
파이썬의 단점
-
파이썬은 인터프리터 언어이기 때문에 컴파일 언어보다 느리고 따라서 실시간 거래 시스템처럼 매우 짧은 응답시간을 필요로 하는데 사용할 수 없다.
-
파이썬은 동시다발적인 멀티스레드를 처리하거나 CPU에 집중된 많은 스레드를 처리하는 데 적합하지 않다.
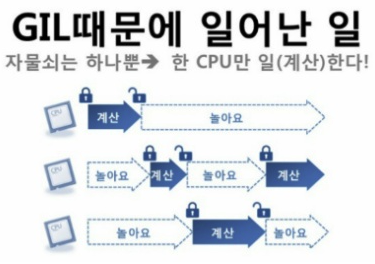
-> GIL(Global Interpreter Lock)때문 : 파이썬은 자원배분을 한 쓰레드에게 할당한 후, 그 쓰레드가 끝날 때까지 Lock을 걸어 다른 쓰레드가 접근하지 못하게 한다.
-> 때문에 파이썬에서 스레드 여러개를 이용하는 프로그램을 만들게 되면 동시에 일하는 것을 바라지만 실제로는 CPU를 점유할 수 있는 스레드는 한 개이기 때문에 실행속도가 더 느려지게 되는 것.
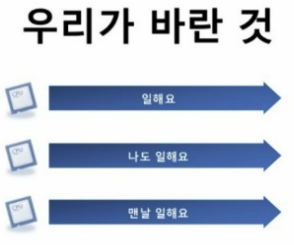
멀티 쓰레드의 효과를 볼 수 있는 경우
I/O 작업의 경우 CPU작업이 아니라서 GIL의 영향을 받지 않는다. 따라서 멀티 쓰레드의 효과를 볼 수 있다.
-> 반복 작업이 I/O 작업 (입출력 또는 파일 다운로드 등)으로 이루어져 있다면 멀티 쓰레드를 이용하여 성능을 개선할 수 있다.
그렇다면 CPU bound & I/O bound 에 대해 알아보자
Burst : 어떤 특정된 기준(criterion)에 따라 한 단위로서 취급되는 연속된 신호(signal) 또는 데이터의 모임.
어떤 현상이 짧은 시간에 집중적으로 일어나는 현상.
또는 주기억 장치의 내용을 캐시 기억 장치에 블록 단위로 한꺼번에 전송하는 것.
-> 즉 CPU burst는 프로세스 내에서 CPU 명령 작업이 연속된 작업을 의미하며, IO Burst는 로컬 혹은 네크워크 등의 I/O wait 작업이 연속되는 것을 의미한다.
프로세스는 수행과정 중에 CPU Burst, I/O Burst가 계속 변경되면서 수행되며 프로세스 작업의 종류에 따라 CPU Burst 가 일어나는 시간이 달라진다. 이 때 일반적으로 CPU Burst가 많이 일어나는 작업을 CPU bound process라고 부르게 된다.
