NumPy와 Pandas
Numpy
1. Numpy 시작하기
NumPy 배열 생성 및 타입 확인
import numpy as np
# 리스트와 넘파이 배열 생성
arr1 = [1, 2, 3, 4] # 파이썬 리스트
arr2 = np.array([1, 3, 5, 7]) # NumPy 1차원 Array
print(type(arr1)) # <class 'list'>
print(type(arr2)) # <class 'numpy.ndarray'>배열의 상태 확인 (속성 정보)
data = np.array([[1, 2, 3], [4, 5, 6]])
print('차원 :', data.ndim) # 2차원
print('모양 :', data.shape) # (2, 3) -> 2행 3열
print('원소 개수 :', data.size) # 6개
print('데이터 타입 :', data.dtype) # int64 (정수형)NumPy의 ndarray와 파이썬의 list 속도 차이
import time # 시간 측정을 위한 라이브러리
# 엄청나게 큰 배열/리스트 만들기
# arange: numpy에서 제공하는 함수로, 지정한 범위 내의 값을 갖는 배열을 생성
large_list = list(range(1, 100000001))
large_np_array = np.arange(1, 100000001)
# Python 리스트로 계산
start_time = time.time()
result_list = [x * 2 for x in large_list]
end_time = time.time()
print(f'Python 리스트 계산 시간: {end_time - start_time:.5f}초')
# Python 리스트 계산 시간: 2.47560초
# NumPy 배열로 계산
start_time = time.time()
# NumPy 배열은 벡터화 연산을 지원하여, 배열 전체에 대해 한 번에 연산을 수행할 수 있음.
result_np_array = large_np_array * 2
end_time = time.time()
print(f'NumPy 배열 계산 시간: {end_time - start_time:.5f}초')
# NumPy 배열 계산 시간: 0.13900초- NumPy가 약 20배 가까이 빠른 것을 확인할 수 있다.
2. NumPy에서 행렬 표현
Norm : 벡터의 크기를 나타냄
import numpy as np
v = np.array([3, 4])
print(v)
print(np.linalg.norm(v))선형 변환의 이해
선형 변환은 "변환 행렬" 이라는 행렬을 곱해주면 된다.
선형 변환의 예시는 확대, 축소, 회전, 대칭 뒤집기 등이 있는데, 선형 변환 결과로 공간이 찌그러지거나 늘어나는데 원점은 유지된다는 특징이 있다.
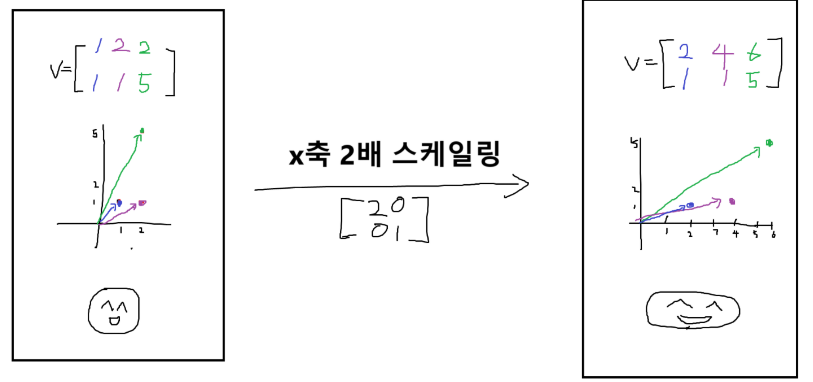
import numpy as np
v = np.array([[1, 2, 3], [1, 1, 5]])
S = np.array([[2, 0], [0, 1]]) #변환행렬
v_scaled = S @ v # 선형변환
print(v_scaled)-
변환 행렬은 스케일링도 있고, 회전도 있고, 대칭도 있다.
