너무 길어서 두 개로 나눠서 포스팅
오늘 뭘 했니?
- 캐글 benz 데이터로 GBT, XGBoost, lightgbm, catboost를 적용하고 제출
실습파일: (코랩으로 실습) 0803-Benz-tree-model-input.ipynb - 캐글 credit card faud detection 의 데이터로 불균형한 데이터를 다뤄보고 분류측정지표에 대해 배움
실습파일: 0804-credit_card_SMOTE-input
뭘 배웠니?(new)
GBM (Gradient Boosting Machine)
- 회귀 분류 가넝
- 앙상블 방법론 중 부스팅 계열에 속하는 알고리즘
- 계산량이 많이 필요해서 하드웨어를 효율적으로 구현해야 함
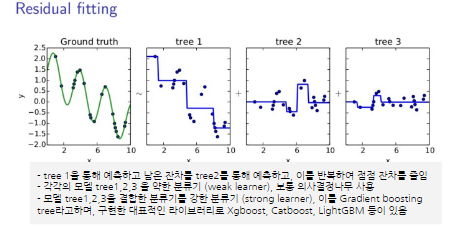
그래디언트 부스팅 트리(Gradient Boosting Tree) GBT
-
랜덤포레스트와 다르게 무작위성이 x
-
매개변수조정이 중요하며 훈련시간이 길다
-
데이터의 스케일에 구애받지 x
-
고차원의 희소한 데이터에는 잘 작동하지 x
-
주요파라미터
-
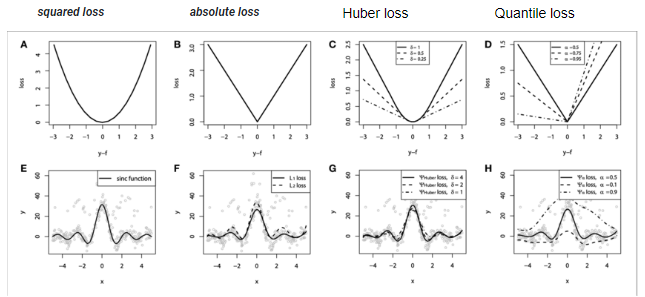
loss : 최적화 시킬 손실 함수(squared_error, absolute_error, huber, quantile), default=squared_error
💡 회귀 평가지표로 absolute loss보다 squared loss를 더 많이 사용하는 이유는 무엇일까요?
squared loss에서는 점진적으로 loss가 줄어들 때 기울기가 0에 가까워지는 것을 확인할 수 있지만,
absolute loss에서는 기울기의 부호가 바뀌기 전까지 loss의 변화를 감지할 수 없습니다.
-
-
주요 매개변수
- learning_rate: 각 트리의 기여도를 제한
- n_estimators: 부스팅 단계를 지정
- subsample: 개별 기본 학습자를 맞추는 데 사용하는 샘플의 비율
- n_estimators : int, default=100
- criterion : {‘friedman_mse’, ‘squared_error’, ‘mse’, ‘mae’}, default=’friedman_mse’
- max_depth : int, default=3
- max_features : {‘auto’, ‘sqrt’, ‘log2’}, int or float, default=None
-
최상의 분할을 찾을 때 고려해야 할 기능의 수
엑스트라 트리 모델
- 극도로 무작위화(Extremely Randomized Tree)된 모델
