자연어 처리(Natural Language Processing)
- 자연어는 일상 생활에서 사용하는 언어
- 자연어 처리는 자연어의 의미를 분석 처리하는 일
- 텍스트 분류, 감성 분석, 문서 요약, 번역, 질의 응답, 음성 인식, 챗봇과 같은 응용
자연어 처리 단계
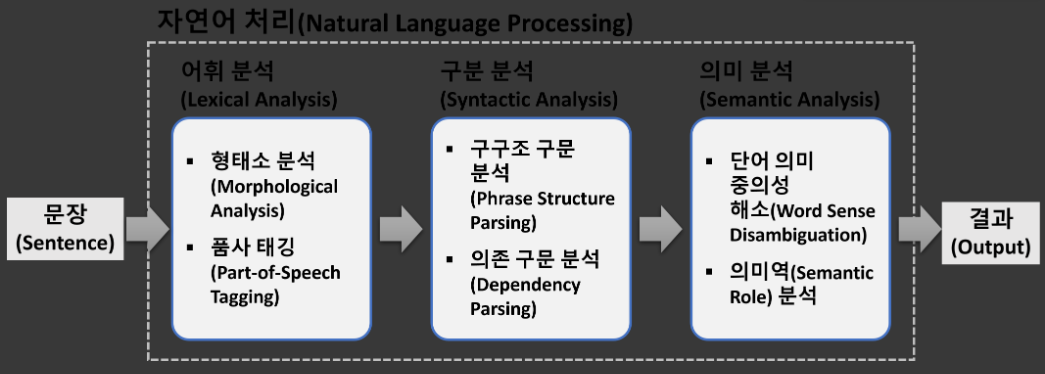
-
어휘 분석(Lexical Analysis): 단어의 구조를 식별하고 분석하여 어휘의 의미와 품사에 대한 단어 수준의 연구
- 형태소 분석(Morphological Analysis): 더 이상 분해될 수 없는 최소한의 의미를 갖는 단위인 형태소를 사용해 단어가 어떻게 형성되는지에 대해 자연어의 제약 조건과 문법 규칙에 맞춰 분석
- 품사 태깅(Part-of-Speech Tagging): 단어의 기능, 형태, 의미에 따라 나눈 것이 품사이고, 같은 단어에 대해 의미가 다를 경우(중의성)를 해결하기 위해 부가적인 언어의 정보를 부착하는 태깅
-
구문 분석(Syntactic Analysis): 자연어 문장에서 구성 요소들의 문법적 구조를 분석
- 구구조 구문 분석(Phrase Structure Parsing): 구구조 문법에 기반한 구문 분석 기술
- 의존 구문 분석(Dependency Parsing): 자연어 문장에서 단어 간의 의존 관계를 분석함으로써 문장 전체의 문법적 구조를 분석
-
의미 분석(Semantic Analysis): 문장의 의미에 근거해서 그 문장을 해석하는 방법
- 단어 의미 중의성 해소(Word Sense Disambiguation): 문장 내 중의성을 가지는 어휘를 사전에 정의된 의미와 매칭하여 어휘적 중의성을 해결
- 의미역(Semantic Role) 분석: 의미를 해석하기 위해 서술어가 수식하는 대상의 의미 관계를 파악하고, 그 역할을 분류
라이브러리와 형태소 분석기 설치
- 한국어 자연어 처리 konlpy 라이브러리
- 형태소 분석기 Okt, Kkma, Hannanum, Komoran, Twitter, MeCab 설치
- 설치 명령어:
!curl -s https://raw.githubusercontent.com/teddylee777/machine-learning/master/99-Misc/01-Colab/mecab-colab.sh | bash
from konlpy.tag import Kkma, Hannanum, Komoran, Twitter, Okt, Mecab
#twitter는 okt로 바뀌어서 사실상 같음
kkma = Kkma()
hannanum = Hannanum()
komoran = Komoran()
twitter = Twitter()
okt = Okt()
mecab = Mecab()토큰화(Tokenization)
-
특수문자에 대한 처리
- 단어에 일반적으로 사용되는 알파벳, 숫자와는 다르게 특수문자는 별도의 처리가 필요
- 일괄적으로 단어의 특수문자를 제거하는 방법도 있지만 특수문자가 단어에 특별한 의미를 가질 때 이를 학습에 반영시키지 못할 수도 있음
- 특수문자에 대한 일괄적인 제거보다는 데이터의 특성을 파악하고, 처리를 하는 것이 중요
-
특정 단어에 대한 토큰 분리 방법
- 한 단어지만 토큰으로 분리할 때 판단되는 문자들로 이루어진 we're, United Kingdom 등의 단어는 어떻게 분리해야 할지 선택이 필요
- we're은 한 단어이나 분리해도 단어의 의미에 별 영향을 끼치진 않지만 United Kingdom은 두 단어가 모여 특정 의미를 가리켜 분리해선 안됨
- 사용자가 단어의 특성을 고려해 토큰을 분리하는 것이 학습에 유리
단어 토큰화(Word Tokenization)
- 파이썬 내장 함수인
split을 활용해 단어 토큰화 - 공백을 기준으로 단어를 분리
sentence = "Time is gold"
tokens = [x for x in sentence.split(" ")]
tokens- 토큰화는
