0. Kafka란
- Apache Kafka는 고성능 데이터 파이프라인, 스트리밍 분석, 데이터 통합 및 미션 크리티컬 애플리케이션을 위해 오픈 소스 분산 이벤트 스트리밍 플랫폼(distributed event streaming platform)이다.
1. Kafka와 같은 이벤트 브로커를 사용하는 이유.
1-1. 서버 컴포넌트간의 직접의존을 방지하기 위해서 사용한다.
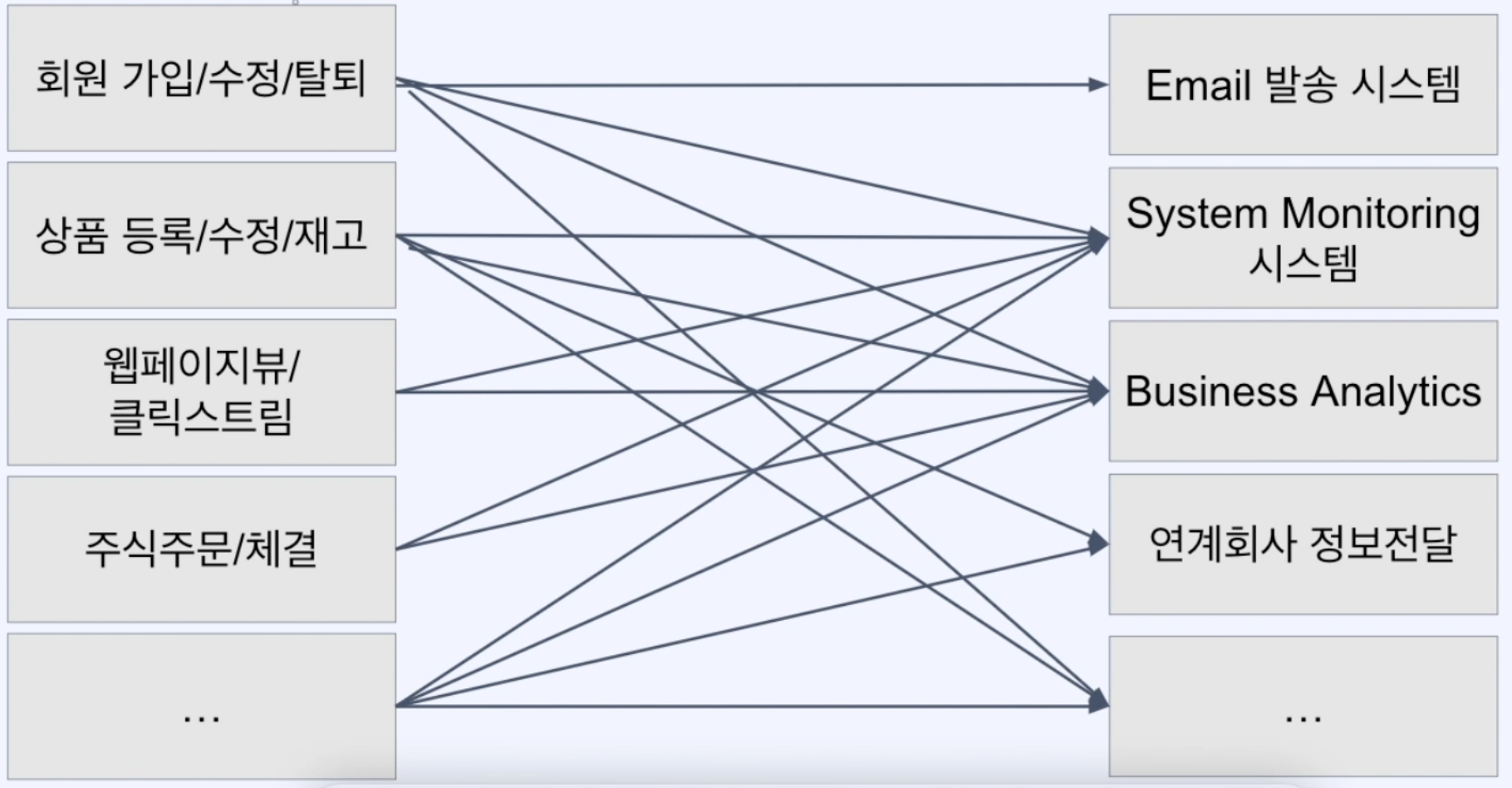
위 아키텍처의 문제점.
