
부스트캠프 스터디원분들과 진행한 논문 스터디에서 이번주에는 Skip-Thought Vectors라는 생소한 논문을 리뷰했다.
Skip-gram과 Word2Vec, Seq2Seq까지 Transformer가 나타나기 이전에 word embedding에서 한 획을 그었다 할 수 있는 모델의 총집합처럼 느껴졌다.
하지만,논문에 대한 한국어 리뷰가 전무하고 이듬해에 transformer가 등장했기 때문에 주목을 받지 못한 것으로 보인다.
대신, general한 encoder 생성의 필요성에 대한 인식을 높여주고 이전 논문들의 총집합이었다고 생각을 하면 좋을 것 같다.
💡 전체 내용에 대한 요약
skip-thoughts라는 이름에서 알 수 있듯이 해당 모델은 skip-gram과 유사한 모습을 보인다. 모델의 encoder는 일반적인 GRU로 이루어져 있으며, time step t에서 주어지는 문장 와 더불어 이전 문장 과 다음 문장 이 주어진다. 이들을 종합적으로 읽어 hidden vector 를 생성한다.
이후 conditional GRU로 이루어진 decoder를 통해 이전 문장과 이후 문장을 생성한다. 이렇게 학습된 encoder의 임베딩 벡터를 추출해 임베딩에 사용하는 것이다.
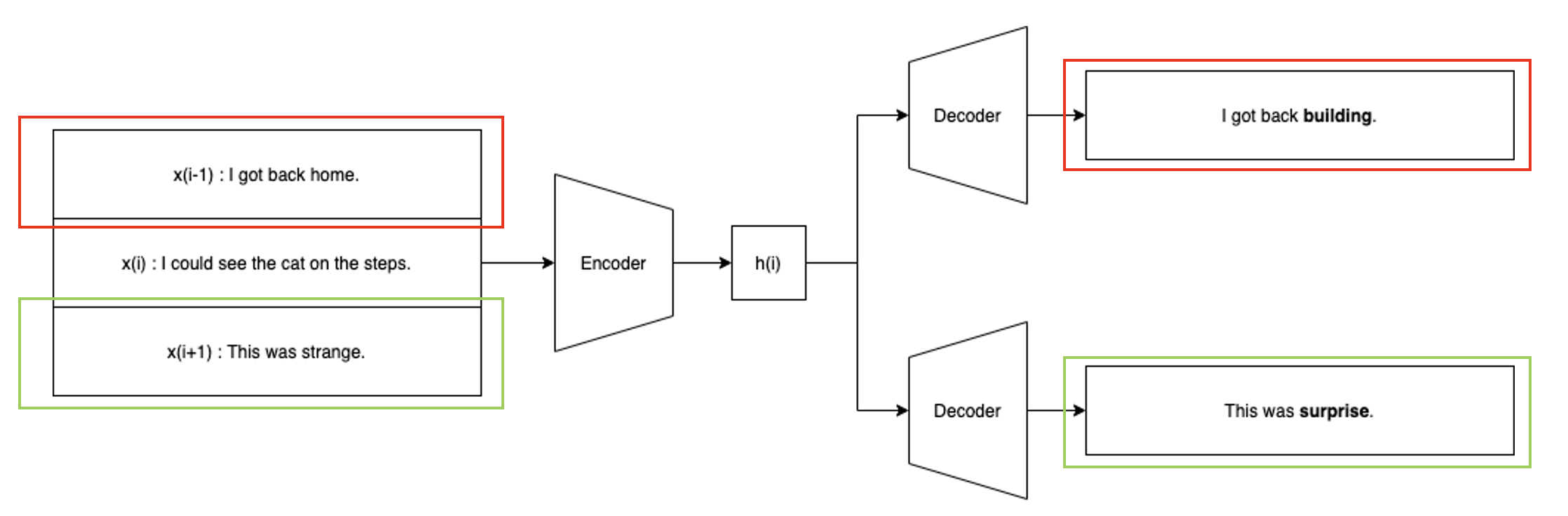
주요하게 볼 점은 단어 하나 하나를 임베딩하는 것이 아니라 문장을 임베딩하려 했으며 MNT와 같은 특정 task만을 위한 word embedding이 아니라 general한 encoder를 만들고자했던 점이다.
📌 Introduction and Background
단어의 의미 분포를 잘 표현하는 언어 모델을 생성하는 것이 오랫동안 관심사였다. 최근에는 이를 해결하기 위해 재귀적 network, convolution network, 재귀적 convolution network 등등이 사용되었다.
