시험 준비 과정에서 총 6개의 챕터를 중심으로 핵심 내용을 간단히 정리해보았다. 내용의 범위가 넓어 세부적인 코드나 수식까지 완벽히 이해하지는 못했지만, AI와 ML의 기본 개념과 흐름을 전반적으로 파악할 수 있는 의미 있는 시간이었다!
AI&기계학습 기초
① AI / ML / DL 정의
- AI (Artificial Intelligence, 인공지능): 인간의 지능을 기계로 구현하는 기술.
- ML (Machine Learning, 머신러닝): 데이터를 통해 기계가 스스로 학습하는 AI의 한 분야.
- DL (Deep Learning, 딥러닝): 인간의 뇌 구조를 본뜬 인공신경망을 사용하여 복잡한 패턴을 학습.
관계도: AI > ML > DL
② 데이터 구성 요소
- 입력 (Feature): 학습을 위해 필요한 정보 / 원인.
- 출력 (Label): 모델이 맞춰야 하는 결과 / 목표.
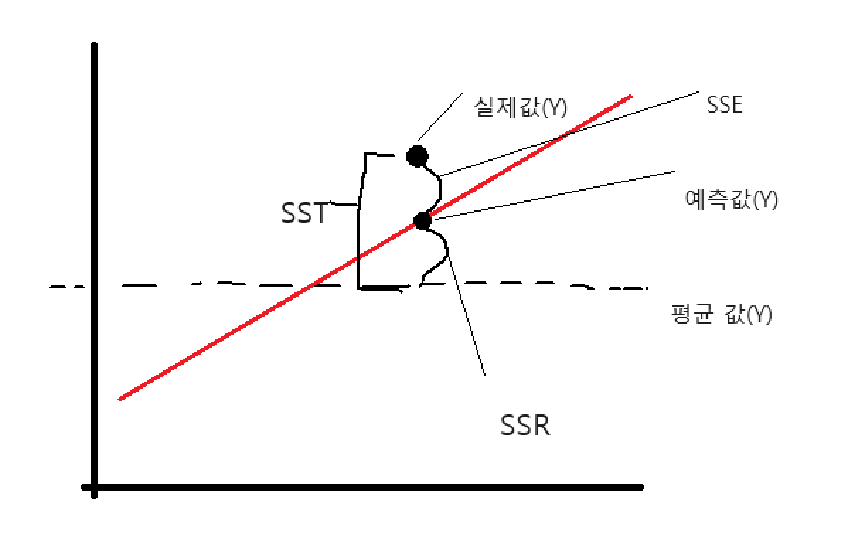
③ 결정계수 (, Coefficient of Determination)
- 정의: 회귀 모델의 설명력. (입력 data 바탕으로 연속적인 수치를 예측하는 학습 모델)
- 의미: 모델이 데이터를 얼마나 잘 설명하는지 나타내는 지표. Label의 분산 중에서 Feature로 설명되는 비율.
- 주의: (x) 단순 예측값 아님.
R² 수식 및 개념도
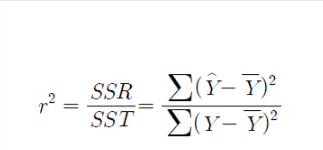
-
수식: 1에 가까울수록 설명력이 높음. ( : 모델 예측값)
-
비교 (vs): MSE (Mean Squared Error, 평균제곱오차)라는 정량 지표도 존재.
④ 혼동 행렬 (Confusion Matrix)
- 정의: 분류 모델 설명 (성능 평가). (입력 data 바탕으로 출력이 범주값으로 나타남. ex: 스팸 메일 여부)
- 메모: 모델의 신중함 정도를 평가.
