서론
이전에 Process Scheduling(Long-term, Medium-term, Short-term Scheduling)에 대해 간단히 살펴보았다. 현대의 컴퓨터는 시분할 시스템을 활용을 하여 Long-term Scheduling의 필요성이 사라져 더 이상 사용하지 않고, Virtual-Memory 기술의 발달로, Medium-Term Scheduling로 해결하였던 문제점 자체를 제거하여 이 또한 사용하지 않게 되었다.
그러므로, 현 시점에서 Process Scheduling 중 오직 Short-Term Scheduling 만이 쓰이고 있다. 그렇기에, 이번에는 Short-term Scheduling가 무엇인지, 어떤 종류가 있는지 한번 자세히 다루어보자.
Short-term Scheduling, CPU Scheduling?
다중 프로그래밍을 구현하기 위한 Scheduling으로, CPU의 자원을 사용할 process를 선택하는 scheduling 이기에, CPU-Scheduling 이라고도 한다. 이러한 CPU Scheduling은 크게 1. CPU 자원 활용 최대화, 2. Overhead 최소화 를 목표로 한다.
Preemptive, non-preemptive
CPU Scheduling Algorithm이 가질 수 있는 특징은 Preemptive, non-Preemptive 인지 이다. 선점형, 비선점형이라는 말이 어렵게 들리지만, 쉽게 말하자면 외부의 요인으로 인해 Scheduling이 발생하는가, 아닌가 차이이다.
* Preemptive : Process가 terminated 상태로 가지 않아도, OS가 CPU 자원을 회수할 수 있음
* Non-Preemptive : Process가 terminated 상태로 가야만, CPU 자원을 회수할 수 있음이것만 가지고는 정확하게 어떤 상황에서 발생하는 스케쥴링이 Preemptive 인지, non-preemptive인지 알수는 없다. 그렇기에, Process State를 다시한번 복기해보자.
Process State
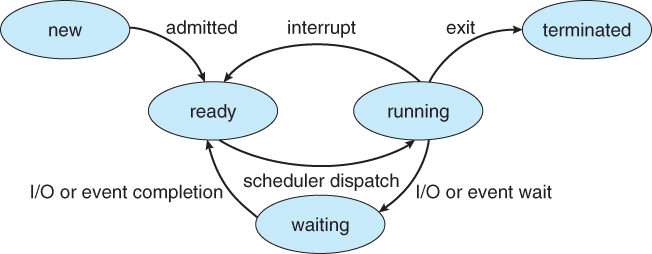
위의 Process State에서 CPU를 점유하고 있는 상태는 running state 이고, CPU Scheduling은 CPU를 점유하는 프로세스를 관리하는 것이기 때문에, running state가 포함된 상태 변화는 곧 CPU Scheduling이 일어났다고 볼 수도 있다. 이들을 정리하면 다음과 같다.
- Running -> Waiting
- Running -> Ready
- Ready -> Running
- Running -> Terminated
Non-Preemptive 방식은 Process가 Terminated 상태로 가야 Context-switching이 일어나는데, 1번과 2번의 state change는 해당되지 않는다. Preemptive는 1~4번의 process state change가 모두 발생할 수 있는 방식이다.
Scheduling Performance
Scheduling algorithm을 고를 때, 고려할 수 있는 지표는 다음과 같다.
- Throughput
시간당 완료되는 process의 수 - CPU Utilization
0% ~ 100% 까지가 이론상의 범위 이지만, 현실적으로는 부하가 적은 시스템은 약 40%, 부하가 높은 시스템은 약 90%의 값을 가지게 된다.
- Turnaround time
한 process가 ready queue에 처음 들어간 시점부터, terminated state로 넘어갈 때 까지의 시간 - Waiting Time
한 process가 queue에서 대기한 총 시간 - Response Time
Queue에 들어가고, 처음 running state로 들어갈 때 까지 걸린 시간
CPU Utilization, throughput이 높을 수록, Turnaround, waiting, response time이 적을 수록 좋은 algorithm이라고 할 수 있다.
Scheduling Algorithm
Single Queue
1. FCFS(First-Come, First-Served)
- 먼저 들어온 process먼저 처리
- Non-preemptive
- Simple 하고 Fair 하다.
- 들어오는 순서에 따라 Turnaround, waiting, response time이 매우 큰 폭으로 바뀔 수 있다.
2. SJF(Shortest-Job-First)
- Ready Queue에서 running time이 가장 짧게 걸리는 process 먼저 처리
- preemptive
- waiting time을 줄이는 관점에서는 SJF가 좋음
starvation- Running time을 예측하는 것 자체가 현실적이지 못함
2-a. Shortest-Remaining-Time-First
- 남은 running time이 가장 짧은 process 먼저 처리
- Non-preemptive
starvation- 이것도 비현실적임
3. RR(Round-Robin)
- Time quantum을 배정하여 돌아가면서 CPU를 사용
- Preemptive
- Performance가 Time-Quantum(T)에 따라 바뀐다. T가 매우 크면 FCFS와 동일하게 작동을 하고, T가 매우 작으면 Context-Switching overhead가 매우 커진다.