- 서버 컴포넌트가 서로 직접 의존되어 있는 경우 상대방 시스템의 변경에 따라 의존하는 시스템도 변경해주어야한다.
- 의존되는 시스템에 장애가 발생할 경우 의존하는 시스템도 영향을 받아서 장애가 발생할 수 있다.
해결방안
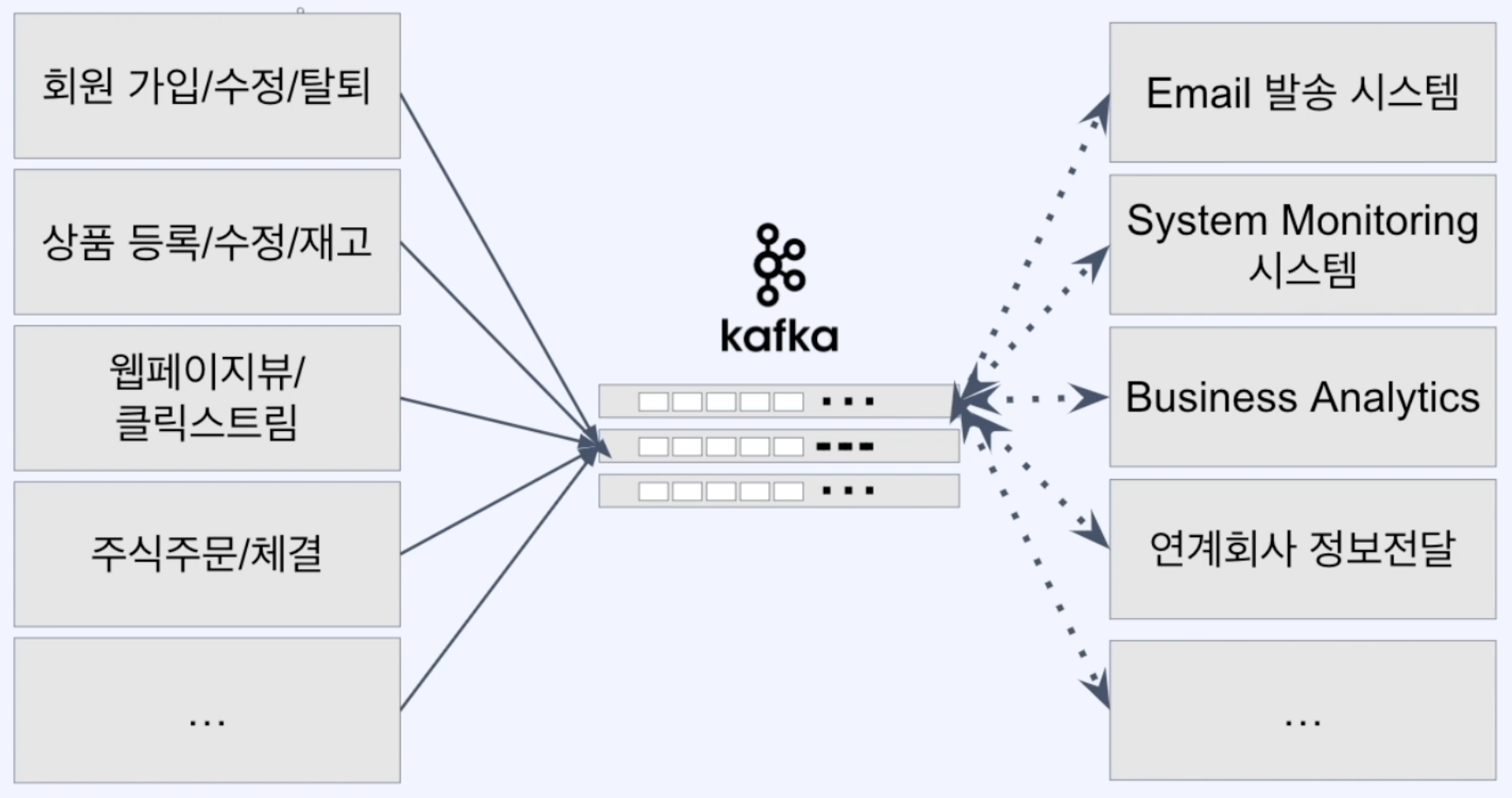
- 다음과 같이 Kafka를 메세지 브로커로서 두면 시스템간에 직접 메시지를 주고 받지 않기 때문에 위의 두 문제를 해결할 수 있다.
