오늘 뭘 했니?
-
klue데이터셋을 통해 nmf와 lda 기법을 사용하여 토픽모델링
실습파일: 1203-klue-topics_extraction_with_nmf_lda-input -
klue데이터셋을 통해 유사도 분석
실습파일: 1204-LDA-similarity-input -
비즈니스데이터를 이용한 기업데이터 분석
실습파일: 1205-online-retail-eda-input
뭘 배웠니?(new)
토픽 모델링
토픽 모델(Topic model)이란 문서 집합의 추상적인 "주제"를 발견하기 위한 통계적 모델 중 하나로, 텍스트 본문의 숨겨진 의미구조를 발견하기 위해 사용되는 텍스트 마이닝 기법 중 하나
비음수 행렬분해( Non-negative matrix factorization, NMF)
유용한 특성을 뽑아내기 위한 비지도 학습 알고리즘
PCA와 비슷하며, 차원축소에도 사용가능PCA와 다른 점 : 음수가 아닌 성분(즉 양수인 성분)과 계수값을 찾는다.- 주성분과 계수가 모두 0보다 크거나 같아야 함
- 음수가 아닌 특성을 가진 데이터에만 적용 가능
- 용도 : 섞여 있는 데이터에서 원본/성분을 구분하는데 사용
- ex) 시각 처리, 문서 분류, 음파 분석
BOW 잠재 디리클레 분석(LDA)
- 자연어 처리에서 잠재 디리클레 할당(Latent Dirichlet allocation, LDA)은 주어진 문서에 대하여 각 문서에 어떤 주제들이 존재하는지를 서술하는 대한 확률적 토픽 모델 기법 중 하나
- 미리 알고 있는 주제별 단어수 분포를 바탕으로, 주어진 문서에서 발견된 단어수 분포를 분석함으로써 해당 문서가 어떤 주제들을 함께 다루고 있을지를 예측할 수 있음
- 주의⚡️ 선형판별분석과는 다름! (LDA: Linear discriminant analysis)
pyLDAvis
- 문서에 대한 클러스터 연관성을 찾는 데 사용되는 확률론적 모델
- 두 가지 확률 값을 사용하여 문서를 군집화
- P(단어 | 주제): 특정 단어가 특정 주제와 연관될 확률. 이 첫 번째 확률 집합은 워드 X 주제 행렬로도 간주됩니다.
- P(주제 | 문서): 문서와 관련된 항목. 이 두 번째 확률 집합은 주제 X 문서 행렬로 간주
Jupyter Notebook Viewer (nbviewer.org)
https://github.com/bmabey/pyLDAvis
# pip install pyldavis
# 주어진 문서에 어떤 주제들이 존재하는지를 확인하는 잠재 디리클레 분석(LDA)
from sklearn.decomposition import LatentDirichletAllocation
LDA_model = LatentDirichletAllocation(n_components=num_topics, random_state=42)
LDA_model.fit(dtm_cv)
# 토픽 모델링에 이용되는 LDA 모델의 학습 결과를 시각화하는 라이브러리인 pyLDAvis
# t-SNE(t-Stochastic Neighbor Embedding) 차원축소기법중 하나
import pyLDAvis.sklearn
pyLDAvis.enable_notebook()
pyLDAvis.sklearn.prepare(LDA_model, dtm_cv, cvect, mds='tsne'))
#독립 실행형 HTML 파일로 저장
pyLDAvis.save_html(prepare_tfidf, "lda_vis_tfidf.html")유사도
- 특성 공간 상에서 거리를 이용해 두 문서의 유사성(similarity)을 측정하는 방식으로 다음과 같은 유사도 측정 방법이 있음
- 유클리드 거리(euclidean distance)
- 코사인 유사도(cosine similarity)
- 맨해튼 거리(Manhattan distance)
- 자카드 유사도(Jaccard similarity)
