B-Tree 인덱스
탐색 성능을 높이기 위해 균형 있게 높이를 유지하는 자료구조. (Balanced Tree)
특징
- OTLP(실시간으로 데이터 입력과 수정이 일어나는 환경)에 적합하다.
구조
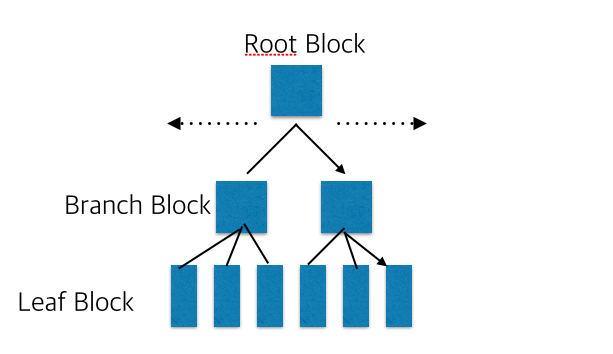
트리 구조의 최상위에 하나의 루트 블록을 가지며, 그 하위에 노드가 붙어있는데 이 노드 중 가장 하위에 있는 노드를 리프 블록이라고 하며 루트 블록과 리프 블록 사이에 존재하는 블록을 브랜치 블록이라고 한다.
리프 블록
-
리프블록은 아래 두 개의 데이터로 이루어져 있으며
-
인덱스를 구성하는 칼럼의 데이터
-
해당 데이터를 가지고 있는 행의 위치를 가리키는 ROWID
리프 블록끼리는 이중연결 리스트 구조로 연결되어있다.
-
-
리프 블록의 각 로우와 테이블 로우 간에는 1:1 관계이고, 각 로우의 키 값과 각 테이블 로우의 키 값은 서로 일치한다.
-
리프 블록의 각 로우는 테이블 로우에 대한 주소걊을 갖는다.
-
브랜치 블록의 각 로우의 키 값은 하위 블록이 갖는 값의 범위를 의미하며, 각 로우는 하위 블록에 대한 주소값을 갖는다. 따라서 하위 블록 첫 번째 로우의 키 값과 일치하지 않을 수 있다.
비트맵 인덱스
비트르 이용하여 컬럼 값을 저장하고, ROWID를 자동으로 생성하는 인덱스이다. 비트를 직접 관리하여 저장공간이 크게 감소하고, 비트연산을 수행할 수 있다.
Start Rowid와 End Rowid 의 Range 사이에 있는 모든 row 수 만큼 비트맵이 표현되어야 하지만, 오라클에서는 내부적인 압축 알고리즘을 사용하여 비트맵을 생성하기 때문에 모두 표현되지 않는 경우도 있다.
비트맵 인덱스 또한 B-Tree 처럼 조직되어 있으나, 리프 노드는 ROWID 값 대신에 각 키 값에 대한 비트맵을 저장한다.
활용
- 비트맵 인덱스는 Distinct Value 개수가 적을 때 저장효율이 매우 좋으며, 그런 칼럼이라면 B-Tree 인덱스보다 훨씬 적은 용량을 차지하므로 인덱스가 여러 개 필요한 대용량 테이블에 유용하다.
- 주로 다양한 분석관점을 가진 팩트성 테이블이 여기에 속하며, 오히려 Distinct Value가 많을수록 B-Tree 인덱스보다 많은 저장공간을 차지한다.