nltk패키지의tokenize모듈을 사용해 손쉽게 구현 가능 - 단어 토큰화는
word_tokenize()함수를 사용해 구현 가능
-
NLTK(Natural Language Toolkit) 패키지는 교육용으로 개발된 자연어 처리 및 문서 분석용 파이썬 패키지
-
NLTK 패키지의 주요 기능
-
말뭉치
-
토큰 생성
-
형태소 분석
-
품사 태깅
-
import nltk
nltk.download("punkt")
from nltk.tokenize import word_tokenize
tokens = word_tokenize(sentence)
tokens-
한국어는 공백으로 단어를 분리해도 조사, 접속사 등이 남아 분석에 어려움이 있음
-
이를 해결해주는 한국어 토큰화는 조사, 접속사를 분리해주거나 제거
sentence = "추세의 방향과 주가를 분석하는 데 유용한 지표로 평가된다."
# `pos()`라는 함수 이용
print("Kkma 형태소 분석: ", kkma.pos(sentence))
print("Hannanum 형태소 분석: ", hannanum.pos(sentence))
print("Komoran 형태소 분석: ", komoran.pos(sentence))
print("Twitter 형태소 분석: ", twitter.pos(sentence))
print("Okt 형태소 분석: ", okt.pos(sentence))
print("Mecab 형태소 분석: ", mecab.pos(sentence))
# 토큰화만 실행할 때는 morphs()라는 함수를 이용
print("Kkma 형태소 분석: ", kkma.morphs(sentence))
print("Hannanum 형태소 분석: ", hannanum.morphs(sentence))
print("Komoran 형태소 분석: ", komoran.morphs(sentence))
print("Twitter 형태소 분석: ", twitter.morphs(sentence))
print("Okt 형태소 분석: ", okt.morphs(sentence))
print("Mecab 형태소 분석: ", mecab.morphs(sentence))
# 형태소만 사용하고 싶을 때는 nouns()라는 함수를 이용해 조사, 접속사 등을 제거 가능
print("Kkma 형태소 분석: ", kkma.nouns(sentence))
print("Hannanum 형태소 분석: ", hannanum.nouns(sentence))
print("Komoran 형태소 분석: ", komoran.nouns(sentence))
print("Twitter 형태소 분석: ", twitter.nouns(sentence))
print("Okt 형태소 분석: ", okt.nouns(sentence))
print("Mecab 형태소 분석: ", mecab.nouns(sentence))
문장 토큰화(Setence Tokenization)
# 문장 토큰화는 줄바꿈 문자('\n')를 기준으로 문장을 분리
sentences = "Your mom raised you as a prince.\nBut this is queendom, right?"
print(sentences)
tokens = [x for x in sentences.split("\n")]
tokens
# 문장 토큰화는 sent_tokenize() 함수를 사용해 구현 가능
from nltk.tokenize import sent_tokenize
tokens = sent_tokenize(sentences)
tokens
- 문장 토큰화에서는 온점(.)의 처리를 위해 이진 분류기를 사용할 수도 있음
- 온점은 문장과 문장을 구분해줄 수도, 문장에 포함된 단어를 구성할 수도 있기 때문에 이를 이진 분류기로 분류해 더욱 좋은 토큰화를 구현할 수도 있음
# konlpy 라이브러리의 형태소 분석기 중에서는 꼬꼬마만 문장 분리 가능
text = "미안하다. 이거 보여주려고 어그로 끌었다."