- 이벤트 발행자는 kafka에게 어떻게 메시지를 발행할지만 고민하면 되고 이벤트 수신자는 Kafka에서 메시지를 수신하여 어떻게 처리할 지만 고민하면 된다.
1-2. 동기 방식을 비동기 방식으로 전환함과 동시에 관심사를 분리하기 위해서 사용한다.
- 예를 들어 내가 쓴 글에 타인이 좋아요를 누를 경우 알림이 울리는 기능이 있다고 하자.
- 이 기능에는 크게 두가지의 관심사가 있는데
- 첫번째 관심사는, like를 저장하는 관심사
- 두번째 관심사는, 알림을 저장하고 발송하는 관심사
- 첫번째 관심사는 좋아요를 누르고 나서 사용자가 정상 응답을 받는 사이에 동기적으로 이루어지면서 좋아요가 저장되어야 한다. 두번째 관심사는 좋아요를 저장하는 것과 꼭 함께 이루어져야할 필요는 없고 비동기적으로 이루어져도 상관이 없다.
- 이 두 관심사를 모두 동기적으로 처리하고 하나의 시스템에서 처리한다면 알림 기능에서 장애가 발생했을 때 좋아요가 눌리는 기능자체가 실패할 수 있다.
- 이 때 kafka를 활용하면 좋아요를 눌렀을 때 Kafka에 이벤트를 발행만 하는것으로 대체하고 비동기적으로 컨슈머 그룹에서 이벤트를 읽고 처리할 수 있다.
- 따라서, 알림기능에 장애가 발생하더라도 좋아요 기능은 제대로 수행 될 수 있다.
1-3. 단일 진실 공급원으로서 활용한다.
- 서버 아키텍처에서 데이터는 cache, RDB, 여러 NOSQL등에 분산되어 저장될 수 있는데 이때 각 DataSource에서 데이터의 내용은 다를 수 있다.
- Kafka에 event를 발행하고 그 event를 각각의 DataSource가 서로 다른 Consumer Group으로서 저장및 처리하는 방식으로 구성하면 각각의 DataSource의 현재 데이터 형상이 다를 때 실제 데이터는 Kafka에 발행한 Event라고 정의할 수 있다.
2.Kafka 핵심 개념들
2-0. Message Broker와 Event Broker인 Kafka의 차이점
- Message Broker에는 RabbitMQ, ActiveMQ, RedisQueue등이 있다.
- 가장 큰 차이는 Event Broker Kafka의 경우 publish 한 event를 반영구 적으로 저장할 수 있다는 점이다. Message Broker에서는 subscribe한 메시지를 저장하기 힘들다.
- kafka의 경우 이벤트를 저장하기 때문에 이벤트 발행 및 소비여부를 보장할 수 있으며, 장애가 발생 했을 때 재처리할 수 있다.
- 단일 진실 공급원으로서 활용할 수 있다.
- 따라서 이벤트 브로커는 메시지 브로커로도 활용될 수 있지만 메시지 브로커를 이벤트 브로커로 활용할 수는 없다.
2-1. Topic
- topic은 이벤트를 발행하거나 혹은 발행한 이벤트를 소비하는 곳을 지정하는 개념이다.
- 따라서 이벤트 발행 및 소비 시 토픽을 지정해주어야한다.
- 토픽내에는 여러개의 Partition이 존재하여 이벤트는 각각의 Partition에 분리되어 저장된다.
2-2. Partition
- topic내에 실제로 이벤트가 record형태로 저장되는 곳이다.
- 큐 자료 구조로 되어있으며 이벤트 발행 시 partition 내에 이벤트가 레코드로 저장되고 저장된 이벤트는 기본적으로는 삭제되지 않는다.(설정에 따라 주기적으로 삭제)
- Partition하나당 consumer가 하나 붙어서 소비할 수 있고 Partition개수 만큼 Consumer를 생성하면 병렬 처리가 가능하기 때문에 성능을 늘리는데 활용할 수 있다.
- Partition은 늘릴 수는 있지만 줄일 수 없기 때문에 Partition개수를 늘리는 것에 신중해야한다.
- Partition개수보다 Consumer가 많은 경우 Consumer가 많아서 생기는 이점이 없기 때문에 Consumer를 Partition개수보다 항상 같거나 작게 유지해야한다.
