Memory Layout
process에 대해 공부하다 보면 아래와 같은 그림이 많이 보인다. 이를 Process의 Memory Layout이라고 하는데, 각각의 영역을 한번 알아보자.
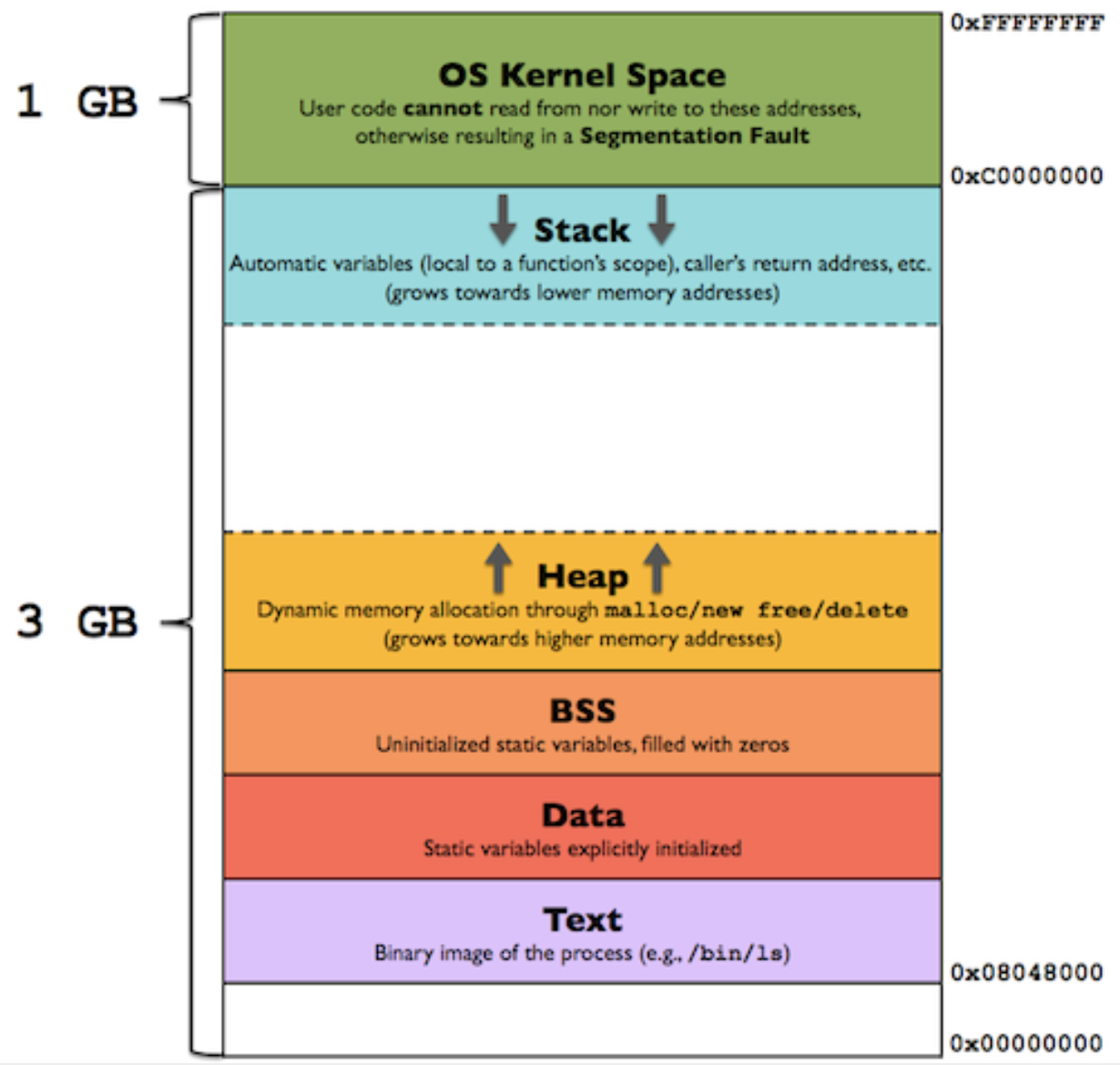
OS Kernel Space
Process의 Memory Layout은 크게 2가지로 나뉠 수 있다. 하나는 User Space이고, 다른 하나는 Kernel Space이다. OS Kernel Space는 모든 process가 같은 내용을 갖게된다. Syscall이 필요할 경우 이 kernel space를 이용하여 OS Kernel에 작업을 요청하게 된다.
