1. 정렬이란?
- 정렬은 물건을 크기순으로 오름차순이나 내림차순으로 나열하는 것을 의미
- 정렬되어 있지 않은 자료가 주어지면 탐색의 효율성은 크게 떨어진다.
- 즉 자료 탐색에 있어서 필수적
2. 정렬의 대상
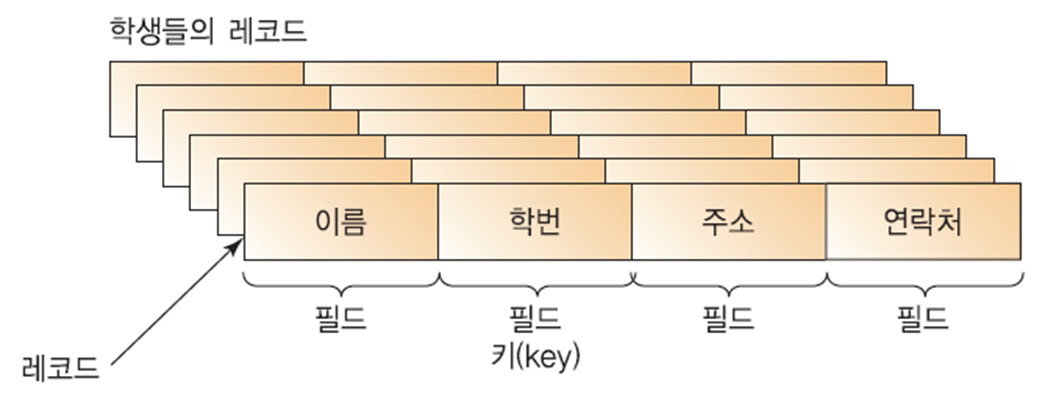
- 일반적으로 정렬시켜야 할 대상은
레코드(record)라고 불린다. - 레코드는 다시
필드(field)라고 하는 단위로 나누어진다. - 여러 필드 중에서 특별히 레코드와 레코드를 식별해 주는 역할을 하는 필드를
키(key)라고 한다.
3. 정렬 알고리즘을 평가하는 효율성의 기준
- 비교 연산의 횟수
- 이동 연산의 횟수
-> 일반적으로 이 둘은 서로 비례하지 않음
4. 정렬 알고리즘 종류
정렬 알고리즘은 크게 2가지로 나누어진다.
- 단순하지만 비효율적인 방법 (보통 O(n2))
- 삽입 정렬, 선택 정렬, 버블 정렬 등 - 복잡하지만 효율적인 방법 (보통 O(nlog(n)))
- 퀵 정렬, 힙 정렬, 합볍 정렬, 기수 정렬 등
자료의 개수가 적다면 단순한 정렬 방법을 사용하는 것도 괜찮지만 자료의 개수가 일정 개수를 넘어가면 반드시 효율적인 알고리즘을 사용
4-1. 선택 정렬
선택 정렬은 오른쪽 리스트가 공백 상태가 될 때까지 이 과정을 되풀이하는 방법
메모리를 절약하기 위해 배열을 사용하지 않고 제자리 정렬 사용
코드 예시
public class Selection_Sort {
private static void swap(int[] list, int least, int i) {
int temp = list[least];
list[least] = list[i];
list[i] = temp;
}
public static void selection_sort(int[] list) {
selection_sort(list, list.length);
}
private static void selection_sort(int[] list, int size) {
for(int i = 0; i < size - 1; i++) {
int least = i;
// 최솟값을 갖고있는 인덱스 찾기
for(int j = i + 1; j < size; j++) {
if(list[j] < list[least]) least = j;
}
// i번째 값과 찾은 최솟값을 서로 교환
swap(list, least, i);
}
}
}선택 정렬의 분석
외부 루프는 n-1번 실행, 내부 루프는 (n-1)-i번 반복
시간 복잡도 : O(n2)
선택 정렬의 문제점
- 자료가 정렬된 경우 불필요하게 자기 자신과의 이동을 하게 됨
- 같은 레코드가 있는 경우 상대적인 위치가 변경될 수 있는
안정성문제 - 개선을 위해서는 다음과 같은 if문 추가
if(i!=least)
swap(list, least, i);4-2. 삽입 정렬
삽입 정렬은 정렬되어 있는 리스트에 새로운 레코드를 적절한 위치에 삽입하는 과정을 반복
코드 예시
public class Insertion_Sort {
public static void insertion_sort(int[] list) {
selection_sort(list, list.length);
}
private static void insertion_sort(int[] list, int size){
int key, i, j;
for(i=1; i<size; i++){
key = list[i];
for(j=i-1; j>=0 && list[j] > key; j--)
list[j+1] = list[j];
list[j+1] = key;
}
}
}삽입 정렬의 분석
이미 정렬되어 있는 경우 가장 빠름
외부 루프는 n-1번 실행, 각 단계에서 1번의 비교와 2번의 이동
총 비교 횟수는 n-1번, 총 이동 횟수는 2(n-1)번
시간 복잡도
- 최악의 경우(입력 자료가 역순) : O(n2)
- 평균의 경우 : O(n)
4-3. 버블 정렬
버블 정렬은 인접한 2개의 레코드를 비교하여 크기가 순서대로 되어 있지 않으면 서로 비교하는 비교-교환 과정을 리스트의 왼쪽 끝에서 오른쪽 끝까지 진행
코드 예시
public class Bubble_Sort {
private static void swap(int[] list, int least, int i) {
int temp = list[least];
list[least] = list[i];
list[i] = temp;
}
public static void bubble_sort(int[] list) {
selection_sort(list, list.length);
}
private static void bubble_sort(int[] list, int size) {
for(int i=size-1; i>0; size--){
for(int j=0; j<i; j++)
if(list[j] > list[j+1]
swap(list, j, j+1);
}
}
}버블 정렬의 분석
버블 정렬의 비교 횟수는 최선, 평균, 최악의 어떠한 경우에도 항상 일정하고 이동 횟수는 자료가 역순일 경우 최악, 정렬되어 있는 경우 최선이다.
