리스트 (List) & 딕셔너리 (Dictionary)
리스트와 딕셔너리는 파이썬을 사용하다보면 가장 빈번하게 접하게 되는 자료형이다. 코딩 테스트에서 이 2가지 자료형은 거의 모든 문제에 빠짐없이 사용된다고 해도 과언이 아니다. 리스트와 딕셔너리에 대해서 자세히 알아보았다.
리스트 (List)
파이썬의 리스트는 말 그대로 순서대로 저장하는 시퀀스이자 변경 가능한 목록을 말한다. 입력 순서가 유지되고 내부적으로 동적배열로 구현된다.
파이썬의 리스트의 장점은 매우 다양한 기능을 제공한다는 점이다. 파이썬의 리스트는 스택과 큐에서 사용 가능한 모든 연산을 제공하기 때문에 스택이나 큐에 대한 고민을 하지 않아도 된다. 또한 append()를 사용하여 요소를 추가하고 index()를 사용하여 원하는 요소의 인덱스 값을 반환하는 등의 다양한 기능들이 존재한다.
리스트의 주요 연산
len(a) O(1) 전체 요소의 개수를 반환한다.
a[i] O(1) 인덱스 i의 요소를 가져온다.
a[i:j] O(k) i부터 j까지 슬라이스의 길이만큼인 k개의 요소를 가져온다. 객체 k개에 대한 조회가 필요하므로 O(k)이다.
elem in a O(n) elem 요소가 존재하는지 확인한다. 처음부터 순차 탐색하므로 n만큼의 시간이 소요된다.
a.count(elem) O(n) elem 요소의 개수를 반환한다.
a.index(elem) O(n) elem 요소의 인덱스를 반환한다.
a.append(elem) O(1) 리스트의 마지막에 elem 요소를 추가한다.
a.pop() O(1) 리스트의 마지막 요소를 추출한다. (스택의 연산)
a.pop(0) O(n) 리스트의 첫번째 요소를 추출한다. (큐의 연산) 이 경우 전체 복사가 필요하므로 O(n)이다. 큐의 연산을 주로 사용한다면 리스트보다 O(1)에 가능한 데크(deque)를 권장한다.
del a[i] O(n) a[i]를 제거한다. 시간 복잡도는 i에 따라 다르고 최악의 경우 O(n)이다.
a.sort() O(n log n) 리스트를 정렬한다. 팀소트(Timsort)를 사용하며 최선의 경우 O(n)에도 실행할 수 있다.
min(a), max(a) O(n) 최솟값/최댓값을 반환한다. 이 연산을 위해 전체를 선형탐색 해야하므로 O(n)이다.
a.reverse() O(n) 리스트를 뒤집는다. 리스트는 입력 순서가 유지되므로 뒤집게 되면 입력 순서가 반대로 된다.리스트의 경우 탐색 시 값의 존재 유무를 확인하려면 정렬된 경우에는 이진 탐색이 효율적이다. 그러나 매번 정렬이 필요하고 대개는 리스트가 정렬된 상태가 아니기 때문에 리스트의 경우에는 모든 엘리먼트를 순차적으로 조회하는 형태로 구현되어 있다. 최악의 경우 O(n)이 소요된다.
리스트의 활용 방법
선언
리스트의 선언 방법은 다음과 같다.
a = list()
a = []추가
다음과 같이 초기값을 지정하여 선언하거나 append()로 요소를 추가할 수 있다.
a = [1, 2, 3]
print(a) # [1, 2, 3]
a.append(4)
print(a) # [1, 2, 3, 4]insert() 함수를 사용하면 특정 위치의 인덱스를 지정하여 요소를 추가할 수 있다.
a.insert(3, 5) # 인덱스 3 자리에 5를 삽입
print(a) # [1, 2, 3, 5, 4]리스트 자료형
파이썬의 리스트는 다양한 자료형을 단일 리스트에 관리할 수 있다.
a.append('Hello')
a.append(True)
print(a) # [1, 2, 3, 5, 4, 'Hello', True]다른 언어들은 동적 배열에 동일한 자료형만 입력이 가능하도록 제한되어 있는 경우가 대부분이다. 하지만 파이썬은 다양한 자료형을 하나의 리스트에 입력할 수 있어 관리하기 매우 편리하고 생산성 또한 우수하다.
