Alert Manager는 Prometheus에서 발생한 Alert을 수집하고 관리합니다.
- 수집된 Alert은 Receiver로 전달되며, Receiver는 Alert을 해결합니다.
- Alert Manager는 수집된 Alert을 그룹화하고 중복 제거하며 간헐적 알림을 통해 관리할 수 있습니다.
- 알림 전달은 REST API, Email, Slack, PagerDuty를 통해 이루어집니다.
✅ Webhooks
슬랙 채널 및 웹훅 URL 생성 및 얼럿매니저 설정 적용 : 책 350~360페이지, 참고 - 링크
개인 Slack 워크스페이스의 Webhook 전용 채널을 생성하여 실습을 진행하였습니다.
# 웹훅 주소 적용
WEBHOOK='https://hooks.slack.com/services/T****'
# Alert Manager에 Webhook 정보 반영
cat <<EOT > ~/alertmanager-slack.yaml
alertmanager:
config:
global:
resolve_timeout: 5m
slack_api_url: 'https://hooks.slack.com/services/T****'
route:
group_by: ['job'] # namespace
group_wait: 10s
group_interval: 1m
repeat_interval: 5m
receiver: 'slack-notifications'
routes:
- receiver: 'slack-notifications'
matchers:
- alertname =~ "InfoInhibitor|Watchdog"
receivers:
- name: 'slack-notifications'
slack_configs:
- channel: '#webhook'
send_resolved: true
title: '[{{.Status | toUpper}}] {{ .CommonLabels.alertname }}'
text: |
*Description:* {{ .CommonAnnotations.description }}
EOT
# helm 업그레이드로 얼럿매니저에 웹훅 URL 정보 반영
helm upgrade kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.0.0 --reuse-values -f alertmanager-slack.yaml --namespace monitoring
# 반영 확인 : 얼럿매니저 설정 파일에 반영(config reload)
kubectl describe pod -n monitoring alertmanager-kube-prometheus-stack-alertmanager-0
kubectl exec -it -n monitoring alertmanager-kube-prometheus-stack-alertmanager-0 -- ls /etc/alertmanager/config
alertmanager.yaml.gz슬랙으로 경고메시지가 전달되는것을 확인할 수 있습니다
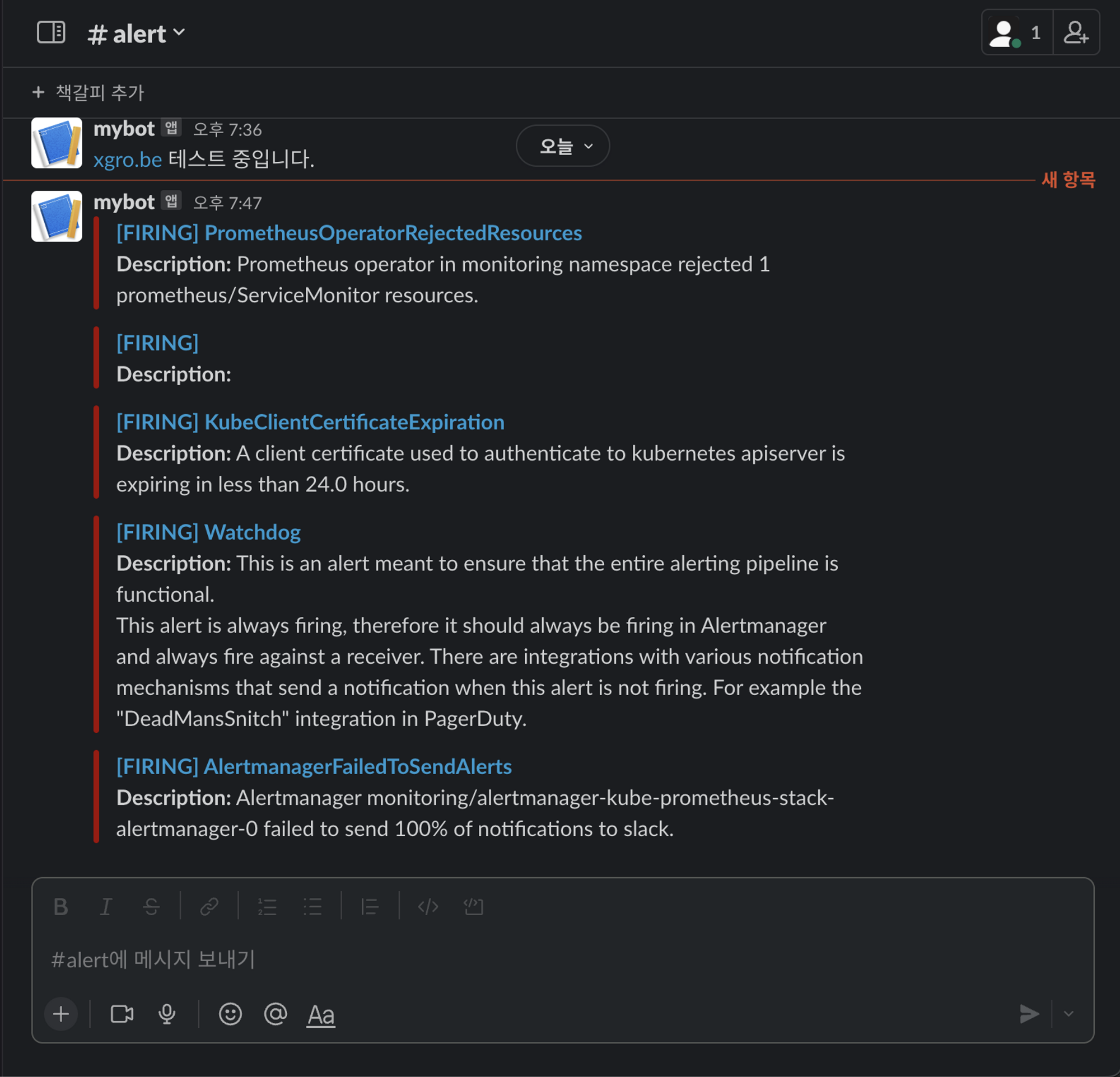
🚨 장애 재현
임의의 워커노드 1대를 선택하여, kubelet을 중지하고, 얼럿매니저 기능이 정상적으로 동작하는지 확인합니다.
