0. 이전 포스트
- 이전 포스트에서 테스트 시나리오, 테스트 장애지점, 테스트 병목원인에 대해서 분석하여습니다.
- 이번 포스트에서는 해당 병목을 해결하기 위해서 Thread pool, DBCP적정 값을 설정해보려고 합니다.
1. Thread pool
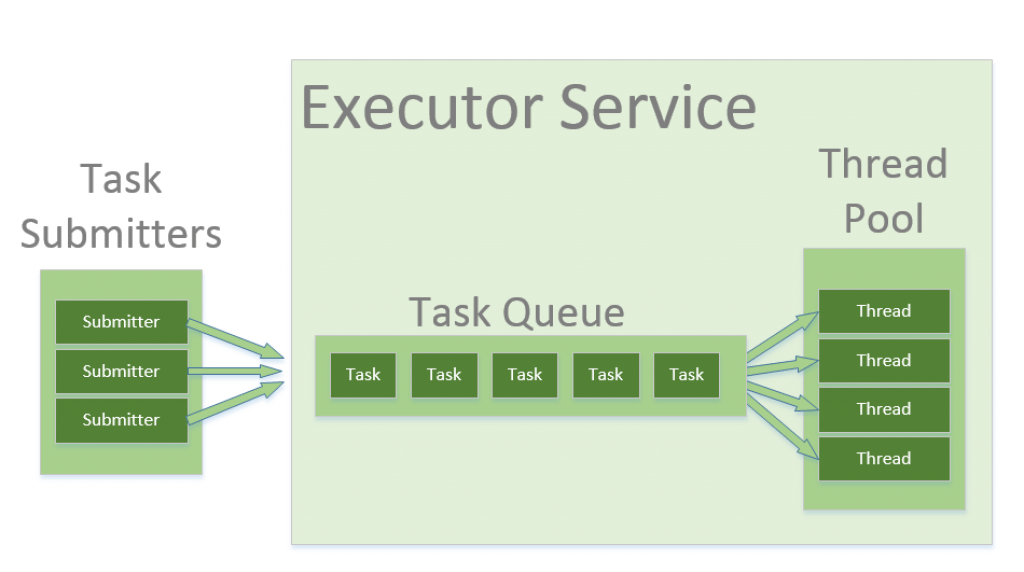
1-1. Thread pool 왜 사용해야할까?
- Thread는 바로 생성될 수 없다.
요청이 온 순간에 생성한다면 그 만큼 응답시간이 지연될 수 있다. - Thread 생성 시 메모리 자원을 소모한다.
각각의 thread는 JVM내에서 Stack, PC Register등의 메모리 자원을 독립적으로 할당 받아야한다. - Thread가 많다고 해서 성능이 항상 향상 되지 않으며 오히려 하락할 수 있다.
CPU-bound인 경우 하드웨어 스레드 개수 만큼의 스레드 생성은 성능 향상을 가져오지만, 이 이상 스레드가 생성되어도 Context Switching으로 인한 Overhead만 증가하고 성능이 오히려 하락한다.
I/O-bound인 경우 Thread per Request model의 경우 하드웨어 스레드보다 많은 Thread를 생성하면 I/O작업으로 인해 CPU에 Thread가 할당 되지 않는 경우를 방지하여 성능을 향상시킬 수 있다. 하지만 이 경우 또한 너무 많은 스레드 개수는 Context Switching으로 인한 Overhead만 증가시킬 수 있다. - Thread Pool size, waiting Queue의 한계가 지정되어 있지 않은 경우 장애 요인이 될 수 있다.
스레드, Waiting Queue는 메모리 자원을 차지한다. 요청이 들어오는 만큼 무한정 늘려서 메모리 자원을 차지하게 한다면 메모리 부족 상태에 도달하여 장애 발생 요인이 될 수 있다.
1-2. Thread Pool Size 설정 기준
Little's Law
https://davidasync.medium.com/littles-law-tuning-the-thread-pool-size-fedfe4158fb
https://www.infoq.com/articles/Java-Thread-Pool-Performance-Tuning/
https://engineering.zalando.com/posts/2019/04/how-to-set-an-ideal-thread-pool-size.html
Little's Law는 초당 처리되길 원하는 요청 수와 하나의 요청을 서버내에서 처리하는데 걸리는 시간(스레드 점유시간)을 곱하여 스레드 개수를 정하는 식이다.
L = λ * W
L - the number of requests processed simultaneously
λ – long-term average arrival rate (RPS)
W – the average time to handle the request (latency)경험적으로 찾기
처음 값은 Little's Law와 같은 방식으로 대략적으로 정한 후 조절해가면서 테스트 한다.
1-3. ThreadPoolExecutor와 설정 주요 옵션
https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/ThreadPoolExecutor.html
위 링크의 메뉴얼에 정말 잘 설명 되어있기 때문에 가셔서 보시는걸 추천합니다.
- Queueing
- Direct handoffs.(SynchronousQueue )
default로 활용된다. 새로운 요청이 들어오면 큐에 저장하지 않고 바로 thread 로 넘겨주며 새로운 스레드를 생성한다.- Unbounded queues.(LinkedBlockingQueue without a predefined capacity)
링크드리스트를 이용한 큐로 만들면 용량을 지정하지 않을 경우 Queue에 무한정 Task가 쌓이게 만들 수 있다. Queue에 무한정 자원이 쌓여 장애가 발생가능하다.- Bounded queues.(ArrayBlockingQueue)
큐의 사이즈를 ArrayBlockingQueue로 제한한다.
일반적으로 thread poool설정을 할때 이 Queue를 활용한다.
- Core and maximum pool sizes
thread pool size를 지정한다. core size는 유지하려는 thread size이고 maximum pool size 최대값이다.queue size가 지정되어 있을 경우 queue가 가득 찼을 때 core size 스레드가 이미 다 사용되고 있을 때에 maximum pool size까지 thread가 생성된다.
1-4. Tomcat Thread pool설정 방법
해당 문서를 보고 ThreadPoolExecutor, ThreadPoolTaskExecutor를 Bean으로 등록하면 되는 줄 알았는데 우리가 원하는 Tomcat의 Thread pool을 대체하기 위해서는 다음 설정을 이용해아한다.
- 해당 문서를 참고하여 필요한 내용을 추가하면 된다.
https://docs.spring.io/spring-boot/docs/current/reference/html/application-properties.html
server:
tomcat:
threads:
max: 18 # maximumPoolSize
min-spare: 18 corePoolSize
accept-count: 300 QueueSize
port: 80801-5. @Async 비동기 스레드 스레드 풀 설정
- 스레드 풀을 ThreadPoolTaskExecutor를 통해 생성해주고 빈으로 등록한다.
- @Async에 해당 빈이름을 지정한다. @Async로 AOP를 통해 비동기 스레드를 할당 받을 때 해당 빈에서 할당받게 된다.
@Configuration
public class AsyncThreadPoolConfig {
/**
* Async Thread pool 별도 사용
*/
@Bean
public ThreadPoolTaskExecutor threadPoolTaskExecutor() {
ThreadPoolTaskExecutor threadPoolTaskExecutor = new ThreadPoolTaskExecutor();
threadPoolTaskExecutor.setCorePoolSize(5);
threadPoolTaskExecutor.setMaxPoolSize(10);
threadPoolTaskExecutor.setQueueCapacity(100);
threadPoolTaskExecutor.setKeepAliveSeconds(60);
return threadPoolTaskExecutor;
}
}2. Database Connection Pool
2-1. DBCP를 사용해야하는 이유
DB Connection을 생성하기 위해 많은 시간이 소요된다.
- 애플리케이션 로직은 DB 드라이버를 통해 커넥션을 조회한다.
- DB 드라이버는 DB와 TCP/IP 커넥션을 연결한다. 물론 이 과정에서 3 way handshake 같은 TCP/IP
연결을 위한 네트워크 동작이 발생한다. - DB 드라이버는 TCP/IP 커넥션이 연결되면 ID, PW와 기타 부가정보를 DB에 전달한다.
- DB는 ID, PW를 통해 내부 인증을 완료하고, 내부에 DB 세션을 생성한다.
- DB는 커넥션 생성이 완료되었다는 응답을 보낸다.
- DB 드라이버는 커넥션 객체를 생성해서 클라이언트에 반환한다.
2-2. DBCP Size 설정 기준
DB max_connections
DB설정 중에는 max_connections라는 설정이 있는데 Client에 최대 몇개까지의 연결을 허용할지를 의미합니다. max_connections 가 80 이라면 WAS가 4대인 경우 DB connection을 20개까지 생성할 수 있습니다. 20개 보다 많게 설정한다면 연결을 수립되지 않을 것입니다. 또한, 다른 Client로부터의 요청도 있을 수 있기 때문에 여유분을 두어 85개정도로 설정하는 것이 바람직합니다.
max_connections 는 어떻게 정할까 AWS에서는 RDS 스펙중 메모리를 고려하여 max_connections를 동적으로 정해줍니다.