시간 복잡도 : O(n2)
버블 정렬의 문제점
- 순서에 맞지 않는 요소를 인접한 요소와 교환한다는 점.
- 일반적으로 자료의 교환(swap) 작업이 자료의 이동(move) 작업보다 더 복잡하기 때문에 버블 정렬은 그 단순성에도 불구하고 거의 사용하지 않는다.
4-4. 쉘 정렬
- 쉘 정렬은 삽입 정렬이 어느 정도 정렬된 배열에 대해서는 대단히 빠른 것에 착안한 방법.
- 전체 리스트를 한 번에 정렬하지 않고 정렬해야할 리스트를 일정한 기준에 따라 분류하여 연속적이지 않은 여러 개의 여러 개의 부분 리스트를 만들고, 각 부분 리스트를 더 적은 개수의 부분 리스트로 만든 후 알고리즘을 되풀이한다.
코드 예시
public class Shell_Sort {
private static void insertion_sort(int[] list, int first, int last, int gap){
int key;
for(int i=first+gap; i<=last; i+=gap){
key = list[i];
for(int j=i-gap; j>=first && list[j] > key; j-=gap)
list[j+gap] = list[j];
list[j+gap] = key;
}
}
private static void shell_sort(int[] list, int size){
for(int gap = size/2; gap>0; gap/=2){
if(gap%2 == 0) gap++;
for(int i==0; i<gap; i++)
insertion_sort(list, i, size-1, gap)
}
}
}쉘 정렬의 분석
삽입 정렬에 비한 장점
- 연속적이지 않은 부분 리스트에서 자료의 교환이 일어나면 더 큰 거리를 이동
- 부분리스트는 어느정도 정렬이 된 상태이기 때문에 부분 리스트의 개수가 1이 되게 되면 쉘 정렬은 기본적으로 삽입 정렬을 수행하는 것이지만 더 빠름
시간 복잡도
- 최악의 경우 : O(n2)
- 평균의 경우 : O(n1.5)
4-5. 합병 정렬
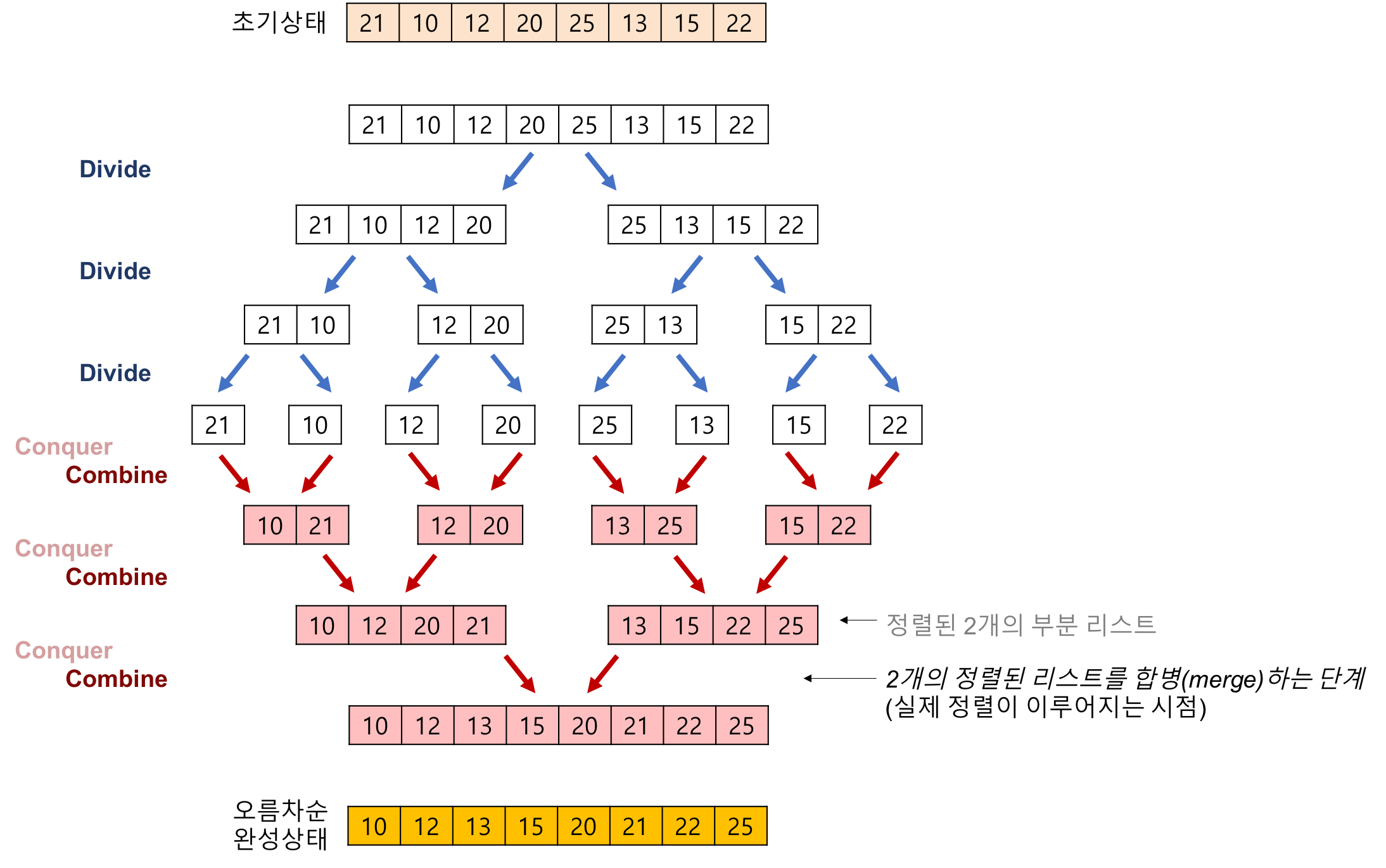
- 합병 정렬은 하나의 리스트를 두 개의 균등한 크기로 분할하고 분할된 부분 리스트를 정렬한 다음, 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트를 얻고자 함