B-Tree인덱스, 비트맵 인덱스 비교
| B-tree 인덱스 | 비트맵 인덱스 |
|---|---|
| 큰 분포도(Cardinality)를 갖는 테이블에 적합 | 적은 분포도를 갖는 테이블에 적합 |
| 비교적 키의 갱신 비용이 적음 | 갱신 비용이 매우 큼 |
| OR사용 Query문에 비 효율적 | OR사용 Query문에 효율적 |
| OLTP에 유용 | DSS에 유용 |
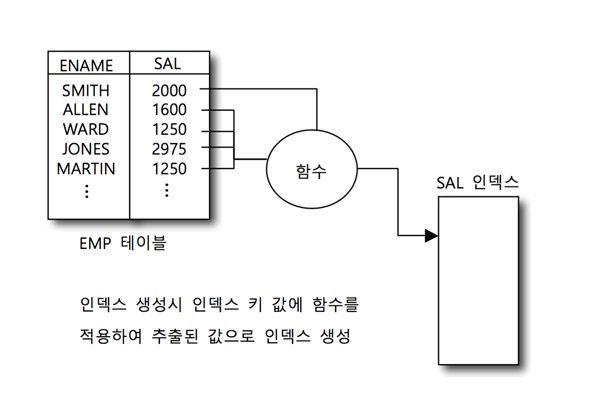
함수 기반 인덱스
8i이후 도입된 인덱스 방식. 테이블의 칼럼들을 가공한 값으로 인덱스를 생성한다.
alter session set QUERY_REWRITE_ENABLE = TRUE;
alter session set QUERY_REWRITE_INTERGRITY = TRUSTED;
grant query rewrite to scott;배경
쿼리문 작성 시 칼럼이 가공되면(SUBSTR , NVL 등) 인덱스가 존재하여도 인덱스를 통한 작업을 수행할 수 없었다. 이러한 문제를 해결하기 위해 오라클 8i부터 함수기반 인덱스를 지원하기 시작했다.
함수기반 인덱스 설정 시 필요한 전제조건
- Compatible=8.1.0 이상
- QUERY_REWRITE_ENABLE = TRUE
- QUERY_REWRITE_INTERGRITY = TRUSTED
- 해당 데이터베이스 유저에게 QUERY REWRITE 시스템 권한 필요
제약사항
- 비용기반 옵티마이저에서만 사용 가능
- 생성 이후 반드시 통계정보 생성
- 사용자지정함수는 반드시 DETERMINISTIC으로 선언되어야함.
- 함수나 수식의 결과가 NULL인 경우, 이 인덱스를 통해 액세스 x(이는 다른 인덱스도 마찬가지)
- 사용자 지정함수 사용시 종속성 유지에 주의
- 파티션 적용 시 파티션 키를 함수기반 인덱스에 사용 불가
- 스칼라 서브쿼리로 표현된 컬럼은 함수기반 인덱스 사용 불가
장점
함수 사용하여 인덱스를 이용할 수 있다. 그렇기에 SQL의 계산 값이 중요한 업무일 시 함수 기반 인덱스를 통해 성능을 향상시킬 수 있다.
단점
- DML에 대한 성능 저하가 발생한다.
- 인덱스의 유연성이 저하된다.
사용 예시
CREATE OR REPLACE FUNCTION GET_COL3(v_key1 VARCHAR2)
RETURN VARCHAR2 IS RES_COL3 VRCHAR2(8);
BEGIN
SELECT COL3 INTO RES_COL3
FROM TAB2
WHERE KEY = v_key1;
RETURN RES_COL3;
END GET_COL3;
CREATE INDEX COL1_COL3_IDX ON TAB1(COL1,GET_COL3(KEY));리버스 키 인덱스
B-Tree 인덱스는 인덱스값이 순차적으로 증가할 경우, 가장 우측의 리프 블록에만 삽입이 발생하게되어 경합이 증가하게 된다. 이러한 이유로 리버스 키 인덱스가 고안되었다.
구조는 B-Tree 인덱스와 동일하며, 단지 기존 데이터의 값을 역으로 하여 인덱스 키 값으로 사용한다. (ex. 12345 → 54321로 저장)
특징
- B-Tree 인덱스와 구조 동일
- 인덱스 키 값에 대해 역으로 구성한다.
- 인덱스 범위 스캔이 불가능하다.
- 우츨 리프블록 경합을 방지할 수 있다.
우측 리프 블록 경합 방지
B-Tree 인덱스의 값이 순차적으로 증가할 경우, 지속적으로 우측 리프 블록으로만 데이터가 증가된다. 그렇기에 우측 리프 블록에 대한 경합이 자주 발생한다. 만면, 리버스 키 인덱스는 인덱스 값이 순차적으로 증가한다 하더라도 모든 인덱스 블록으로 값이 추가되게 된다.