- 컨슈커가 이벤트를 소비해도 record가 사라지지 않으며 컨슈머 그룹의 offset이 변경되기만 한다.
2-3. Producer
- topic에 이벤트를 publish한다.
- publish 시에 Ack 조건을 설정하여 publish를 얼마나 보장할 지 결정할 수 있다.
- ack = 0 ; publish가 실패해도 ack를 보낸다.
- ack = 1 ; publish가 leader에만 성공하면 ack를 보낸다. 이 경우 leader가 fail하여 replica가 leader가 될 경우 이벤트가 유실 될 수 있다.
- ack = all; publish가 leader에서 성공하고 replica에도 모두 복제 되어야 ack를 보낸다. ack = 1에서 leader가 fail하는 경우에도 이벤트가 유실 되지 않는다.
(추가)acks:all 설정 시 min.insync.replicas도 2 이상으로 변경해주어야한다.
- 이벤트 발행 시 어떤 파티션에 이벤트가 저장될 지는 랜덤이기 때문에 이벤트 소비 순서는 보장되지 않는다.
- 만약, 순서가 꼭 보장되어야 한다면 key값을 지정하여 publish할 수 있고 이 경우 하나의 partition에만 event가 저장된다.
- 단, 이 경우 여러 파티션에서 consumer가 consume하여 성능적으로 병렬 처리를 할 수 있다는 이점은 사라지게 되고 partition 개수를 증가 시킬 경우 순서가 보장되지 않을 수 있기 때문에(key 값으로 hashing을 하여 파티션을 대응하는 것이기 때문이다.) 순서가 꼭 보장되어야 하는 경우가 아니면 key값을 지정하지 않는 것이 좋다.
2-4. Consumer Group과 Consumer
- Consumer는 이벤트를 소비할 때 Polling을 활용하여 주기적으로 소비할 이벤트가 존재하는지 확인하는 방식을 취한다. 즉, broker가 이벤트를 소비할 시점이나 소비할 주체를 결정하지 않고 Consumer가 직접 결정한다.(Redis pub-sub의 경우 publish시 subscriber들에게 redis가 메시지를 전해준다.)
- Consumer Group은 Topic에 발행된 이벤트를 consume하는 것에 대해서 공통된 Consumer들의 그룹이다.
- 메시지를 어디까지 소비했는지(offset)와 메시지를 어떻게 처리할지의 로직을 각각 정의할 수 있다.
- Consumer Group내에는 Consumer가 여러 개 존재할 수 있으며 Topic의 한개 혹은 그 이상의 partition에서 consume할 수 있다. 따라서 partition 개수와 같거나 혹은 적게 consumer를 설정해주어야 한다.
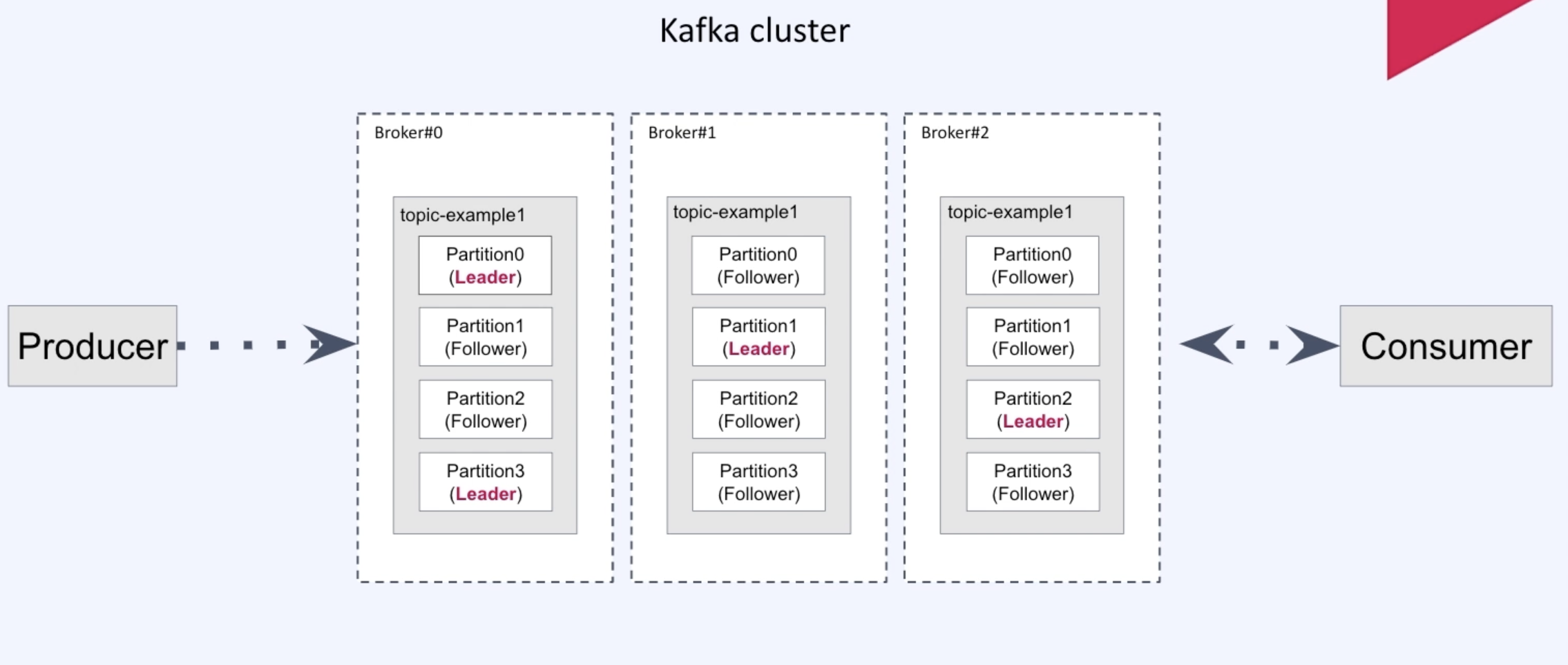
2-5. Broker, Replication, In Sync Replica(ISR) for High Availability
