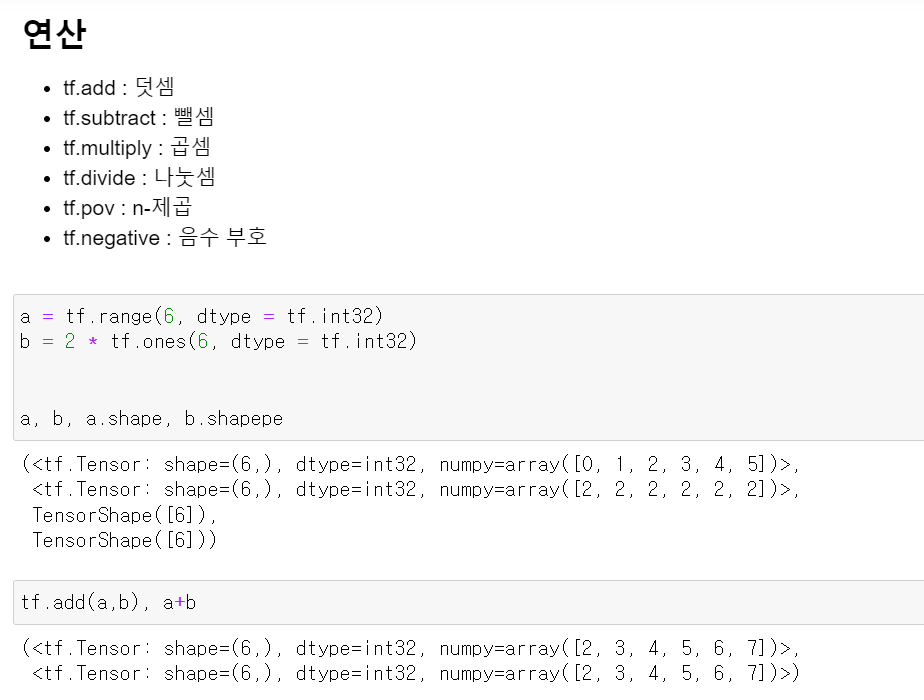
- 행렬로 데이터를 계산하는 딥러닝의 경우 Tensorflow에서도 행렬의 계산을 위한 기본적인 함수가 존재한다.
- a 데이터의 경우 0~5까지 데이터를 가지며, 데이터의 형태는 int다
- 딥러닝에서 정말 중요한 점은 shape와 type을 확인해야한다.
- 그리고 b 변수의 경우 ones에 단순 곱하기 2를 함으로써 2가 6개 있는 데이터가 만들어졌다.
- 그리고 tensor.add를 통해 더할 수 있는데, 연산을 통해서도 할 수 있다.
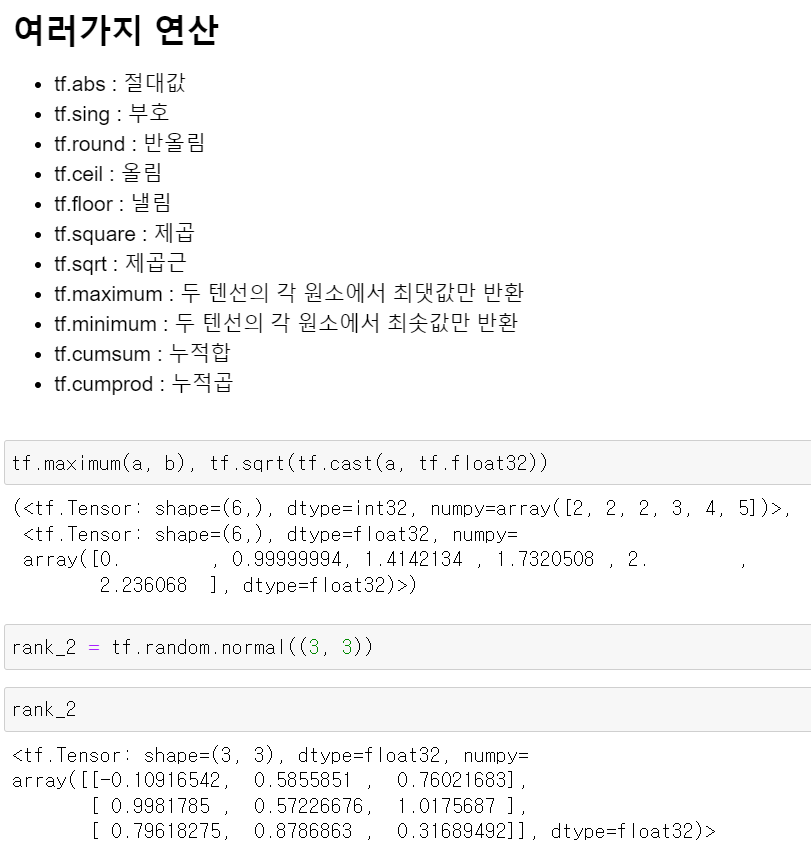
- 그리고 추가적인 함수 기능이 있다.