- 랜덤 포레스트에서와 같이 후보 기능의 무작위 하위 집합이 사용되지만 가장 차별적인 임계값을 찾는 대신 각 후보 기능에 대해 임계값이 무작위로 그려지고 무작위로 생성된 임계값 중 가장 좋은 것이 분할 규칙으로 선택
- 일반적으로 약간 더 큰 편향 증가를 희생시키면서 모델의 분산을 조금 더 줄일 수 있음
GBT의 단점을 개선하고 보완한 것이 아래의 XGBoost, lightgbm, catboost
XGBoost
- 오픈소스 소프트웨어 라이브러리
- GBT에서 병렬학습을 지원하여 학습속도가 빨라짐
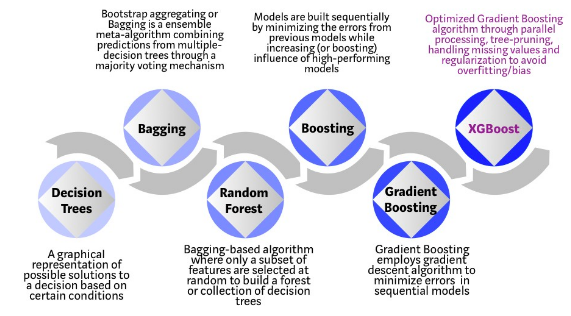
XGBoost Algorithm: Long May She Reign! | by Vishal Morde | Towards Data Science
- 2차 근사식을 바탕으로 한 손실함수를 토대로 매 iteration마다 하나의 leaf로 부터 가지를 늘려나가는 것이 효율적
- 손실 함수가 최대한 감소하도록 하는 분할점을 찾는 것이 목표
- 장점
- 과적합 규제
- 분류와 회귀 가넝
- 조기종료(Ealry Stopping) 기능
- 단점
- GBM보다는 빠르지만 그래도 느림
- Hyper Parameter 수가 많아 튜닝하면 더느려짐
- 모델의 Overfitting
-
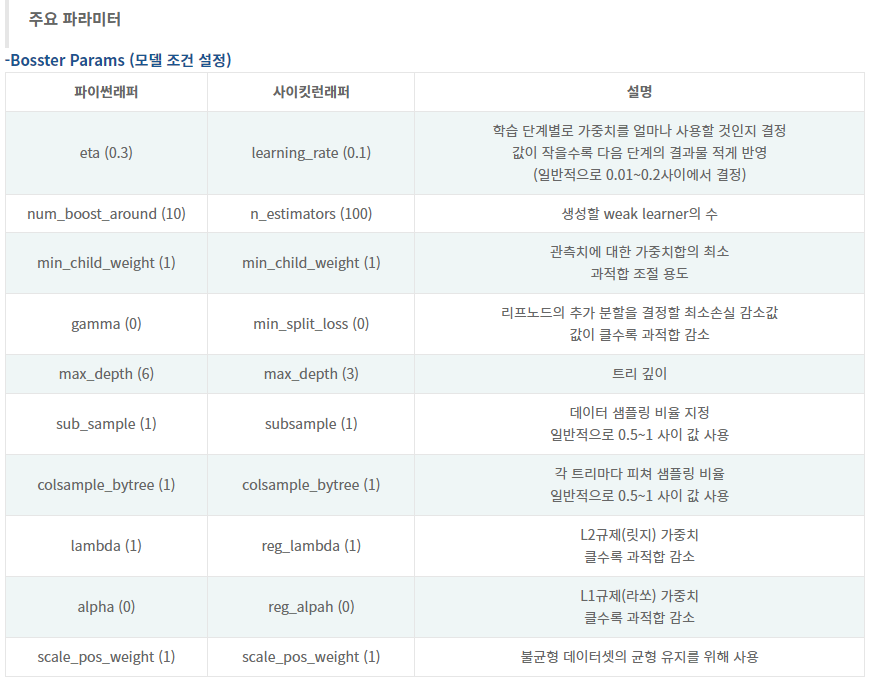
주요 매개변수
- Learning_rate[ 기본값 : 0.3] : Learning rate가 높을수록 과적합되기 쉬움
- n_estimators [기본값 : 100] : 생성할 weaker learner 수, learning_rate가 낮을 땐, n_estimators를 높여야 과적합이 방지됨, value가 너무 낮으면 underfitting이 되고 이는 낮은 정확성의 prediction이 되는반면 value가 너무 높으면 overfitting이 되고 training data 에는 정확한 prediction을 보이지만 test data에서는 정확성이 낮은 prediction을 가짐
- max_depth [ 기본값 : 6 ] : 트리의 maximum depth, 적절한 값이 제시되어야 하고 보통 3-10 사이 값이 적용됨, max_depth가 높을수록 모델의 복잡도가 커져 과적합되기 쉬움
- min_child_weight [ 기본값 : 1 ] : 관측치에 대한 가중치 합의 최소를 말함, 값이 높을수록 과적합이 방지됨
- gamma [ 기본값 : 0 ] : 리프노드의 추가분할을 결정할 최소손실 감소값, 해당값보다 손실이 크게 감소할 때 분리, 값이 높을수록 과적합이 방지됨
- subsample [ 기본값 : 1 ] : weak learner가 학습에 사용하는 데이터 샘플링 비율, 보통 0.5 ~ 1 사용됨, 값이 낮을수록 과적합이 방지됨