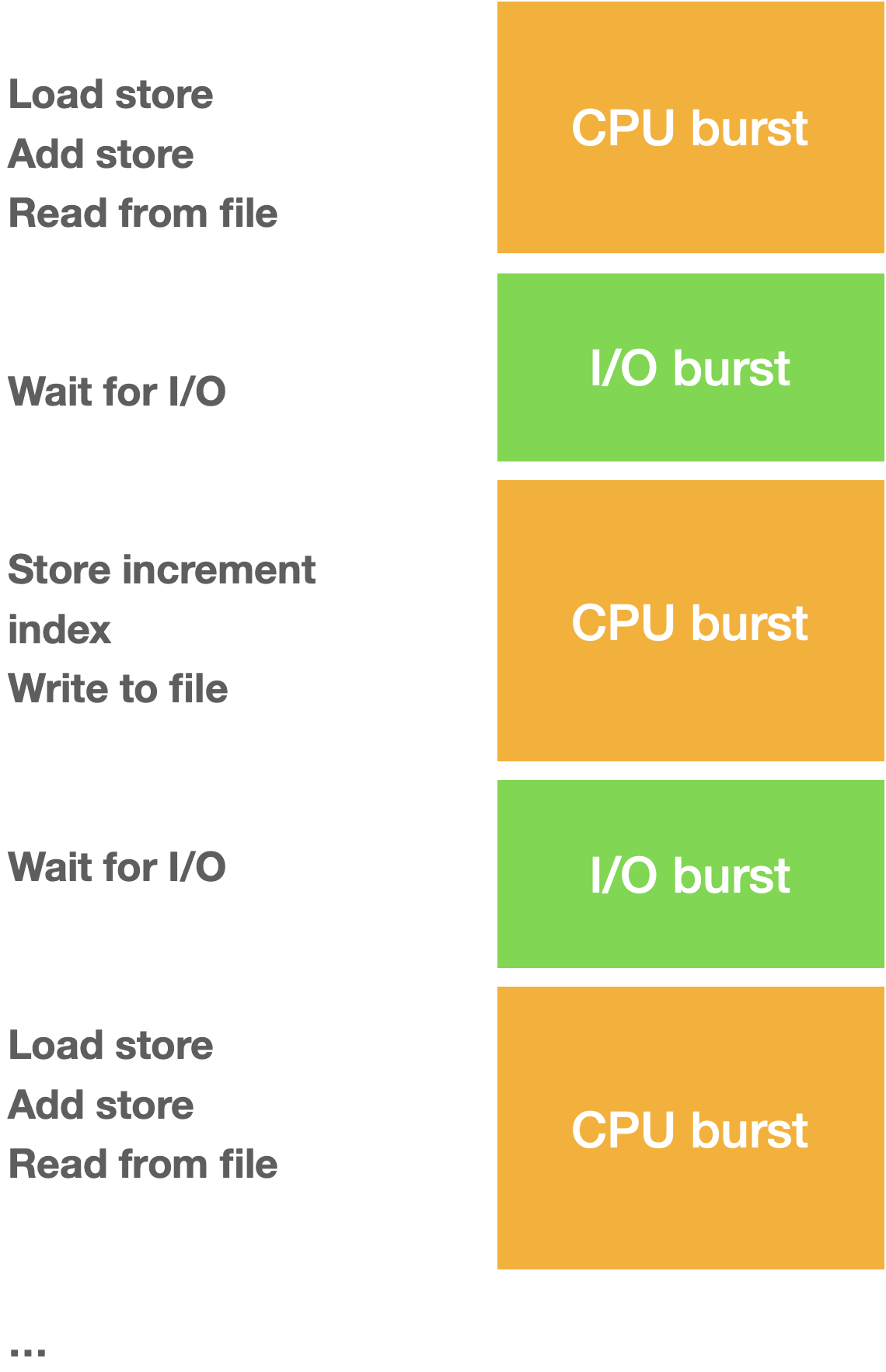
CPU Bound Process
어떤 작업들이 CPU를 많이 사용하게 되는가?
CPU의 주 목적에 부합하는 연산 처리가 많은 프로세스에서 CPU burst 가 많이 일어나게 될 것.
연산이 많은 작업들의 예)
- 데이터 마이닝
- 이미지 프로세싱
- 암호화폐 마이닝
- ....
성능 향상을 위한 방법
프로세스마다 성능에 영향을 미치는 원인이 다르기 때문에, 성능향상 방법을 고민하기에 앞서 작업한 프로젝트가 CPU bound process 인지 IO bound process인지 판별하는 것이 중요.
CPU bound process
-
CPU bound process는 말 그대로 CPU의 성능에 영향을 받는 작업이기 때문에 CPU의 성능을 높여 (높은 클럭의 CPU 사용) 작업의 성능을 향상시킬 수 있다.
-
또한, 단순히 클럭만 높이는 방법이 아닌 프로세서가 추가된 멀티코어 프로세스를 이용해 작업을 병렬적으로 처리해 성능을 더욱이 향상시킬 수 있다.
-
특히나 일반적으로 CPU 연산이 많이 발생하는 머신러닝 작업에서 Many-core processor인 GPU를 사용하는 이유도 병렬연산을 통해 성능을 향상시키려는 같은 이유이다.
I/O bound process
-
로컬 저장소에 대한 I/O wait가 많은 작업의 경우 하드웨어 교체를 통해 (HDD -> SSD) 성능을 향상시켜 볼 수 있을 것. 그보다 좋은 것은 로컬 저장소보다 빠른 memory를 활용하는 것.
다만, memory 용량에는 한계가 있고 네트워크에 대한 I/O wait 성능 개선에는 큰 도움이 안될 수 있다는 점 존재. -
외부 I/O의 성능을 향상시키는 것은 어쩌면 처리할 수 없는 부분이기 때문에, Non-blocking I/O를 통해 쓰로풋을 향상시키는 방법도 있을 것.