혼동 행렬 및 분류 지표 수식
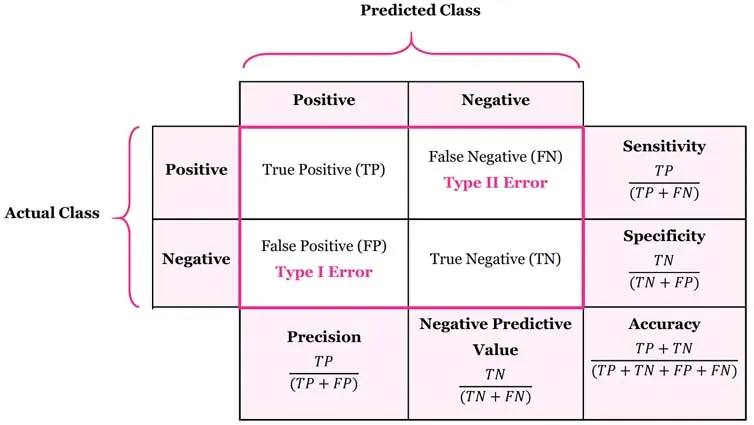
주요 지표 상세 (수식 이미지 참조)
- 정밀도 (Precision): 모델이 P라고 예측한 것 중 실제 P인 비율. (FP를 줄이는 것, 신중함)
- 재현율 (Recall/Sensitivity): 실제 P인 것 중 모델이 P라고 맞춘 비율. (FN을 줄이는 것, 포착력)
- F1-Score: 정밀도와 재현율의 조화 평균. 수식: (이미지 참조)
⑤ 회귀 (Regression)
- 정의: 입력 Features의 추세선을 그리는 것.
- 선형 회귀: 추세선을 찾아내는 가장 기본적인 머신러닝 모델.
- 평가 지표:
- MSE (Mean Squared Error): 모델의 설명력을 평가하는 지표.
- RSS (Residual Sum of Squares, 잔차 제곱합): MSE를 최소화하는 구체적인 계산 방식.
- 핵심 도구: 최소제곱법 (Method of Least Squares).
- 개념: Residual (잔차) = 실제값 - 예측값.
AI&기계학습 방법론
RSS와 신경망(Neural Network)의 기초
① RSS (Residual Sum of Squares, 잔차 제곱합)
- 정의: (실제 정답 - 모델이 예측한 값)의 제곱을 모두 더한 값.
- 특징: 데이터 개수가 많아질수록 당연히 커짐. 모델 자체의 성능보다는 오차의 전체 규모를 나타냄.
- MSE와의 관계: RSS를 데이터 개수(n)로 나누면 MSE(평균제곱오차)가 됨. (회귀 모델 성능 측정의 표준 지표)
② 신경망 (Neural Network)
"결국엔 데이터 학습과 처리!!"
수많은 인공 뉴런들이 연결되어 입력값에 대해 복잡한 연산을 수행하고 결과를 도출하는 통계적 학습 알고리즘.
- 핵심 3요소:
- 입력층 (Input Layer): 외부로부터 데이터를 받아들임. 데이터의 특징(Feature) 개수만큼 뉴런 존재.
- 은닉층 (Hidden Layer): 입력층과 출력층 사이에서 복잡한 계산이 이루어지는 곳.
- 출력층 (Output Layer): 최종 결과값을 내보내는 층.
- 장점: 복잡하고 비선형적인 데이터를 학습하는 데 매우 유리.
신경망이 학습하는 원리
- Weight (가중치): 중요도.
- Bias (편향): 뉴런이 얼마나 쉽게 활성화될지 조절하는 민감도.
- 활성함수 (Activation Function): 신경망에 비선형성을 추가하여 복잡한 패턴을 학습할 수 있게 함.
- ex) Sigmoid: 출력값을 0~1 사이로 제한 (로지스틱 회귀에서 사용).
- Network 구조:
- Shallow Network: 은닉층이 1개인 경우.
- Deep Network: 은닉층이 2개 이상인 경우 Deep Learning.
