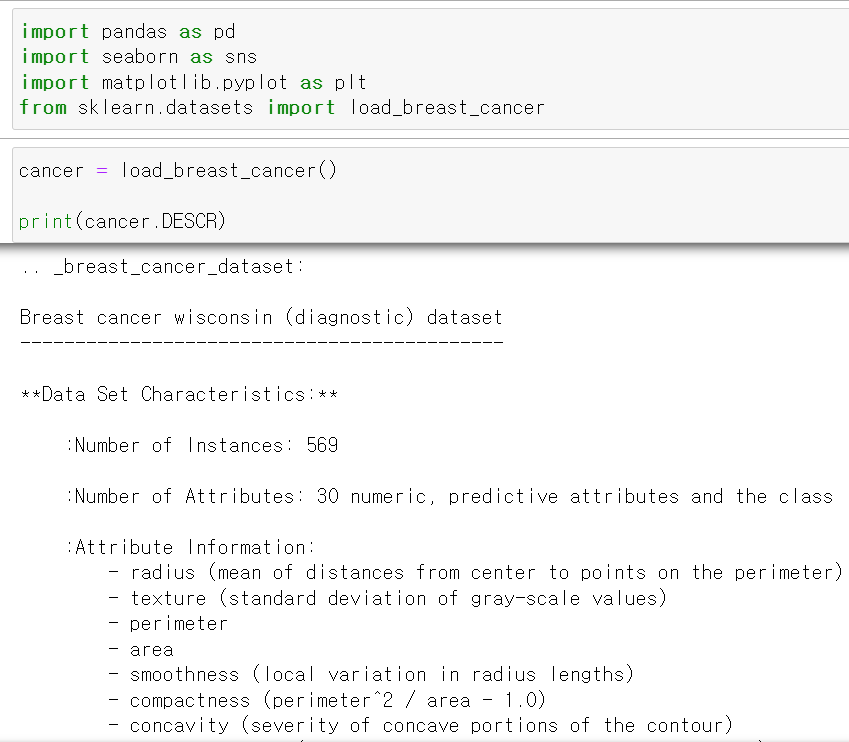
- 이번에는 Pytorch에서 모델을 구축하고 성능을 테스트해봤다.
- 먼저 유방암 데이터를 불러왔다.
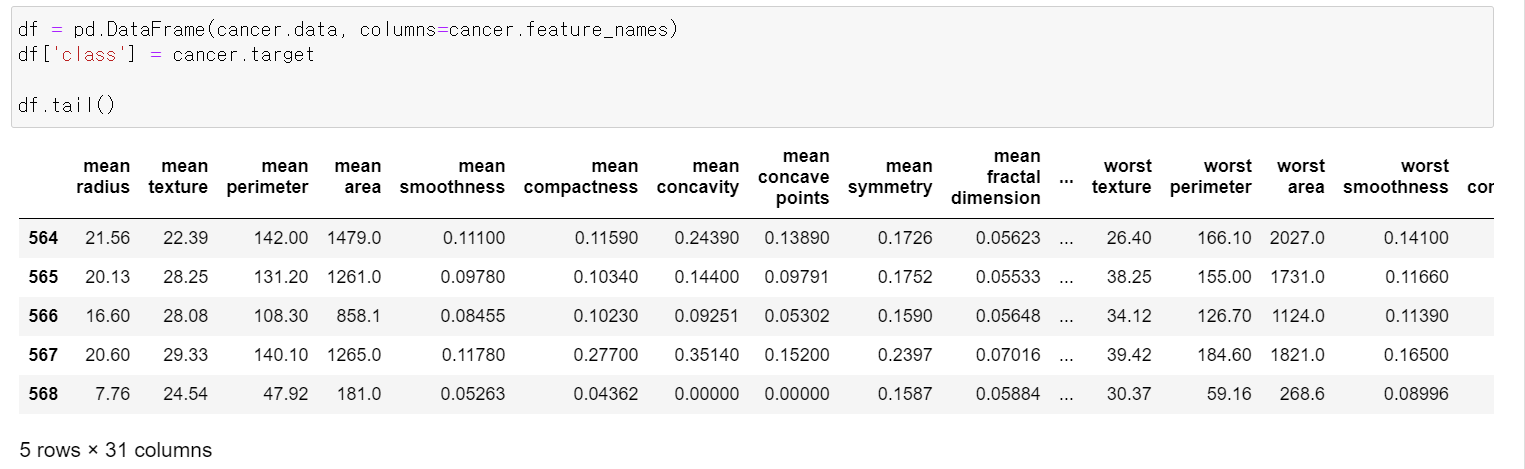
- 그리고 불러온 데이터를 프레임 형태로 만들었다.
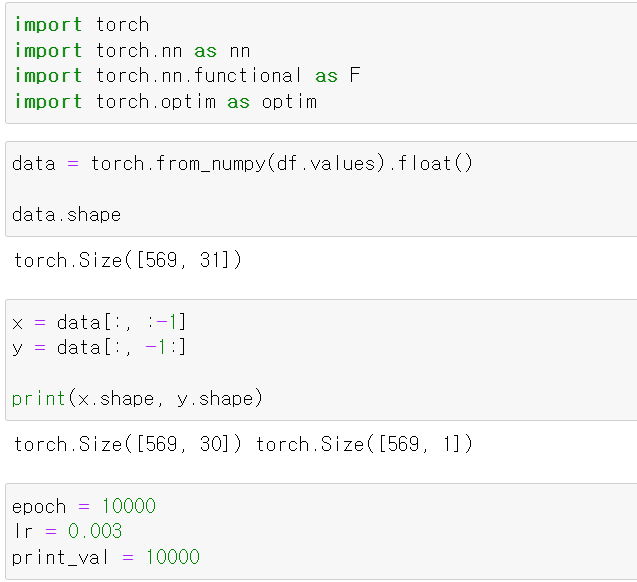
- 이제 torch불러오고, 프레임 데이터를 numpy만든 후 numpy데이터를 torch의 데이터로 변환해 data변수에 저장했다.
- 그리고 x에 데이터를, y에 label값을 저장하고, epoch를 10000 / learning_rate를 0.003으로 저장했다.