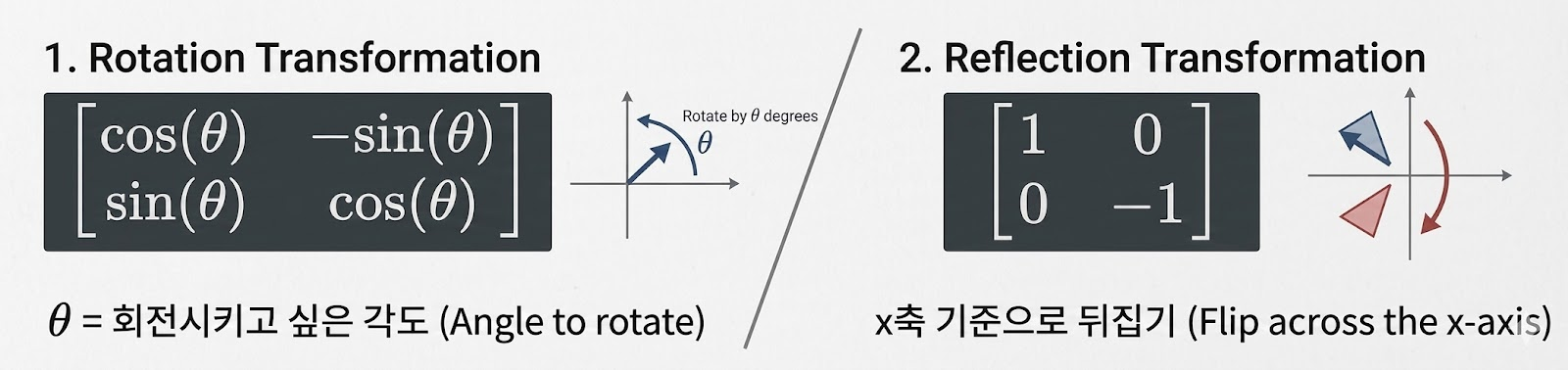
-
행렬 곱은 선형변환 할 때 뿐 아니라, 변환행렬끼리 합성할 때도 쓰인다.
import numpy as np
v = np.array([[1, 2, 3], [1, 1, 5]])
#변환행렬 1 : x축 방향 2배 스케일링
S = np.array([[2, 0],
[0, 1]])
#변환행렬 2 : 90도 반시계 방향 회전
R = np.array([[0, -1],
[1, 0]])
#변환행렬 합성
RS = R @ S
#합성된 변환행렬로 한방에 변환
v_scaled = RS @ v
print(v_scaled)결과
[[-1 -1 -5]
[ 2 4 6]]3. NumPy 배열 초기화하기
- numpy 배열은 기본적으로 float 타입이다
import numpy as np
A = np.zeros(5)
print(A)
# 결과 [0. 0. 0. 0. 0.]- 0으로 초기화된 행렬
import numpy as np
A = np.zeros((3, 5)) # 3행 5열
print(A)- 랜덤값
import numpy as np
print('랜덤 시드 값을 바꿔보면서 실행해보세요.')
np.random.seed(42)
A = np.random.rand(2, 3)
B = np.random.rand(5)
print(A)
print()
print(B)- 단위행렬 (
.eye(n))
import numpy as np
A = np.array([[1, 2, 3],
[4, 5, 6],
[7, 9, 9]])
B = np.eye(3)
print(B)
print()
print(A @ B)numpy로 수학 계산
import numpy as np
A = np.array([4, 16, 25])
print(np.sum(A)) # 전체 합
print(A ** 2) # 제곱
print(np.sqrt(A)) # 제곱근
print(np.log2(A)) # 로그 (밑수 = 2)
print(np.log(A)) # 로그 (밑수 = e, = 자연로그)
print(np.exp(A)) # 자연상수(e)의 지수함수
print()
print('삼각함수')
B = np.array([np.pi / 5, np.pi / 3]) # π/5 값과 π/3
print(np.sin(B)) # sin
print(np.cos(B)) # cos4. numpy array 다루는 코드 이해하기
기본 연산
- numpy array의 타입은 "ndarray" 라는 것을 기억하자
- numpy array 정보를 확인하는 속성 3가지 (size, ndim, shape)을 암기하자
import numpy as np
def show_info(A : np.ndarray):
print(A.size) # 원소의 수
print(A.ndim) # 2차원 벡터 데이터를 가진 행렬
print(A.shape) # 2 x 3 행렬
A = np.array([[1, 2, 3], [4, 5, 6]])
show_info(A)
ndim: 몇차원인지 !