Broker
- kafka 서버를 말한다.
- 가용성을 위해서 broker를 3이상 유지하는 것이 권장된다.
Replication
- 가용성을 위해 topic의 partition을 서로 다른 여러 broker에 복제하여 저장하는 것을 말한다.
- DB Replication등과 다르게 Replica partition에서 Read역할 만해준다거나 하는 부하 분산의 역할은 하지 못하고 단순히 leader partition의 fail-over시 복구 하기 위한 용도로서 replication을 수행한다.
- 특정 브로커가 leader, follwer로 구분되어있는 것이 아니라 partition마다 모두 다르다.
- 일반적인 database에서의 replication과는 다르게 leader에는 아예 요청이 가지 않는다. 단순히 레코드 저장을 보장해주는 역할만 수행한다.
In Sync Replica
- leader 파티션과 다른 broker들에 저장된 replica를 묶어 ISR이라고 한다.
- Replication 개수를 지정하여 ISR에 묶일 partition의 개수를 지정할 수 있다(적어도 2개이상 으로 하는것이 바람직하다).
2-6. ZooKeeper, Controller
- ZooKeeper는 카프카의 메타데이터를 저장하고 상태관리등의 목적으로 이용한다.
- Controller는 Broker중 단 하나만 존재하는데, 각 브로커의 상태를 체크하고 특정 브로커가 fail하면 partition의 새로운 leader를 선축하고 각 broker에게 전달한다.
2-7. Consumer Lag
- 파티션 내에서 이벤트 발행시 이벤트가 저장될 위치 offset과 이벤트가 소비될 offset의 차이를 말한다.
- 이 차이가 클 경우 소비되는 속도가 생산되는 속도 대비 느리다고 볼 수 있다.
3.kafka 클러스터 local에 구축.
- kafka download를 구글에 검색하여 원하는 Kafka버전을 다운로드 한다.(저는 2.8.2을 받아습니다.)
- 다운로드 받은 내용에 보면 bin, config 디렉토리가 있는데 각각 bin은 서버 실행, 정지등의 동작을 수행해주는 스크립트들이 들어있고 config는 실행 시 옵션을 지정해줄 수 있는 설정파일이 들어있다. 이 설정파일을 적절히 수정하여 bin 안의 sh파일로 kafka를 실행할 수 있다.
- Zookeeper server를 실행해준다.
- 주키퍼 실행 시 간혹 Quorum과 관련된 클래스를 찾을 수 없다는 에러가 발생할 수 있는데 이 경우 밑에 있는 gradlew 커맨드를 실행해주면 된다.
(오류: 기본 클래스 org.apache.zookeeper.server.quorum.QuorumPeerMain을(를) 찾거나 로드할 수 없습니다.)