이러한 방식은 지도 학습을 통해 학습이 된다.
- target이 있는 상황이어야만 학습이 된다. = tuned only respective task = not general
결과적으로 이러한 방식은 높은 수준의 문장 임베딩을 보이지만 개별적인 task에 맞춘 형태이다. 그래서 비지도 학습을 통해서 문장을 학습할 수 있는 신경망 구조 모델을 소개했다.
개별적 방식의 loss function이 아니라 모든 task에 적용될 수 있는 general한 loss function을 도출하고자했다.
저자들은 동시에 이러한 모델 생성은 지도 학습을 통해서는 이루어질 수 없다고 생각했다. 그래서 고안한 것이 skip-gram 모델을 문장단위로 하는 방식의 목적함수를 제안했다. 단어를 예측하는 방식이 아니라 문장을 예측하는 방식으로 진행했다. 이를 통해서 모든 문장 구성 연산을 이 encoder로 대체하고 목적함수만 수정해주면 된다.

논문에서는 현재 문장을 읽는 하나의 encoder와 이전 문장과 다음 문장을 예측하는 두개의 decoder로 이루어져있다. 이 모델을 skip-thoughts라고 하고 학습된 인코더의 임베딩 벡터를 skip-thoughts vector라고 한다.
해당 모델은 연속적인 corpus를 기반으로 학습되도록 설계되었다. 이를 위해 소설 책으로 진행되었으며 16개의 다른 장르이다. 많은 장르와 데이터를 통해 편향되지 않았다고 주장한다.
이 부분에 대한 논점은 이후 질문에서 다루도록 하겠다.
근데 이렇게 하려면 매우 많은 단어와 문장을 학습시켜야 한다. 이것을 위해 사용되는 방안은 한 모델에서 학습된 임베딩 방식을 다른 모델로 mapping시키는 방식이다. 사전 학습된 word2vec 표현을 CBOW로 사용하는 것처럼 word2vec 공간을 encoder의 단어 공간에 mapping시켰다.
이러한 mapping은 모든 단어를 공유하게 되고 이렇게 되면 word2vec에서 학습된 단어를 encoder 공간에 표현할 수 있게 된다.