③ 경사하강법 (Gradient Descent)
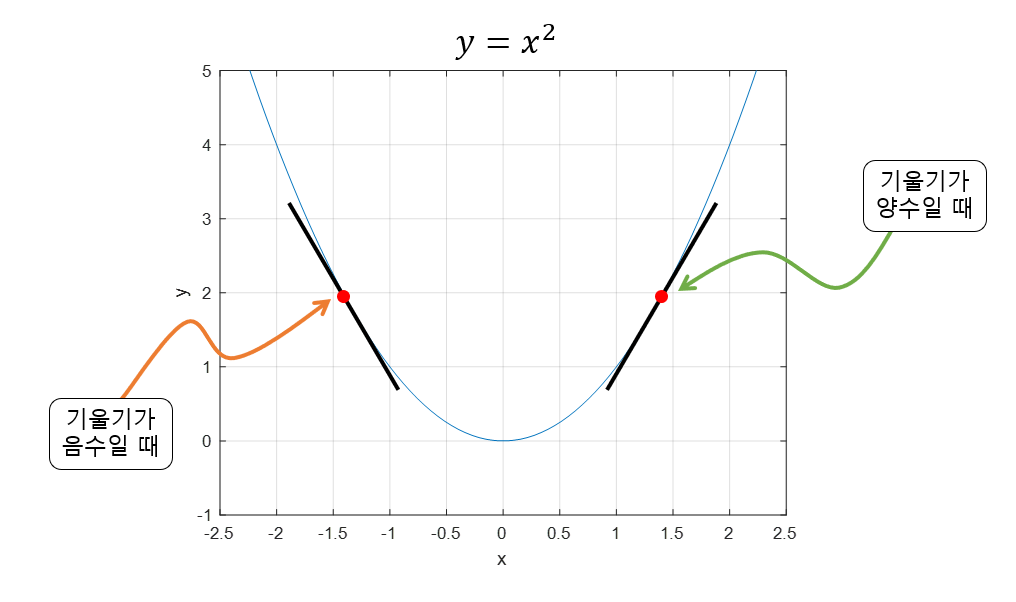
목적: 손실함수(Loss Function)의 값을 최소화하는 가중치(w) 찾기.
- 작동 원리: 전체 데이터를 확인하지 않고, 현재 위치에서의 함수의 기울기(경사)를 구함.
- 현재 위치에서 기울기 계산.
- 가중치 업데이트: 현재 기울기 방향의 반대로 이동!
- 반복: 오차가 더 이상 줄어들지 않을 때까지.
- Learning Rate (lr, 학습률): 한 번의 업데이트에서 이동할 보폭의 크기 결정.
- Epochs: 전체 데이터를 몇 번 반복해서 학습할지 결정.
④ 로지스틱 회귀 (Logistic Regression)
- 주의: 이름은 회귀지만 실제로는 분류(Classification) 기법! (이진 분류)
- 정의: 입력값이 두 범주 중 한 범주에 속할 확률을 예측.
- 핵심 도구: 시그모이드 함수 (Sigmoid Function)
⑤ 손실함수 (Loss Function)
- 정의: 모델의 예측이 틀린 정도를 숫자로 나타낸 함수.
- 학습의 목적: 손실함수값을 최소화하는 와 를 찾는 것.
- 종류:
- 회귀: MSE 사용.
- 분류: Cross-Entropy 사용.
- 이유: MSE는 애매하게 틀린 것을 너무 가볍게 처리함. 크로스 엔트로피는 작은 오차는 작게, 큰 오차는 매우 크게 반응하여 분류 성능을 높임.
자연어 처리 기본
자연어 처리(NLP) 기초 - RNN에서 Transformer까지
① RNN (Recurrent Neural Network, 순환 신경망)
"데이터의 순서가 중요한 시퀀스 데이터 처리에 특화된 모델"
- 원리: 입력 데이터를 한 번 보고 끝내는 것이 아니라, 은닉 상태(Hidden State)를 통해 이전 시점의 정보를 현재로 전달함.
- 핵심 공식: 현재 은닉 상태 = (이전 은닉 상태의 가중치 합) + (현재 입력 벡터의 가중치 합)
- 특징:
- 순서의 중요성: 순서 정보를 모델에 강력하게 전달 가능.
- 가변 길이 처리: 고정된 길이가 아닌 다양한 길이의 문장 처리 가능 (vs CNN은 고정 길이).
- 한계: 문장이 길어지면 앞쪽 정보가 사라지는 기울기 소실(Vanishing Gradient) 발생 장기 의존성 학습 불가.
② LSTM (Long Short-Term Memory)
- 목적: RNN의 장기 의존성 문제를 해결하기 위해 등장.
- 구조적 특징: 하나의 은닉 상태만 갖는 RNN과 달리, Cell State(셀 상태)라는 '컨베이어 벨트'를 추가함.
- Cell State: 긴 시퀀스 전반에 걸쳐 '장기적인 정보'를 잃지 않고 그대로 전달.
- Hidden State: 단기적인 정보를 다음 단계로 전달.
- 3개 게이트(Gate): 정보를 얼마나 남길지 결정 (0~1 사이 값).
