오늘 뭘 했니?
-
케라스의 자동차연비 예측데이터로 regression 코랩 실습
실습파일: 코랩 regression.ipynb의 사본 -
텐서플로 분류 모델 만들고 성능을 개선하기 실습
실습파일: 코랩 0901-pima-TF-classification-input.ipynb -
텐서플로 회귀 모델 만들고 성능 개선 실습
실습파일: 백앤드닷 0902-pima-TF-regression-input -
넘파이
뭘 배웠니?(new)
1.컴파일 여러번 실행하면 레이어 계속 추가됨 주의
2. validation_split 을 비율로 지정해도 상관 없지만 데이터셋에 따라 어떤 문제가 있을 수 있을까요?
→ 계층추출을 할 수 없다.(시간 순서일 때)
2.loss는 0에 가까울수록, accuracy는 1에 가까울수록 좋은 성능이기 때문에(성격이 다르므로) 하나의 그래프에 그리는 거 노추천
#매번 로그 출력하면 너무 길어지니까 점찍어주는 함수
# 에포크가 끝날 때마다 점(.)을 출력해 훈련 진행 과정을 표시합니다
class PrintDot(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
if epoch % 100 == 0: print('')
print('.', end='')
EPOCHS = 1000
history = model.fit(
normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2, verbose=0,
callbacks=[PrintDot()])-
시그모이드 sigmoid :반환값이 1개일 때 사용
0~1사이의 값을 가지며 두 가지 값을 분류해줄 때 활성화 함수로 사용 -
소프트맥스 반환값이 여러개
다수의 값을 분류를 해줄 때 활성화 함수로 사용
분류의 값을 확률로 나타낸다. 모든 값을 합치면 1이 됨[0.7, 0,3] -
compile - 모델을 훈련시킬때의 설정
-
validation_split :비율로 지정해서 학습과 검증 데이터 나눌 수 있음
-
validation_data: 내가 직접 train_test_split을 하고 나서 나눈 데이터를 넣어줘도 됨,
-
patience = 10: 10번 실행해서도 성능이 좋아지지 않으면 멈추게 하는 설정
-
verbose : log 표시 정도
-
early_stop을 사용하는 이유는 예측값이 맞지 않는데 계속 학습을 할 경우 오히려 성능이 떨어지게 되어서, 더이상 좋아지지 않으면 종료 시킴
-
units : 동그라미의 개수, 즉, 파라미터이다.
https://alexlenail.me/NN-SVG/index.html
넘파이 NumPy
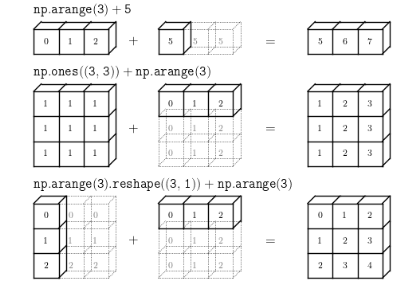
- 모든 연산이 브로드캐스트 방식으로 동작
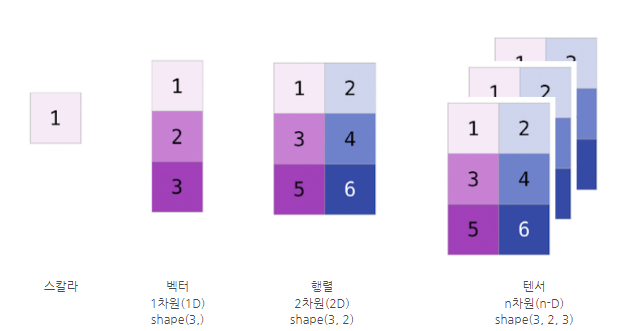
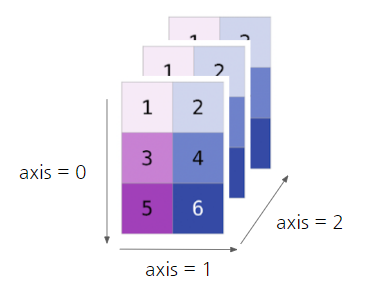
- 배열생성
- 정렬
- np.sort()
- np,argsort()
- np,searchsorted()
- np.partition()
- 인덱싱과 슬라이싱
- 브로드캐스팅
부족한 것
- train = df.sample(frac=0.8, random_state=42)
frac?
3F
사실(Fact) : 딥러닝 분류모델과 회귀모델을 만들고 성능을 개선하는 실습을 했다. backend.ai를 이용했다.
느낌(Feeling) : 어제보다 더 심각하게 모르겠다.
교훈(Finding) : 어제는 특강때문에 시간이 없었는데 오늘은 꼭 복습할 것