- 또한, 행렬의 axis에 대한 이해가 정말 중요하다.
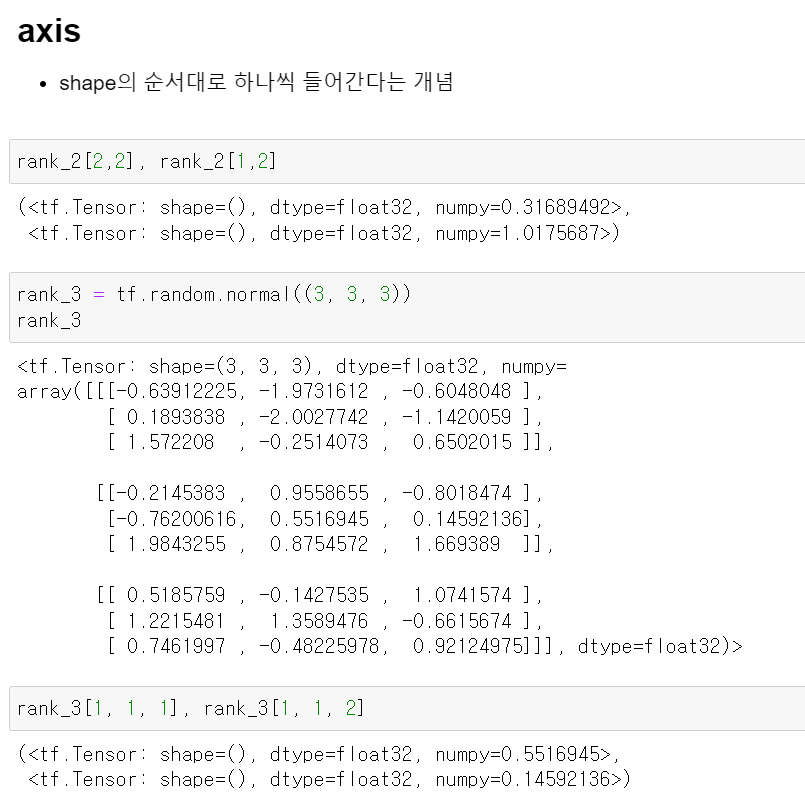
- 위 rank_2변수에서 [2,2]를 뽑으니 0.31...수치가 나왔다. 이는 첫번 째 차원에서 세 번째, 두번 째 차원에서 세 번째 데이터를 뽑는다는 의미다.
- 그리고 rank_3은 3차원 행렬을 만들었는데, 각 위치에 따라 데이터를 뽑을 수 있다.
- 어떤 데이터를 뽑는다기보다 차원(axis)에 대한 이해가 중요하다.
- 간단히 말해 저 큰 묶임이 axis=1, 그리고 묶음 안에서 행이 axis=2, 그리고 거기서 열이 axis=3이라는 의미이다.

- 4차원에서도 동일한 개념이 적용된다.
- 세번 째 큰 묶음에서, 두번 째 묶음, 세번 째 행, 세번 째 열의 데이터를 뽑느다는 의미이다.