- Forget Gate: 과거 정보 중 버릴 것을 결정.
- Input Gate: 현재 정보 중 새로 저장할 것을 결정.
- Output Gate: 어떤 정보를 밖으로 내보낼지 결정.
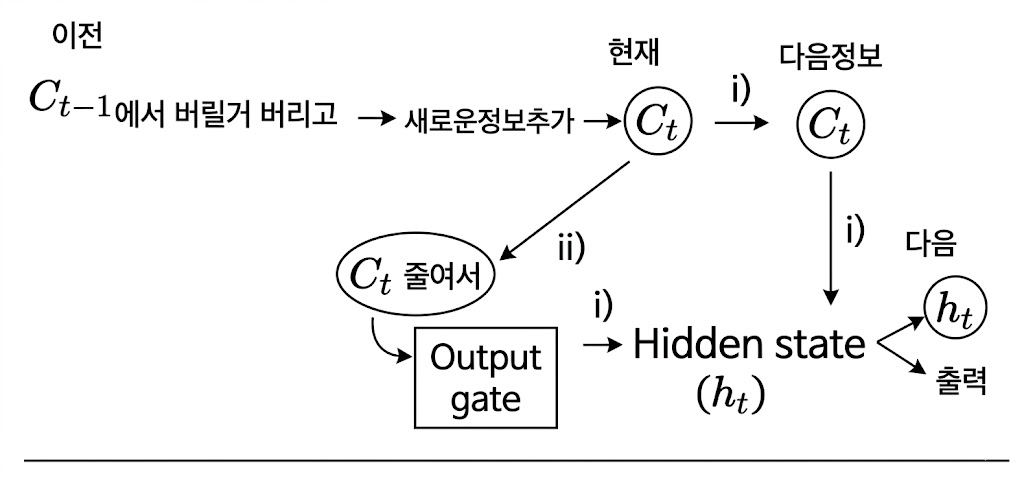
- 상단 흐름 (Cell State 업데이트): 이전 시점()의 정보에서 불필요한 것을 버리고(Forget), 새로운 정보(Input)를 추가하여 현재의 Cell State()를 만듭니다. 이 는 다음 시점으로 직접 전달되어 장기 기억을 보존합니다.
- 하단 흐름 (Hidden State 생성): 현재 Cell State()의 정보를 가공하여(줄여서) 최종적으로 Output Gate를 통과시킵니다. 이 결과가 현재 시점의 최종 출력물인 Hidden State()가 되며, 다음 시점으로 전달되는 동시에 해당 시점의 출력으로 사용됩니다.
③ Transformer (트랜스포머)
"RNN의 순차적 연산을 완전히 배제하고, 어텐션(Attention) 메커니즘만 사용"
- 배경: RNN은 1번부터 100번 단어까지 순서대로 학습해야 해서 병렬 처리가 불가능함.
- 핵심 원리 (Self-Attention):
- 문장 내 각 단어를 Query, Key, Value 벡터로 변환.
- Query와 Key의 내적을 통해 유사도(Attention Score)를 구함.
- 유사도가 높은 단어의 Value값에 가중치를 두어 정보를 취합.
- ex) "철수가 사과를 먹었다. 그는 행복했다." '그'는 '철수'라는 정보에 높은 유사도를 가짐. ('철수'라는 정보를 잔뜩 담은 그가 되는 것!!)
- 한계 극복 방법:
- 순서 정보 부재: Positional Encoding을 더해 단어의 위치 정보를 부여.
- 비선형성 부족: FFN(Feed-Forward Network) 추가.
- 구조: * Encoder: 양방향 문맥 파악 (입력 문장 이해).
- Decoder: 마스크드 어텐션(Masked Attention) 적용, 다음 단어 생성.
④ NLP 성능 평가 및 모델 비교
| 비교 항목 | BERT (인코더 기반) | GPT (디코더 기반) |
|---|---|---|
| 학습 방향 | 양방향 (문맥 전체 이해) | 단방향 (이전 단어로 다음 예측) |
| 핵심 능력 | 자연어 이해 (NLU) | 자연어 생성 (NLG) |
| 학습 방법 | 빈칸 채우기 (Masked LM) | 다음 단어 맞추기 |
- 평가 지표:
- BLEU: 번역 모델 평가 (정답과 얼마나 겹치는지).