User space에서 syscall을 통하지 않고, 직접적으로 이 주소에 접근하게 될 경우, Segmentation Fault가 발생한다.
User Space
User Space는 프로그램마다, 같은 프로그램이어도 실행 시 argument로 무엇을 넘겨줬는가에 따라 다르게 구성이 된다.
제일 먼저, binary image의 모든 내용이 Code segment에 적재가 되고, 그 다음에는 전역변수, static 변수들이 Data segment에 적제가 되며, 작업을 진행하며 stack, heap이 채워지고, 비워진다.
메모리에 적재되는 순서대로 자세히 살펴보자.
1. Code
process의 binary image가 이곳에 적재된다. 작업을 수행하며 함수를 호출할 경우, 해당 함수를 Text 영역에서 찾게 된다.Text 영역은 Read-Only 영역이기에, 수정할 수 없다. 이 Code 영역은 text영역, init 영역, rodata 영역으로 나눌 수 있다.
- Text 영역
코드 그 자체가 기록되는 영역으로, 함수가 호출되면 이곳에서 찾는다. - init 영역
상수/변수가 선언과 동시에 초기화 될 경우, 그 상수/변수의 리터럴 값이 이곳에 저장이 된다. - RO data(.rodata)
Read-Only data의 준말이다. 이 부분에도 리터럴 값들이 저장되지만, init 영역에 저장되지 않은, 나머지 부분이 저장이 된다.
2. Data
Data 영역은 전역변수와 static 변수들이 저장되는 공간으로, 선언되었을 당시 초기화 값이 있는지 없는지에 따라 data 영역, bss영역에 저장이 된다.
1. data 영역
선언 당시 초기화가 된 변수들이 저장된다. 프로그램이 시작하자마자, init 영역의 값을 찾아가 초기화가 된다.
2. bss 영역 (block started by symbol)
선언 당시 초기화값이 없을 경우 이곳에 저장이 된다. 프로그램이 시작하면, init 영역을 확인하지 않고 바로 0으로 초기화가 된다.
3. Stack
지역변수들이 저장되는 곳이다. 함수가 실행되는 경우, 현재의 PC의 값을 stack에 넣은 후, 함수가 종료될 경우 stack에 저장된 PC의 값을 확인하여 다시 진행을 한다. 이렇게, 스택 영역에 저장되는 함수의 호출 정보를 Stack Frame이라고 한다.
변수의 자료형 등은 컴파일 시간에 결정이 되고, 지역변수들은 모두 런타임에 생성되었다가 소멸한다. stack에는 이런 정적 바인딩이 되는 값들이 저장이 된다.
Memory의 높은 주소에서, 낮은 방향으로 할당이 되며, 컴파일을 할 때 크기가 결정이된다.
특징
- 단편화가 일어나지 않아, 효율적이다.
- 크기가 이미 결정되어 있어, 한계를 초과하도록 push할 수 없다.
- 다시 말하지만, 메모리에 할당이 이미 끝난 영역이다. stack 에 push, pop은 오로지 stack pointer만 움직이며, 값을 다루는 과정이다.
4. Heap
메모리 동적 할당으로 저장되는 데이터들은 모조리 힙에 저장이 된다. 런타임 시에 크기가 결정이 되며, 사용자가 관리를 해야만 하는 영역이다. 메모리의 낮은 주소에서 높은 주소의 방향으로 할당이 된다.
특징
- 할당, 해제 작업으로 인해 overhead가 생긴다.
Overflow
Heap이 Stack의 영역을 침범하는 경우, Heap overflow가 일어나고, 반대의 경우 Stack overflow가 일어나게 된다.