대략 t3.micro인 경우 80~90 개 정도 됩니다.
RDS max_connections 공식문서
DBCP Deadlock 주의
- 해당 링크는 이전에 작성했던 글인데 Thread pool size와 DBCP size에 따라서 DB Connection이 부족해지면서 Deadlock이 발생할 수 있는 상황에 대해서 말하고 있습니다. Thread pool size > DBCP 인 경우 주의해야합니다.
DBCP Deadlock 발생
Throughput 고려
- 만약 0.5초 동안 Connection 을 사용하는 트랜잭션을 초당 1000개 처리하고 싶다면 대략적으로 500개 정도 되는 DBCP connection 이 필요하게 됩니다.
실험적으로 맞추기
위 사항들에 주의하면서 DBCP값을 조정해야합니다. DBCP는 다 active인데 DB에 자원이 여유롭다면 DBCP값을 조정하거나 WAS를 늘릴 필요가 있습니다.
2-3. HicariCP설정 주요 옵션
1) connectionTimeout (default : 30000 (30 seconds))
클라이언트가 pool에 connection을 요청하는데 기다리는 최대시간을 설정합니다.
설정한 시간을 초과하면 SQLException이 발생합니다. (허용 가능한 최소 연결 시간은 250ms )
2) maximunPoolSize (default : 10)
유휴 및 사용중인 connection을 포함하여 풀에 보관가능한 최대 커넥션 개수를 설정합니다.
사용할 수 있는 커넥션이 없다면 connectionTimeout 시간 만큼 대기하고 시간을 초과하면 SQLException이 발생합니다.
3) minimumIdle (default : maximumPoolSize와 동일)
connection pool에서 유지가능한 최소 커넥션 개수를 설정합니다.