- PPL (Perplexity): 모델이 다음 단어를 예측할 때 얼마나 헷갈려 하는지 (낮을수록 좋음).
- F1-Score : 질의 응답, 개체명 인식, 정밀도,재현률 모두 측정 (Q에 대한 A가 정확한지? 너무 구구절절하진 않은지?)
- GLUE: 모델의 종합적인 이해력 지표.
⑤ BERT (Bidirectional Encoder Representations from Transformers)
"인코더(Encoder) 구조만 사용! 양방향으로 문맥을 읽어내는 능력이 핵심"
- 핵심 원리: 양방향성
- 기존 모델들이 왼쪽에서 오른쪽으로 순차적으로 읽었다면, BERT는 문장 전체를 한꺼번에 보고 앞뒤 문맥을 동시에 파악함.
- 학습 방법 (Pre-training)
- MLM (Masked Language Model): 문장 내 단어 일부를
[MASK]로 가리고, 주변 단어들을 통해 가려진 단어가 무엇인지 맞추며 문맥을 이해함. - NSP (Next Sentence Prediction): 두 문장을 주어주고, 첫 번째 문장 다음에 두 번째 문장이 오는 것이 자연스러운지 예측함 (
IsNext/NotNext). 이를 통해 문장 간의 논리적 관계를 학습.
- MLM (Masked Language Model): 문장 내 단어 일부를
⑥ Downstream Task (하위 작업)
"사전 학습(Pre-train)을 마친 모델을 특정 목적에 맞춰 미세 조정(Fine-tuning)하여 수행하는 구체적인 작업"
- 문장 수준 (Sentence Level Tasks)
- 문장 분류: 뉴스 카테고리 분류, 감성 분석(긍정/부정 판단) 등 문장 전체의 의미를 파악하는 작업.
- 토큰 수준 (Token Level Tasks)
- 기계 독해 (QA): 질문에 대한 정답이 지문의 어느 위치(토큰 범위)에 있는지 찾아내는 작업 (예: SQuAD 데이터셋).
- 개체명 인식 (NER): 각 토큰(단어)이 인물, 장소, 조직 등 어떤 범주에 속하는지 분류하는 작업.
텍스트 파운데이션
텍스트 파운데이션(Text Foundation) - LLM 추론 및 학습 전략
1. LLM의 추론: 디코딩 알고리즘 (Decoding Algorithm)
"LLM이 이전 토큰들을 재료로 삼아 다음 토큰을 하나씩 예측하는 생성 방식(자기회귀 생성)에서 최종 단어를 선택하는 구체적인 방법"
① 결정적 방식 (Deterministic)
- Greedy Decoding: 매 시점 가장 확률이 높은 다음 토큰을 무조건 선택.
- Beam Search: 확률이 높은 K개의 후보를 동시에 고려하며 최적의 시퀀스를 탐색.
② 확률적 방식 (Probabilistic / Sampling)
- Sampling: 확률 분포에 따라 랜덤하게 토큰을 추출.
- Sampling w/ Temperature (T): 확률 분포의 날카로움을 조절.
- T가 높을수록: 창의적이고 다양한 답변 (확률 분포가 평평해짐).
- T가 낮을수록: 보수적이고 정형화된 답변 (높은 확률에 더 집중).
- Top-K Sampling: 확률 상위 K개의 후보 안에서만 선택.
- Top-p Sampling (Nucleus Sampling): 누적 확률 합이 p가 될 때까지의 후보군 내에서 선택.
2. LLM 평가 지표 (LLM Evaluation)
"모델이 언어라는 도구를 얼마나 잘 다루는지(NLP 평가)를 넘어, 인간의 복잡한 요구사항을 얼마나 잘 해결하는지 측정"
- 정답이 있는 경우 (Ground Truth 존재):
- MMLU: 지식 및 추론 능력을 측정하는 종합 벤치마크.
- 정답이 딱 떨어지지 않는 경우 (텍스트 품질/유사도):
- ROUGE: 정답과 생성된 텍스트 간의 단어 중복도 측정 (주로 요약 모델 평가).
- BERTScore: 단어 임베딩을 통해 문맥적 의미 유사도 측정.
- PPL (Perplexity): 모델이 다음 단어를 예측할 때 얼마나 헷갈려 하는지 측정 (낮을수록 우수).