# 워커노드 3번 kubelet 강제 중지
ssh -i ~/.ssh/id_rsa ubuntu@$WNODE3 sudo systemctl stop kubelet
ssh -i ~/.ssh/id_rsa ubuntu@$WNODE3 sudo systemctl status kubelet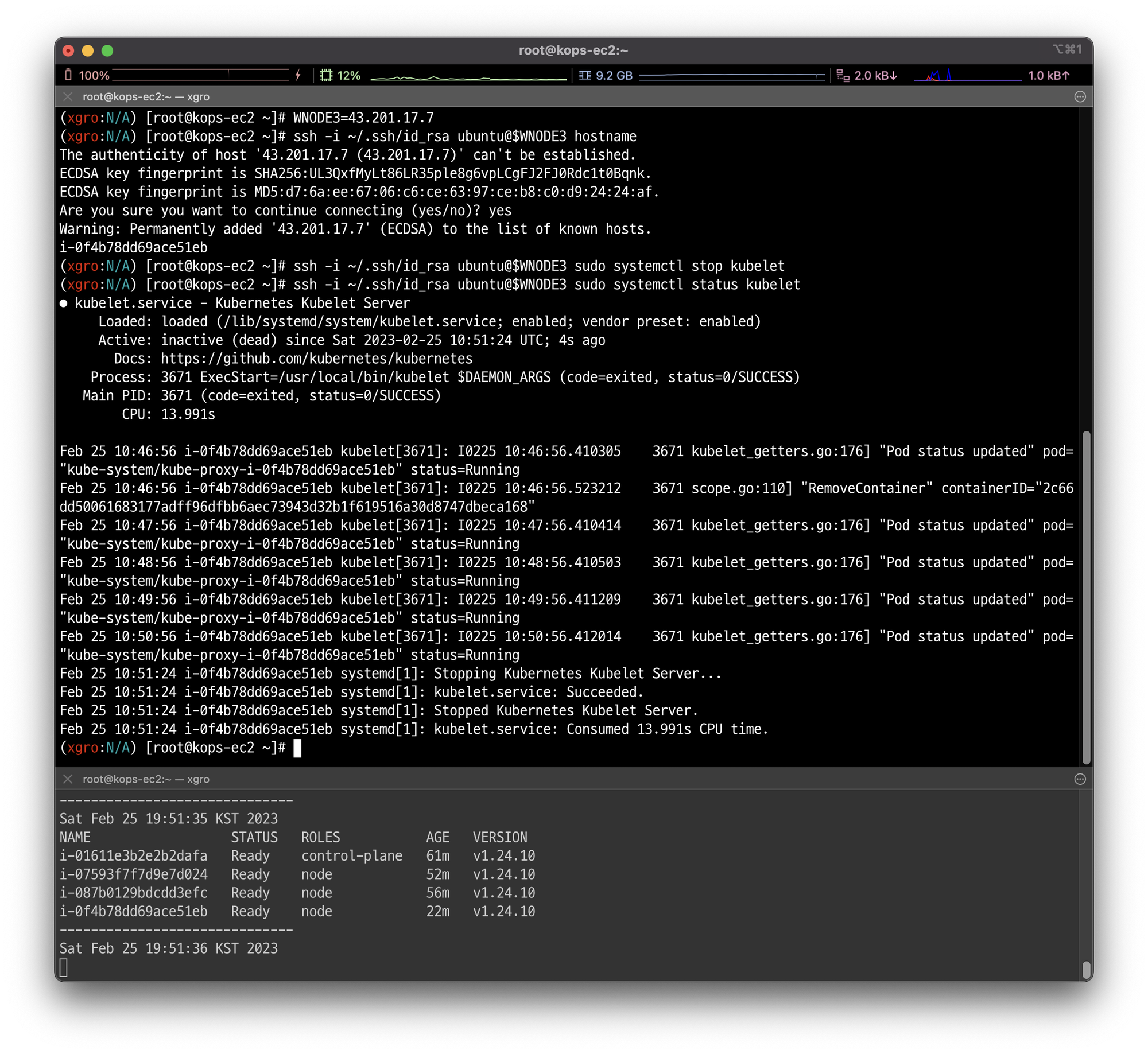
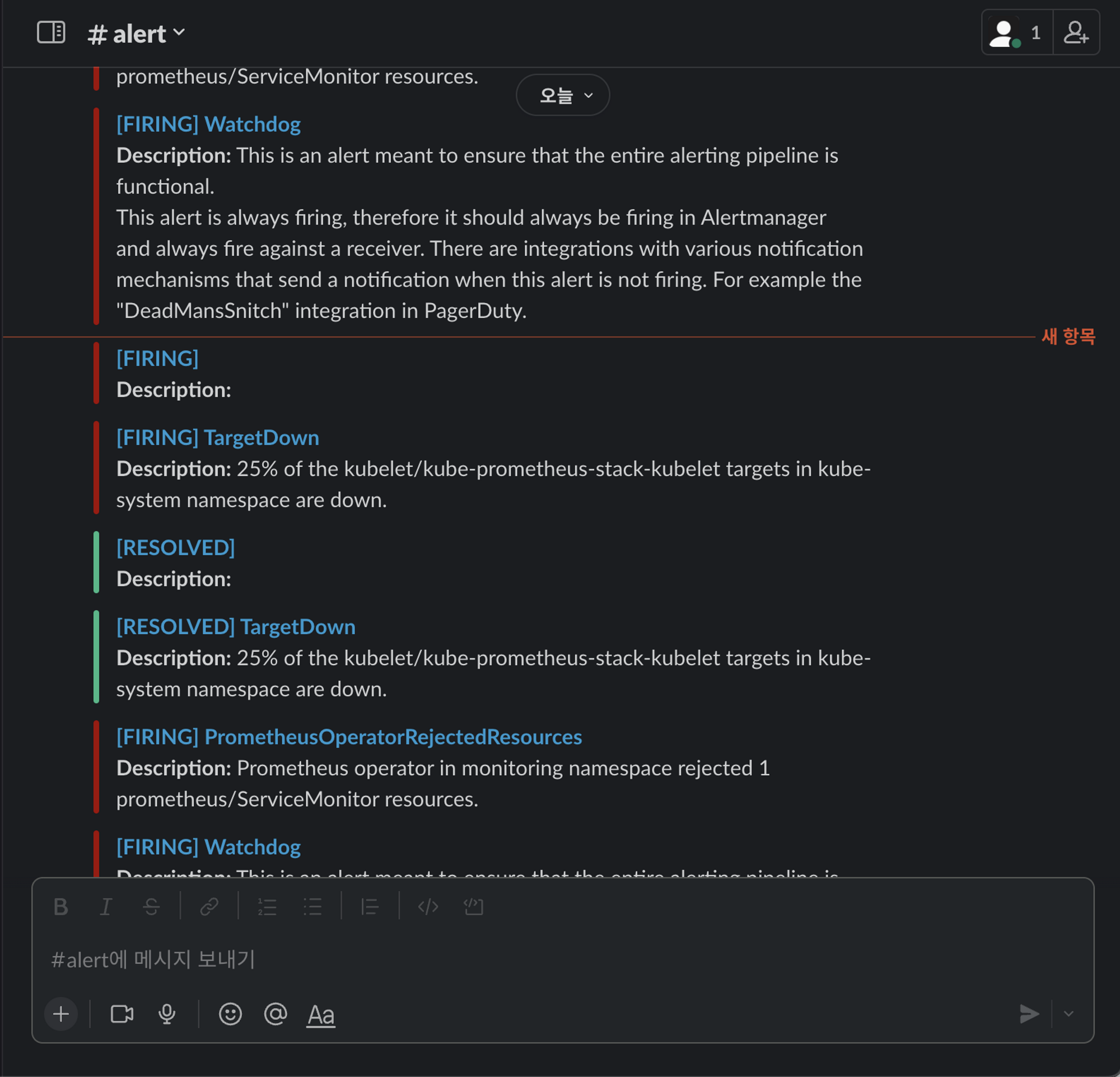
프로메테우스 Alerts(Pending 도 체크)에 TargetDown 항목으로 알람이 발생하는것을 확인할 수 있습니다.