- colsample_bytree [ 기본값 : 1 ] : 각 tree 별 사용된 feature의 퍼센테이지, 보통 0.5 ~ 1 사용됨, 값이 낮을수록 과적합이 방지됨
- booster [기본값 = gbtree] : 어떤 부스터 구조를 쓸지 결정, 의사결정기반모형(gbtree), 선형모형(gblinear), dart
- n_jobs : XGBoost를 실행하는 데 사용되는 병렬 스레드 수
- verbosity [기본값 = 1] : 로그출력여부 0 (무음), 1 (경고), 2 (정보), 3 (디버그)
- early_stopping_rounds : 손실함수 값이 n번정도 개선이 없으면 학습을 중단
- eval_metric:
- rmse: root mean square error
- mae: mean absolute error
- logloss: negative log-likelihood
- error: Binary classification error rate (0.5 threshold)
- merror: Multiclass classification error rate
- mlogloss: Multiclass logloss
- auc: Area under the curve
- map (mean average precision)
-
과적합 방지를 위한 파라미터 조정 방법
- n_estimators 높이기
- learning rate 낮추기
- max_depth 낮추기
- min_child_weight 높이기
- gamma 높이기
- subs_ample, colsample_bytree 낮추기
-
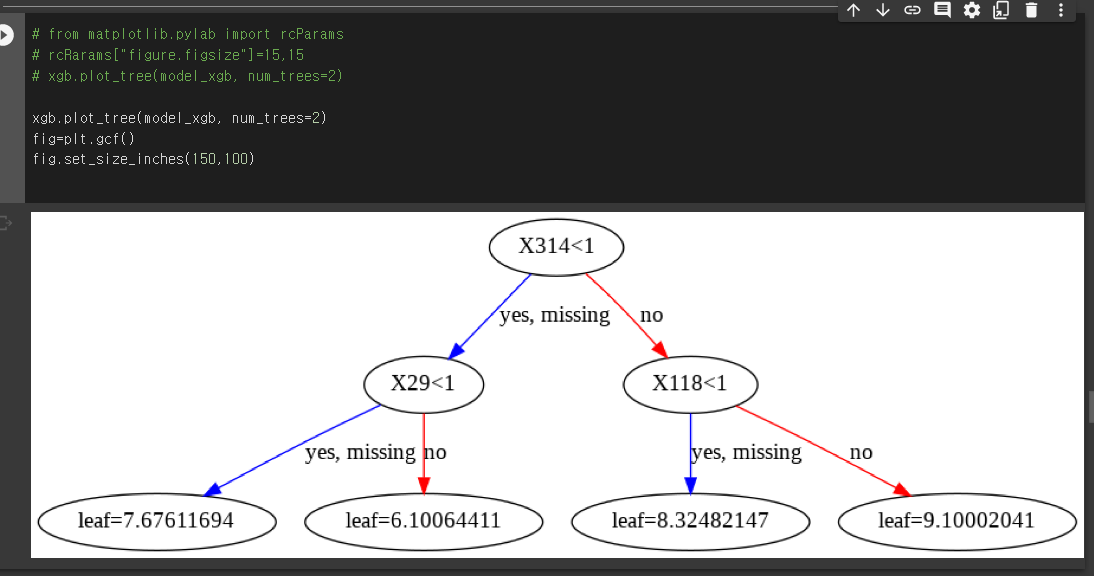
plot_importance, plot_tree
xgb.plot_importance(model_xgb)
# from matplotlib.pylab import rcParams
# rcRarams["figure.figsize"]=15,15
# xgb.plot_tree(model_xgb, num_trees=2)
xgb.plot_tree(model_xgb, num_trees=2)
fig=plt.gcf()
fig.set_size_inches(150,100)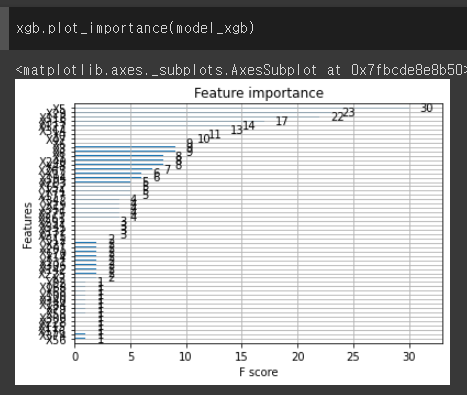
lightgbm
- Microsoft의 오픈소스 분산 그래디언트 부스팅 프레임워크
- 결정트리 알고리즘을 기반
- XGBoost와 정확도는 비슷하지만 빠름
- 행과 열을 줄이는 기법
- 장점
- 적은 메모리 사용량 (행과 열을 줄이기 때문에!)