- 인간 선호도 기반:
- LM Arena: 블라인드 테스트를 통한 상대적 선호도 랭킹 (가장 신뢰도 높음).
- AI가 평가하는 경우:
- G-Eval: LLM(예: GPT-4)을 평가자로 활용. (빠르지만 위치 편향, 길이 편향 등 존재 가능)
3. LLM 학습 전략: 선호 학습 및 RLHF
"단순한 지식 학습(SFT)을 넘어, 사람이 더 선호하는 응답을 생성하도록 정렬(Alignment)하는 과정"
- SFT (Supervised Fine-Tuning): 지시 학습. 실제 사람의 답변 데이터를 통해 직접 학습.
- 한계: 할루시네이션(환각)이나 유해한 응답이 발생할 수 있음.
- RLHF (Reinforcement Learning from Human Feedback) 3단계:
- SFT: 기초적인 지시 이행 학습.
- RM 학습 (Reward Model): 여러 답변 중 사람이 매긴 순위를 학습하여 '채점관 AI'를 만듦.
- PPO 알고리즘 (강화학습): 사람 개입 없이 모델이 답변하면 RM이 점수를 주고, 모델은 높은 점수를 받기 위해 스스로 답변 스타일을 수정함.
- 결과: 정렬 (Alignment) - 사용자의 의도와 가치관에 맞는 우수한 응답 생성 가능.
핵심
- 생성 시점에 Temperature를 어떻게 설정하느냐에 따라 서비스의 성격(창의적 vs 정확적)이 결정됨.
- 단순 정확도보다 인간의 선호도(Alignment)를 맞추는 것이 LLM 성능의 핵심임.
딥러닝 & 영상모델
5차시: 딥러닝 & 영상 모델 (CNN 기초)
① CNN (Convolutional Neural Network) 원리 이해
"이미지의 공간 구조를 유지하며 지역적 특징을 추출하는 모델"
- FCN(Fully Connected Layer)의 한계: 사진을 1차원으로 길게 늘어뜨려(Flatten) 입력하기 때문에 위치나 공간 정보가 깨짐.
- CNN의 해결책: 사진을 3차원(가로, 세로, 색상) 그대로 유지. 그 위에 필터(Filter/Kernel)를 올려두고 슬라이딩하며 지역적 특징을 추출.
