오늘 뭘 했니?
-
텍스트 분석과 자연어처리
실습파일: 1101-BOW-tfidf-input -
머신러닝을 활용한 자연어 분류 실습
실습파일: 1102-ml-classification-input
뭘 배웠니?(new)
자연어 처리 NLP (Natural Language Processing)
- 단어 앞뒤의 순서 고려해야 함 (CNN에서 이미지 Flatten 하면 주변 정보 잃어버리는 것처럼)
- (주로) 텍스트를 벡터화하는 방법
- 머신러닝: 단어의 빈도수
- 딥러닝: 시퀀스 방식의 인코딩
사이킷런으로 자연어 처리 활용하기
- classification - 스팸메일분류, 뉴스기사 분류
- regression - 뉴스기사로 주가 예측
- clustering - 고객센터 비슷한 문의 모으기
- dementionality reduction - 차원축소 기법으로 시각화
.
머신러닝을 활용한 자연어 분류 과정
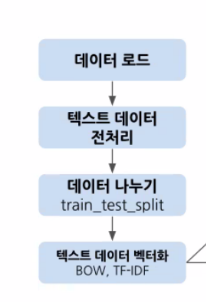
- 데이터나누기 텍스트데이터 벡터화는 상황에 따라 바뀔 수 있음, 근데 실제 비즈니스에서는 테스트에 어떤 데이터가 있을 지 모름, 따라서 보통 나눈 뒤에 벡터화를 진행함
텍스트 전처리
데이터 정제 및 전처리
- 기계가 텍스트를 이해할 수 있도록 텍스트를 정제하여 신호와 소음을 구분
- 이상치로 인한 오버피팅을 방지
- HTML 태그, 특수문자, 이모티콘
- 정규 표현식
- 불용어(Stopword)
- 어간 추출(Stemming)
- 음소표기법(Lemmatizing)
정규표현식 Regular Expression: re
- 정규 표현식(regular expression) 또는 정규식은 특정한 규칙을 가진 문자열의 집합을 의미
- 주로 패턴(pattern)으로 부르는 정규 표현식은 특정 목적을 위해 필요한 문자열 집합을 지정하기 위해 쓰이는 식
정규 표현식 - 위키백과, 우리 모두의 백과사전 (wikipedia.org)
토큰화 Tokenization
- 토큰화는 텍스트 조각을 토큰이라고 하는 더 작은 단위로 분리하는 방법
- 패턴을 찾는 데 매우 유용하며 형태소 분석 및 표제어를 위한 기본 단계로 간주
- 토큰(token): 문자열을 분석을 위한 문자열 단위로 단어, 문자 또는 하위 단어
- 토큰생성(tokenizing): 문자열을 토큰으로 나누는 작업
- ngram_range : 토큰을 몇 개 사용할지 구분.
ngram_range(1, 2) 이면 1이상 2이하 토큰
정제 Cleaning, 정규화 Normalization
- 정제: 갖고 있는 코퍼스로부터 노이즈 데이터를 제거
- 정규화: 표현 방법이 다른 단어들을 같은 단어로 만듦(예. 대소문자 변경 대체)
어간 추출 Stemming, 표제어 표기법 Lemmatization
-
어간 추출은 단어 형식을 의미가 있거나 무의미할 수 있는 (의사) 줄기로 축소
- 눈으로 봤을 때는 서로 다른 단어들이지만, 하나의 단어로 일반화시킬 수 있다면 하나의 단어로 일반화시켜 문서 내의 단어 수를 축소
-
표제어 표기법은 단어 형식을 언어학적으로 유효한 의미로 축소
- 단어의 식별 단일 항목으로 분석 할 수 있도록 단어의 어형 변화 형태를 그룹화
-
어간 추출은 원형을 잃을 수 있지만 표제어 표기법은 원형을 보존할 수 있음
한국어 불용어 Stopword
- 조사, 접미사 같은 단어들은 문장에서는 자주 등장하지만 실제 의미 분석을 하는데는 도움이 안 되는 단어
- ex) 어, 아이고, 차라리
- 언어 분류, 스팸 필터링, 캡션 생성, 자동 태그 생성, 감정 분석 또는 텍스트 분류와 관련된 작업 중 하나인 경우 불용어 제거를 추천
- 반면에 기계 번역, 질문 답변 문제, 텍스트 요약, 언어 모델링 중 하나인 경우 이러한 응용 프로그램의 중요한 부분이므로 불용어를 제거하지 않는 것을 추천
- 단어 빈도만 고려했을 경우, 불영어의 가능성이 높아짐
한국어 형태소 분석기
KoNLPy
soynlp
빈도 기반 워드 임베딩
1. 원-핫 인코딩(One-Hot Encoding)
2. BOW : Bag of Words
- 텍스트를 담는 가방(bag). 단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도(frequency)에만 집중하는 텍스트 데이터의 수치화 표현 방법
- • BOW는 단어의 순서가 완전히 무시 된다는 단점 (이를 보완하기 위해 n-gram 사용)
3. N-gram 언어 모델
- 모든 단어를 고려하는 것이 아니라 일부 단어만 고려하는 접근 방법 사용
- n-gram에서의 n의 의미: 단어의 수
- 앞뒤 의미맥락을 묶어줄 수는 있지만 조합의 갯수가 너무 많아짐 → 희소행렬생겨서 메모리 많이 사용하게 되는 단점도 있음