슬라이싱
파이썬의 리스트는 슬라이싱 기능을 제공한다. 슬라이싱은 특정 범위 내의 값을 매우 편리하게 가져올 수 있기 때문에 많이 사용된다. 원래는 문자열에 유용하게 사용되는 기능으로 리스트에도 동일한 형태로 사용 가능하다. 슬라이싱은 간결함과 강력함을 자랑하는 파이썬의 특징을 잘 나타내는 대표적인 기능 중 하나로, 유난히 돋보이는 장점이기도 하다.
print(a[1:3]) # [2, 3]다른 언어들은 인덱스의 반복문을 구성하고 순회하며 값을 출력해야 하지만 파이썬의 슬라이싱은 시작 인덱스와 종료 인덱스를 설정하여 간단히 해당하는 값을 출력할 수 있다. 시작 인덱스가 0이거나 종료 인덱스가 마지막인 경우에는 생략도 가능하다.
print(a[:3]) # [1, 2, 3]
print(a[4:]) # [4, 'Hello', True]세 번째 파라미터를 부여하면 단계의 의미를 가진다. 만약 세 번째 파라미터를 2로 부여하면 두 칸씩 건너뛰어 값을 불러온다. 세번째 파라미터에 -1을 부여하면 뒤에서 앞으로 역방향 순회를 하게 된다.
print(a[1:4:2] # [2. 5]
print(a[::-1] # [True, 'Hello', 4, 5, 3, 2, 1]IndexError
존재하지 않는 인덱스를 조회할 경우에는 IndexError가 발생한다. 이는 try 구문으로 에러에 대한 예외처리를 할 수 있다.
try:
print(a[9])
except IndexError:
print("Index Error!")삭제
리스트에서 요소를 삭제하는 방법은 크게 2가지가 있다.
- 인덱스로 접근하여 삭제
- 값으로 접근하여 삭제
다음과 같이 del을 사용하면 인덱스로 접근하여 삭제할 수 있다.
del a[1]
print(a) # [1, 3, 5, 4, 'Hello', True]remove() 함수를 사용하면 값으로 접근하여 삭제할 수 있다.
a.remove(3)
print(a) # [1, 5, 4, 'Hello', True]pop() 함수를 사용하면 스택의 pop 연산처럼 추출로 처리된다. 추출은 삭제될 값을 반환하고 삭제하는 것이다.
print(a.pop(3)) # 'Hello'
print(a) # [1, 5, 4, True]리스트의 특징
파이썬의 리스트는 연속된 공간에 요소를 배치하는 배열의 장접과 다양한 타입을 연결해 배치하는 연결 리스트의 장접을 모두 취한 듯한 형태를 띠며, 실제로 리스트를 잘 사용하기만 해도 배열과 연결 리스트가 모두 필요 없을 정도로 강력하다.
리스트의 구조
CPython에서 리스트를 정의한 헤더 파일을 보면 리스트는 요소에 대한 포인터 목록(ob_item)을 갖고 있는 구조체로 선언되어 있다. 리스트에 요소를 추가하거나 조작하기 시작하면 ob_item의 사이즈를 조절해 나가는 형태로 구현되어 있다.
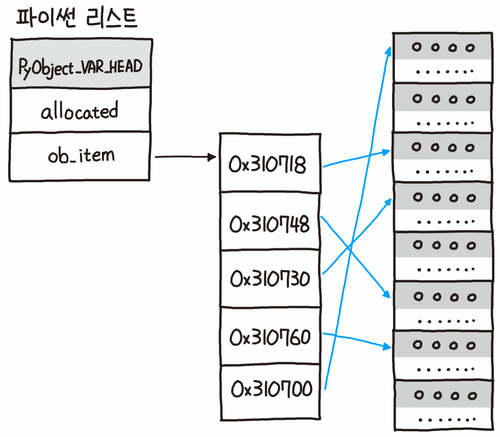
이전 글에서 파이썬의 모든 자료형은 정수형 또는 객체로 되어 있음을 다룬 적이 있었다. 리스트는 이처럼 객체로 되어 있는 모든 자료형을 위의 그림처럼 포인터로 연결한다.
파이썬은 모든 것이 객체이고, 리스트는 위의 그림처럼 이들 객체에 대한 포인터 목록을 관리하는 형태로 구현되어 있다. 사실상 연결 리스트에 대한 포인터 목록을 배열 형태로 관리하고 있으며 그 덕에 파이썬의 리스트는 배열과 연결 리스트를 합친 듯한 강력한 기능을 자랑한다.