# 등장 빈도에 기반하여, 코사인 유사도 알고리즘 적용해봅니다.
from sklearn.metrics.pairwise import cosine_similarity
cs_cv = cosine_similarity(dtm_cv[0], dtm_cv)
cs_cv기업데이터 분석
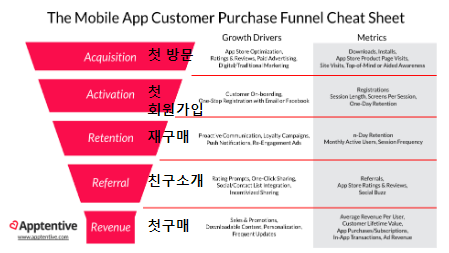
AARRR
-
AARRR은 시장 진입 단계에 맞는 특정 지표를 기준으로 우리 서비스의 상태를 가늠할 수 있는 효율적인 기준
-
수많은 데이터 중 현 시점에서 가장 핵심적인 지표에 집중할 수 있게 함으로써, 분석할 리소스(인력이나 시간)가 충분하지 않은 스타트업에게 매력적인 프레임워크
-
Acquisition : 어떻게 우리 서비스를 접하고 있는가
-
Activation : 사용자가 처음 서비스를 이용할 때 긍정적인 경험을 제공하는가
-
Retention : 이후의 서비스 재사용률은 어떻게 되는가
-
Referral : 사용자가 자발적 바이럴, 공유를 일으키고 있는가
-
Revenue : 최종 목적(매출)으로 연결되고 있는가
코호트 분석(Cohort analysis)
-
코호트 분석은 분석 전에 데이터 세트 의 데이터 를 관련 그룹으로 나누는 일종의 행동 분석
-
이러한 그룹 또는 집단은 일반적으로 정의된 시간 범위 내에서 공통된 특성이나 경험을 공유
-
코호트 분석을 통해 회사는 고객이 겪는 자연적 주기를 고려하지 않고 맹목적으로 모든 고객을 분할하는 대신 고객(또는 사용자)의 수명 주기 전반에 걸쳐 패턴을 명확하게 볼 수 있음
-
이러한 시간 패턴을 보고 회사는 특정 집단에 맞게 서비스를 조정 가능
-
시간집단
특정 기간 동안 제품이나 서비스에 가입한 고객
- 행동집단
과거에 제품을 구매했거나 서비스에 가입한 고객
- 규모집단
회사의 제품이나 서비스를 구매하는 다양한 규모의 고객
잔존율 분석(Retention rate analysis)
- 고객이 이탈하는 방법과 이유를 이해하기 위해 사용자 메트릭을 분석하는 과정
- 유지 분석은 유지 및 신규 사용자 확보율을 개선하여 수익성 있는 고객 기반을 유지방법 확보
- 일관된 유지 분석을 실행하여 알 수 있는 항목
- 고객이 이탈하는 이유
- 고객이 떠날 가능성이 더 높을 때
- 이탈이 수익에 미치는 영향
- 유지 전략을 개선하는 방법
RFM 분석
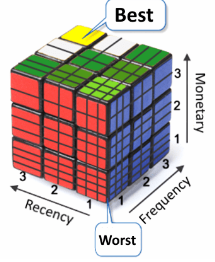
Recency : 얼마나 최근에 구매했는가
Frequency : 얼마나 자주 구매했는가
Monetary : 얼마나 많은 금액을 지출했는가
- RFM은 가치있는 고객을 추출해내어 이를 기준으로 고객을 분류할 수 있는 분석 방법
- 구매 가능성이 높은 고객을 선정하기 위한 데이터 분석방법
- • RFM 분석에서 우리는 세 가지 지표 또는 차원에 따라 각 고객을 분석
ARPU, ARPPU
- ARPU(Average Revenue Per User) : 가입자 당 평균수익
- 가입한 서비스에 대해 가입자 1명이 특정 기간 동안 지출한 평균 금액
- ARPU = 매출 / 중복을 제외한 순수 활동 사용자 수(전체 유저)
- ARPPU(Average Revenue Per Paying User): 결제 유저당 수익, 지불 유저 별 결제금액
- 지불 유저 1명 당 한 달에 결제하는 평균 금액을 산정한 수치
- 기준 기간의 총 수익 / 기준 기간 당 구매 고객

부족한 것
- .style.format("{:,.0f}")
# 국가별 매출액의 평균과 합계를 구합니다.
# TotalPrice를 통해 매출액 상위 10개만 가져옵니다.
df.groupby("Country")["TotalPrice"].agg(['mean','sum']).nlargest(10, "sum").style.format("{:,.0f}")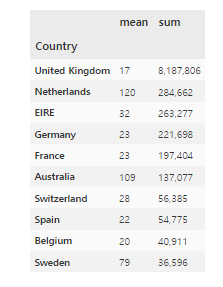
- agg({"InvoiceNo":"count","Quantity":"sum"})
groupby agg 딕셔너리로 지정해서 변수마다 다른 연산
df.groupby("StockCode").agg({"InvoiceNo":"count",
"Quantity":"sum","TotalPrice":"sum"}).sort_values(
"InvoiceNo", ascending=False)- crosstab, groupby, pivot 차이점 다시 정리
- print(plt.colormaps()) 좀 외워라 좀!!!!!
- copy() 깊복 얕복
df_valid = df[df["CustomerID"].notnull() & (df["Quantity"]>0) & (df["UnitPrice"]>0)].copy() - df.transform()
- unstack() 마지막 인덱스값을 컬럼으로 올려줌
- df.transform
3F
사실(Fact) : 기업데이터 분석을 하였다.
느낌(Feeling) : 딥러닝 이론에 치여있다가 익숙한 걸 하게 되니 진짜 살 거 같다.
교훈(Finding) : 쉽다고 안주하지말고 복습 꾸준히..!