다시 Python의 병렬 작업으로 돌아와서
우리가 원하는 병렬적인 작업을 하기 위해서는 쓰레드 대신 프로세스를 만들어주는 라이브러리 Multiprocessing 모듈을 사용하면 된다고 함.
multiprocessing 모듈은 스레드 대신 프로세스를 띄워준다.
즉, 하나의 interpreter를 쓰는 게 아니라 여럿의 프로세서를 구동시키는 것.
이 경우에는 프로세스 관리는 Python에서 하는 것이 아니라 os에서 하는 것이기 때문에, OS에서 적절하게 프로세스를 코어별로 할당을 하게 해서, 전체적으로 스피드를 올려주게 됨.
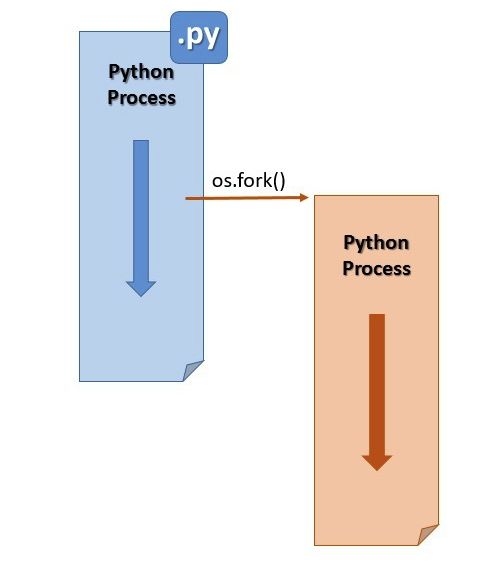
멀티프로세싱 모듈은 fork를 통해서 동시에 여러 프로세스에 원하는 작업을 실행할 수 있도록 도와주는 모듈이다.
파이썬에서는 OS 모듈에 속한 fork() 함수를 사용해서 여러 프로세스를 사용할 수 있다.
파이썬 프로세스가 fork() 함수를 호출하면 프로세스의 복사본이 생성되고 이 카피는 모든 데이터와 코드를 부모 프로세스에서 직접 가져와 운영 체제에서 자체 PID를 얻는 완전히 독립적인 프로세스로 수행된다.
IPC에서 손해를 보긴하지만 이를 지원하는 각종 메커니즘도 존재하며 쓰레드와 똑같이 사용할 수 있다.
PID는 뭔데?
Process identifier, also known as process ID or PID, is a unique number to identify each process running in an operating system such as Linux, Windows, and Unix. PIDs are reused over time and can only identify a process during the lifetime of the process, so it does not identify processes that are no longer running. This number can be used as a framework for various function calls, meaning processes can be manipulated and adjusted.
PID는 short for Process identifier임. 즉, Unix, Linux, Windows와 같은 OS에서 실행되고 있는 각각의 프로세스에 대한 ID를 말함.
더이상 실행되고 있지 않은 process를 identify하지는 않고, 실행되고 있는 process만을 identify함.
IPC는 뭔데?
In computer science, inter-process communication or interprocess communication (IPC) refers specifically to the mechanisms an operating system provides to allow the processes to manage shared data. Typically, applications can use IPC, categorized as clients and servers, where the client requests data and the server responds to client requests.[1] Many applications are both clients and servers, as commonly seen in distributed computing.
IPC는 short for inter-process communication 이다.
우리가 수행하는 프로그램이 하나의 process만이 수행하는 것은 아니고, 상황에 따라 process끼리 협력을 해서 수행하는 케이스가 발생한다.
보통 이럴 경우에는 System Resource를 같이 사용함으로써 효율적으로 처리할 수 있음. 이런 과정들을 뭉뚱그려서 InterProcess Communication (IPC)라고 한다.
이 IPC의 모델은 크게 두가지가 있다.
- Message Passing 방식
- Shared Memory 방식
-> 생각많은 소심남 님의 블로그에서 더 자세히 알아보기
Reference
https://wangin9.tistory.com/entry/pythonthreadGIL
https://taes-k.github.io/2021/06/05/cpu-io-bound/
https://www.webopedia.com/definitions/pid/
https://talkingaboutme.tistory.com/entry/Process-Inter-Process-Communication-IPC