./gradlew jar -PscalaVersion=2.13.5//zookeeper 실행 커맨드
bin/zookeeper-server-start.sh config/zookeeper.properties- Kafka 서버들을 실행해준다.
설정 파일 수정
- 다음 두 옵션을 모두 다르게 설정 해준다.
- broker.id=0
- listeners=PLAINTEXT://{domain}:{port}
bin/kafka-server-start.sh config/server.properties
bin/kafka-server-start.sh config/server.properties1
bin/kafka-server-start.sh config/server.properties24. Kafka AWS MSK.
MSK 설정
- Kafka 버전 지정
- 브로커 유형 선택 저는 비용을 고려하여 t3.small을 선택했습니다.
- 영역 수(2 or 3) 설정 영역당 브로커 선택. 영역당 브로커는 Bloker의 개수를 의미하며 영역 수는 Availability zone을 의미합니다. 영역 수는 설정 후 변경할 수 없습니다.
- storage는 자동 확장은 가능하지만 줄일 수 없기 때문에 너무 크지않게 선택합니다. 프로미저닝옵션을 선택할 경우 요금이 추가됩니다.
- vpc 서브넷, 보안 그룹을 설정해줍니다. MSK는 기본적으로 VPC내부에서만 연결됩니다
- 클라이언트 접속 방식을 선택합니다. 저는 IAM Role방식을 선택했습니다.
5. Spring boot와 연동
application.yml
spring:
kafka:
producer:
properties:
min:
insync:
replicas: 2
kafka:
bootstrapAddress: localhost:9092, localhost:9093
admin:
properties:
topic:
alarm:
name: alarm
replicationFactor: 2
numPartitions: 2
consumer:
alarm:
rdb-group-id: createAlarmInRDB
redis-group-id: publishInRedis
autoOffsetResetConfig: latest
producer:
acksConfig: all
retry: 3
enable-idempotence: true
max-in-flight-requests-per-connection: 3
Topic 생성
- topic을 생성할 때에는 in sync replica의 개수와 파티션 개수를 지정해줍니다.
@Configuration
public class KafkaTopicConfig {
@Value(value = "${kafka.bootstrapAddress}")
private String bootstrapAddress;
@Value("${kafka.topic.alarm.name}")
private String topicName;
@Value("${kafka.topic.alarm.numPartitions}")
private String numPartitions;
@Value("${kafka.topic.alarm.replicationFactor}")
private String replicationFactor;
@Bean
public KafkaAdmin kafkaAdmin() {
Map<String, Object> configs = new HashMap<>();
configs.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress);
return new KafkaAdmin(configs);
}
/**
* broker 를 두개만 설정하였으므로 최소 Replication Factor로 2를 설정하고
* Partition의 경우 Event 의 Consumer인 WAS를 2대까지만 실행되도록 해두었기 때문에 2로 설정함.
* 이보다 Partition을 크게 설정한다고 해서 Consume 속도가 빨라지지 않기 때문이다.
* @return
*/
@Bean
public NewTopic newTopic() {
return new NewTopic(topicName, Integer.parseInt(numPartitions), Short.parseShort(replicationFactor));
}
}Producer 설정
- 이벤트가 단 하나만 생성 되는것이 보장되는 것을 원한다면 ack:all, retry 0초과, max.in.flight.request.per.connection: 5이하, enable.idempotence:true로 설정해야만합니다.
- max.in.flight.request.per.connection 가 1이상이면 순서가 보장되지 않을 수 있습니다.
@Configuration
public class KafkaProducerConfig {
@Value("${kafka.bootstrapAddress}")
private String bootstrapServers;
/**
* ack: all
* In-Sync-Replica에 모두 event가 저장되었음이 확인 되어야 ack 신호를 보냄 가장 성능은 떨어지지만
* event produce를 보장할 수 있음.
*/
@Value("${kafka.producer.acksConfig}")
private String acksConfig;
@Value("${kafka.producer.retry}")
private Integer retry;
@Value("${kafka.producer.enable-idempotence}")
private Boolean enableIdempotence;
@Value("${kafka.producer.max-in-flight-requests-per-connection}")
private Integer maxInFlightRequestsPerConnection;
/**
* enable.idempotence true를 위해서는 retry가 0이상,
* max.in.flight.requests.per.connection 은 5이하여야한다.