🛠 Inducing skip-thought vectors
Encoder - Decoder 모델은 이미 번역에서 많이 사용되는 모델이다. 이들을 저자들은 GRU를 사용한 RNN을 사용해 학습 구조를 만들고 학습시키고자 했다.
먼저, 연속된 세 문장이 주어졌다고 가정하자. 이때 문장 의 t번째 단어의 임베딩을 이라고 하자.
Encoder
매 time step마다 문장들을 종합한 hidden state를 만들어낸다. encoder는 기본적인 GRU 형태를 보이고 있기 때문에 추가적인 설명이 필요하지 않아 보인다. 아래와 같은 방식으로 문장이 임베딩되게 된다.

Decoder
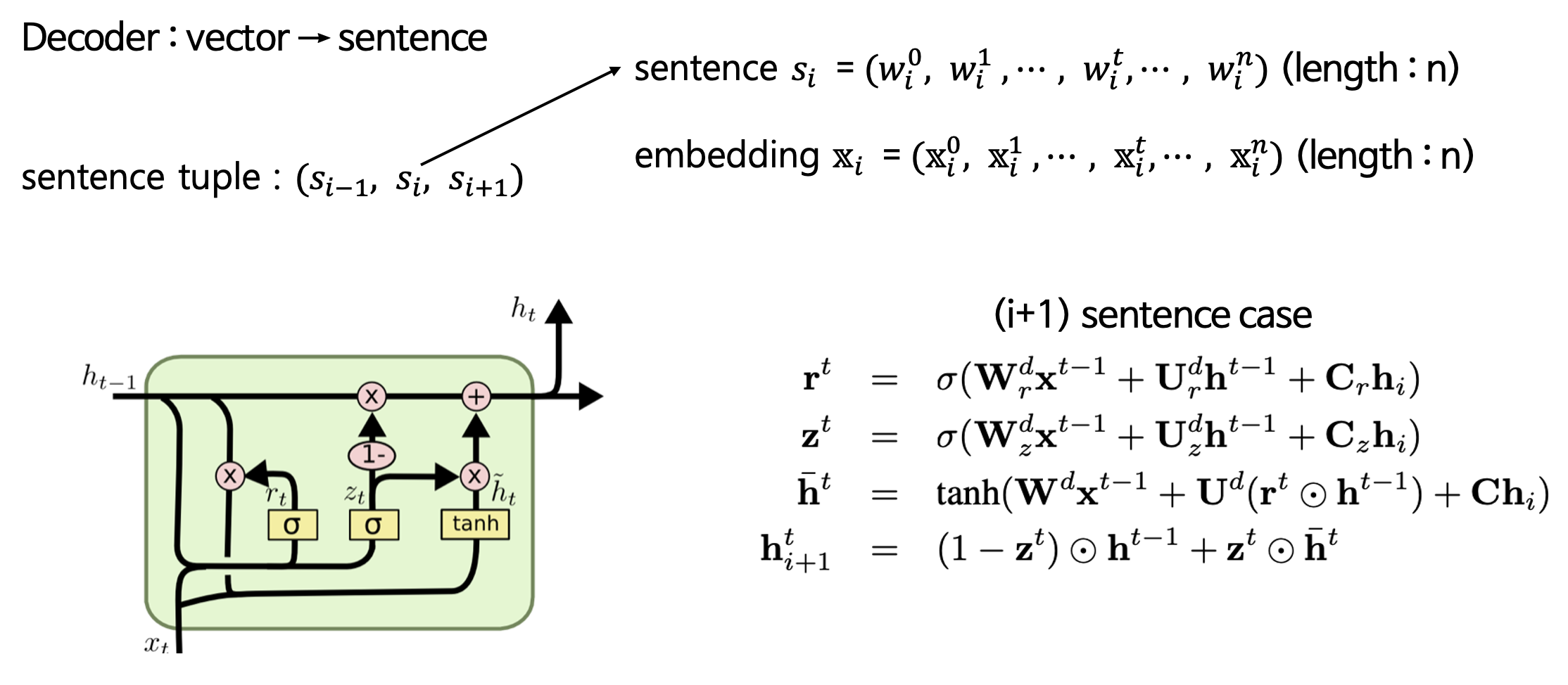
Decoder는 Encoder와는 조금 다른 형태를 보인다. Decoder에서 생성하는 외에 encoder에서 생성된 hidden vector인 가 input으로 gate들에 주어지는 것이다. 이때 각 gate들은 라는 bias 벡터를 통해 conditional하게 제공된다. 이때문에 conditional GRU라고 불린다.
🔥 Vocabulary expansion
이 논문에서 가장 특징적으로 다루어지는 부분이다. 소설을 통해 학습시킨 skip-thoughts 임베딩 벡터 corpus는 당연하게도 기존에 계속 발전해오던 GloVe나 Word2Vec보다 적다. 그렇기에 실생활에서 소위 [unk] 토큰이 많이 등장하게 되는데 이를 보완하기 위한 방식이다.
해당 방식은 pre-trained된 모델을 활용해 mapping 시켜주어 vocab extension 시켜준다. 보통 문장은 단어가 1개가 바뀌었더라도 동일한 뜻을 지니게 된다.(별로 변동이 없다)
pre-trained CBOW word2vec을 사용해 단어번역(translate)을 통해 훈련셋에 없는 단어를 학습시킨다. 이때 word2vec보다 vector space가 encoder보다 더 큰데, 이를 활용해 유사 단어를 injection하는 방식으로 보인다.