+ Priority Scheduling
- Process마다 priority를 배정하고, Priority가 높은 process먼저 수행한다. Priority가 같은 경우, 다른 algorithm을 사용할 수 있다.
- Preemptive, Non-preemptive 모두 가능
- Inifinite blocking, Starvation의 문제점이 있다.
Multilevel Queue Scheduling
- 이러한 Priority Scheduling은 Queue를 여러개 두는 것으로 구현할 수 있다.
Multilevel Feedback Queue Scheduling
Priority를 ready queue에 들어올 때 결정하고, 변화를 주지 않을 경우, Infinite Blocking, Starvation을 해결할 수 없는 문제점이 있다. 이를 해결하기 위해 Feedback을 Scheduler에게 주어 Priority를 변화시킨다.
MLFQ를 디자인할 때는 4가지를 고려해야 한다.
1. Queue(== Priority)의 개수
2. 각 Queue에서의 Scheduling 방법
3. Priority 올리는 시기를 결정하는 방법
4. Priority 내리는 시기를 결정하는 방법
위에서 나온 Scheduling은 모두 하나의 Processor가 있고, 그 processor를 점유하는 Scheduling에 관한 것이다. 그러면, process가 여러개 있다면, 어떻게 Scheduling을 진행해야 할까? 간단히만 다뤄보자.
Multi-Processor Scheduling
- 대상 : 멀티코어 시스템, NUMA(Non-Uniform Memory Access)
1. Asymmetric Multi-Processing
Master Server의 역할을 갖는 하나의 Processor가 Scheduling, I/O 처리 등을 처리한다. 다른 Slave Client들은 사용자의 코드를 실행하는 역할만 한다.
2. SMP(Symmetric Multi-Processing)
각 Processor가 스스로를 Scheduling 하는 방식을 말한다. 이를 구현하기 위한 2가지 방법이 있다. Linux, Windows, Android, iOS 모두 이 방식을 지원한다.
2-a. Common Ready Queue
- Common Ready Queue에 ready state의 process들이 들어오고, 각각의 Processor는 이 queue에서 실행할 Process를 선택하여 가져간다.
공유 자원(Queue)에 대해 Race-Condition이 생길 수 있으므로, 두 개의 processor가 같은 process를 가져가지 않고, queue에서 process가 사라지지 않도록 보장해야 한다. 이를 위해 Queue를 Locking할 방법이 필요하고, 한번에 한 Processor만 가져가야 하는데, 이렇게 될 경우 Locking에 대한 경쟁이 치열하여 overhead가 발생할 것이고, Common Queue 접근 자체가 병목이 될 것이다.
2-b. Per-Core Ready Queue
Common Queue access overhead를 해결하기 위해 나온 방법이 바로 Per-Core Ready Queue이다. 각각의 Processor만의 Cache를 잘 사용할 수 있다는 장점이 있지만, 각각의 Processor의 Queue의 부하는 차이가 있을 수 있다는 단점이 있다.
이렇게 다시 Queue의 부하를 균등하게 하기 위해 Load-balancing Algorithm을 사용한다.
Linux에서 사용하는 Load Balancer algorithm의 동작을 정리하고, 글을 마치겠다.
1. find_busiest_group() 함수와 find_busiest_queue() 함수를 호출
부하가 집중된 처리기 그룹과 실행 큐 검색
2. 가장 바쁜 실행 큐의 우선순위 배열에서 태스크 선택
우선순위 배열은 active 배열과 expired 배열 두가지로 구분되어 있음
처리기 캐시에 없을 가능성이 높은 비활성 배열을 선호함
비활성 배열이 비어있다면 활성 배열에서 선택
3. 가장 높은 우선순위 태스크를 선택
높은 우선순위의 태스크를 공평히 나누어 조금이라도 빨리 처리하기 위함
4. 태스크 검색 조건
실행중이 아니고, 다른 처리기로 이동이 금지 되지 않은 태스크
5. pull_task() 함수를 호출하여 바쁜 실행 큐로부터 현재 실행 큐로 태스크 이동
6. 실행 큐의 균형 상태를 확인하고 균형이 이루어 질 때까지 3~5번 과정 반복
7. 실행 큐의 불균형이 해제되면 현재 실행 큐의 잠금을 해제하고 알고리즘 종료
출처:
- Operating System Concepts 9th edition, Silverschatz
- "멀티코어 환경에서 효율적인 부하 분산 알고리즘 = An Efficient Load Balancing Algorithm on Multi-core Architecture"
http://www.riss.kr/search/detail/DetailView.do?p_mat_type=be54d9b8bc7cdb09&control_no=f6d9f48fe292fec0ffe0bdc3ef48d419&outLink=K