- 더 나은 정확도
- 대규모 데이터를 처리
- 단점
- 과적합에 민감하고 작은 데이터에 대해 과적합되기 쉬움
- 특징
- 결정트리 알고리즘을 기반
- 범주형에 강하다
- GOSS(Gradient based One side Sampling) : 기울기 기반 단측 샘플링ㅎㅎ
- EFB(Exclusive Feature Bundling) : 배타적 특성 묶음ㅎㅎ
- 균형을 맞추지 않고 최대 손실 값을 가지는 리프 노드를 지속적으로 분할하여 트리가 깊어지고 비대칭적인 트리구조를 생성하여 예측 오류 손실을 최소화
- 결측치 전처리할 필요가 없음
- 주요 매개 변수
-
max_depth : 나무의 깊이. 단일 결정나무에서는 충분히 데이터를 고려하기 위해 depth를 적당한 깊이로 만들지만, 보정되기 때문에 부스팅에서는 깊이 하나짜리도 만드는 등, 깊이가 짧은것이 크리티컬하지 않음
-
min_data_in_leaf : 잎이 가질 수 있는 최소 레코드 수, 기본값은 20, 과적합을 다루기 위해 사용
feature_fraction : 부스팅 대상 모델이 랜덤포레스트일때, 랜덤포레스트는 feature의 일부만을 선택하여 훈련하는데, 이를 통제하기 위한 파라미터, 0.8이라면 LightGBM이 각 반복에서 80%의 파라미터를 무작위로 선택하여 트리를 생성
-
bagging_fraction : 데이터의 일부만을 사용하는 bagging의 비율
예를들어 오버피팅을 방지하기 위해 데이터의 일부만을 가져와서 훈련시키는데, 이는 오버피팅을 방지하며 약한예측기를 모두 합칠경우는 오히려 예측성능이 좋아질 수 있음
훈련 속도를 높이고 과적합을 방지하는 데 사용
-
early_stopping_round : 더이상 validation데이터에서 정확도가 좋아지지 않으면 멈춰버림 훈련데이터는 거의 에러율이 0에 가깝게 좋아지기 마련인데, validation데이터는 훈련에 사용되지 않기때문에 일정이상 좋아지지 않기 때문
-
lambda : 정규화에 사용되는 파라미터, 일반적인 값의 범위는 0 ~ 1
-
min_gain_to_split : 분기가 되는 최소 정보이득, 트리에서 유용한 분할 수를 제어하는 데 사용
-
max_cat_group : 범주형 변수가 많으면, 하나로 퉁쳐서 처리하게끔 만드는 최소단위
-
objective : lightgbm은 regression, binary, multiclass 모두 가능
-
boosting: gbdt(gradient boosting decision tree), rf(random forest), dart(dropouts meet multiple additive regression trees), goss(Gradient-based One-Side Sampling)
-
num_leaves: 결정나무에 있을 수 있는 최대 잎사귀 수. 기본값은 0.31
-
learning_rate : 각 예측기마다의 학습률 learning_rate은 아래의 num_boost_round와도 맞춰주어야 함
-
num_boost_round : boosting을 얼마나 돌릴지 지정한다. 보통 100정도면 너무 빠르게 끝나며, 시험용이 아니면 1000정도 설정하며, early_stopping_round가 지정되어있으면 더이상 진전이 없을 경우 알아서 멈춤