합병 정렬은 다음의 단계들로 이루어진다.
- 분할(Divide) : 입력 배열을 같은 크기의 2개의 부분 배열로 분할
- 정복(Conquer) : 부분 배열을 정렬, 부분 배열의 크기가 충분히 작지 않으면 순환 호출을 이용하여 다시
분할 정복기법을 적용 - 결합(Combine) : 정렬된 부분 배열들을 하나의 배열에 통합
코드 예시
public class Merge_Sort {
private static void merge(int[] list, int left, int mid, int right){
// i는 정렬된 왼쪽 리스트에 대한 인덱스
// j는 정렬된 오른쪽 리스트에 대한 인덱스
// k는 정렬된 리스트에 대한 인덱스
int i = left;
int j = right;
int k = left;
int[] sorted = new int[list.length];
// 분할 정렬된 list의 합병
while(i<=mid && j<=right){
if(list[i] <= list[j])
sorted[k++] = list[i++];
else
sorted[k++] = list[j++];
}
if(i>mid) // 남아 있는 레코드의 일괄 복사
for(int l=j; l<=right; l++)
sorted[k++] = list[l];
else // 남아 있는 레코드의 일괄 복사
for(int l=i; l<=mid; l++)
sorted[k++] = list[l];
// 배열 sorted[]의 리스트를 배열 list[]로 재복사
for(int l=left; l<=right; l++)
list[l] = sorted[l];
}
private static void merge_sort(int[] list, int left, int right){
int mid;
if(left<right){
mid = (left+right)/2; // 리스트의 균등 분할
merge_sort(list, left, mid); // 부분 리스트 정렬
merge_sort(list, mid+1, right); // 부분 리스트 정렬
merge(list, left, mid, right); // 합병
}
}
}합병 정렬에서 실제로 정렬이 이루어지는 시점은 2개의 리스트를 합병하는 단계이다.
합병 자체는 어렵지 않으나 추가적인 리스트를 필요로 한다.