🔨 Model Architecture 정리
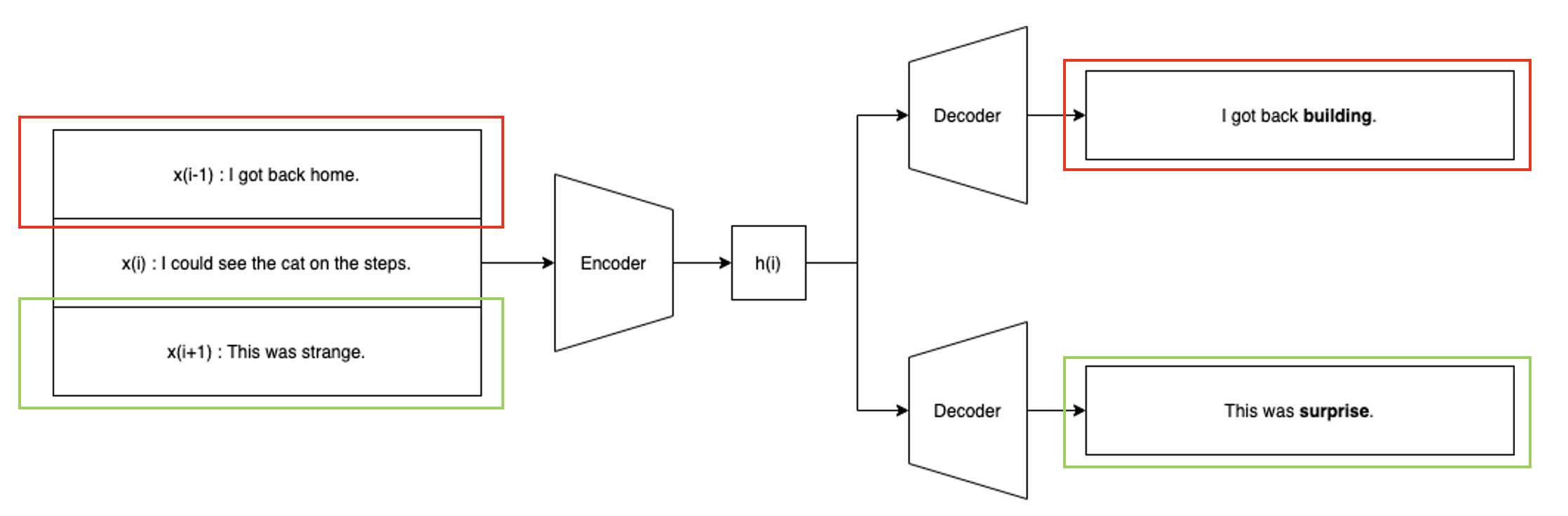
input으로는 세개의 tuple이 들어가게 된다.
하나의 encoder를 통해 들어가게 되고 hidden vector로 만들어준다.
그리고 decoder를 통해 앞 뒤 문장을 내뱉어준다.
- 이때 문장들이 완벽히 동일하지는 않을 수 있고 문법적으로도 오류가 있을 수 있다.
- 대신 문장의 전체적인 느낌은 비슷 → 그러나 다르게 복원
- auto-encoder 형식과 매우 비슷
- 이후 실험에서 더욱 드러나지만 문장 및 이미지를 복원하는 실험이 등장하는 것을 통해 해당 모델이 auto-encoder 구조임을 알 수 있다.
🧪 Experiments
BookCorpus dataset을 학습시켜서 general한 encoder를 생성하고자 함.
- Using the learned encoder as a feature extractor, extract skip-thought vectors for all sentences.
- If the task involves computing scores between pairs of sentences, compute component-wise features between pairs. This is described in more detail specifically for each experiment.
- Train a linear classifier on top of the extracted features, with no additional fine-tuning or backpropagation through the skip-thoughts model.
모델에 linear classification만을 붙인 이유는 임베딩된 벡터를 명확하게 판단하고 싶기 때문이라고 말한다.
Details of training
Corpus를 두 개의 undirectional encoder와 bidirectional encoder로 임베딩 진행했다.
그리고 이후 두가지 모델의 성능 추이를 살펴봄
⇒ 큰 차이는 존재하지 않지만 uni-skip이 성능이 MSE에서 조금 떨어짐
⇒ 대신 acc, f1은 biskip이 더 높다.
학습에서 Adam 알고리즘 사용했으며, uni-skip과 bi-skip을 모두 활용한 combine-skip의 성능이 가장 좋았다.
Semantic Relatedness
모델을 통해서 문장간의 유사도를 구하고자 했다. 실험은 사람이 매긴 수치를 통해 학습한 모델이 매칭시킨 수치 비교로 진행되었다.