최적의 성능과 응답성을 원하면 이 값을 설정하지 않는게 좋다고 합니다.
항상 maximumPoolSize가 우선순위를 가진다.
4) idleTimeout (default : 600000 (10분))
connection pool에서 유휴 상태로 유지시킬 최대 시간을 설정합니다.
이 설정은 minimumIdle이 maximumPoolSize보다 작은 경우에만 사용할 수 있습니다.
pool에 있는 connection이 minimumIdle에 도달할 경우 이후에 반환되는 connection에 대해서 바로 반환하지 않고 idleTimeout 만큼 유휴 상태로 있다가 폐기됩니다.
5) maxLifeTime (default : 1800000 (30분))
connection의 최대 유지 시간을 설정합니다.
connection의 maxLifeTime 지났을 때, 사용중인 connection은 바로 폐기되지않고 작업이 완료되면 폐기됩니다.
하지만 유휴 커넥션은 바로 폐기됩니다.
중요! maxLifeTime 설정은, db의 wait_timeout 보다 2~3초 짧게 주자. 좀더 여유있게 준다면 5초 정도 짧게 주면 된다.이렇게 하지않으면 DB Connection 객체는 남아있는 데 DBMS에서는 Connection이 종료되어 예외가 발생할 수 있다.
6) readOnly (default : false)
pool에서 얻은 connection이 기본적으로 readOnly인지 지정하는 설정입니다.
데이터베이스가 readOnly 속성을 지원할 경우에만 사용할 수 있습니다.
7) connectionTestQuery (default : none)
데이터베이스 연결이 여전히 활성화되어있는지 확인하기 위해 pool에서 connection을 제공하기 전에 실행되는 쿼리입니다.