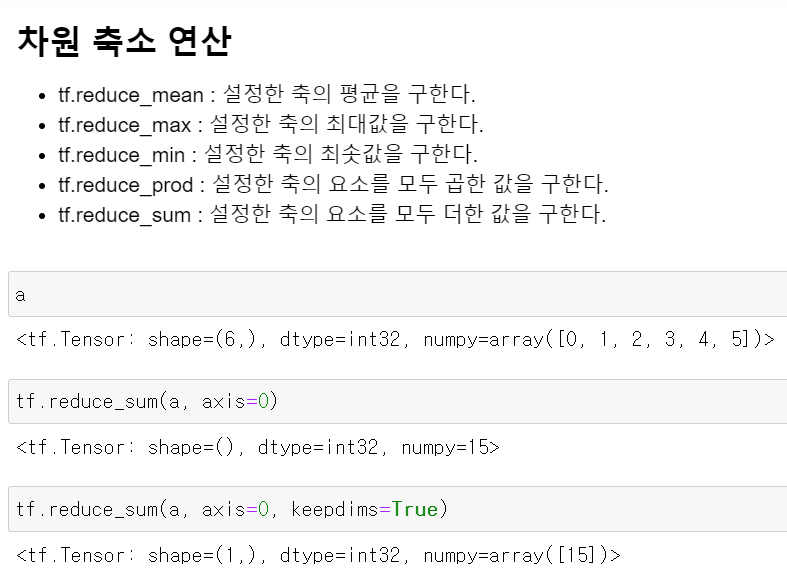
- 그리고 행렬의 설정한 차원에서 결과값을 더할 수도 있다.
- 위에서 keepdims는 계산할 때 원래 차원을 유지한채 계산을 하는 기능이다.
- 이제 3차원 행렬이 있다.
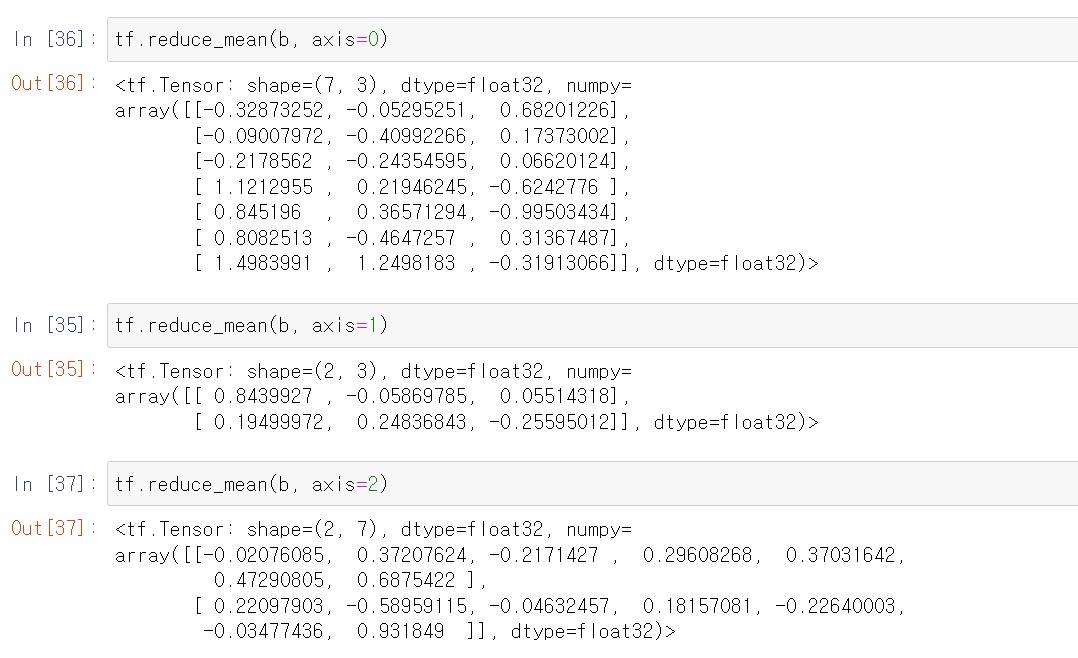
- 각 차원 axis 1, 2, 3에서 평균값을 구했다.
- 여기서 아까 설명한 차원의 개념이 중요하다.
- axis=0으로 설정한 상태에서 평균값을 구하면, 위에서 가장 큰 묶음 2개를 기준으로 위 데이터와 아래의 데이터를 (7, 3)으로 평균값을 구한다.
- 그리고 axis=1를 기준으로 계산할 경우 각 큰 묶음에서 행을 기준으로 평균값을 구한다.

- 그리고 행렬의 차원을 임의로 조정할 수 있다.

- 기본적으로 1차원 행렬이 존재한다.