- 핵심: 층이 깊어질수록 Receptive Field(수용 영역)가 넓어져 더 복잡한 특징을 파악 가능.
② CNN 연산 및 데이터 흐름
- Convolution (합성곱): 이미지 위에 필터를 슬라이딩하며 내적 연산을 수행하여 Feature Map 생성.
- ReLU: 활성화 함수를 통해 비선형성 부여.
- Pooling (풀링): 데이터의 크기(해상도)를 줄여 연산량을 절감하고 주요 특징을 추출. (불변성 유지)
- Max Pooling: 정해진 구역에서 가장 큰 값만 추출. (가장 많이 사용)
- Average Pooling: 평균값 추출. (계산 효율은 좋으나 세밀한 정보 손실 위험)
CNN 데이터 흐름도
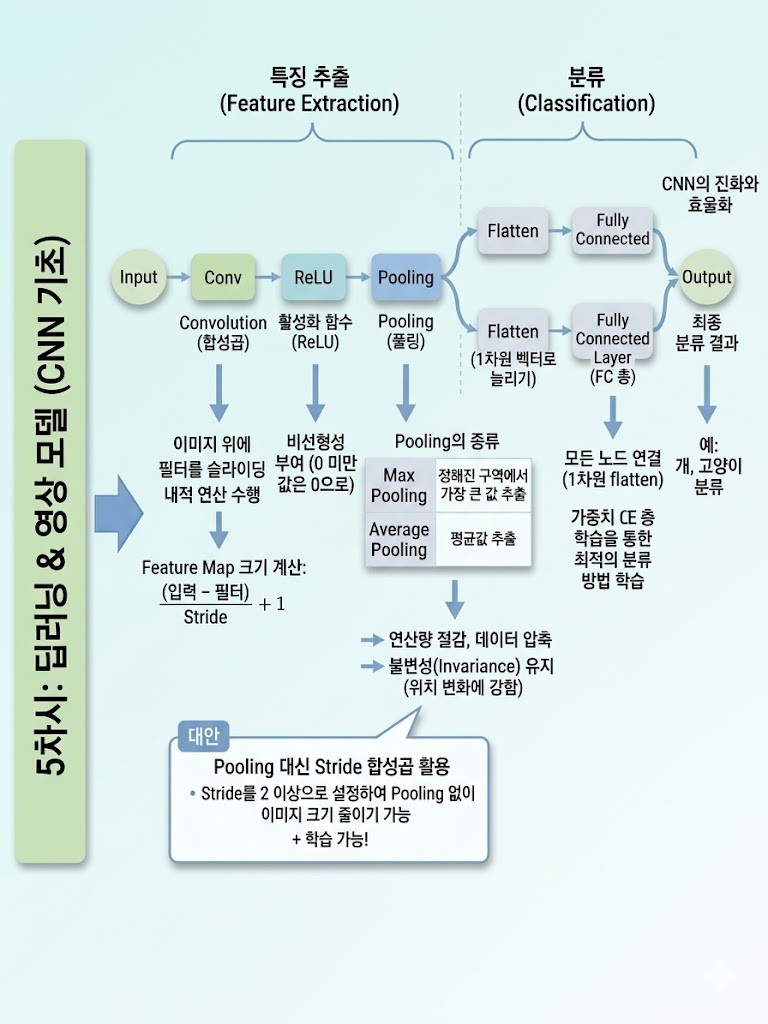
③ CNN의 진화와 효율화
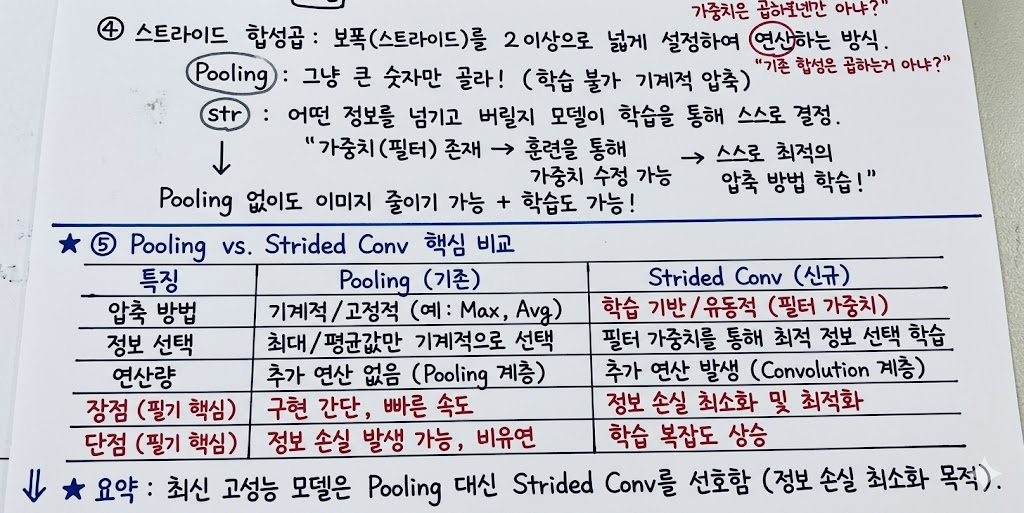
- Stride (스트라이드): 필터가 이동하는 보폭. 2 이상으로 설정하면 Pooling 없이도 이미지 크기를 줄일 수 있음.
- 학습 가능한 압축: Pooling은 단순히 큰 숫자만 고르지만, 스트라이드 합성곱은 가중치(필터)가 존재하므로 모델이 스스로 최적의 압축 방법을 학습함.
④ 출력 데이터 크기 계산 공식
- Feature Map 크기:
- 출력 채널 수: 사용한 필터의 개수와 동일.
이미지 파운데이션
멀티모달 & 이미지 생성 모델
1. VLM (Vision-Language Models)
"이미지와 텍스트 데이터를 모두 처리하고 이해할 수 있는 모델"
- 기본 구조:
- Vision Encoder: 이미지를 분석하여 특징(Feature) 추출.
- Linear Projection: 비전 엔코더가 뽑은 정보(이미지 특징)를 LLM이 이해할 수 있는 텍스트 임베딩 공간으로 변환.
- Text Decoder (LLM): 변환된 정보를 바탕으로 사고 및 추론 수행 (텍스트 생성).