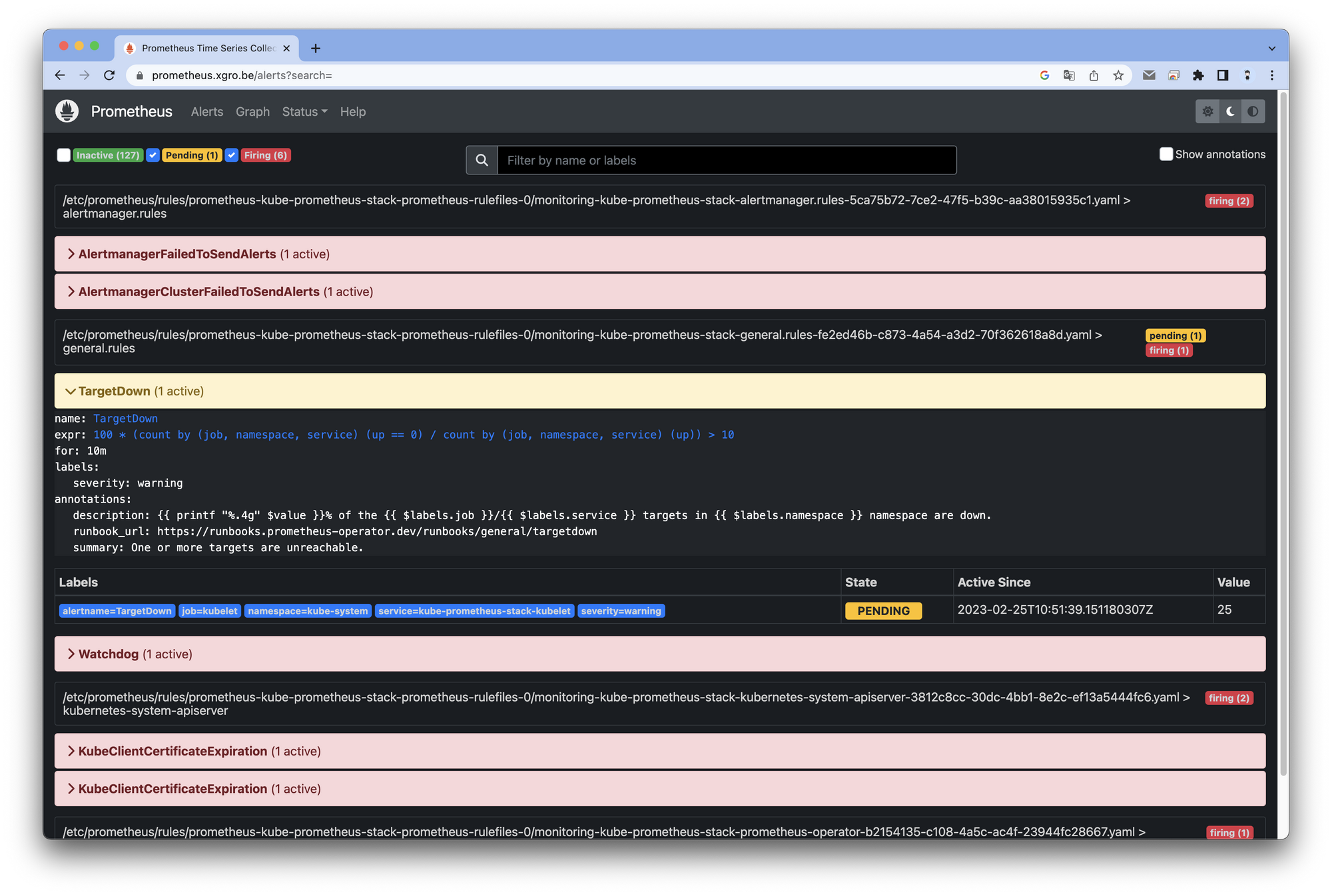
설정된 시간이 초과되면(10분) firing 상태가 되는것을 확인할 수 있습니다.