- 앞뒤 맥락 보존 가넝
4. 문서 단어 행렬(DTM Document-Term Matrix)
- 다수의 문서에서 등장하는 각 단어들의 빈도를 행렬로 표현한 것
- 쉽게 생각하면 각 문서에 대한 BOW를 하나의 행렬로 만든 것
5. TF , DF, IDF, TF-IDF
- TF 단어빈도 Term Frequency
- 특정한 단어가 문서 내에 얼마나 자주 등장하는지를 나타내는 값
- 이 값이 높을수록 문서에서 중요하다고 생각할 수 있음
- DF 문서빈도 Document Frequency
- 특정 단어가 등장한 문서의 수
- 단어 자체가 문서군 내에서 자주 사용되는 경우, 단어가 흔하게 등장한다는 의미
- IDF 역문서 빈도 Inverse Document Frequency
- DF의 역수로 DF에 반비례하는 수
- TF-IDF
- TF와 IDF를 곱한 값
- 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단
- 특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단
- 문서의 핵심어를 추출하거나, 검색 엔진에서 검색 결과의 순위를 결정하거나, 문서들 사이의 비슷한 정도를 구하는 등의 용도로 사용할 수 있음
- TF-IDF 값이 낮으면 중요도가 낮고, 높으면 중요도가 높은 것
- 불용어의 TF-IDF 값은 다른 단어의 TF-IDF에 비해서 낮음
사이킷런의 feature_extraction
-
CountVectorizer
- feature_extraction.text.CountVectorizer() 텍스트 문서 모음을 토큰 수의 행렬로 변환
- 단어 토큰을 생성하고 각 단어의 수를 세어 BOW(Bag of Words) 벡터를 생성
-
TfidfVectorizer
- feature_extracion.text.TfidfVectorizer() 문서 모음을 TF-IDF 매트릭스로 변환
- TF-IDF 인코딩은 단어를 갯수 그대로 카운트하지 않고 모든 문서에 공통적으로 들어있는 단어(낮은 구별력)의 경우 가중치를 축소하는 방법
-
주요 파라미터
- stop_words :
불용어 지정 - ngram_range : (min_n, max_n)
단어수를 min부터 max 까지 묶어서 사용
의미가 없는 불용어가 많이 생김 → 극복하기 위해 TF-IDF - analyzer : 문자열 {‘word’, ‘char’, ‘char_wb’} 또는 함수
- max_df : 정수 또는 [0.0, 1.0] 사이의 실수. default 1
빈도수로 해당 빈도 이하까지 사용
너무 자주 등장하지만 큰 의미가 없는 불용어 제거 효과 - min_df : 정수 또는 [0.0, 1.0] 사이의 실수. default 1
빈도수로 해당 빈도 이상인 단어만 사용
오타, 희귀 단어 제거 효과 - max_features: 정수 , default =None
벡터라이저가 학습할 기능(어휘)의 양 제한, corpus중 빈도수가 가장 높은 순으로 해당 갯수만큼만 추출 - vocabulary: Mapping or iterable, default =None
- stop_words :
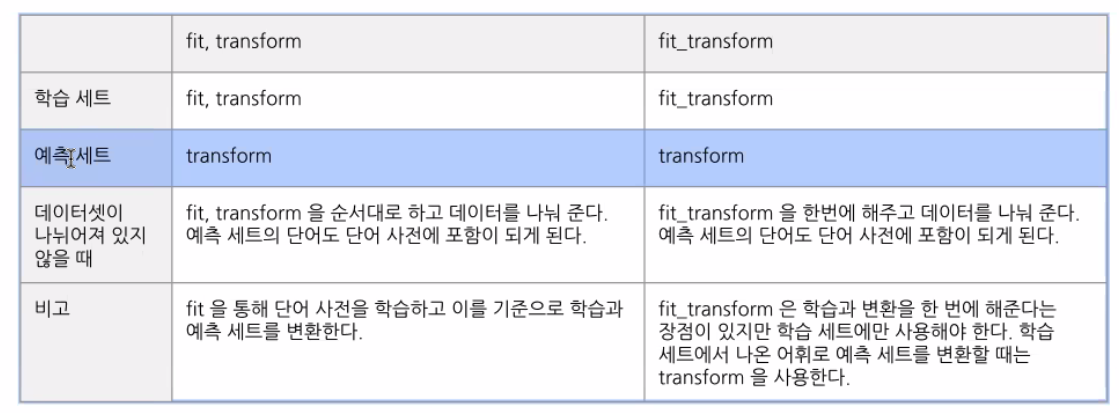
fit, transform과 fit_transform
1.min_df 값을 지정하게 되면 어떤 효과가 있을까요
→ 특이 단어 제거
→ 우연히 등장하는 의미없는 단어 제외
→ 오타 제거
2. max_df ?
→ 불용어 제거에 용이
3. TF-IDF는 문서 내 키워드 추출, 데이터 마이닝 분야에서 굉장히 활용도가 높은 알고리즘 중에 하나
4. countvectorizer +tfidfTransformer = tfidfvectorizer
5. 1. BOW 에서 앞뒤 순서를 고려하지 않는 단점을 보완한 방법이 무엇일까요?
→ n_gram
6. 단어빈도만 고려했을 때의 단점?
→ 불용어일 가능성이 높음
→ 특정분야에서만 사용하는 단어가 있을 때 문제가 생김 > 보완한 것이 tf-idf
부족한 것
- 정규표현식
- dict(zip)
vocab = tfidfvect.get_feature_names_out() idf_dict = dict(zip(vocab, idf)) idf_dict
3F
사실(Fact) : 자연어처리 NLP 에 대한 기초개념들을 배웠고 실습했다.
느낌(Feeling) : CNN 가고 NLP온다.. 또다시 생소한 단어들과 개념들이 마구잡이로 들어오니 아찔하다.
교훈(Finding) : 절대 복습을 밀려서는 안돼! 한번 놓치면 따라가는데 피똥싼다는 것을 지난 CNN때 이미 배웠기에..