드라이버가 JDBC4를 지원하는 경우 이 속성을 사용하지 않는 것이 좋다고합니다.
2-4. HicariCP설정 방법
spring:
datasource:
hikari:
connectionTimeout : 30000
maximumPoolSize : 20
maxLifetime : 295000 # db wait_timeout 보다 짧게 유지
poolName : HikariCP
readOnly : false3. Thread Pool, DBCP 튜닝 후 테스트
3-1. 설정 값
Thread pool
- max: 18 # maximumPoolSize
- min-spare: 18 corePoolSize
- accept-count: 300 QueueSize
HikariCP
- connectionTimeout : 30000
- maximumPoolSize : 20
- maxLifetime : 295000 # db wait_timeout 보다 짧게 유지
RDS
- max_connections: 85
- wait_timeout: 300
3-2. Scalability Test 후 결과
부하 테스트 조건은 이전 포스트 시나리오와 동일합니다.(방 생성, 참여, 취소, 조회가 특정 비율로 일어남.)
테스트 조건
-
조회 api
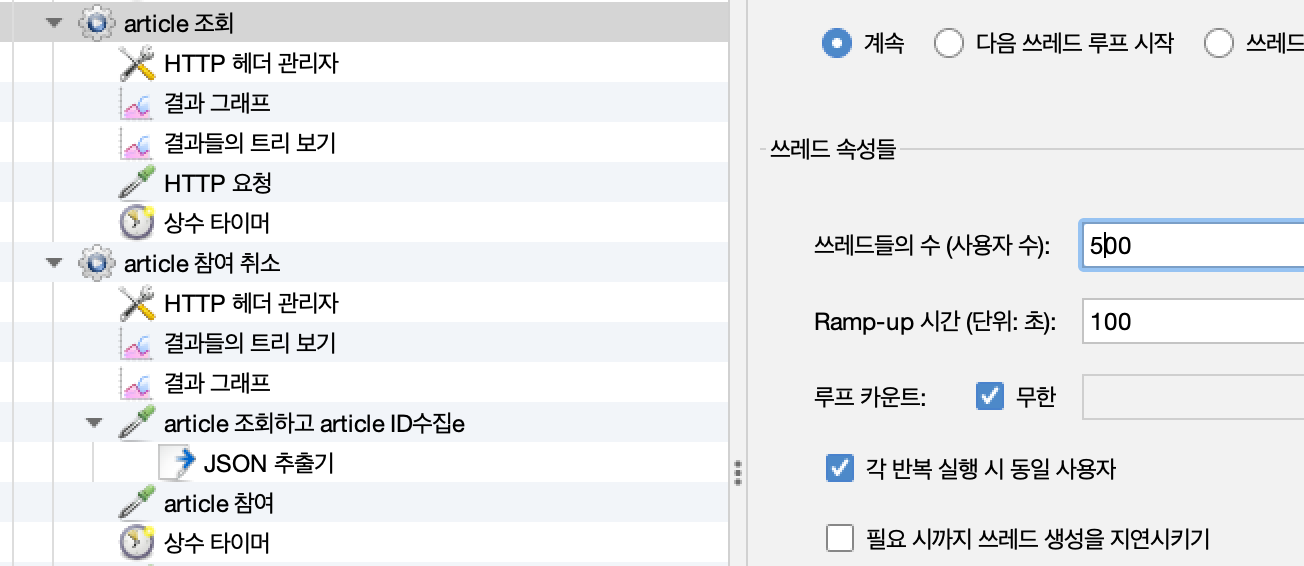
-
수정및 Redis pub/sub, Kafka 이벤트 produce가 발생하는 api
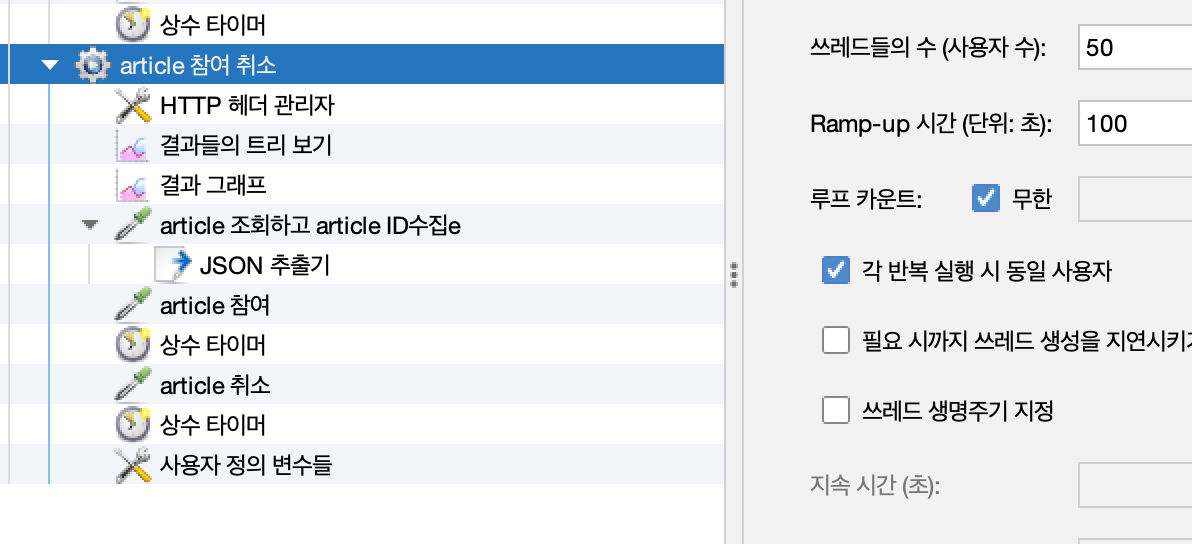
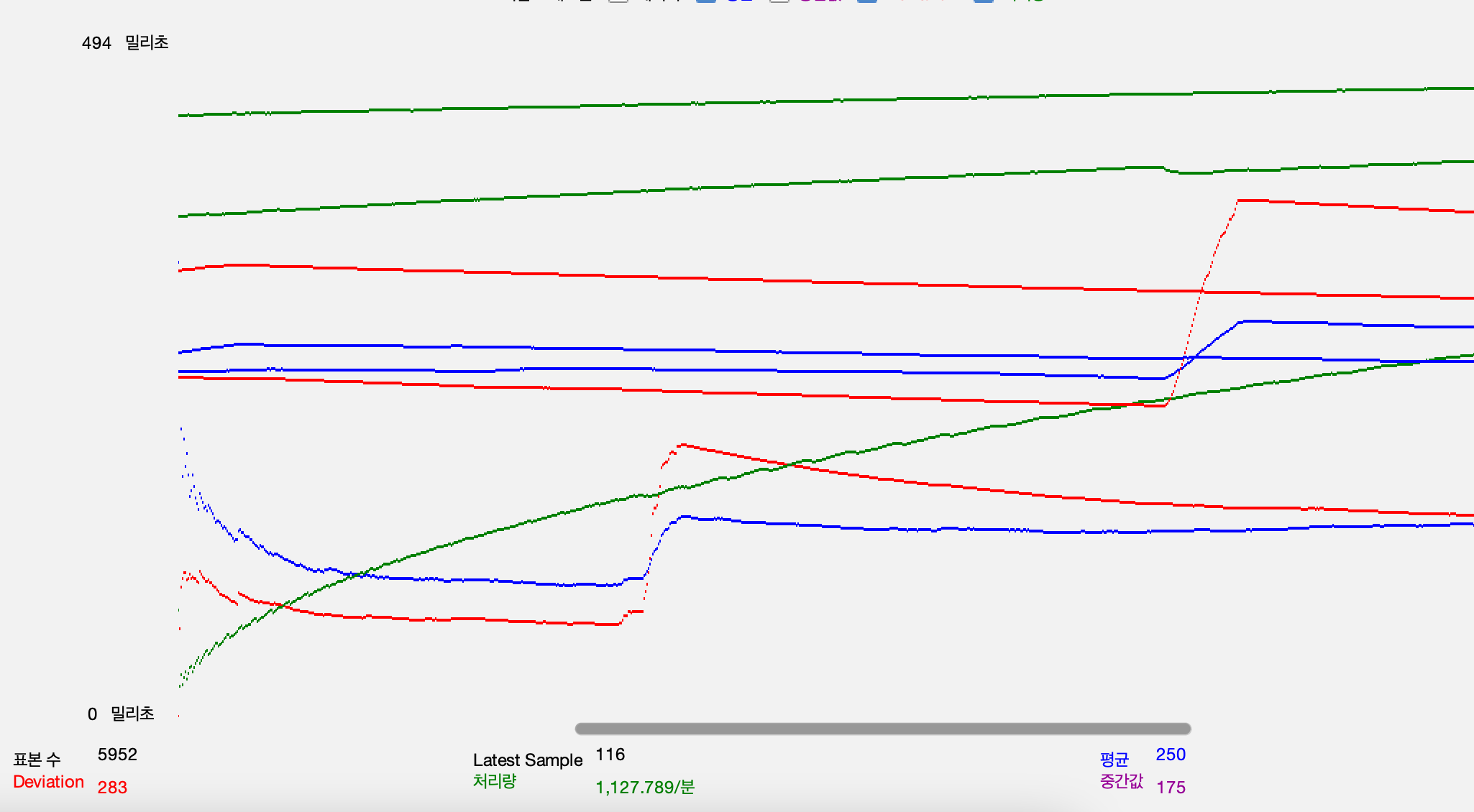
테스트 결과
이전과 달리 서버가 비정상 종료하지 않고 부하를 견뎌냈음을 확인할 수 있었습니다. 따라서 DBCP의 수를 늘리고 Thread pool제한을 준 것이 병목지점을 일부 해결했다고 볼 수 있습니다.