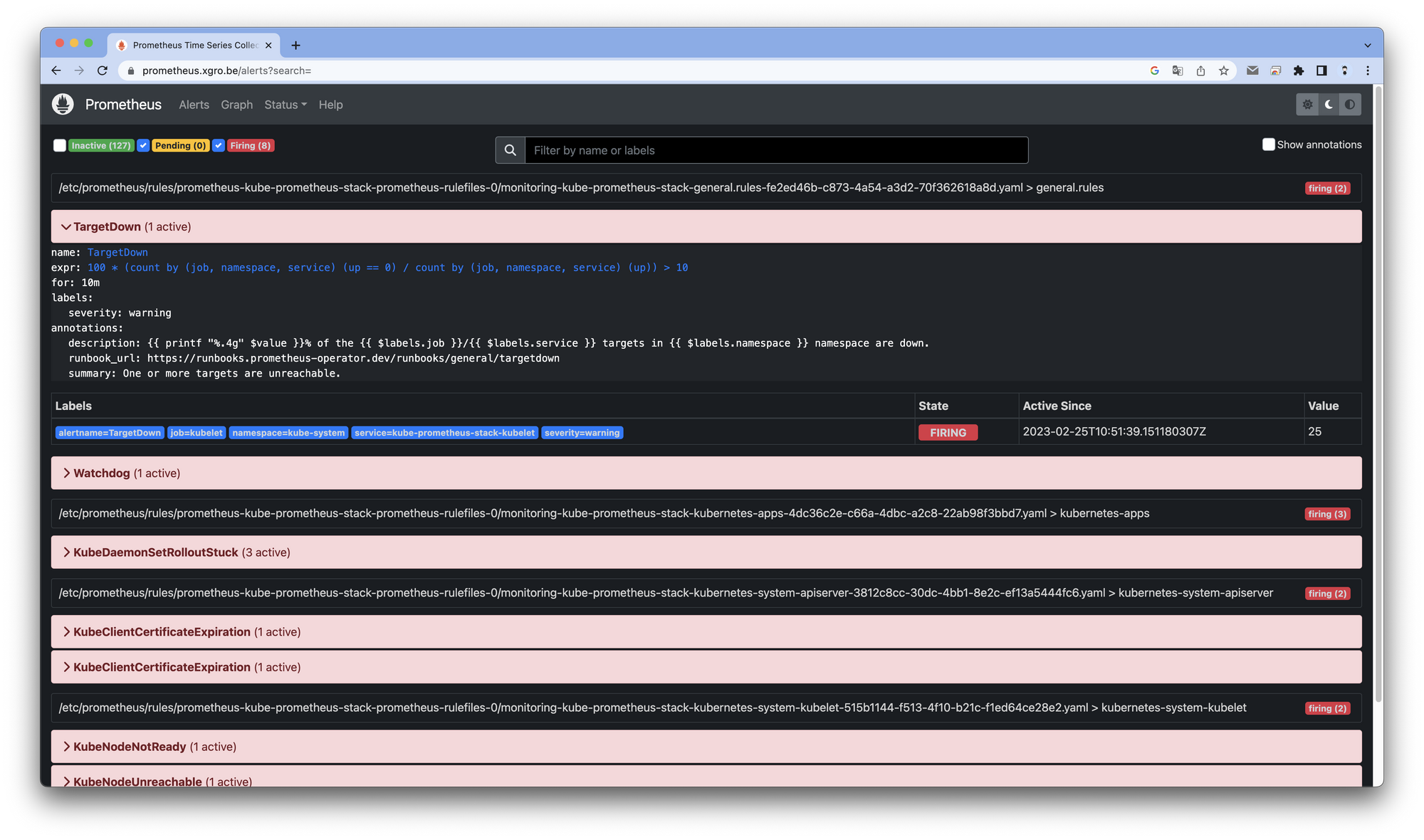
중지한 워커노드를 재시작 합니다.
# 워커노드 3번 kubelet 재시작
ssh -i ~/.ssh/id_rsa ubuntu@$WNODE3 sudo systemctl start kubelet
ssh -i ~/.ssh/id_rsa ubuntu@$WNODE3 sudo systemctl status kubelet워커노드가 정상 상태가 되면, 알람이 RESOLVED 되었다고 슬랙을 통해 확인할 수 있습니다.
👉 Step 03. PLG 스택
✅ PLG 스택이란?
PLG 스택은 아래와 같습니다.
- Prometheus: 모니터링 데이터 수집 및 저장
- Loki: 로그 수집 및 검색
- Grafana: 모니터링 대시보드
- Alertmanager: 알림 발송 및 관리

PLG 스택을 통해 아래와 같은 기능을 수행할 수 있습니다.
- 시스템 및 애플리케이션 metrics 수집
- 로그 수집 및 검색
- 대시보드를 통한 모니터링
- 알림 관리 및 발송
- 문제 진단을 위한 tracing
- 모니터링 데이터 저장 및 쿼리
- Dashboard를 통한 보고서 작성
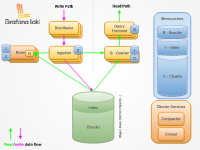
출처 - https://grafana.com/docs/loki/latest/fundamentals/architecture/components/
✅ Loki 설치
# 모니터링
kubectl create ns loki
watch kubectl get pod,pvc,svc,ingress -n loki
# Repo 추가
helm repo add grafana https://grafana.github.io/helm-charts
# 파라미터 설정 파일 생성
cat <<EOT > ~/loki-values.yaml
persistence:
enabled: true
size: 20Gi
serviceMonitor:
enabled: true
EOT
# 배포
helm install loki grafana/loki --version 2.16.0 -f loki-values.yaml --namespace loki
# 설치 확인 : 데몬셋, 스테이트풀셋, PVC 확인
helm list -n loki
kubectl get pod,pvc,svc,ds,sts -n loki
kubectl get-all -n loki
kubectl get servicemonitor -n loki
kubectl krew install df-pv && kubectl df-pv
# curl 테스트 용 파드 생성
kubectl apply -f ~/pkos/2/netshoot-2pods.yaml
# 로키 gateway 접속 확인
kubectl exec -it pod-1 -- curl -s http://loki.loki.svc:3100/api/prom/label
# (참고) 삭제 시
helm uninstall loki -n loki
kubectl delete pvc -n loki --all✅ Promtail 설치
Promtail은 데몬셋으로 실행되며 각 로그에 로그를 중앙 로키 서버에 전달, Promtail 외에도 도커, FluentD 등 다른 로그수집 에이전트 사용 할 수 있습니다.