print(kkma.sentences(text))
- 한국어 문장을 토큰화할 때는 kss(korean sentence splitter) 라이브러리 이용
- 라이브러리를 이용해도 한국어에는 전치 표현이 존재해 제대로 토큰화가 안됨
- 좀 더 나은 학습을 위해 사용자는 해당 부분을 따로 처리해주어야만 함
!pip install kss
import kss
print(kss.split_sentences(text))
정규 표현식을 이용한 토큰화
- 토큰화 기능을 직접 구현할 수도 있지만 정규 표현식을 이용해 간단하게 구현할 수도 있음
- nltk 패키지는 정규 표현식을 사용하는 토큰화 도구인 RegexpTokenizer를 제공
from nltk.tokenize import RegexpTokenizer
sentence = "Where there\'s a will. there\'s away"
#특문제거
tokenizer = RegexpTokenizer("[\w]+")
tokens = tokenizer.tokenize(sentence)
tokens
#gaps=True ?
tokenizer = RegexpTokenizer("[\s]+", gaps=True)
tokens = tokenizer.tokenize(sentence)
tokenssentence = "변수가 잘ㄹ생성되었는지 확인!합니다ㅎㅎ."
# 자음제거
tokenizer = RegexpTokenizer("[가-힣]+")
tokens = tokenizer.tokenize(sentence)
tokens
tokenizer = RegexpTokenizer("ㄱ-ㅎ]+", gaps=True)
tokens = tokenizer.tokenize(sentence)
tokensTextBlob을 이용한 토큰화
케라스를 이용한 토큰화
기타 토크나이저
WhiteSpaceTokenizer: 공백을 기준으로 토큰화WordPunktTokenizer: 텍스트를 알파벳 문자, 숫자, 알파벳 이외의 문자 리스트로 토큰화MWETokenizer: MWE는 Multi-Word Expression의 약자로 'republic of korea'와 같이 여러 단어로 이뤄진 특정 그룹을 한 개체로 취급TweetTokenizer: 트위터에서 사용되는 문장의 토큰화를 위해서 만들어졌으며, 문장 속 감성의 표현과 감정을 다룸
n-gram 추출
- n-gram은 n개의 어절이나 음절을 연쇄적으로 분류해 그 빈도를 분석
- n=1일 때는 unigram, n=2일 때는 bigram, n=3일 때는 trigram으로 불림
PoS(Parts-of-Speech) 태깅
- PoS는 품사를 의미하며, PoS 태깅은 문장 내에서 단어에 해당하는 각 품사를 태깅
불용어(Stopword) 제거
- 영어의 전치사(on, in), 한국어의 조사(을, 를) 등은 분석에 필요하지 않은 경우가 많음
- 길이가 짧은 단어, 등장 빈도 수가 적은 단어들도 분석에 큰 영향을 주지 않음
- 일반적으로 사용되는 도구들은 해당 단어들을 제거해주지만 완벽하게 제거되지는 않음
- 사용자가 불용어 사전을 만들어 해당 단어들을 제거하는 것이 좋음
- 도구들이 걸러주지 않는 전치사, 조사 등을 불용어 사전을 만들어 불필요한 단어들을 제거
철자 교정(Spelling Correction)
- 텍스트에 오탈자가 존재하는 경우가 있음
- 예를 들어, 단어 'apple'을 'aplpe'과 같이 철자 순서가 바뀌거나 spple 같이 철자가 틀릴 수 있음
- 사람이 적절한 추정을 통해 이해하는데는 문제가 없지만, 컴퓨터는 이러한 단어를 그대로 받아들여 처리가 필요
- 철자 교정 알고리즘은 이미 개발되어 워드 프로세서나 다양한 서비스에서 많이 적용됨
단수화(Singularize)와 복수화(Pluralize)
어간(Stemming) 추출
개체명 인식(Named Entity Recognition)
의존 구문 분석(Dependency Parsing)
- Spacy 라이브러리를 이용해 문장을 token들로 구성된 document로 처리하고, 각 token에는 품사, 의존 관계, 개체명 정보 등이 태깅
- token.text: token 문자열
- token.dep_: token과 token의 지배소 간의 의존 관계 유형
- token.head: 지배소 token
단어 중의성(Lexical Ambiguity)

데린이여요