[1,2,3]-> ndim = 1
[[1, 2], [3, 4]]-> ndim = 2
[[[1, 2], [3, 4]]]-> ndim = 3
triu (상삼각행렬추출)과 Transpose(전치연산)
import numpy as np
A = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13, 14, 15, 16]])
print(np.triu(A)) # 행렬에 삼각형 Upper 부분만 남기고, 나머지 다 0으로 만듭니다.
print()
B = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
print(B)
print()
C = B.T # Transpose
print(C)결과
[[ 1 2 3 4]
[ 0 6 7 8]
[ 0 0 11 12]
[ 0 0 0 16]]
[[1 2]
[3 4]
[5 6]
[7 8]]
[[1 3 5 7]
[2 4 6 8]]5. Pandas
Pandas는 파이썬에서 표 형태의 데이터를 다루기 위한 가장 강력하고 대중적인 라이브러리이다.
- Series : Column 하나
- DataFrame : 여러 개의 시리즈가 모인 표 전체
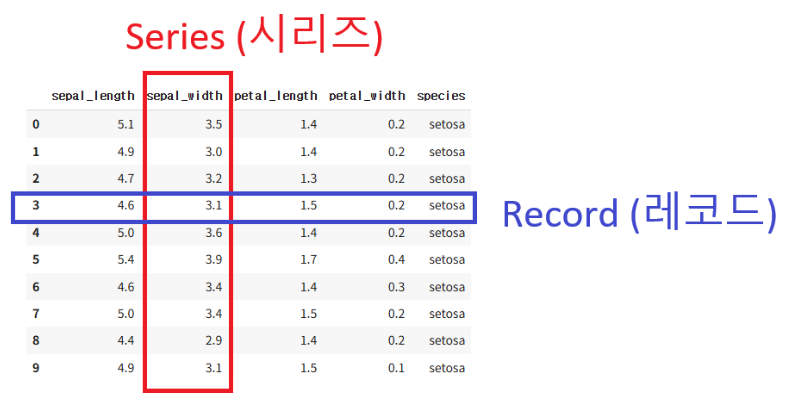
Pandas 사용 이유
-
다양한 데이터 타입: 숫자뿐만 아니라 문자열(이름), 날짜, 불리언(True/False) 등을 한 표에 담을 수 있다.
-
데이터 읽기/쓰기: 엑셀(.xlsx), CSV, SQL 데이터베이스 등 거의 모든 형태의 파일을 한 줄로 불러온다.
-
비어있는 데이터(결측치) 처리: 데이터가 빠져 있는 부분(NaN)을 찾아내거나 채우는 기능이 매우 강력하다.
코드 예시 - 표 만들기
import pandas as pd
# 1. 데이터 준비
data = {
'이름': ['지민', '정국', '뷔'],
'나이': [28, 26, 28],
'역할': ['보컬', '보컬', '보컬']
}
# 2. 데이터프레임(표) 생성
df = pd.DataFrame(data)
print(df)결과
| | 이름 | 나이 | 역할 |
|---|---|---|---|
| 0 | 지민 | 28 | 보컬 |
| 1 | 정국 | 26 | 보컬 |
| 2 | 뷔 | 28 | 보컬 |열 선택
# 열 선택
import pandas as pd
data = {'이름': ['철수', '영희', '민조', '지아', '서준'],
'학년': [2, 3, 1, 3, 2],
'과목': ['수학', '영어', '수학', '영어', '과학'],
'점수': [85, 92, 78, 88, 95]}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd', 'e'])
print(df, '\n')
# '이름' 열만 선택
names = df['이름']
print(names, '\n')
# '이름'과 '점수' 열 선택
info = df[['이름', '점수']]
print(info)행 선택
# 행 선택
data = {'이름': ['철수', '영희', '민조', '지아', '서준'],
'학년': [2, 3, 1, 3, 2],
'과목': ['수학', '영어', '수학', '영어', '과학'],
'점수': [85, 92, 78, 88, 95]}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd', 'e'])
# 인덱스 이름이 'b'인 행 선택
print(df.loc['b'], '\n')