# 파라미터 설정 파일 생성
cat <<EOT > ~/promtail-values.yaml
serviceMonitor:
enabled: true
config:
serverPort: 3101
clients:
- url: http://loki-headless:3100/loki/api/v1/push
#defaultVolumes:
# - name: pods
# hostPath:
# path: /var/log/pods
EOT
# 배포
helm install promtail grafana/promtail --version 6.0.0 -f promtail-values.yaml --namespace loki
# (참고) 파드 로그는 /var/log/pods에 저장
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME ls /var/log/pods
# 설치 확인 : 데몬셋, 스테이트풀셋, PVC 확인
helm list -n loki
kubectl get pod,pvc,svc,ds,sts,servicemonitor -n loki
kubectl get-all -n loki
# (참고) 삭제 시
helm uninstall promtail -n loki✅ Grafana에서 Loki 연동
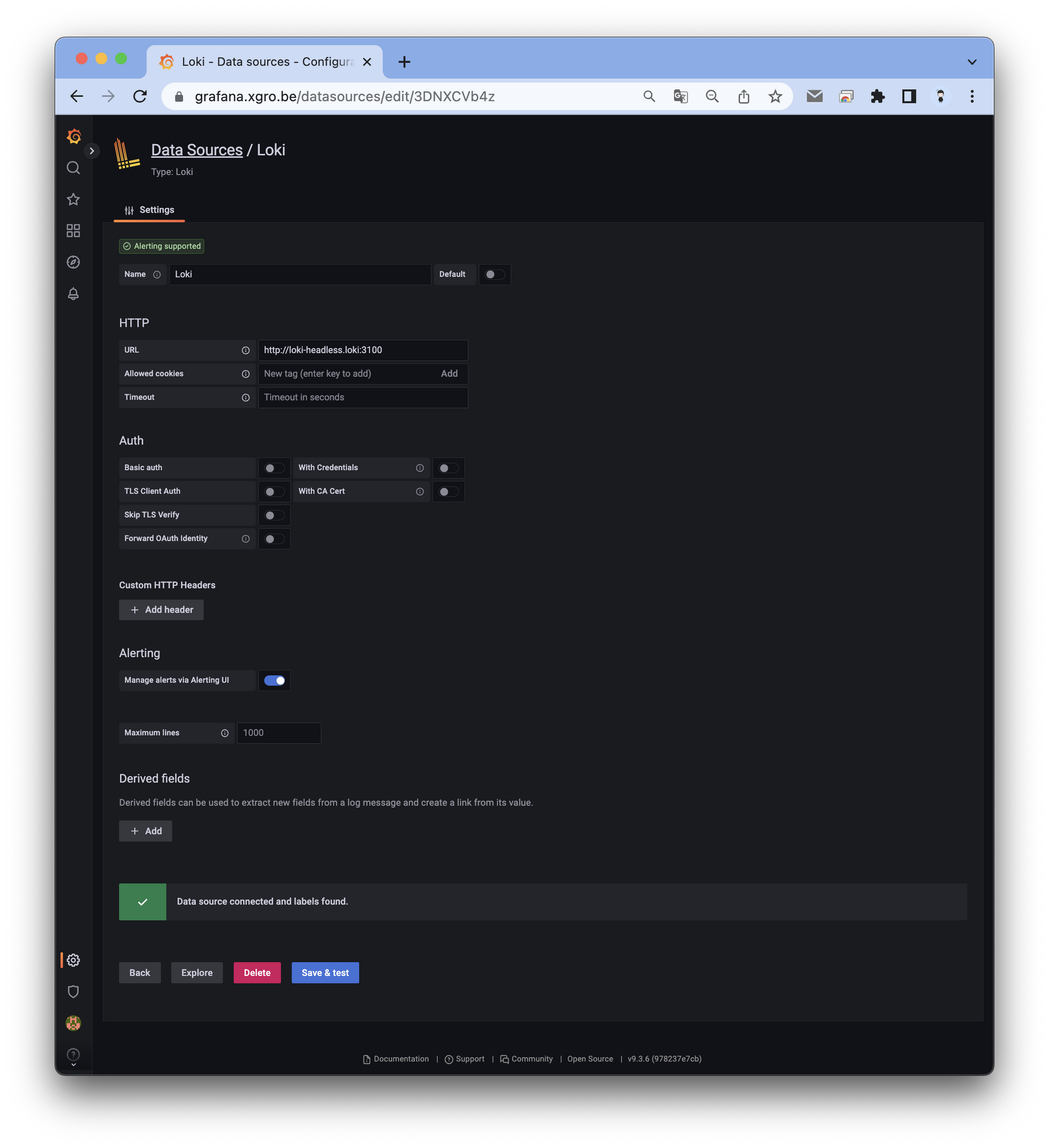
그라파나 → Configuration → Data Source : 데이터 소스 추가 ⇒ Loki 클릭
- HTTP URL : http://loki-headless.loki:3100 ⇒ Save & Test
👉 Step. 04 실습 진행(로그 확인)
Nginx 파드를 배포하여 실습을 진행하였습니다.