-
device : gpu, cpu
-
metric: loss를 측정하기 위한 기준. mae (mean absolute error), mse (mean squared error), 등
-
max_bin : 최대 bin
-
categorical_feature : 범주형 변수 지정
-
ignore_column : 컬럼을 무시한다. 무시하지 않을경우 모두 training에 넣는데, 뭔가 남겨놓아야할 컬럼이 있으면 설정
-
save_binary: True 메모리 절약
-
- plot_tree, plot_importance
```python lgbm.plot_importance(model_lgbm) lgbm.plot_tree(model_lgbm, figsize=(20,20), tree_index=0, show_info=['split_gain', 'internal_value', 'internal_count', 'leaf_count']) ```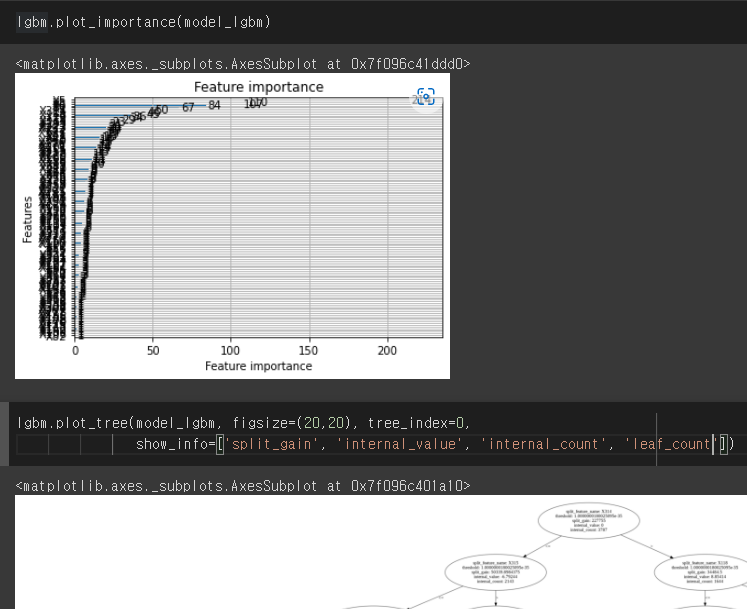
What makes LightGBM lightning fast? | by Abhishek Sharma | Towards Data Science
Features — LightGBM 3.3.2.99 documentation
CatBoost
- Yandex의 오픈소스 라이브러리
- gradient boosting tree(GBT)에서 카테고리형 변수와 과대적합 방지를 구현한 라이브러리
- 순열 기반 대안을 사용하여 범주형 기능을 해결
- 범주형에 강하다
- 빠른 GPU훈련
- 모델 및 기능 분석을 위한 시각화 도구,
- 과적합 극복 위해 순서가 있는 부스팅 사용
- 장점
- 과적합 극복 위해 순서가 있는 부스팅 사용
- 범주형에 강하다
- 단점
- 희소행렬을 지원하지 않음
- 특징
- 수평트리(Level-wise Tree)
- 임의 순열(Ordered Boosting)
- 중복되는 범주형 변수를 하나로 통합해 처리하여 feature 늘어나는 문제 예방
- 주요 파라미터
- cat_features 범주형 변수 인덱스 값
- loss_function 손실 함수를 지정
- eval_metric 평가 메트릭을 지정
- iterations 머신러닝 중 만들어질 수 있는 트리의 최대 갯수를 지정
- learning_rate 부스팅 과정 중 학습률을 지정
- subsample 배깅을 위한 서브샘플 비율을 지정
- max_leaves 최종 트리의 최대 리프 개수를 지정
import catboost
model_cat = catboost.CatBoostRegressor(eval_metric="R2", verbose=False)
from scipy.stats import randint
from sklearn.utils.fixes import loguniform
# SymmetricTree - 대칭트리
# Lossguide - 리프별
# Depthwise - 깊이별
param_grid = {
'n_estimators': randint(100, 300),
'depth': randint(4, 10),