Throughput, Response time 평균, 표본 편차
-
조회 api
테스트 데이터가 너무 많아서 충첩되어 보이는데 처리량이 지속적으로 증가하다가 일정 이상으로 올라가지 않는 것이 보입니다. 이때 응답시간의 표준편차가 높지 않게 유지되는 것으로 보아 해당 부하까지는 잘 처리하고 있는 것으로 볼 수 있습니다. 병목 지점을 추가적으로 확인하기 위해서는 부하를 더 늘려서 테스트해야합니다.
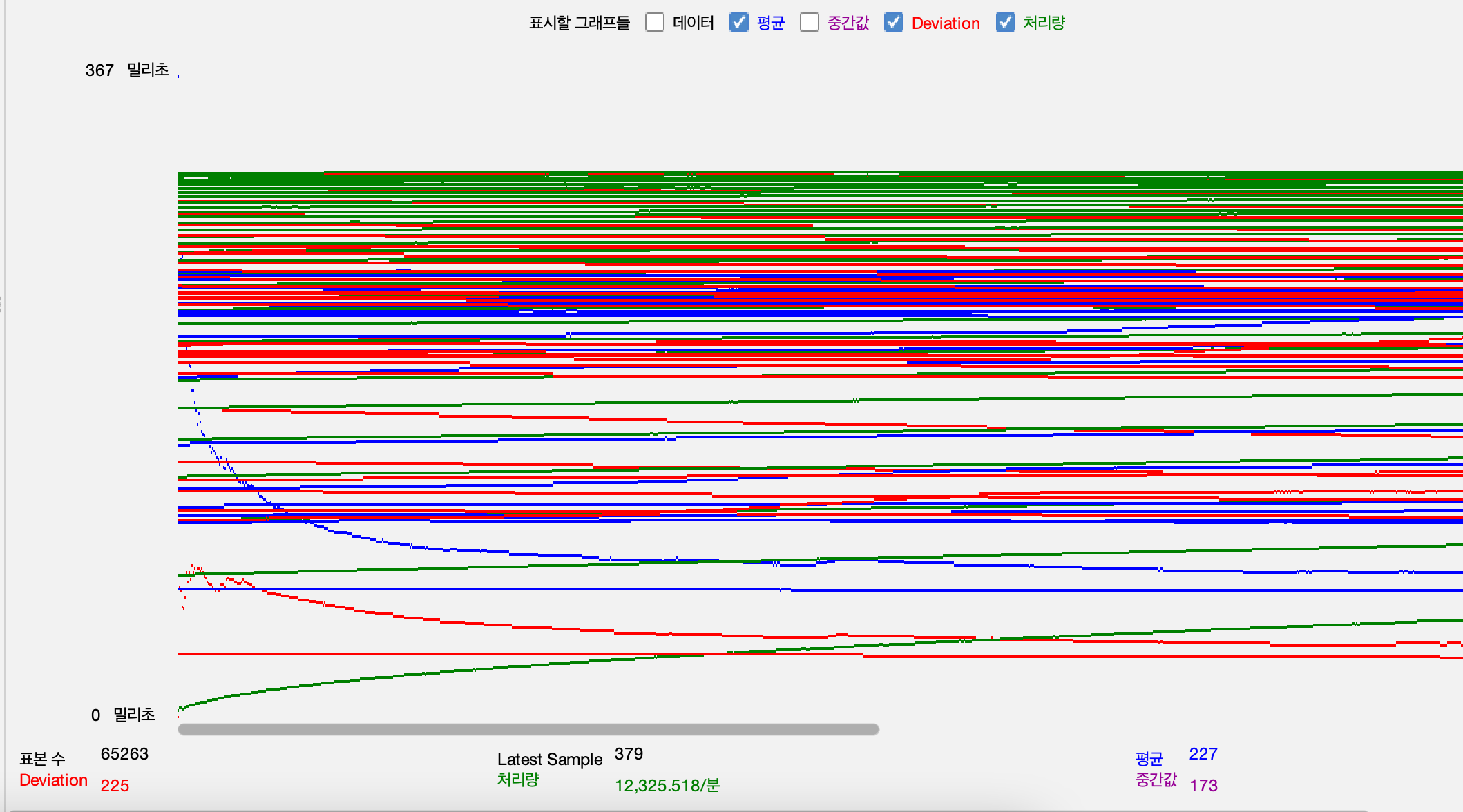
-
수정및 Redis pub/sub, Kafka 이벤트 produce가 발생하는 api
Web Application Server
-
CPU
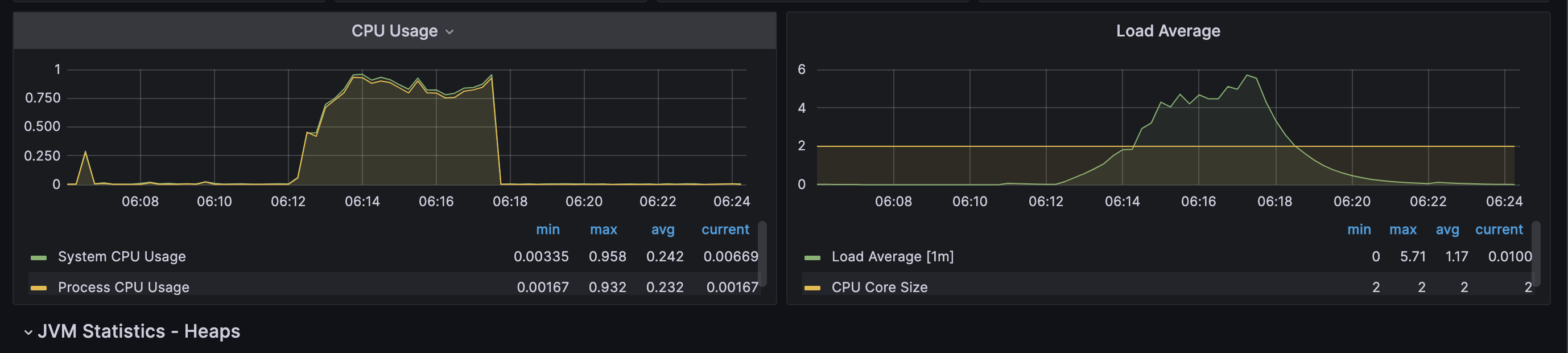
-
DBCP
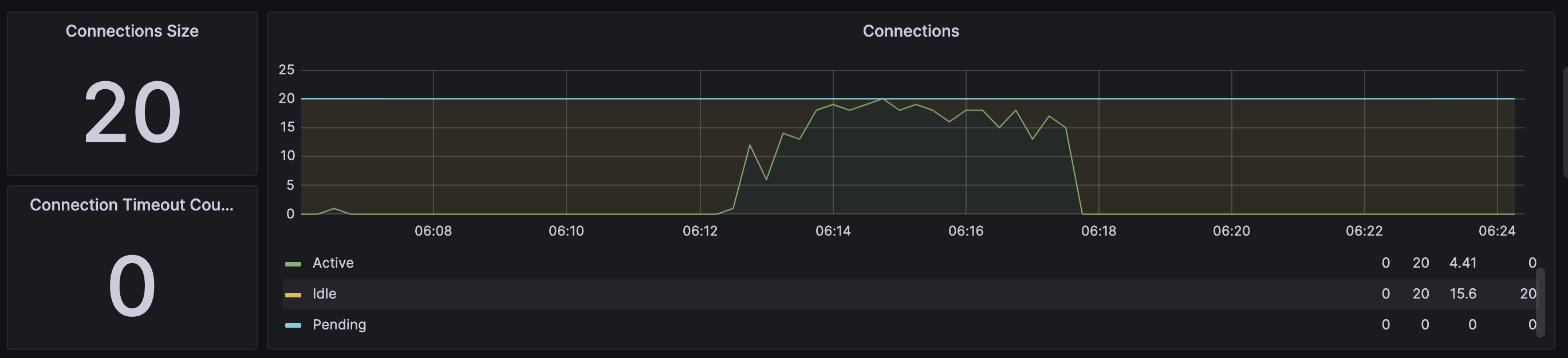
RDS
- RDS의 경우도 CPU사용량은 늘었지만 DBCP증가로 트랜잭션을 잘 처리하고 있다.
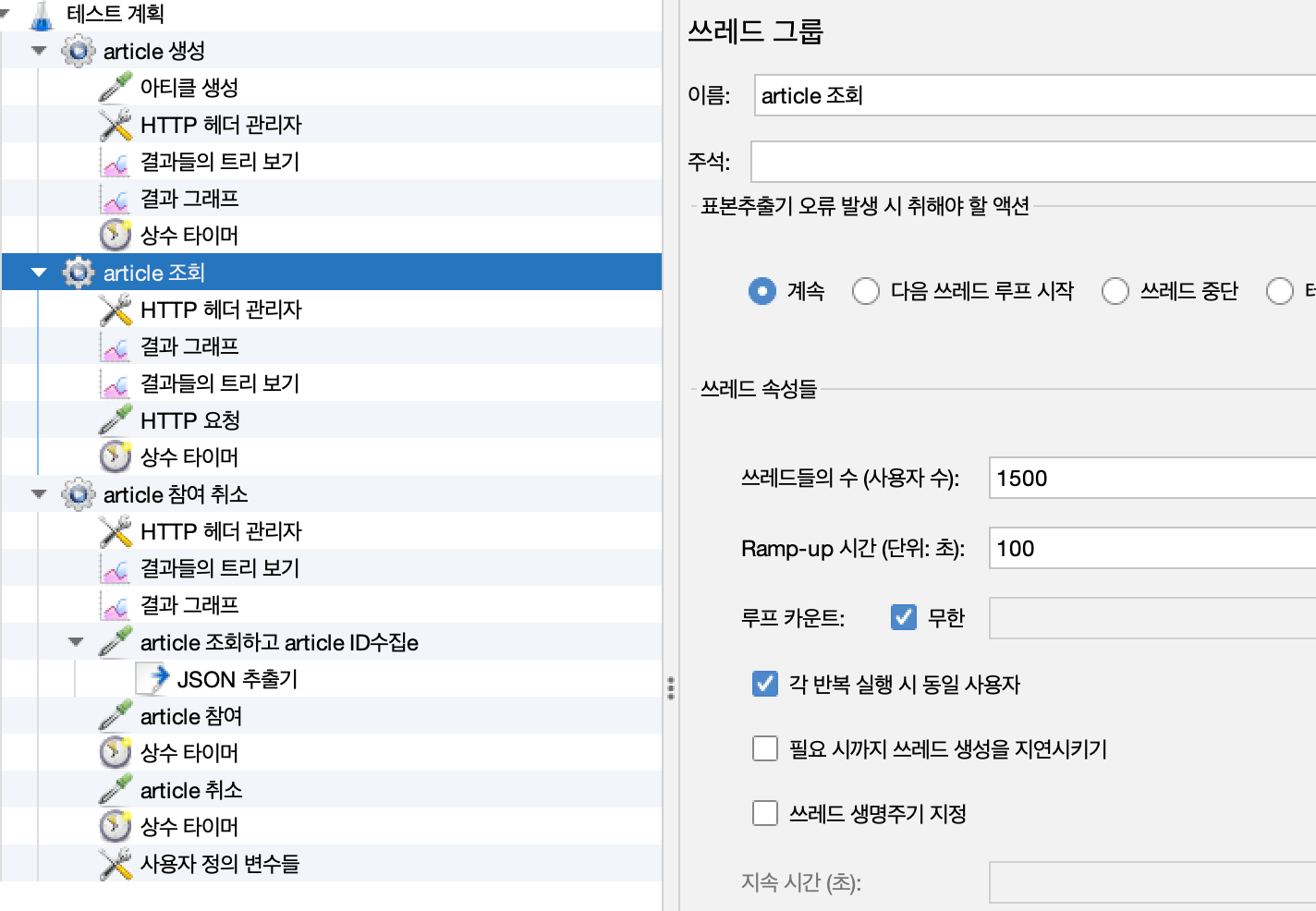
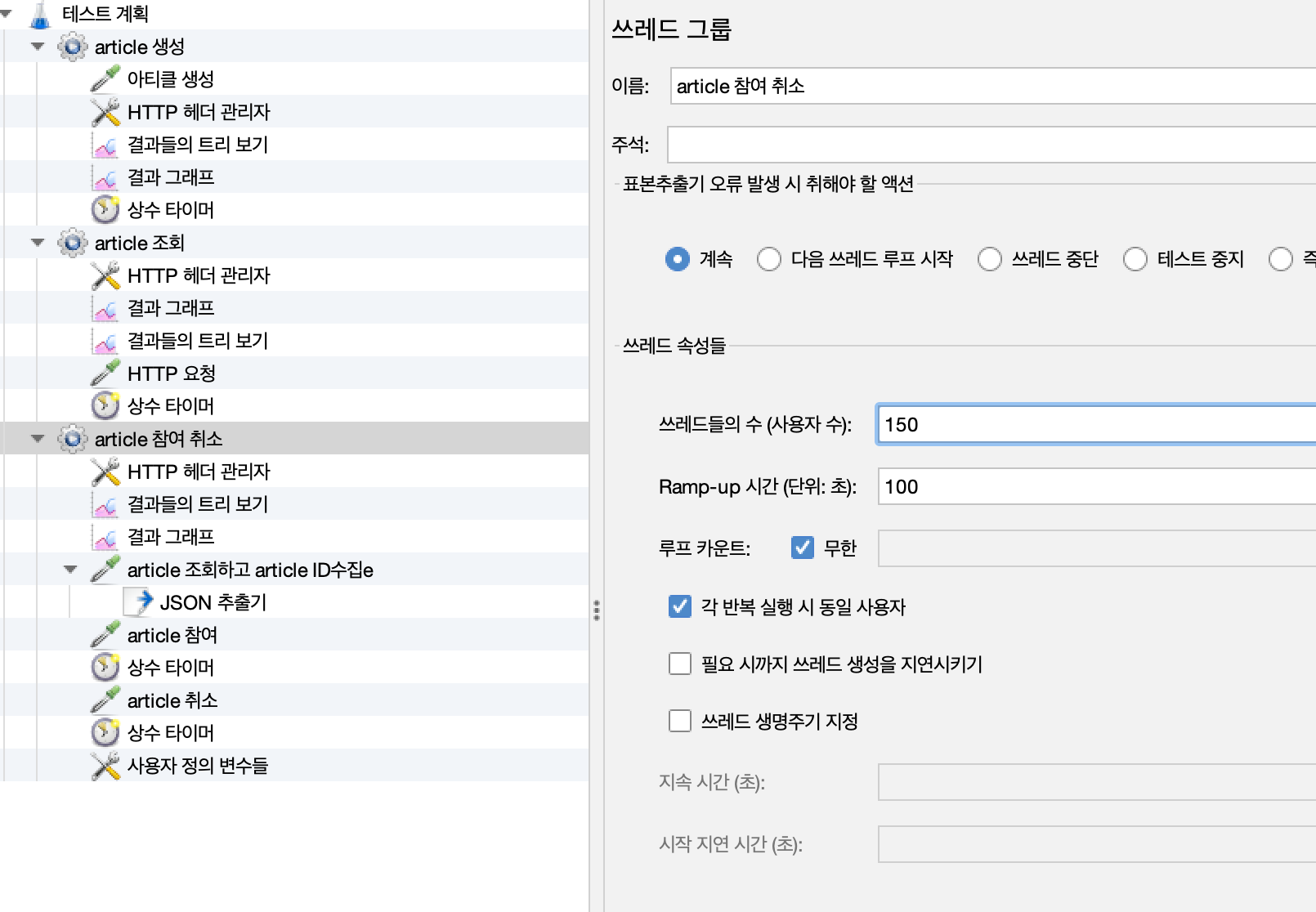
4. 부하를 늘려 테스트 (요청 수 3배)
4-1. 테스트 부하 3배로 수정
조회
방매칭 참여 취소
4-2. 테스트 결과
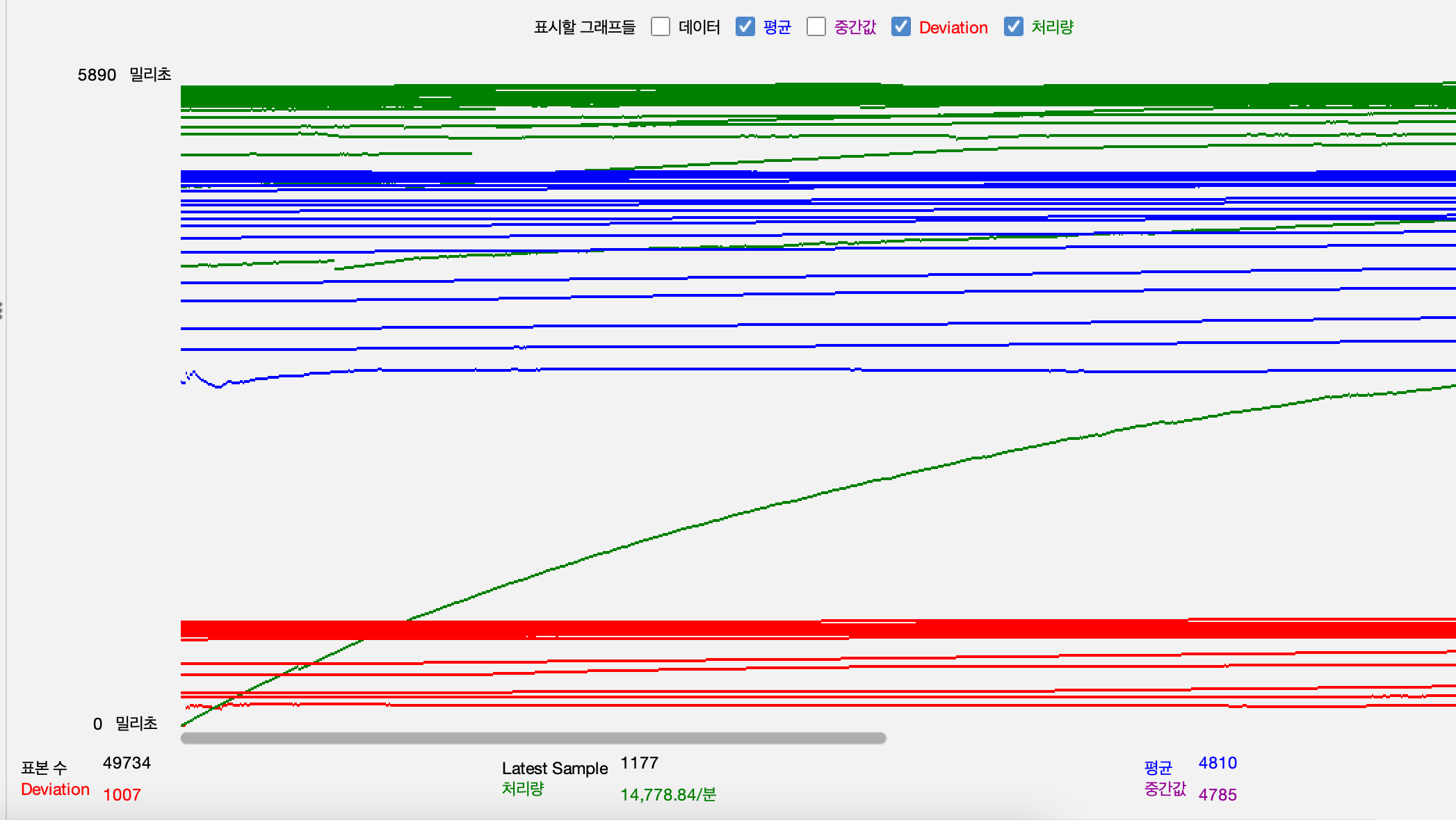
Throughput, Response time 평균, 표본 편차
- 조회 api
- 방 매칭 참여, 취소 api
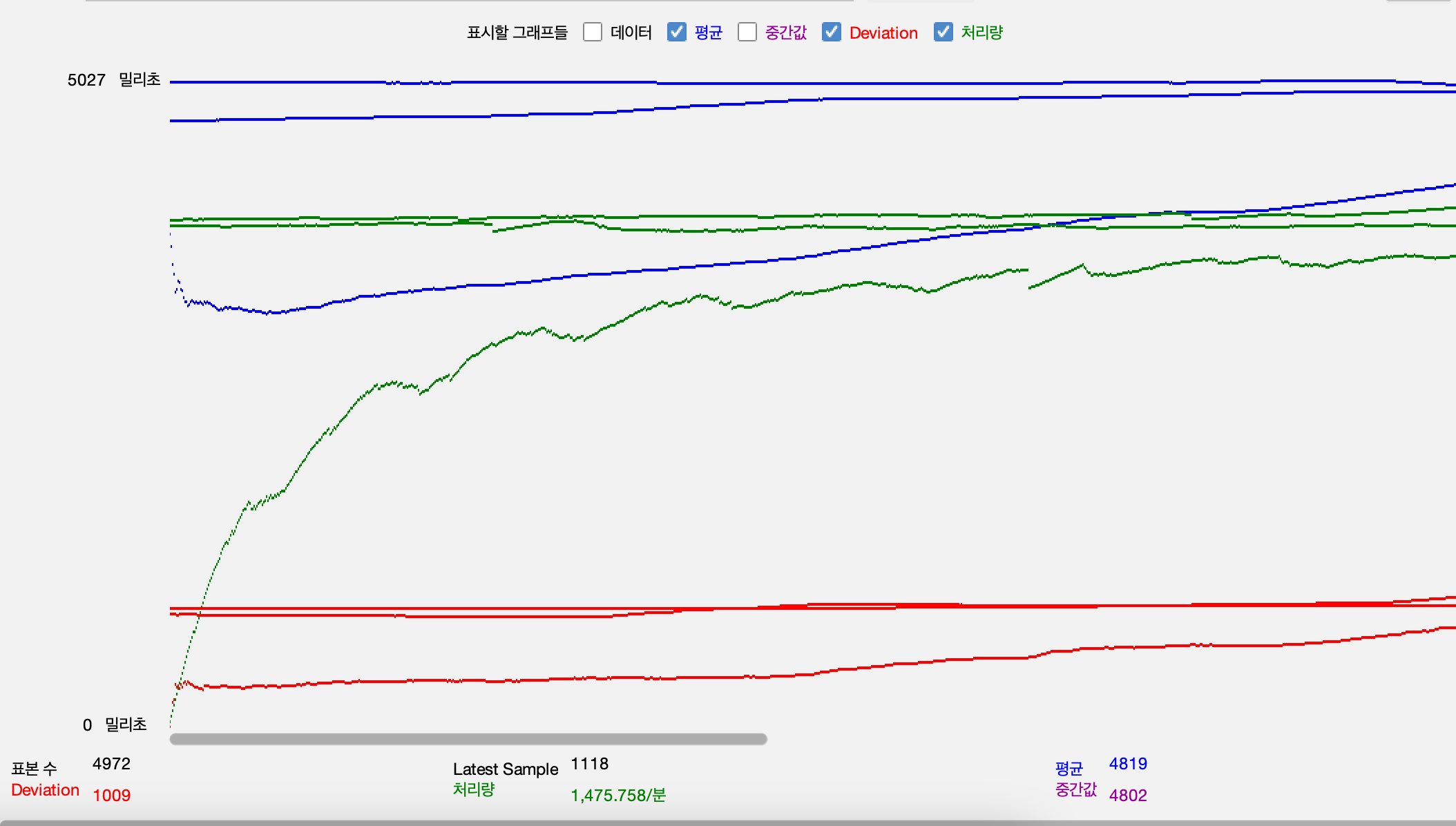
AWS 모니터링과 Grafana 모니터링 시간이 다른 이유는 AWS의 경우 시간대가 다르게 설정되어있어서 그렇습니다.