리스트의 자료형
위에서 설명했듯이 리스트는 다양한 자료형을 단일 리스트에 입력할 수 있다. 일반적으로 정수형 배열은 정수형 이외의 자료형은 입력될 수 없지만 파이썬의 경우 연결 리스트에 대한 포인터 목록을 관리하고 있기 때문에 다양한 자료형을 동시에 단일 리스트에서 관리할 수 있다.
이 기능은 매우 편리하고 강력하지만 다양한 자료형을 동시에 관리하게 되면 각 자료형의 크기가 모두 다르기 때문에 이들을 연속된 메모리 공간에 할당하는 것이 불가능하다. 결국 각각의 객체에 대한 참조로 구현하게 된다. 이에 따라 인덱스를 조회하는 데에도 모든 포인터의 위치를 찾아가서 타입 코드를 확인하고 값을 일일히 살펴봐야 하는 등의 추가적인 작업이 필요하게 되고 속도면에서 훨씬 불리하다. 이는 다양한 자료형을 단일 리스트에서 관리할 수 있는 파이썬의 리스트의 장단점이라고 할 수 있다.
딕셔너리 (Dictionary)
파이썬의 딕셔너리는 키/값으로 이뤄진다. 파이썬 3.7 이상부터는 딕셔너리의 입력순서가 유지되고 내부적으로 해시 테이블로 구현된다.
인덱스를 숫자로만 지정할 수 있는 리스트와 달리 딕셔너리는 문자를 포함한 다양한 타입을 키로 사용할 수 있다. 파이썬의 딕셔너리는 해시할 수만 있다면 숫자뿐만 아니라, 문자, 집합까지 불변 객체를 모두 키로 사용할 수 있다. 이 과정을 해싱이라 하고 해시 테이블을 이용해 자료를 저장한다. 해시 테이블은 다양한 타입을 키로 지원하면서도 입력과 조회 모두 O(1)에 가능하다. 물론 최악의 경우에는 O(n)이 될 수 있지만 대부분의 경우 훨씬 더 빨리 실행되며 분할 상환 분석에 따른 시간 복잡도는 O(1)이다.
딕셔너리의 주요 연산
len(a) O(1) 요소의 개수를 반환한다.
a[key] O(1) 키를 조회하여 값을 반환한다.
a[key] = value O(1) 키/값을 삽입한다.
key in a O(1) 딕셔너리에 키가 존재하는지 확인한다.딕셔너리 입력 순서 유지
이처럼 딕셔너리는 대부분의 연산이 O(1)에 처리되는 매우 우수한 자료형이다. 키/값 구조의 데이터를 저장하는 유용한 자료형으로서 코딩 테스트에서도 리스트만큼이나 매우 빈번하게 활용된다. 원래 파이썬 3.6 이하의 딕셔너리는 입력 순서를 유지하지 않았다. 입력 순서를 유지하기 위해서는 collections.Ordered.Dict()라는 별도 자료형을 사용해야 했다. 그러나 파이썬 3.7부터는 내부적으로 인덱스를 이용해 입력 순서를 유지하도록 개선되었다. 여전히 파이썬 3.6 이하 버전을 사용하는 곳이 많기 때문에 코드를 작성할 때에 딕셔너리의 입력 순서가 유지된다고 생각하고 코드를 작성하는 것은 매우 위험하기 때문에 주의해야 한다.
딕셔너리 관련 모듈
파이썬은 딕셔너리를 효율적으로 생성하기 위한 추가 모듈을 많이 지원한다.
- collections.Ordered.Dict()
항상 입력 순서가 유지된다. - collections.defaultdict()
조회 시 항상 디폴트 값을 생성해 키 오류를 방지한다. - collecitons.Counter()
요소의 값을 키로 하고 개수를 값 형태로 만들어 카운팅한다.