합병 정렬의 분석
- 합병 정렬의 비교 횟수와 이동 횟수의 복잡도는 같다.
- 안정적인 정렬 방법
시간 복잡도
- 최악, 평균, 최선 : O(nlog(n))
4-6. 퀵 정렬
- 퀵 정렬은 평균적으로 매우 빠른 수행 속도를 자랑
- 퀵 정렬도
분할-정복법에 근거 - 합병 정렬과는 달리 퀵 정렬은 리스트를
비균등하게 분할

코드 예시
public class Quick_Sort {
private static void swap(int[] list, int least, int i) {
int temp = list[least];
list[least] = list[i];
list[i] = temp;
}
private static int partition(int[] list, int left, int right){
int pivot, temp;
int low, high;
low = left;
hight = right+1;
pivot = list[left];
do {
do
low++;
while(list[low]<pivot);
do
high--;
while(list[high]>pivot);
if(low<high) swap(list, low, high);
} while(low<high);
swap(list, left, high);
return high;
}
private static void quick_sort(int[] list, int left, int right){
if(left<right){
int q = partition(list, left, right);
quick_sort(list, left, q-1);
quick_sort(list, q+1, right);
}
}
}퀵 정렬의 분석
- O(nlog(n)의 복잡도를 가지는 다른 정렬과 비교했을 때 가장 빠름
- 불필요한 데이터의 이동을 줄임
- 속도가 빠르고 추가 메모리 공간 필요 X
시간 복잡도
- 최악의 경우 : O(n2)
- 평균의 경우 : O(nlog(n))
4-7. 힙 정렬
힙을 이용하여 데이터를 차례대로 최대 힙에 추가 후 한 번에 하나씩 힙에서 꺼내 배열의 뒤쪽부터 저장
코드 예시
public class Heap_Sort {
private static void heap_sort(int[] list){
PriorityQueue<Integer> heap = new PriorityQueue<Integer>();
// 힙에 배열의 원소 추가
for(int i = 0; i < list.length; i++) {
heap.add(list[i]);
}
// 힙에서 추출하여 정렬
for(int i = 0; i < list.length; i++) {
list[i] = heap.poll();
}
}
}힙 정렬의 분석
힙트리의 전체 높이가 거의 log(n)이므로 하나의 요소를 힙에서 삽입하거나 삭제할 때 힙을 재정비하는 시간이 log(n)만큼 소요, 요소의 개수는 n개
시간 복잡도
- 평균의 경우 : O(nlog(n))
4-8. 기수 정렬
- 이때까지의 정렬 방법들은 레코드들을 비교하여 정렬
- 기수 정렬은 비교하지 않고도 정렬 가능
- 레코드의 키들이 동일한 길이를 가지는 숫자나 문자열로 구성되어야 함
- 기수는 숫자의 자리수를 뜻함
코드 예시
public class Radix_Sort {
private static int BUCKETS = 10;
private static int DIGITS = 4;
private static void radix_sort(int[] list, int size){
int factor = 1;
// bucket 초기화
Queue<Integer>[] bucket = new LinkedList[BUCKETS];
for (int i = 0; i < BUCKETS; i++) {
bucket[i] = new LinkedList<>();
}
// 데이터들을 자리수에 따라 버킷에 삽입
for (int d = 0; d < DIGITS; d++) {
for (int i = 0; i < n; i++) {
bucket[(list[i] / factor) % 10].add(list[i]);
}
for (int b = i = 0; b < BUCKETS; b++) {
while (!bucket[b].isEmpty()) {
list[i++] = bucket[b].poll();
}
}
factor *= 10;
}
}
}기수 정렬의 분석
- 입력 리스트가 n개의 정수를 가지고 있다면 내부 루프는 n번 반복
- 각 정수가 d개의 자리수를 가지고 있다고 하면 외부 루프는 d번 반복
시간 복잡도
- 평균의 경우 : O(d*n)
5. 정렬 알고리즘 비교
| 알고리즘 | 최선 | 평균 | 최악 |
|---|---|---|---|
| 선택 정렬 | O(n2) | O(n2) | O(n2) |
| 삽입 정렬 | O(n) | O(n2) | O(n2) |
| 버블 정렬 | O(n2) | O(n2) | O(n2) |
| 쉘 정렬 | O(n) | O(n1.5) | O(n1.5) |
| 합병 정렬 | O(nlog(n)) | O(nlog(n)) | O(nlog(n)) |
| 퀵 정렬 | O(nlog(n)) | O(nlog(n)) | O(n2) |
| 힙 정렬 | O(nlog(n)) | O(nlog(n)) | O(nlog(n)) |
| 기수 정렬 | O(d*n) | O(d*n) | O(d*n) |