Web Application Server
-
CPU

-
Heap
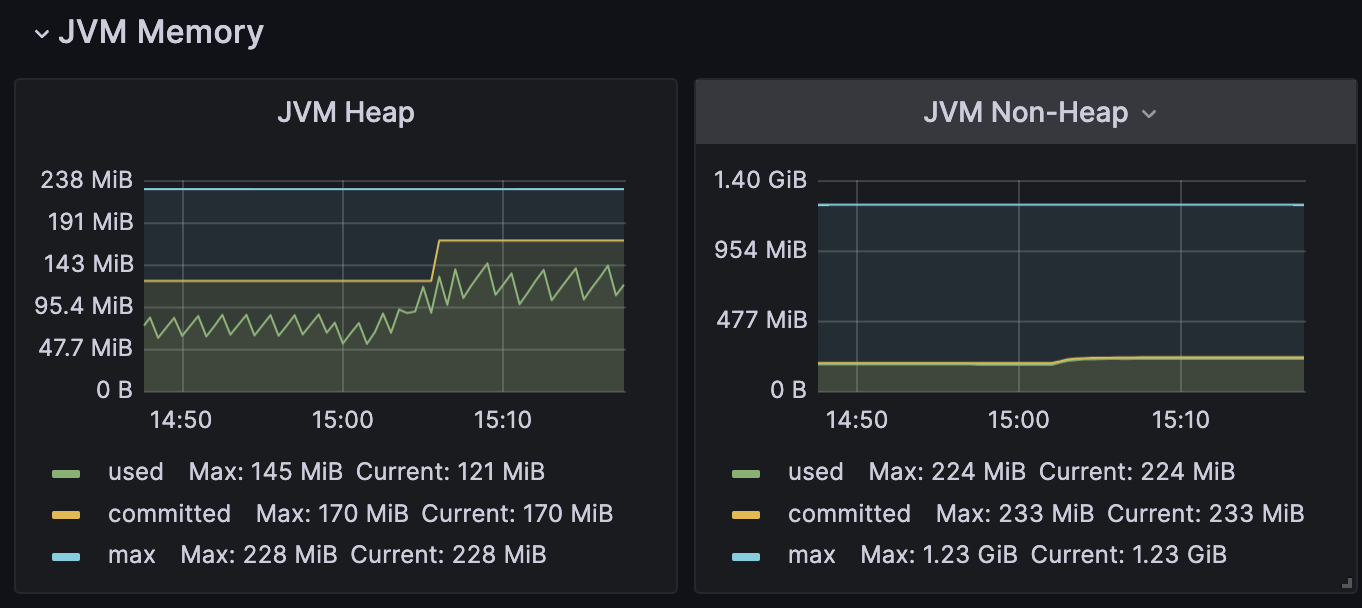
-
Major GC
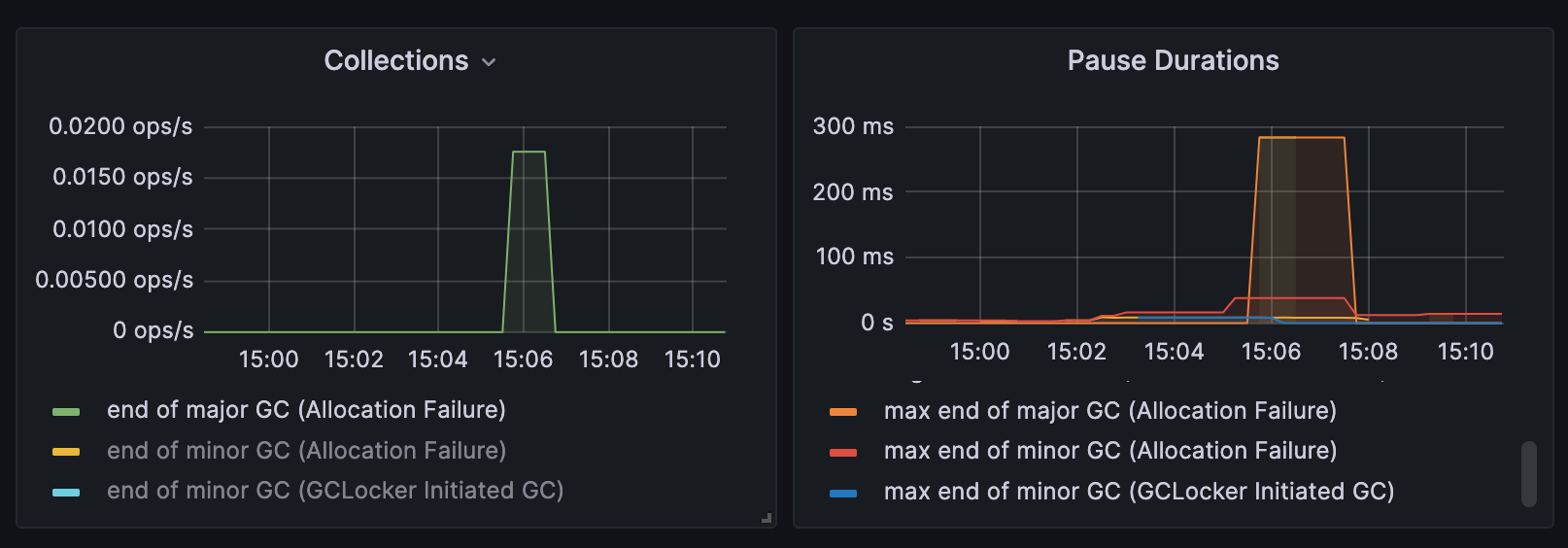
-
Minor GC
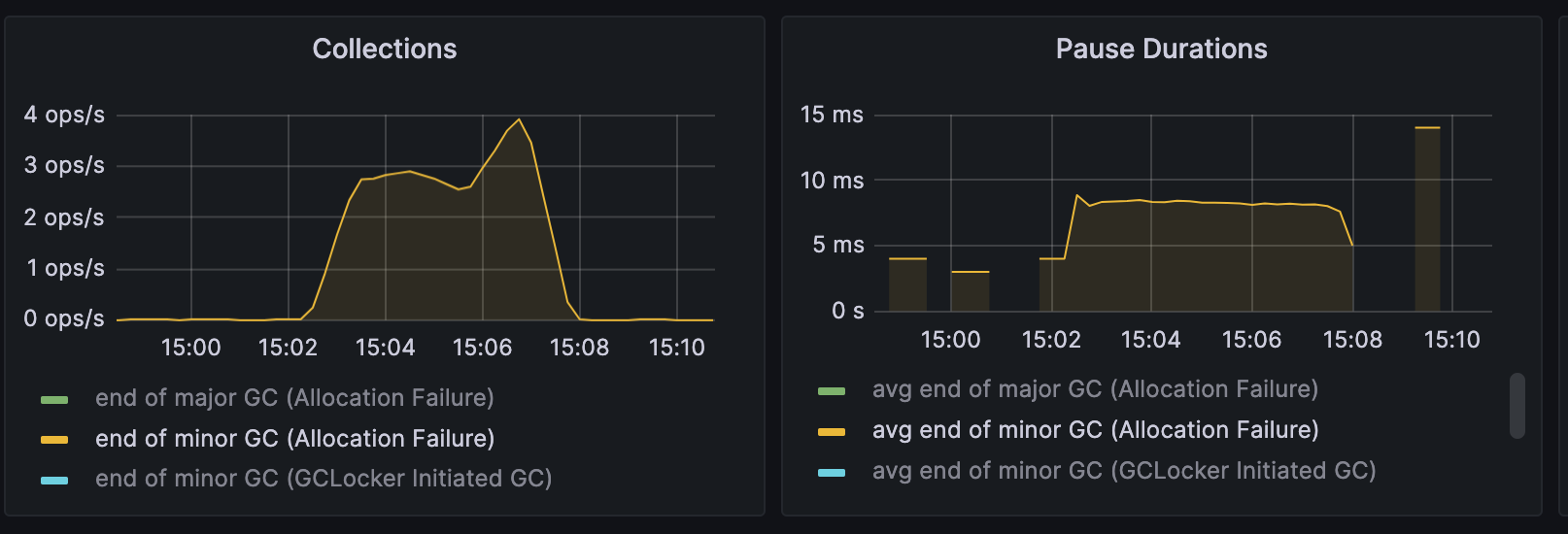
-
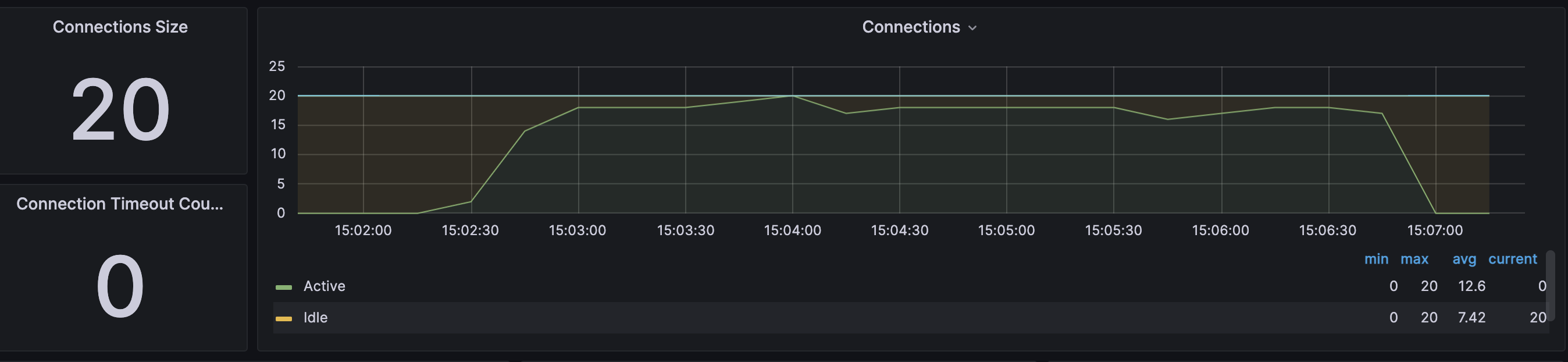
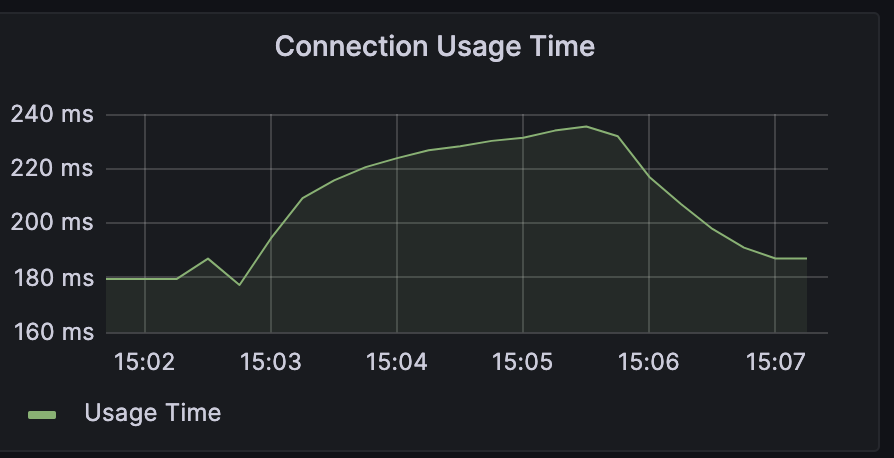
DBCP
DBCP가 거의 다 활용되고 있다. 하나의 Connection의 사용 시간이 증가하는 모습을 볼 수 있다. RDS자체에 부하가 발생하기 때문으로 보인다.