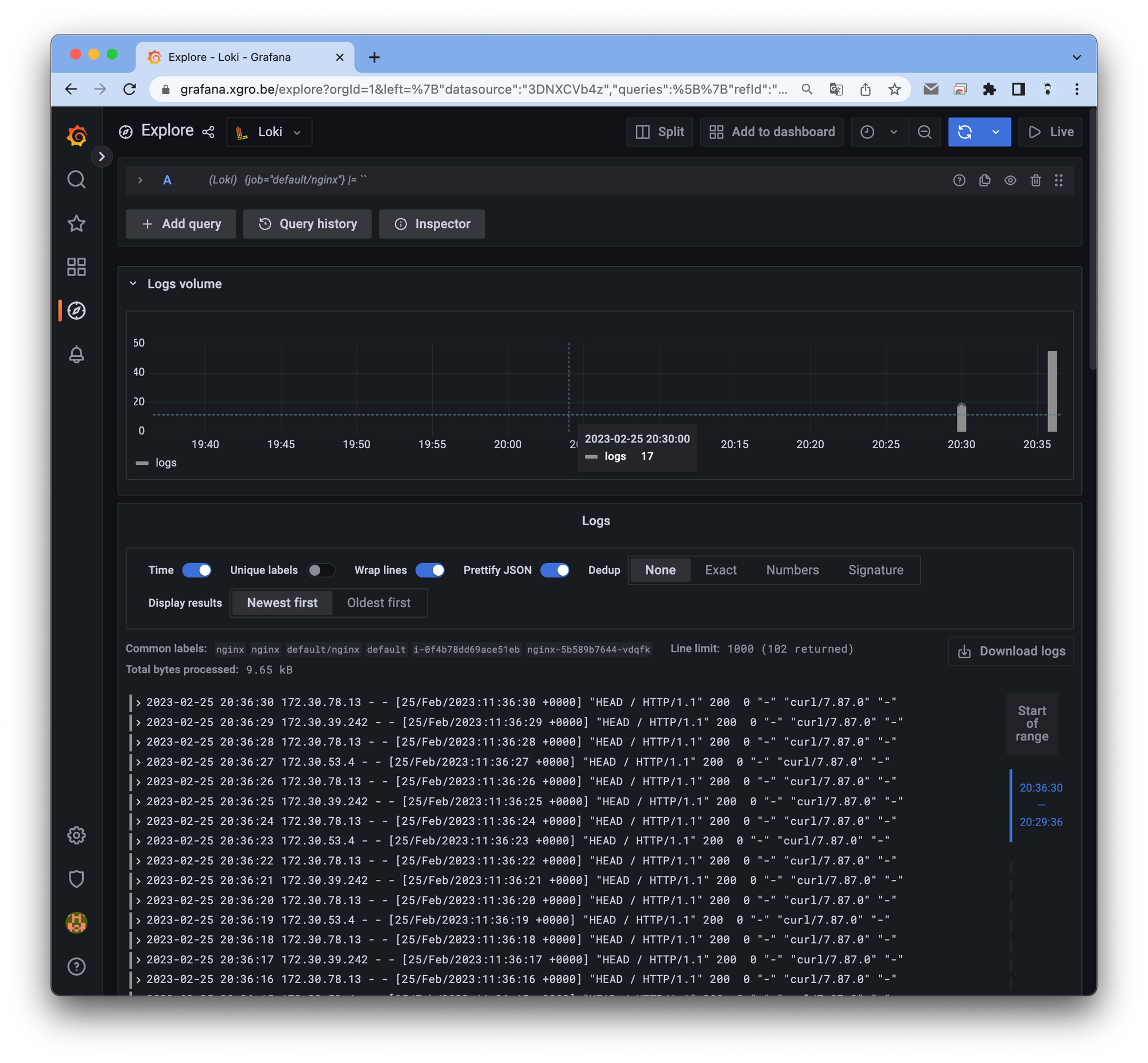
Explore 탭을 사용하여 간편하게 로그를 확인할 수 있습니다.