딕셔너리의 활용 방법
선언
딕셔너리는 다음과 같이 선언할 수 있다.
a = dict()
a = {}초기값을 지정하여 선언할 수도 있고 나중에 별도로 선언하여 새로운 값을 할당할 수도 있다.
a = {'k1': 'v1', 'k2': 'v2'}
print(a) # {'k1': 'v1', 'k2': 'v2'}
a['k3] = 'v3'
print(a) # {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}KeyError
딕셔너리는 키를 지정하면 값을 조회할 수 있다. 이 과정에서 존재하지 않는 키를 조회할 경우에는 에러가 발생한다. 이는 리스트에서 IndexError가 발생하는 것과 같은 에러로 딕셔너리에서는 KeyError로 발생한다. 이는 try 구문으로 예외처리 할 수 있다.
try:
print(a['k4'])
except KeyError:
print("KeyError!")try 구문을 사용하면 존재하지 않는 키의 경우 별도 작업을 할 수 있기 때문에 매우 유용하다.
조회
딕셔너리에 있는 키/값은 반복문으로도 조회가 가능하다. 다음과 같이 딕셔너리의 items() 메소드를 사용하면 키와 값을 불러올 수 있다.
for k, v in a.items():
print(k, v) # 딕셔너리의 키/값을 순서대로 출력딕셔너리 모듈
딕셔너리 관련된 특수한 형태의 컨테이너 자료형 defaultdict, Counter, OrderedDict에 대해 자세히 알아보았다.
defaultdict 객체
defaultdict 객체는 존재하지 않는 키를 조회할 경우 에러 메세지를 출력하는 대신에 기본 값을 기준으로 해당 키에 대한 딕셔너리 아이템을 생성해준다. 실제로는 collections.defaultdict 클래스를 가진다.
a = collecitions.defaultdict(int)
a['A'] = 5
a['B'] = 4
print(a) # {'A': 5, 'B': 4}
a['C'] += 1
print(a) # {'A': 5, 'B': 4, 'C' : 1}a 딕셔너리에서 C는 존재하지 않는 키이다. defaultdict를 사용하지 않았더라면 KeyError가 발생했을 상황이지만 defaultdict를 사용하였기 때문에 존재하지 않는 키 C에 대한 기본값 0이 자동 생성되었고 +=1 연산을 수행하여 'C': 1이 만들어지게 된 것이다.
Counter 객체
Counter 객체는 아이템에 대한 개수를 계산하여 딕셔너리로 리턴한다.
a = [1, 2, 3, 4, 5, 5, 5, 6, 6]
b = collections.Counter(a)
print(b) # {5: 3, 6: 2, 1: 1, 2: 1, 3: 1, 4: 1}마지막 줄의 주석과 같이 키에는 아이템의 값이 들어가고, 값에는 해당 아이템의 개수가 들어간 딕셔너리가 생성된다. 실제로는 딕셔너리를 한 번 더 래핑한 collections.Counter 클래스를 갖는다. 개수를 자동으로 계산해주기 때문에 매우 편리하며 여러 분야에서 다양하게 활용된다.
빈도수가 가장 높은 요소는 most_common()을 사용해 추출할 수 있다.
print(b.most_common(2)) # [(5, 3), (6, 2)]most_common()의 파라미터로 2가 들어갔으므로 빈도수가 가장 높은 요수 2개를 추출한 것을 확인할 수 있다.
OrderedDict 객체
대부분의 언어에서 해시 테이블을 이용한 자료형은 입력 순서가 유지되지 않는다. 파이썬 3.6 이하 버전도 그러했고 입력 순서를 유지해주는 OrderedDict를 제공했다.
print(collections.OrderedDict({'banana': 3, 'apple': 4, 'pear': 1, 'orange': 2})
# {'banana': 3, 'apple': 4, 'pear': 1, 'orange': 2}그러나 파이썬 3.7 버전부터 딕셔너리에 대한 입력 순서의 유지를 제공하게 되었고 이에 따라 OrderedDict는 사용할 필요가 없어졌다. 그러나 아직까지도 여러 곳에서 파이썬 3.6 이하의 버전을 사용하고 있고 원래 해시 테이블은 입력 순서에 관여하지 않는 자료형이기 때문에 코드를 작성할 때에 딕셔너리의 입력 순서 유지를 기대하고 코드를 작성하게 된다면 매우 위험할 수 있으므로 주의해야 한다.
문법: 타입 선언
파이썬에서 타입을 선언하는 문법은 타입의 이름을 지정하는 방식이 있지만 기호를 사용해서 좀 더 간편하게 처리할 수도 있다.
- 이름으로 선언
a = list()
print(type(a)) # <class 'list'>- 기호로 선언
print(type([]) # <class 'list'>
print(type(()) # <class 'tuple'>
print(type({}) # <class 'dict'>
print(type({1}) # <class 'set'>