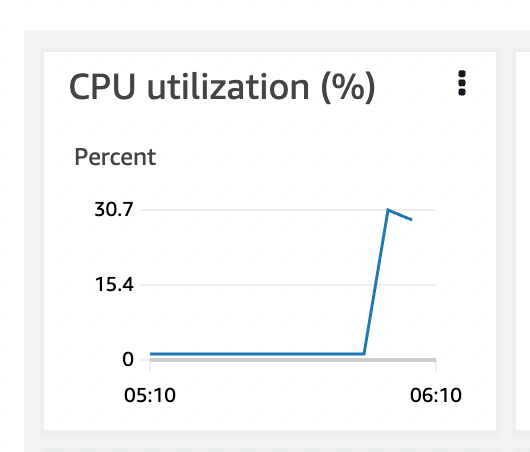
EC2 자체 하드웨어 사용률
- CPU
- JVM에 할당된 CPU Usage에 비해 EC2의 CPU사용률이 적다. JVM이 CPU자원을 더 많이 할당 받을 수 있다면 좋을 것 같다.
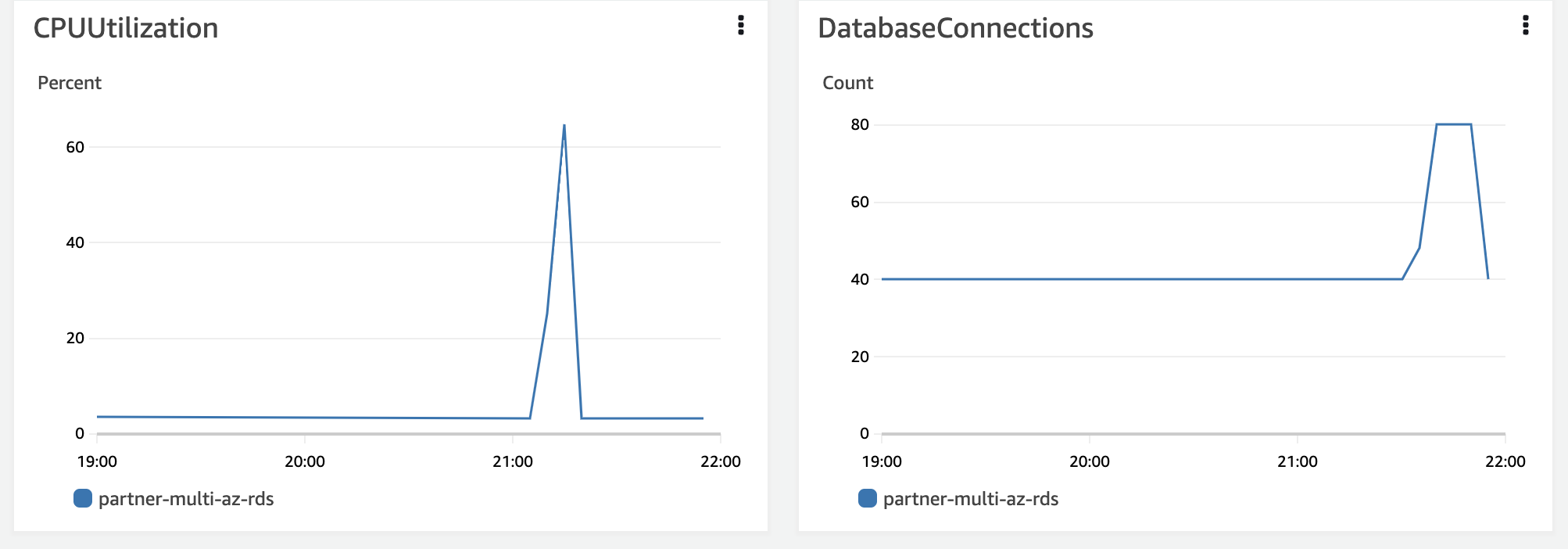
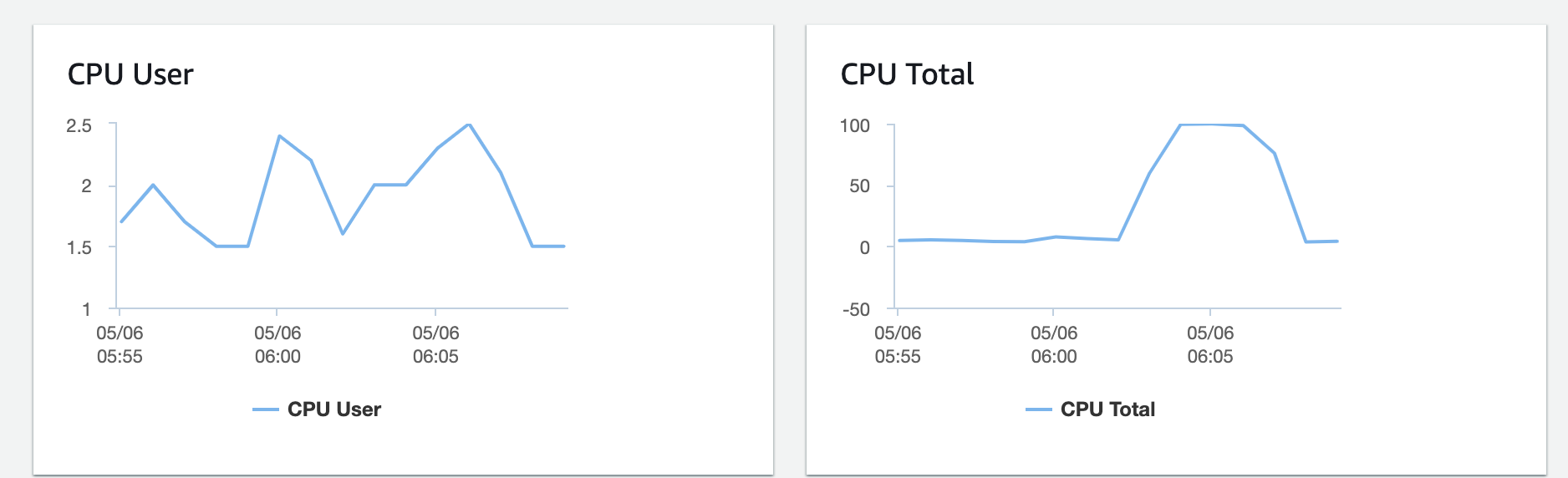
RDS
처음으로 RDS의 CPU가 100% 까지 활용되었다. DB자체에 병목이 생기는 지점에 도달하였다.
