📌 윈도우 함수
ㄴ 내가 가장 취약한 부분 😣😣
ㄴ group by랑 비슷
ㄴ 참고) https://dev.mysql.com/doc/refman/8.0/en/window-functions-usage.html
[1] 모양새
☑️ 함수(컬럼) OVER (PARTITION BY 칼럼 ORDER BY 칼럼)
-함수: SUM,AVG,COUNT
-PARTITION BY 는 Group By와 비슷
ㄴ 내가 어떤 것을 그룹으로 만들 것인지 그 기준이 되는 칼럼을 기재
ㄴ partition by , order by는 둘다 없어도 되고, 있을 때도 있고
[2] 집계 함수
☑️ MAX(컬럼) OVER (PARTITION BY 컬럼)
EX) 각 부서별로 가장 많이 버는 사람을 찾기
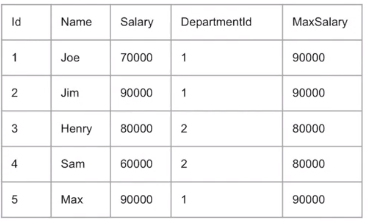
SELECT ID,NAME,SALARY,DEPARTMENTID,
MAX(SALARY) OVER (PARTITION BY DEPARTMENTID) AS MAXSALARY
FROM EMPLOYEE
*) GROUP BY 랑 다르게 원래 RAW 데이터 옆에 집계가 되어 나타남
*) Group BY의 결과는 1 90000
2 80000 이런식으로 나왔을 것☑️ SUM(컬럼) OVER (ORDER BY 칼럼)
ㄴ 누적합 구하기 (문제 출제 빈도 높다!)
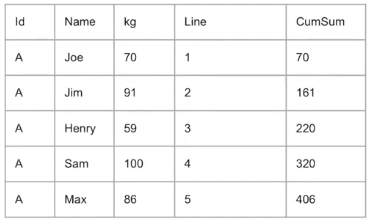
SELECT ID,NAME,KG,LINE,
-- 누적합을 구하게 됨
-- LINE의 순서대로 누적합을 구해주세요
SUM(KG) OVER (ORDER BY LINE) AS CUMSUM
FROM ELEVATOR
- 누적합을 구할 수 있는 케이스
1) 윈도우 함수 사용
2) 다른 방법 ☑️ SUM(컬럼) OVER (ORDER BY 칼럼 PARTITION BY 컬럼)
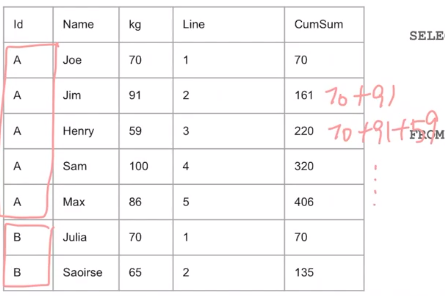
SELECT ID,NAME,KG,LINE,
-- 누적합 ID 별로 구하게 됨
-- Line B부터 새로 더함
SUM(KG) OVER (ORDER BY LINE PARTITON BY ID) AS CUMSUM
FROM ELEVATOR[3] 순위 정하기
☑️ ROW_NUMBER(), RANK(), DENSE_RANK()
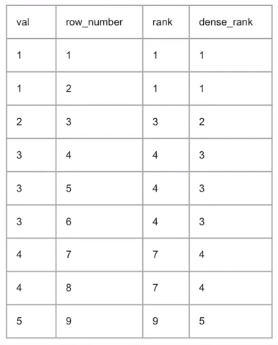
SELECT VAL,
-- 어떻게든 순서를 정해서 중복되는 순위는 없다
ROW_NUMBER() OVER (ORDER BY VAL) AS 'ROW_NUMBER',
-- VAL가 같을 때 같은 순위를 준다 / 1등이 있으면 2등은 없다.
RANK() OVER (ORDER BY VAL) AS 'RANK',
-- 1등이 두명 있어도, 2등이 있다
DENSE_RANK() OVER (ORDER BY VAL) AS 'RANK'
FROM SAMPLE[4] 데이터 위치 바꾸기
☑️ LEAD(), LAG()
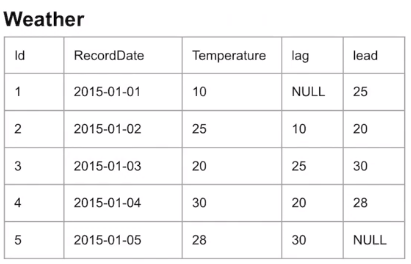
SELECT ID, RECORDATE, TEMPERATURE,
LAG(TEMPERATURE) OVER (ORDER BY RECORDDATE) AS 'LAG',
LEAD(TEMPERATURE) OVER (ORDER BY RECORDDATE) AS 'LEAD'
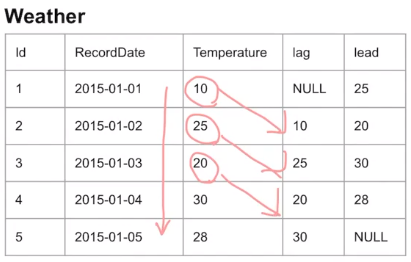
FROM SAMPLE-LAG (한칸씩 뒤로 밀림)
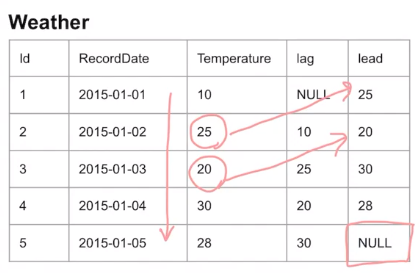
-LEAD (뒤에 있는 데이터를 앞으로 댕겨옴)
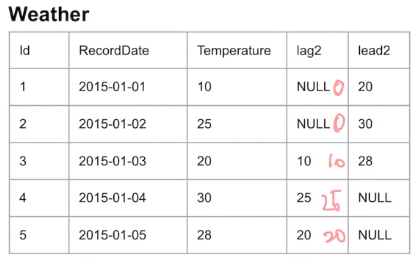
-옵션을 줄수도 있음

-LAG(TEMPERATURE,2,0)
ㄴ여기서 '0'은 디폴트값, 그래서 NULL 대신 0 삽입

안녕하세요 IT 그로스 마케터입니다.