1 BeatifulSoup로 HTML 소스 파싱하기(데이터로 변환하기)
- requests로 들고온 HTML 소스를 파이썬 코드로 접근할 수 있는 형태로 파싱한다.
- BeautifulSoup: 복잡하게 작성된 HTML 문서를 구조화된 데이터 형태로 바꾸는 패키지.
- 파싱(Parsing): 주어진 데이터(파일, 문자열 등)을 분석하여 그 구조를 이해하고, 필요한 정보를 추출하거나 다른 형식으로 변환하는 과정. 특히 텍스트 데이터를 처리한다.
- 파서(Parser): 파싱을 하는 기계. 컴퓨터 과학 및 프로그래밍에서 사용되는 개념으로, 특정 형식의 데이터를 읽고 해석하는 프로그램이나 모듈을 가리킨다. 파서는 일련의 입력 데이터를 가져와서 문법적으로 해석하고 이를 프로그램이나 다른 형태의 데이터로 변환한다.
from bs4 import BeautifulSoup
soup = BeautifulSoup(res,text, 'html.parser')
print(soup.prettify())BeautifulSoup(html, 'html.parser'): html 문자열 객체를 받아서, BeautifulSoup 객체로 바꾼다. 이를 파싱이라 한다. BeautifulSoup 객체는 Python의 복잡한 HTML/XML 문서를 파싱하고, 그걸 탐색하기 위한 다양한 메서드랑 속성을 제공한다.res.text: 여기서 res를 그대로 넣으면 안들어간다. res는 requests의 Response 클래스 객체(urllib의 Request에서 urlopen을 했으면 HTTPResponse 객체). BeautifulSoup는 HTML/XML 문서의 string 혹은 byte string객체를 받아서, 파싱하는 함수다.res.text로 HTML의 본문을 string 타입 객체로 추출해서 집어넣는다.html.parser은 BeautifulSoup에서 사용되는 파싱 방식을 지정하는 인자. html.parser은 Python 표준 라이브러리에 내장된 HTML 파서. 보다 빠른 파싱이나 복잡한 HTML 문서 처리하려면, lxml, html5lib 같은 외부 파서 선택할 수도 있다.soup.prettify(): .prettify() 메서드는 파싱된 HTML 또는 XML 문서를 보기 좋게(가독성 있게) 포맷팅된 형태로 반환한다. 들여쓰기를 포함해 이 HTML/XML 코드를 보기 좋게 출력.
2 BeautifulSoup 객체에서 원하는 요소 추출
.find(): BeautifulSoup 객체, Tag 객체에 사용 가능. 태그 이름, 속성, 문자열 등을 기준으로 검색. 주어진 조건에 맞는 요소를 찾아서, 첫 번째로 찾아진 요소를 반환. 일치하는 요소 없으면 None 반환.
반환되는 타입은 bs4.element.Tag..find_all(): BeautifulSoup 객체, Tag 객체에 사용 가능. 태그 이름, 속성, 문자열 등을 기준으로 검색. 주어진 조건에 맞는 모든 요소를 찾아서, 리스트 형태로 반환. 일치하는 요소 없으면 빈 리스트 반환.
반환되는 타입은 bs4.element.ResultSet인데, 리스트처럼 작용한다. 안의 요소들의 타입은 bs4.element.Tag..select_one(선택자): select와 똑같지만, 첫 번째 요소만 반환..select(선택자): BeautifulSoup 객체, Tag 객체에 사용 가능. find_all과 비슷하게 조건에 맞는 모든 요소를 찾아서 반환하지만, CSS 선택자를 사용해서 클래스, ID, 속성 선택자 등 다양하고 복잡한 선택 가능. 일치하는 요소 없으면 빈 리스트 반환.
반환되는 타입은 bs4.element.ResultSet인데, 리스트처럼 작용한다. 안의 요소들의 타입은 bs4.element.Tag.- 아래 예시는, body 안의 p 요소를 모두 찾아 리스트로 반환했다. for문으로 리스트를 돌리고, tag.text로 해당 p 요소의 text를 하나씩 print.
tag_list = soup.select('body p')
for tag in tag_list:
print(tag.text)
driver.close()- 예시로 보는 HTML 태그의 속성들
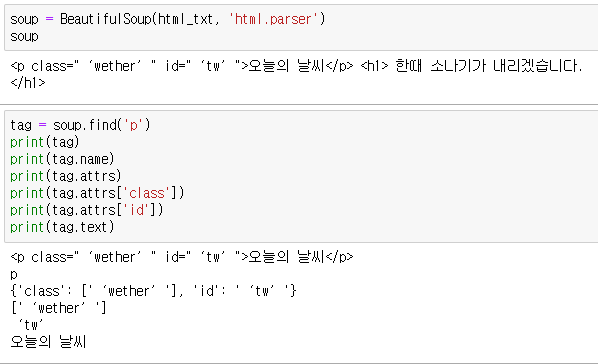
tag = soup.find('p')
print(tag)
print(tag.name)
print(tag.attrs)
print(tag.attrs['class'])
print(tag.attrs['id'])
print(tag.text)- ```find('p')```로 p~/p까지의 요소 중 첫번째로 걸리는 걸 들고 온다.
- ```tag.name```: 태그의 이름은 p
- ```tag.attrs```: 태그의 속성들을 딕셔너리 형태로 반환. 여기서는 class, id.
- ```tag.attrs['class']```: 속성 중 클래스의 값에 접근.
- ```tag.text```: p~/p 사이에 있는 본문만 string으로 return. - 선택자로 디테일하게 태그 찾기
- 부모-자식 관계로 태그 찾기는
b a,b > a이렇게 두 가지로 표현 가능. 띄워쓰기 혹은 > 표시. #company에서 #은 ID를 뜻.footage_cls에서 .은 class를 뜻.a[href]: a 태그의 href(링크)를 들고옴
- 부모-자식 관계로 태그 찾기는

일본에서 일하는 게임 기획자. 시시해서 죽어버리지 않게, 재밌고 의미 있는 컨텐츠에 관심 있습니다. 그 도구로 데이터, AI도 찝적댑니다.