4-3. AWS ASG Dynamic Scaling Policy
- 현재 ASG의 Scaling 정책은 CPU 50이 넘으면 증설되게 되어있습니다.
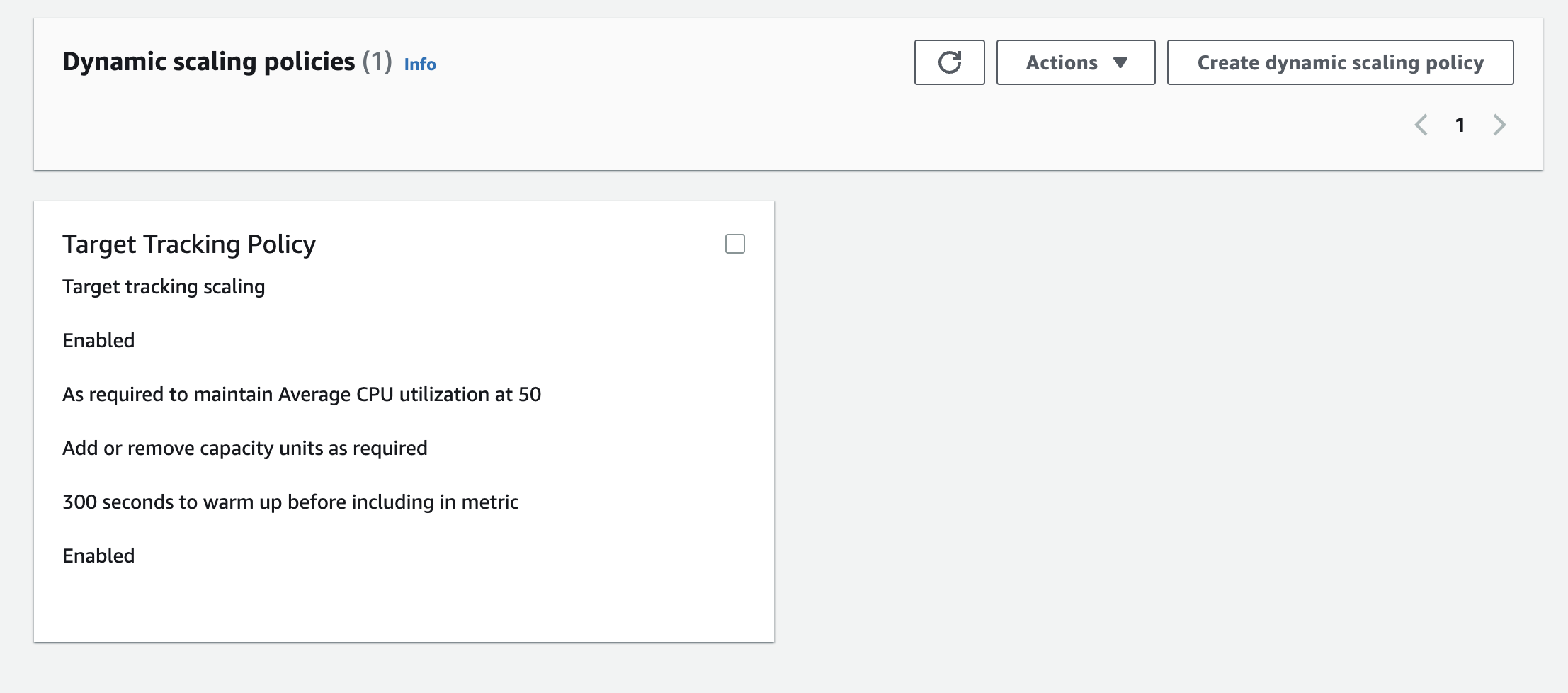
- 3배의 부하 테스트 과정에서 Auto scaling이 되어 WAS가 2배로 총 4대가 되었습니다.
기대하는 결과는 ASG에 WAS증설이 응답시간을 낮추고 TPS를 증가시켜 주길 원합니다.
4-4. 병목이 생긴 이유를 계산을 통해 파악해보자.
- 위에서의 그래프를 보면 DB Connection당 하나의 트랜잭션을 처리하는데 0.2s정도가 걸린다.
- 그런데 DBCP는 최대 80개를 사용할 수 있다.
- 산술적으로 초당 최대 400개의 트랜잭션을 처리할 수 있다는 의미이다.
- 반면 현재 요청은 JMeter에서 1500의 스레드가 응답을 받은 후 1초마다 발생시키도록 설정해두었다. 따라서 하나의 요청이 2초마다 온다고 여유를 두더라도 750~1000개의 요청이 초마다 오기 때문에 트랜잭션을 모두 처리할 수 없다.
- 반면 3배로 부하를 조절하기 이전에는 초당 대략 250~330개의 요청이었기 때문에 심각한 Response time 저하 없이 요청을 처리할 수 있었다.
4-5. 테스트 결과 분석
- 부하 증가 전과 달리 DBMS, DBCP, WAS CPU등의 자원이 최대 치까지 사용된다.
- 3배의 부하에서는 서버가 종료되거나, DB가 종료되는 등의 문제는 발생하지 않았지만 응답시간 평균이 5000ms정도로 서비스가 정상적으로 운영되기 힘든 수준에 도달한다.
- 테스트 상황 중 ASG에 의해서 WAS가 2배로 증설되었고, DBCP또한 2배가 되었지만 12000 정도의 분당 트랜잭션이 14000정도까지 밖에 증가 되지 않았으며 응답시간은 5초에 육박한다. WAS가 병목된 것이 아니기 때문에
- DB 사용률이 100%에 도달 했기 때문에 DB에서 병목이 발생한 것으로 보인다.
4-6. 테스트 결과 결론
ASG에 의해서 WAS가 2배로 증가되어도 증가전과 마찬가지로 부하를 해결 하지 못했고 DB 성능도 100% 가까이 사용되는 것으로 보아 DB에서 병목이 발생했다.
5. 결과 요약
DBCP 병목 해결 결과
DBCP로 인한 병목을 해결하여
- Article 조회 기준
1. TPS 66 -> 200 으로 3배 증가
2. 응답 시간 3.6s -> 0.2s- Article 참여, 취소 기준
1. TPS 7 -> 18 으로 2.5배 증가
2. 응답 시간 3.6s -> 0.25s
추가적인 요청 부하 증가(요청 스레드 3배 증가)시 DB에서 병목 발생
- Article 조회 기준
1. TPS 200 -> 240 으로 1.2배 증가
2. 응답 시간 0.2 -> 5.5s- Article 참여, 취소 기준
1. TPS 18 -> 22 으로 1.2배 증가
2. 응답 시간 0.2s -> 5.5s
결국에 DB가 병목인 상황을 맞이했습니다. 이를 해결하기 위해 다음 포스트에서는 Cache를 통해 DB에 가해지고 있는 읽기 부하를 분산시켜보고자 합니다.
