SUBQUERY
1) FROM 절 서브쿼리
- 가상의 테이블을 하나 더 만든다.
EX) 이 테이블을 이용해 각 주의 평균 범죄 발생율을 count해보세요.
CRIMES 테이블
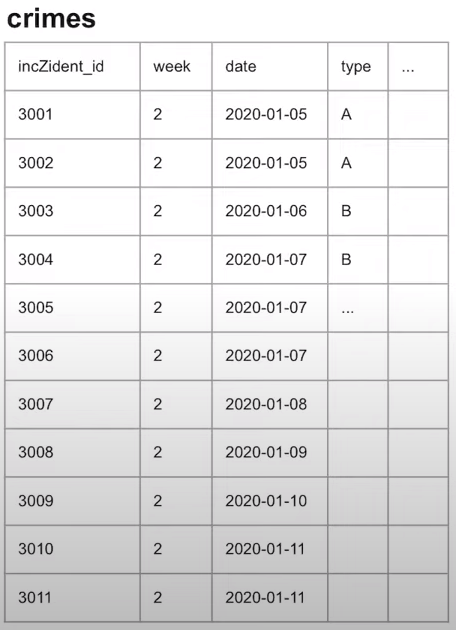
SELECT DAILY_STATUS.WEEK, AVG(DAILY.STATUS.INCIDENTS_DAILY)
FROM
(SELECT WEEK,DATE,COUNT(INCIDENT_ID) AS INCIDENTS DAILY
FROM CRIMES
GROUP BY WEEK,DATE
) DAILY_STATUS
GROUP BY DAILY_STATUS.WEEK* 집계함수 사용 시 주의점 > 데이터가 null 일 때 0은 집계가 안되기 때문에 주의!
(특히 평균 함수, 날짜 함수 사용 시)
2) WHERE 절 서브쿼리
예제) 가장 빠른 날짜를 구해라
SEELCT *
FROM CRIMES
WHERE date = ( SELECT MIN(date) FROM crimes) > 요 서브쿼리의 결과물은 반드시 1개 여야함
만약 서브쿼리 결과물이 여러개이고, 한번에 보고 싶을 땐? > IN OR OR 함수
SEELCT *
FROM CRIMES
WEHER date IN (SELECT date FROM crimes ORDER BY date DESC LIMIT 5)
> 최신 date를 기준으로 해서, 최신 데이터 5개를 가지고 와서 그것의 날짜가 들어갔을 때 보여줘라
> 서브 쿼리의 결과물이 1개 이상이여도 괜찮음
3) 문제풀이
✔️HACKERRANK - Top Earners
Write a query to find the maximum total earnings for all employees as well as the total number of employees who have maximum total earnings. Then print these values as space-separated integers.
[내가 작성한 답안] 정답!
SELECT EARNINGS, COUNT(EMPLOYEE_ID)
FROM (
SELECT EMPLOYEE_ID, NAME, SALARY*MONTHS AS EARNINGS
FROM EMPLOYEE
ORDER BY EARNINGS DESC ) E
GROUP BY EARNINGS
ORDER BY EARNINGS DESC
LIMIT 1;
[풀이] 1) WHERE절 서브쿼리
SELECT MONTHS * SALARY AS earnings , COUNT(*)
FROM EMPLOYEE
WHERE MONTHS * SALARY = (SELECT MAX(MONTHS*SALARY) FROM EMPLOYEE)
GROUP BY EARNINGS
--참고로 SELECT 절 ALIAS는 WHERE절에서는 사용하지 못하고 GROUP BY 절에서는 이용 가능!
[플이] 2) HAVING절 서브쿼리
SELECT MONTHS * SALARY AS earnings , COUNT(*)
FROM EMPLOYEE
GROUP BY EARNINGS
HAVING EARNINGS = (SELECT MAX(MONTHS*SALARY) FROM EMPLOYEE)
✔️184. Department Highest Salary
Write an SQL query to find employees who have the highest salary in each of the departments.
Input:
Employee table:
+----+-------+--------+--------------+
| id | name | salary | departmentId |
+----+-------+--------+--------------+
| 1 | Joe | 70000 | 1 |
| 2 | Jim | 90000 | 1 |
| 3 | Henry | 80000 | 2 |
| 4 | Sam | 60000 | 2 |
| 5 | Max | 90000 | 1 |
+----+-------+--------+--------------+
Department table:
+----+-------+
| id | name |
+----+-------+
| 1 | IT |
| 2 | Sales |
+----+-------+
Output:
+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Jim | 90000 |
| Sales | Henry | 80000 |
| IT | Max | 90000 |
+------------+----------+--------+[내가 작성한 답 - 오답]
SELECT D.NAME AS Department, E.NAME AS Employee, E.SALARY AS Salary
FROM (
SELECT *
FROM EMPLOYEE
WHERE SALARY = (SELECT MAX(SALARY) FROM EMPLOYEE)
GROUP BY DEPARTMENTID ) E
INNER JOIN DEPARTMENT D ON E.DEPARTMENTID = D.ID
[결과]
| Department | Employee | Salary |
| ---------- | -------- | ------ |
| IT | Jim | 90000 |
ㄴ 의문점)) 왜 부서별로 안나오지?
[정답]
SELECT d.name AS department
, e.name AS employee
, e.salary
from employee AS e
inner join (
--1) 부서에서 가장 많이 벌 때에 그 임금과 부서 id
SELECT departmentid, MAX(salary) AS max_salary
FROM employee
GROUP BY departmentid
) AS dh
ON e.departmentid = dh.departmentid
AND e.salary = dh.max_salary
--2)부서별로 가장 연봉이 높은 데이터만 추려서 나옴
INNER JOIN department AS d ON d.id= e.departmentid
--3)부서이름을 출력하기 위해 이너조인☑️ 오답노트1)) 부서별로 연봉이 높은 ID,SALARY 추출
<내가 작성한 오답>
SELECT DEPARTMENTID, SALARY
FROM EMPLOYEE
WHERE SALARY = (SELECT MAX(SALARY) FROM EMPLOYEE)
GROUP BY DEPARTMENTID
[Output]
| DEPARTMENTID | SALARY |
| ------------ | ------ |
| 1 | 90000 |
ㄴ 이건 조건절이여서 가장 높은 연봉의 ID와 SALARY를 추출
<정답>
SELECT departmentid, MAX(salary) AS max_salary
FROM employee
GROUP BY departmentid
[Output]
| departmentid | max_salary |
| ------------ | ---------- |
| 1 | 90000 |
| 2 | 80000 |
☑️ 오답노트2)) ON절을 조건식으로 사용하자!

안녕하세요 IT 그로스 마케터입니다.