- 해당 행렬을 reshape(2,3)으로 바꿀 수 있다.
- 그리고 transpose함수를 통해 행렬의 차원을 뒤집을 수 있다.
- expand_dims의 경우 넣은 메소드 값 뒤에 1차원 행렬을 추가할 수 있다.
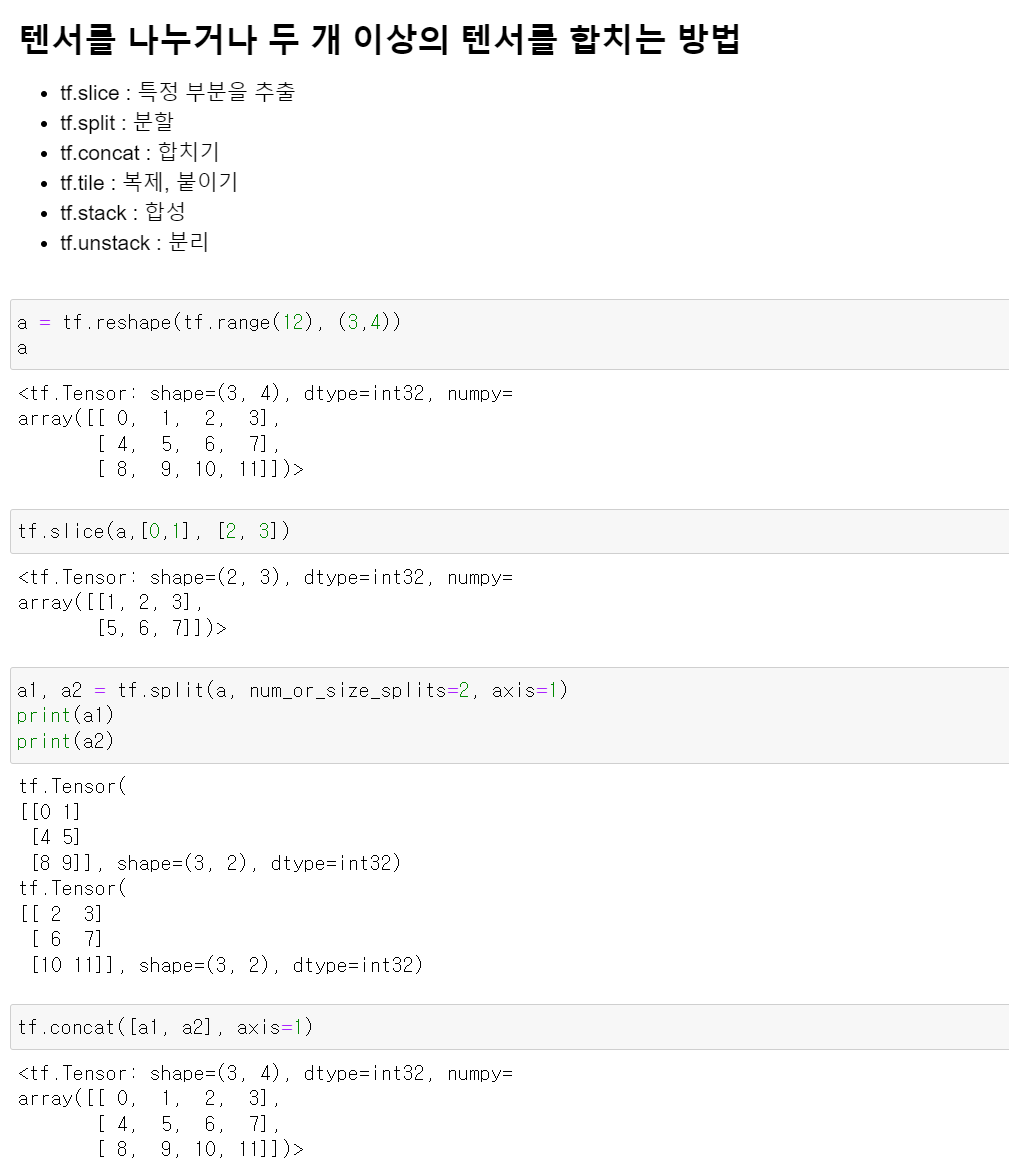
- 그리고 하나의 행렬을 쪼개거나, 합칠 수도 있다.