'learning_rate': loguniform(1e-3, 0.1),
'min_child_samples': randint(10, 40),
'grow_policy': ['SymmetricTree', 'Lossguide', 'Depthwise']
}
result = model_cat.randomized_search(param_grid, X_train, y_train, cv=3, n_iter=10)
df_result = pd.DataFrame(result)
df_result = df_result.loc[["train-R2-mean", "test-R2-mean"], "cv_results"]
pd.DataFrame({"train-R2-mean" : df_result.loc["train-R2-mean"],
"test-R2-mean" : df_result.loc["test-R2-mean"] }).plot()
[ML] Unbiased boosting : CatBoost (tistory.com)
범주형 데이터 다루기
# category type 변경
cat_col = train.select_dtypes(include="object").columns
cat_col
for col in cat_col:
train[col] = train[col].astype("category")
test[col] = test[col].astype("category")
train.dtypes
X_train, X_valid, y_train, y_valid = train_test_split(train.drop(columns="y"), train["y"],
train_size = 0.9, random_state=0)
lightGBM
model_lgbm = lgbm.LGBMRegressor(random_state=42)
model_lgbm.fit(X_train, y_train)
catBoost
model_cat = catboost.CatBoostRegressor(eval_metric='R2', verbose=False,
cat_features=cat_col.tolist())
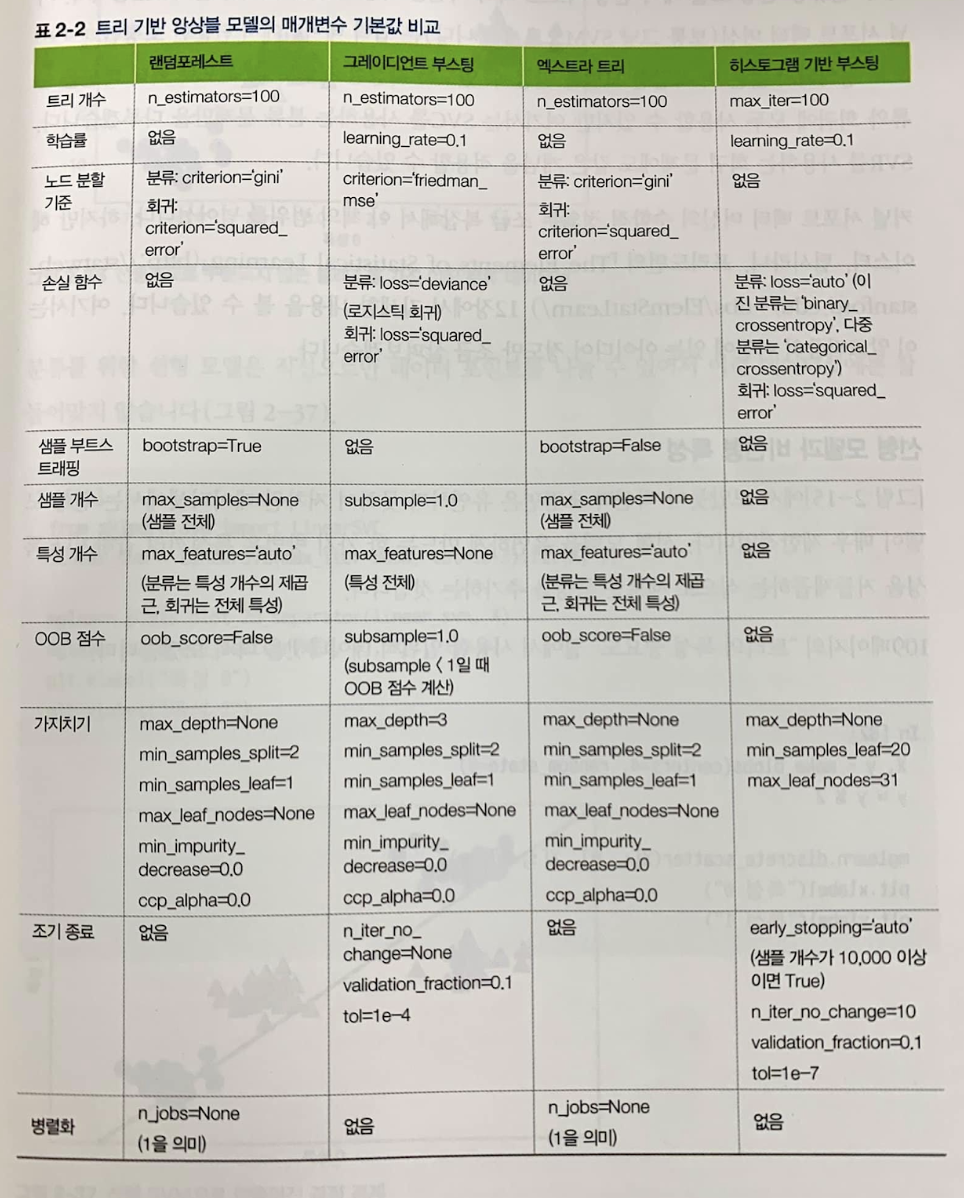
model_cat.fit(X_train, y_train)트리 기반 앙상블 모델의 매개변수 기본값 비교
점수산출 함수화
# 점수 산출하는 과정을 함수화합니다.
def scoreModel(model, X_train, X_valid, y_train, y_valid):
'''
머신러닝 모델과 X_train, X_valid, y_train, y_valid 변수를 받아서
모델명, 학습용 세트 정확도(R2 score), 테스트 세트 정확도(R2 score)를 출력하는 함수
'''
print("모델 : {}".format(model))
print("학습용 세트 정확도: {:.3f}".format(model.score(X_train, y_train)))
valid_score = model.score(X_valid, y_valid)
print("검증 세트 정확도: {:.3f}".format(valid_score))
return valid_score