* @return
*/
@Bean
public ProducerFactory<String, AlarmEvent> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.ACKS_CONFIG, acksConfig);
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
configProps.put(ProducerConfig.RETRIES_CONFIG, retry);
configProps.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, enableIdempotence);
configProps.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, maxInFlightRequestsPerConnection);
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate<String, AlarmEvent> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}Consumer 설정
@EnableKafka
@Configuration
public class KafkaConsumerConfig {
@Value("${kafka.bootstrapAddress}")
private String bootstrapServers;
@Value("${kafka.consumer.autoOffsetResetConfig}")
private String autoOffsetResetConfig;
@Value("${kafka.consumer.alarm.rdb-group-id}")
private String rdbGroupId;
@Value("${kafka.consumer.alarm.redis-group-id}")
private String redisGroupId;
@Bean
// @Qualifier("alarmEventRDBConsumerFactory")
public ConsumerFactory<String, AlarmEvent> alarmEventRDBConsumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.GROUP_ID_CONFIG, rdbGroupId);
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetResetConfig);
return new DefaultKafkaConsumerFactory<>(props,
new StringDeserializer(),
new JsonDeserializer<>(AlarmEvent.class));
}
@Bean
public ConsumerFactory<String, AlarmEvent> alarmEventRedisConsumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.GROUP_ID_CONFIG, redisGroupId);
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetResetConfig);
return new DefaultKafkaConsumerFactory<>(props,
new StringDeserializer(),
new JsonDeserializer<>(AlarmEvent.class));
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, AlarmEvent> kafkaListenerContainerFactoryRDB() {
ConcurrentKafkaListenerContainerFactory<String, AlarmEvent> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(alarmEventRDBConsumerFactory());
factory.getContainerProperties().setAckMode(AckMode.MANUAL);
// ContainerProperties containerProperties = factory.getContainerProperties();
// containerProperties.setIdleBetweenPolls(1000);
return factory;
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, AlarmEvent> kafkaListenerContainerFactoryRedis() {
ConcurrentKafkaListenerContainerFactory<String, AlarmEvent> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(alarmEventRedisConsumerFactory());
factory.getContainerProperties().setAckMode(AckMode.MANUAL);
return factory;
}
}
@KafkaListener
Event Consume시 실행할 로직을 구현합니다.
@KafkaListener는 ConcurrentKafkaListenerContainerFactory를 특정하여 실행되는 방식이기 때문에 이를 고려하여 작성하면 됩니다.
똑같은 produce된 event에 대해서 두가지 방식으로 (RDB, Redis)에서 Consumer되어야 하기 때문에 두가지 Consumer Group을 정의하고 각각 KafkaListener를 등록합니다.
kafkaLisener에서 ack를 명시적으로 지정하고 싶은 경우
factory.getContainerProperties().setAckMode(AckMode.MANUAL); 옵션을 지정해야합니다. 하지않을 경우 직렬화 관련 에러가 발생합니다.
@Slf4j
@Component
@RequiredArgsConstructor
public class AlarmConsumer {
private final AlarmService alarmService;
/**
* offset을 최신으로 설정.
* https://stackoverflow.com/questions/57163953/kafkalistener-consumerconfig-auto-offset-reset-doc-earliest-for-multiple-listene
* @param alarmEvent
* @param ack
*/
@KafkaListener(topics = "${kafka.topic.alarm.name}", groupId = "${kafka.consumer.alarm.rdb-group-id}",
properties = {AUTO_OFFSET_RESET_CONFIG + ":earliest"}, containerFactory = "kafkaListenerContainerFactoryRDB")
public void createAlarmInRDBConsumerGroup(AlarmEvent alarmEvent, Acknowledgment ack) {
log.info("createAlarmInRDBConsumerGroup");
alarmService.createAlarm(alarmEvent.getUserId(), alarmEvent.getType(), alarmEvent.getArgs());
ack.acknowledge();
}
@KafkaListener(topics = "${kafka.topic.alarm.name}", groupId = "${kafka.consumer.alarm.redis-group-id}",
properties = {AUTO_OFFSET_RESET_CONFIG + ":earliest"}, containerFactory = "kafkaListenerContainerFactoryRedis")
public void redisPublishConsumerGroup(AlarmEvent alarmEvent, Acknowledgment ack) {
log.info("redisPublishConsumerGroup");
alarmService.send(alarmEvent.getUserId(),
alarmEvent.getEventName());
ack.acknowledge();
}
}
Fail Fast