# 인덱스 이름이 'a'부터 'c'까지인 행들 선택 (c 포함!)
print(df.loc['a':'c'], '\n')
# 0번째 위치의 행 선택 (첫 번째 행)
print(df.iloc[0], '\n')
# 0번째부터 3번째 이전까지 (0, 1, 2) 위치의 행들 선택 (3 미포함!)
print(df.iloc[0:3], '\n')Boolean Indexing 필터링
# Boolean Indexing 필터링
data = {'이름': ['철수', '영희', '민조', '지아', '서준'],
'학년': [2, 3, 1, 3, 2],
'과목': ['수학', '영어', '수학', '영어', '과학'],
'점수': [85, 92, 78, 88, 95]}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd', 'e'])
# '점수'가 90점 이상인 행 필터링
filt = df['점수'] >= 90
df_high_score = df[filt]
print(df_high_score)
# 또는 한 줄로: df_high_score = df[df['점수'] >= 90]특수 조건 필터링
# 특수 조건 필터링
import pandas as pd
import numpy as np
data = {'이름': ['철수', '영희', '민조', '지아', '서준'],
'학년': [2, 3, 1, 3, 2],
'과목': ['수학', '영어', '수학', '영어', '과학'],
'점수': [85, 92, 78, 88, 95]}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd', 'e'])
# '서준'의 '과목'과 '점수'를 NaN으로 설정
df.loc['e', '과목'] = np.nan
df.loc['e', '점수'] = np.nan
# '학년'이 2학년 또는 3학년인 행 필터링
target_grades = [2, 3]
filt_isin = df['학년'].isin(target_grades)
print(df[filt_isin], '\n')
# '과목'이 NaN인 행 필터링
filt_isnull = df['과목'].isnull()
df_is_null = df[filt_isnull]
print(df_is_null, '\n')
# '점수'가 NaN이 아닌 행 필터링
filt_notnull = df['점수'].notnull()
df_not_null = df[filt_notnull]
print(df_not_null)데이터 전처리 및 변환
데이터의 신뢰도를 떨어뜨리고, 모델의 학습을 방해하는 "결측치"를 처리
import pandas as pd
import numpy as np
data = {'A': [1, 2, np.nan, 4, 5],
'B': [6, np.nan, 8, np.nan, 10],
'C': [11, 12, 13, 14, 15],
'D': [np.nan, np.nan, np.nan, np.nan, np.nan]}
df = pd.DataFrame(data)
print(df, '\n')
# 결측치(NaN)가 하나라도 있는 행을 제거
df_dropped_rows = df.dropna()
print(df_dropped_rows, '\n')
# 결측치(NaN)가 하나라도 있는 열을 제거
df_dropped_cols = df.dropna(axis=1)
print(df_dropped_cols, '\n') # 출력 안됨
# 모든 값이 결측치인 행을 제거
df_dropped_all_rows = df.dropna(how='all')
print(df_dropped_all_rows, '\n')결과
# 1
A B C D
0 1.0 6.0 11 NaN
1 2.0 NaN 12 NaN
2 NaN 8.0 13 NaN
3 4.0 NaN 14 NaN
4 5.0 10.0 15 NaN
# 2
Empty DataFrame
Columns: [A, B, C, D]
Index: []
# 3
C
0 11
1 12
2 13
3 14
4 15
# 4
A B C D
0 1.0 6.0 11 NaN
1 2.0 NaN 12 NaN
2 NaN 8.0 13 NaN
3 4.0 NaN 14 NaN
4 5.0 10.0 15 NaN 결론
NumPy는 복잡한 수치 계산을 위한 '빠른 계산기'이고, Pandas는 대량의 데이터를 효율적으로 관리하고 분석하는 '스마트한 엑셀' 이라고 정리할 수 있다.
- Numpy : 다차원 배열 (숫자 데이터)를 다룸
- 강점 : 압도적인 연산 속도와 수학 기능
- Pandas : 표, 시계열 데이터를 다룸
- 강점 : 데이터 필터링, 정렬, 그룹화