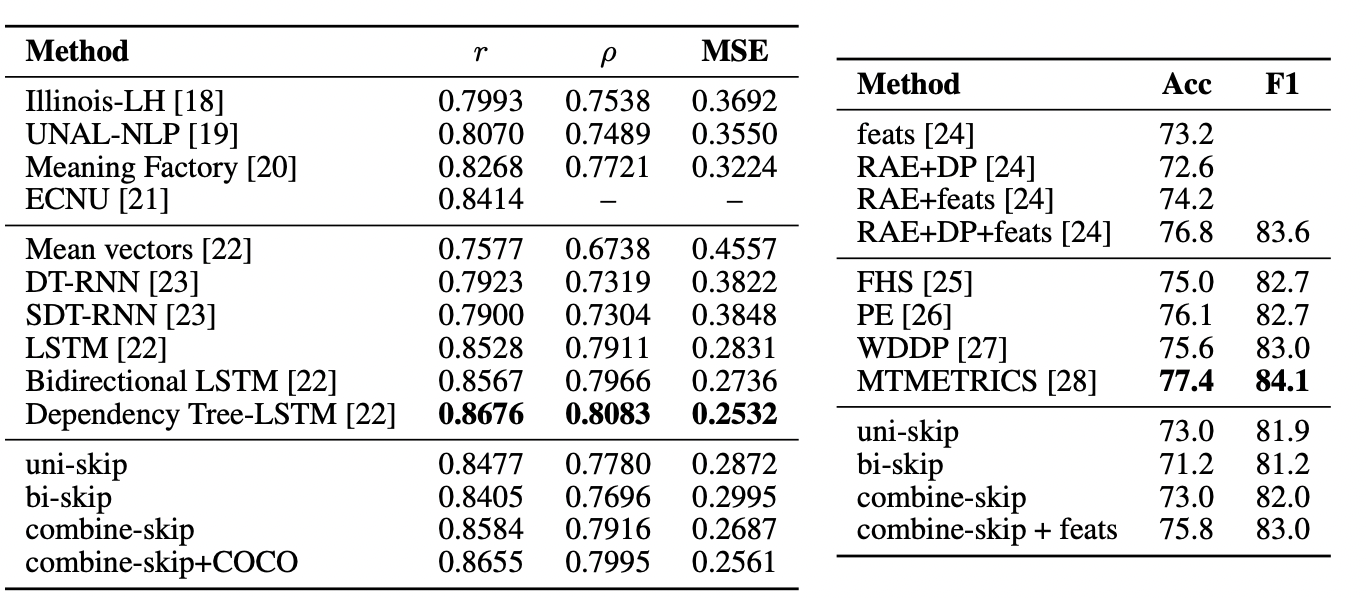
저자들은 skip-thoughts의 경우 문장간의 뺄셈 연산을 통해 유사도를 구하고자 했고 이전 모델의 모든 부분에서 압도했으며 좋은 성적을 보임.
또한 성적표에서 알 수 있듯이 Tree - LSTM layer를 추가하거나 COCO dataset을 추가해서 성능을 더 boosting시킬 수도 있다.
Paraphrase detection
Microsoft Research Paraphrase Corpus를 사용한 문장의 paraphrase을 예측하는 실험을 진행했다. 즉, 두 문장이 paraphrase된 문장인지 아닌지를 예측하는 것이다. 해당 방식은 위의 의미적 유사도를 추론하는 실험과 매우 비슷하게 진행되었다고 한다.
그도 그럴 것이 문장 유사도 vs 의미적 유사도라 큰 차이가 없어 보이기는 한다.
그리고 SICK dataset에서도 동일한 작업 수행했다. 학습에서는 logistic regression을 통해서 문장이 paraphrase된지 예측했으며 Cross-validation을 위해서는 L2 penalty를 사용되었다.
여기서도 의미적 유사성을 보는 방식을 사용해서 선형적 연산을 통해 paraphrase 여부를 예측했다.
최종적으로 skip-thoughts와 두 문장간의 pair-wise statistics를 활용한 것이 dynamic pooling과 함께 recursive nets을 구성한 것보다 성능이 좋았다.
이는 feature에 대한 많은 작업을 하지 않았음에도 좋은 성적이 나온 것이기에 괄목할 만 했다고 여겨진다.
Image-sentence ranking
이번 논문에서 가장 재밌게 본 실험. 해당 방식은 auto-encoder의 모습과 유사하기도해 이후 multi-modal의 약간의 근간이 되기도 한 것 같다.
이미지와 설명 문장을 복원하는 task로 진행했다. 여기서는 Microsoft COCO dataset을 사용했다.
해당 데이터셋에는 각 이미지에 대해서 다른 사람이 작성한 5개의 설명이 존재한다.
이것을 가지고 image annotation task와 image search task을 진행했다.
- image annotation
- image가 보여지고 caption이 얼마나 잘 설명하고 있는지를 평가
- image search는 그 반대로 설명이 주워지고 image를 복원하는 작업
평가는 Recall@K라는 방식이 사용되었다.