- torch의 경우 model을 구축할 때 class를 구현한다.
- model을 구축하고 회귀값을 출력한 후 해당 값을 return했다.
- 그리고 model에 필요한 각 변수를 저장 후

- epoch만큼 가중치 값을 조정했다.
- 먼저 model를 통해 pred(y_hat) 예측값을 출력하고
- 실제값과 예측값의 loss를 구했다.
- 그리고 가중치를 초기화 후 loss값에 대한 역방향 미분값을 구하고 해당 미분값을 바탕으로 가중치를 조정했다.
- 중간에 zero_grad를 넣어준 이유는 torch에서는 가중치를 default값으로 계속 더해주기 때문에 한 번의 교육이 끝나면 초기화를 해줘야한다.
- 결과를 확인해보니 loss값이 많이 낮다.

- 이제 위 방법을 통해 mnist데이터를 torch로 DeepLearning을 해봤다.
- 먼저 batch_size, lr, epoch 변수를 저장하고
- 데이터를 불러왔다.
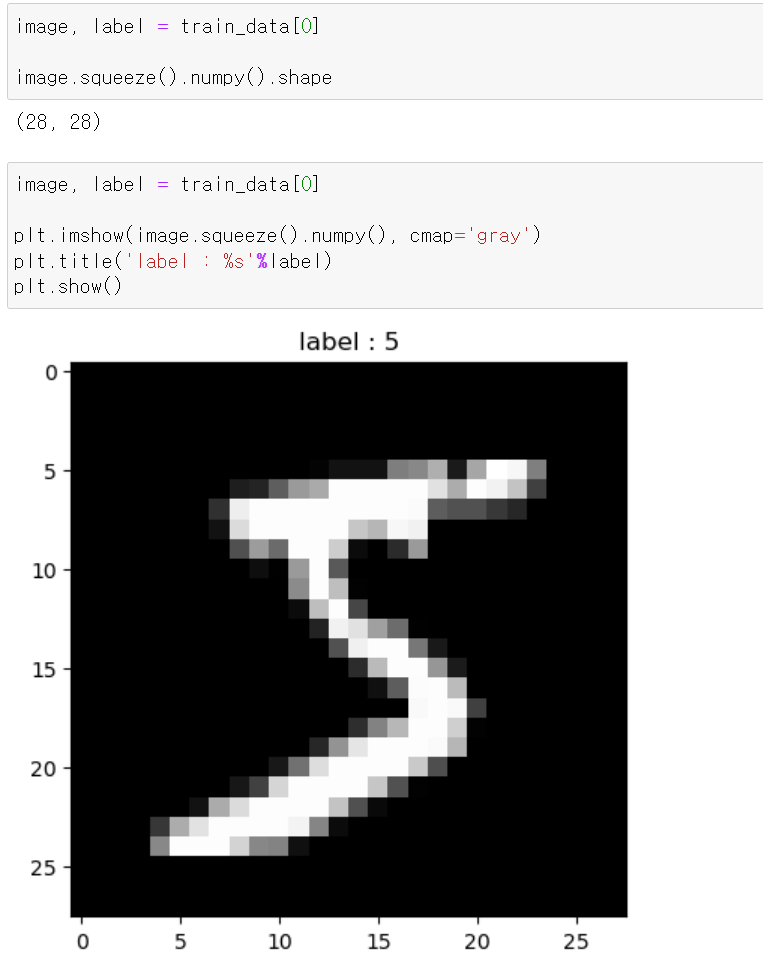
- 아무 데이터나 시각화해본 결과 정상적으로 출력됐다.