Logfilters: Job → default/nginx 값 선택 ⇒ 우측 상단 Run query 클릭
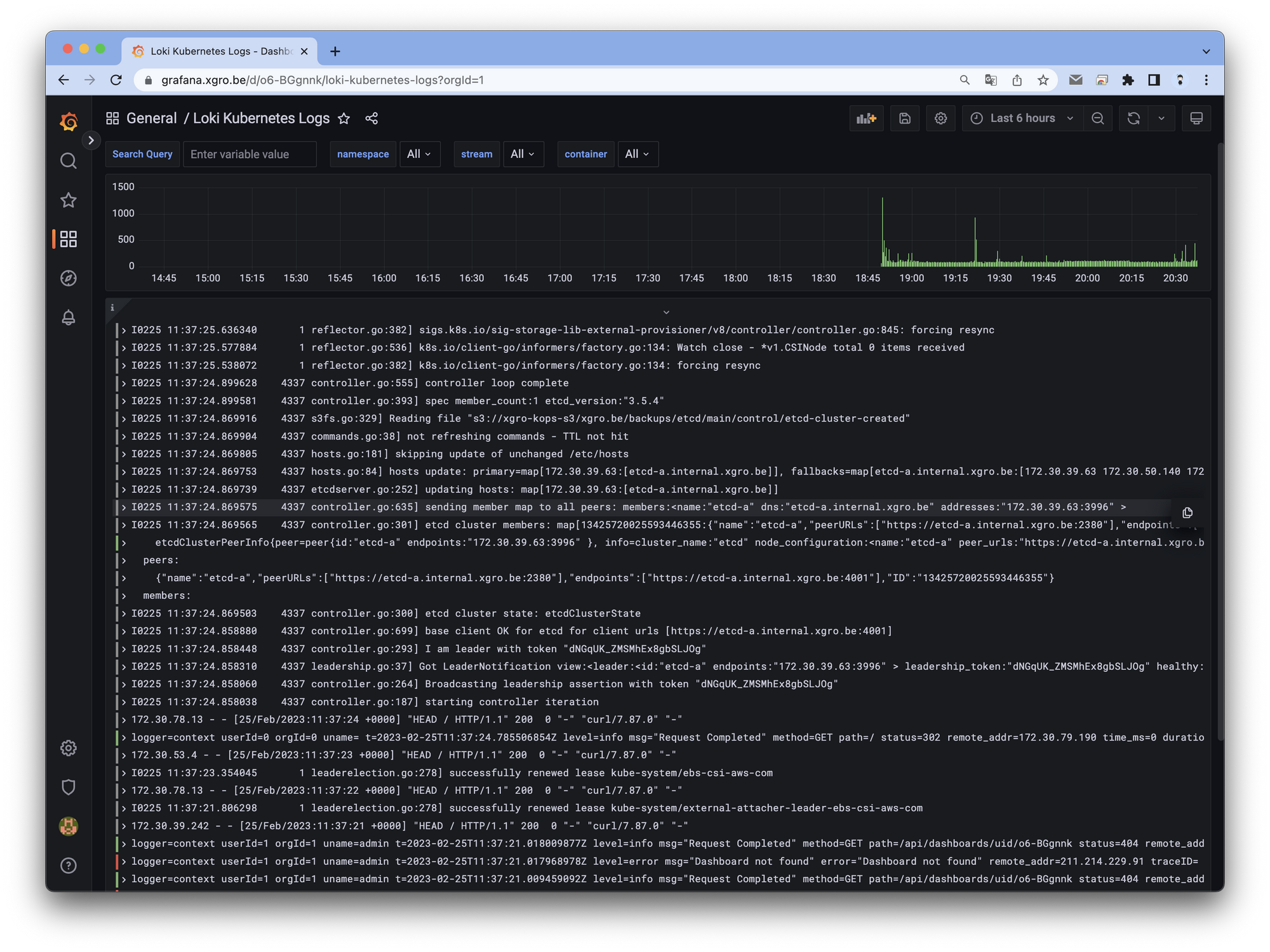
그라파나의 강력한 기능중 하나인 커스텀 대시보드를 이용하여 로그를 확인 할 수 있습니다.
- Loki 로그 확인 대시보드 : 15141
📌 Conclusion
5주차 내용이었던 Prometheus와 Grafana에 이어지는 내용인 Alert Manager에 대해서 스터디 하였습니다.
Kubernetes 로그 수집 및 관리 도구인 Loki를 설치하여 관리하고, 그라파나에서 Loki를 연동하여 로그를 확인하는 실습을 진행하였습니다.
로키 설치 및 로그 수집을 위한 Promtail 설치 후, 그라파나에서 로키를 데이터 소스로 추가하여 확인 할 수 있었습니다.
그라파나의 Explore 탭을 이용하여 간편하게 로그를 검색하고, 대시보드를 이용하여 로그를 가시적으로 확인 할 수 있었습니다.
로키는 로그를 중앙 집중화하여 저장 및 쿼리할 수 있는 오픈소스 도구로, 프로메테우스와 함께 모니터링 스택을 구성하는데 사용되고 있습니다.
📌 Reference