- 의의: 이미지가 단순히 배경이 아니라, '알아들을 수 있는 언어(벡터)' 형태로 LLM에 입력되어 시각 정보를 바탕으로 한 고차원 추론이 가능해짐.
2. SIGLIP (Sigmoid Language-Image Pre-training)
"기존 CLIP의 성능과 효율성을 극적으로 개선한 최신 이미지-텍스트 페어링 기술"
- 배경: 기존 CLIP은 전체 대비 비율을 계산하는 Softmax 방식을 사용하여 대량의 이미지-텍스트 쌍을 한꺼번에 비교해야 했음 (연산량 과다).
- SIGLIP의 혁신: 각 이미지-텍스트 쌍을 독립적으로 처리하는 Sigmoid 함수를 이용.
- 장점:
- 학습 효율성 ↑: 더 적은 자원으로 더 많은 데이터를 학습 가능.
- 데이터 편향 제거: 개별 쌍으로 처리하므로 특정 데이터 그룹에 대한 편향 없이 대량 학습 가능.
- 의의: 최신 VLM 모델들이 우수한 시각-언어 정렬(Alignment) 능력을 갖추는 데 필수적인 기초 기술.
3. 이미지 생성 모델 (Image Generation Models)
"텍스트 설명(프롬프트)을 기반으로 고품질의 이미지나 영상을 생성하는 모델"
① 주요 모델 종류
- 폐쇄형 (Closed-source):
- DALL-E 3: 텍스트-이미지 정렬 능력 우수 (프롬프트 반영 우수).
- Sora: 고품질 영상 생성 모델.
- 오픈소스 (Open-source):
- Stable Diffusion: 현재 가장 널리 쓰이는 오픈소스 이미지 생성 모델.
- Flux: 최신 모델로, 텍스트나 글자 묘사 능력이 탁월함.
② 주요 응용 기술
- ControlNet: "포즈나 뼈대까지 내 맘대로!"
- 기존 Stable Diffusion에 조건부 제어 기능을 추가.
- 스케치, 뼈대, 선 정보를 입력받아 생성될 이미지의 자세, 모양 등을 정확하게 제어 가능.
- 텍스트로 설명하기 힘든 세밀한 제어(예: 특정 포즈)에 필수적.
- InstructPix2Pix: "말로 이미지 편집!"
- 사람이 직접 라벨링한 데이터가 아닌, 언어 모델과 이미지 생성 모델이 협업해서 만든 대량의 합성 데이터로 학습.
- 학습 방식: 사용자가 프롬프트로 편집 지시(예: "고양이가 모자를 쓰게 해줘")를 내리면, 원본 이미지에서 지시 내용에 맞게 이미지를 편집하여 출력.
③ 생성 AI의 핵심 메커니즘
- T2P (Text-to-Photo) 학습 시계:
[사전 1] + [프롬프트] = [사전 2](즉, 이전 상태와 프롬프트를 결합하여 다음 상태의 이미지를 예측하는 방식).
4. AI 파운데이션 모델과 생태계
① AI 파운데이션 모델 (AI Foundation Model)
- 정의: 인공지능의 기초가 되는 거대 모델.
- 전통적 모델 vs 파운데이션 모델:
- 전통적: 특정 작업을 위해 처음부터 끝까지 학습. (범용성 낮음)
- 파운데이션: 하나의 거대한 모델을 여러 용도로 미세 조정(Fine-tuning)하여 사용. (범용성 높음)
- 특징: 새로운 Task 해결을 위해 프롬프트 입력만으로도 충분한 능력을 보여줌 (In-context Learning).
- 구성 요소: ① 거대 데이터, ② 거대 학습 알고리즘, ③ 어텐션 기반 트랜스포머 구조.
② Hugging Face (허깅페이스)
- 정의: "AI계의 GitHub"
- 의의: 전 세계 AI 연구자와 개발자들이 다양한 파운데이션 모델과 데이터를 공유하고 협업하는 거대 플랫폼.
- 주요 서비스:
- Model Hub: 수만 개의 사전 학습된 AI 모델 공유.
- Datasets: 방대한 양의 학습 데이터셋 제공.
- Spaces: 자신이 만든 AI 모델을 웹상에서 바로 실행하고 공유할 수 있는 공간.