- 이제 batch_size만큼 데이터를 쪼개기 위해 train_loader 변수를 만들었다.
- 60000개의 데이터를 50개씩 쪼개서 1200개의 데이터셋을 만들었다.
- 즉 train_loader에는 50개씩 묶인 데이터가 1200개 있다는 것이다.

- 이제 모델을 구축했다.

- 구축한 모델을 저장하고, 최적화는 Adam, loss는 crossEntropyLoss로 저장하고
- train_loader에서 하나씩(50개의 데이터씩) model에 넣어서 가중치를 조정했다.
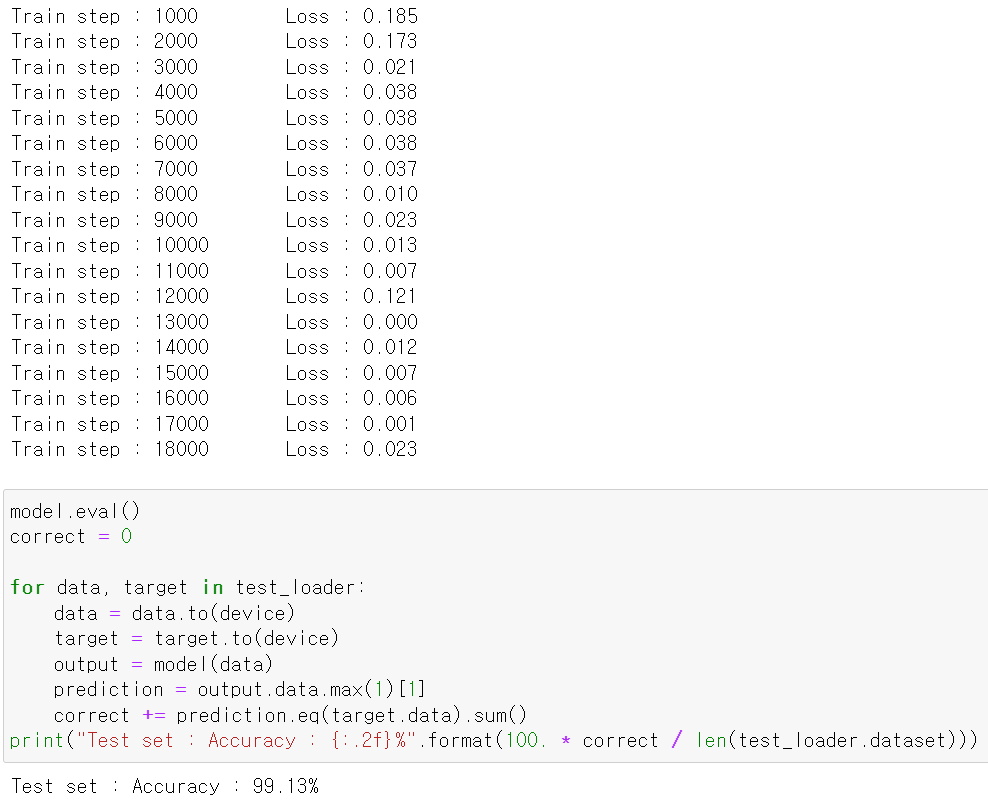
- 1200(50개 데이터 묶음)의 데이터를 15번 돌아서 총 18000돌린 model를 test데이터 성능을 테스트해보니 99.13%의 정확도가 나왔다.

상황을 바꿀 수 없다면, 나를 바꾸자