- 이미지에 대한 정확한 설명이 top-k에 나타났는지에 대한 평균 숫자를 표시하는 방식
보통 성적이 좋은 RNN을 사용해서 문장을 encoding하도록 만드는데 여기서는 Fisher vector를 사용해 문장을 표현하는 방식인 linear CCA를 베이스라인 모델로 삼았다.
그리고 이미지 복원에서는 4096-dimensional OxfordNet을 사용해 이미지 복원을 진행했다.
loss 함수는 아래와 같다.
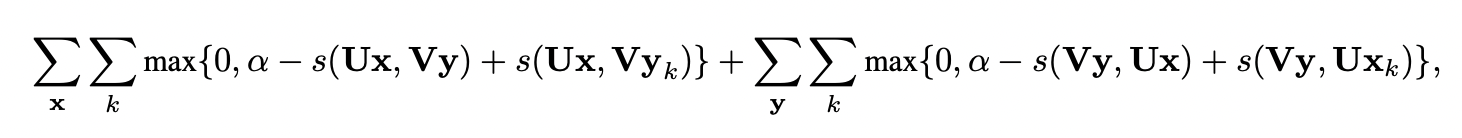
여기서 x는 이미지 벡터, y는 skip-thoughts vector를 의미한다. 그리고 는 정확하지 않은 문장들이다.
각 벡터들은 U, V라는 임베딩 matrix를 통해 임베딩 된다. 그 후 s라는 image-sentence score를 연산해주는 cosine similarity 연산을 통해 성능을 평가한다.
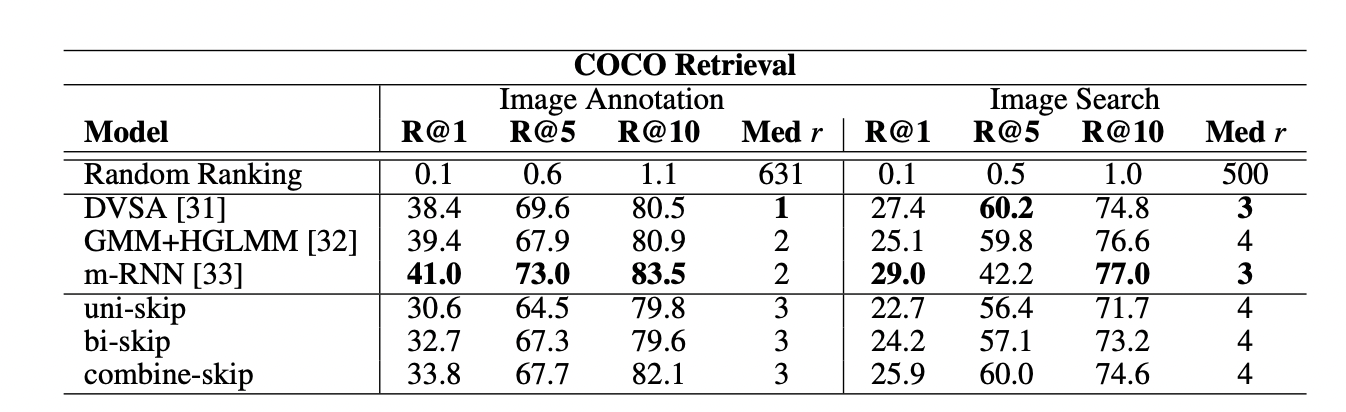
성적을 살펴볼 때 엄청 좋지는 않지만 그래도 나쁘지 않은 성능추이를 보이고 있다.
이는 general하게 caption에 대해 학습할 수 있는 encoder를 생성했다는 점에서 의의가 있다.
그리고 skip-thoughts에 두 가지 방식을 차용한 것은 매우 높은 품질의 결과를 생성해냈다.
✏️ 결론과 느낀점
general한 encoder를 만들기 위해 모든 방식을 차용한 논문. 앞선 한 문장으로 해당 논문을 종합할 수 있을 것 같다. 해당 논문을 통해 바라볼 수 있었던 것은 이 시기에 transformer를 포함해 general한 모델 생성에 상당히 초점이 맞춰져 있었다라는 생각이 들었다.
한국어 리뷰가 없는 만큼 유명한 논문은 아니지만 그래도 앞선 임베딩 방식을 모두 종합해볼 수 있는 논문이었다고 생각한다.
참고 : https://arxiv.org/pdf/1506.06726.pdf
https://www.kdnuggets.com/2016/11/deep-learning-group-skip-thought-vectors.html
special thanks to 발표를 맡아주신 박기범 캠퍼님