- slice의 경우 짜를 위치를 넣고, 짜를 크기를 넣으면 해당 행렬이 추출된다. 위에 경우 1 데이터부터 (2,3)만큼 짤라서 추출했다.
- 그리고 split의 경우 짜를 크기를 넣으면 데이터를 분할해서 각 변수에 저장해준다.
- concat의 경우 두 데이터를 하나로 합쳐준다.
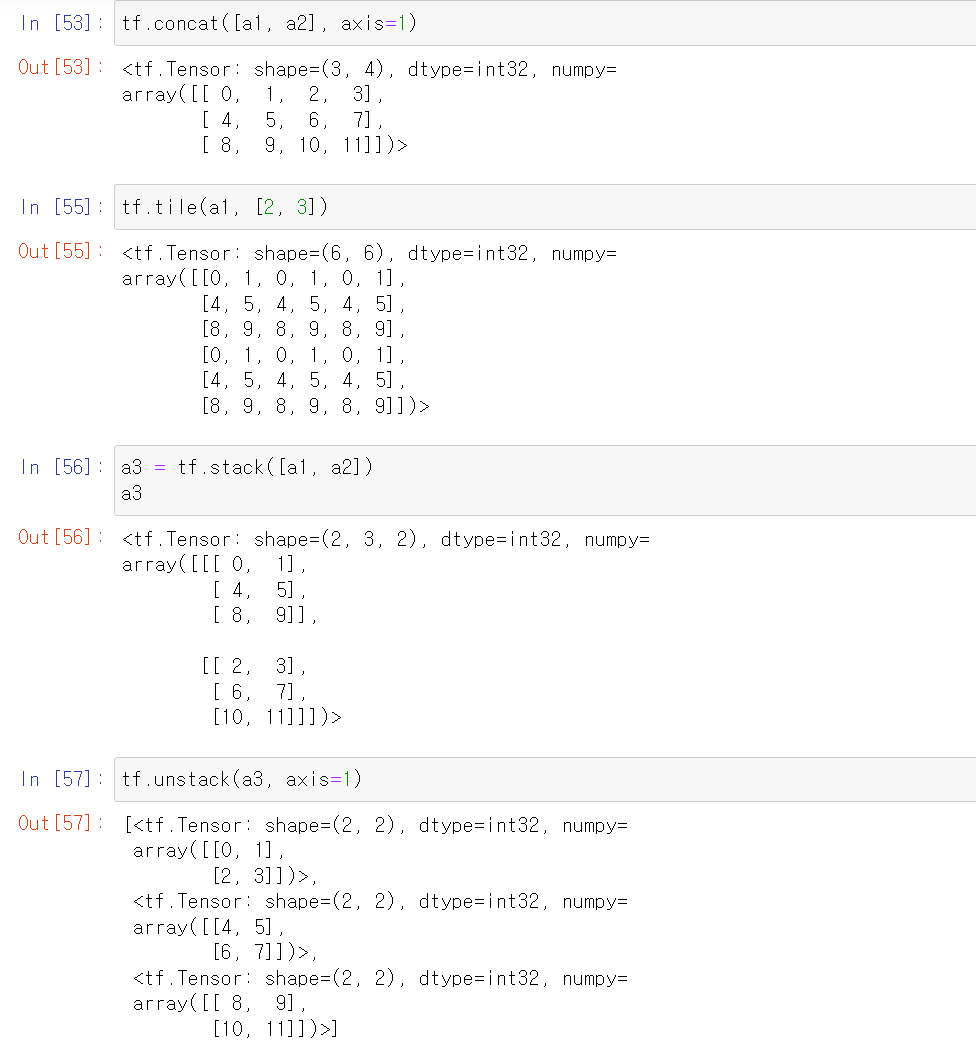
- title 함수는 데이터를 복사해준다고 생각하면 편하다.
- a1은 (3,2)형태인데 title([2,3])를 넣어서 곱하기를 통해 (6, 6)데이터를 만들었다.
- 스택은 두 데이터를 하나의 차원을 추가해서 합쳐주고, unstack의 경우 axis에 넣은 차원에 따라 분할해준다. 위에서는 각 큰 묶음에서 행을 기준으로 나눴기 때문에 3개의 (2,2) 데이터가 추출됐다.

상황을 바꿀 수 없다면, 나를 바꾸자