02-1) 0과 1로 숫자를 표현하는 방법
정보 단위
-
컴퓨터는 0 또는 1밖에 이해하지 못하는데, 0과 1을 나타내는 가장 작은 정보 단위를 비트라고 한다.
- 1비트로는 정보 2개, 2비트로는 정보 4개, 3비트로는 정보 8개 표현 가능
- n비트로는 2^n 개
-
단위 체계
| 1 byte | 8 bit |
|---|---|
| 1 kB | 1,000 byte |
| 1 MB | 1,000 kB |
| 1 GB | 1,000 MB |
| 1 TB | 1,000 GB |
- 추가적으로 정보 단위 중 워드 라는 단위가 있는데, 워드란 CPU가 한 번에 처리할 수 있는 데이터 크기를 의미한다.
- half word, full word, double word 등 ..
이진법
- 0과 1만으로 숫자를 표현하는 방법
- 10이 이진수인지 십진수인지 구분 ? 이진수 앞에
0b를 붙임 (0b1000)
- 10이 이진수인지 십진수인지 구분 ? 이진수 앞에
이진수의 음수 표현
- 2의 보수 를 구해 이를 음수로 간주
- 2의 보수 : 어떤 수를 그보다 큰 2^n에서 뺀 값 (사전적 의미)
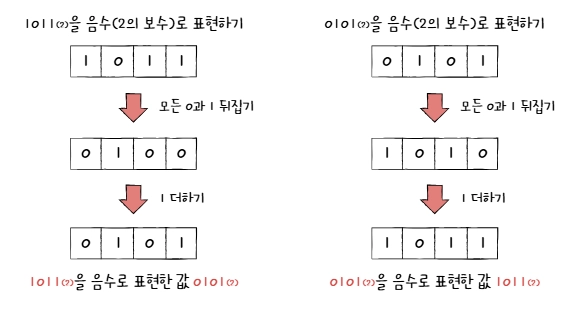
0b11의 2의 보수 =0b100에서0b11을 뺀 값 =0b01 - 쉽게 구하는 방법
- 모든 0과 1을 뒤집고, 거기에 1 더하기
- 모든 0과 1을 뒤집고, 거기에 1 더하기
- 2의 보수 : 어떤 수를 그보다 큰 2^n에서 뺀 값 (사전적 의미)
Q) 음수로서의
0b0101과 십진수 5를 표현하기 위한0b0101을 어떻게 구분합니까?
A) 컴퓨터 내부에서는 어떤 수가 음수인지 양수인지 구분하기 위해 Flag를 사용한다.
십육진법
- 이진수로 표현하면 숫자의 길이가 너무 길어진다는 단점을 보완하기 위해 데이터를 표현할 때 십육진법도 자주 사용한다. → 십육진법 : 수가 15를 넘어가는 시점에 자리 올림을 하는 숫자 표현 방식
- 십육진수 구별법 :
0x붙이기

십육진수를 이진수로 변환하기
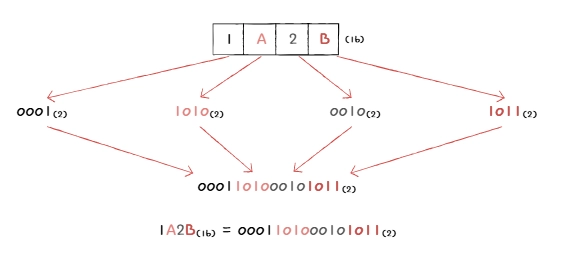
- 십육진수를 이루고 있는 각 글자를 따로따로 (4개의 숫자로 구성된) 이진수로 변환하고, 그것들을 이어붙인다
이진수를 십육진수로 변환하기
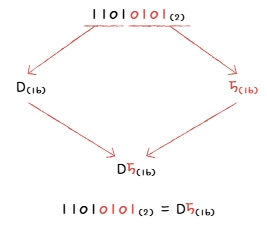
- 십육진수 변환법과 반대 (네글자씩 끊어서 십육진수로 변환)
02-2) 0과 1로 문자를 표현하는 방법
문자 집합과 인코딩
- 문자 집합 : 컴퓨터가 인식하고 표현할 수 있는 문자의 모음
- 문자 인코딩 : 문자 집합에 속한 문자를 컴퓨터가 이해할 수 있는 0과 1로 변환하는 과정
- 문자 디코딩 : 0과 1로 이루어진 문자 코드를 사람이 이해할 수 있는 문자로 변환하는 과정
[문자집합 1] 아스키 코드
- 아스키 문자들은 각각 7트로 표현되고, 128(=2^7)개의 문자를 표현할 수 있다.
ex) `A` = 십진수 65 = `0b1000001`로 인코딩된다.
- **코드 포인트** : 문자 인코딩에서 ‘글자에 부여된 고유한 값’
- 아스키 문자 A의 코드 포인트 = 65하지만, 아스키 코드는 한글, 특수문자 등 아스키 문자 집합 외의 문자를 표현할 수 없다는 단점이 있는데 .. 그래서 등장한 한글 인코딩 방식이 EUC-KR 이다
EUC-KR
- 한글의 특수성 : 알파벳을 쭉 이어 쓰면 단어가 되는 영어와 달리 한글은 각 음절 하나하나가 초성,중성,종성의 조합으로 이루어짐
- 한글 인코딩의 두 가지 방식
- 완성형 인코딩 : 초성,중성,종상의 조합으로 이루어진 완성된 하나의 글자에 고유한 코드 부여
- EUC-KR은 완성형 인코딩 방식 !! (한글 단어에 2바이트 크기의 코드 부여)
- 조합형 인코딩 : 초성을 위한 비트열, 중성을 위한 비트열, 종성을 위한 비트열을 할당하여 그것의 조합으로 하나의 글자 코드 완성
- 완성형 인코딩 : 초성,중성,종상의 조합으로 이루어진 완성된 하나의 글자에 고유한 코드 부여
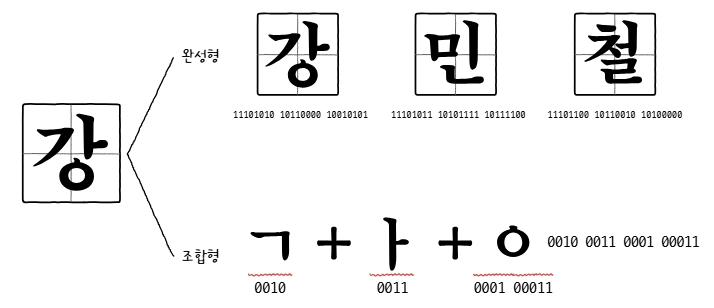
- 한글 인코딩 방식 중 마이크로소프트의 CP949 (EUC-KR의 확장된 버전) 도 존재. 모든 한글을 표현할 수 있는 것은 아니지만 더욱 다양한 문자 표현 가능
유니코드와 UTF-8
언어별로 인코딩을 나라마다 해야 한다면, 다국어를 지원하는 프로그램을 만들 때 각 나라 언어의 인코딩을 모두 알아야 하는 번거로움이 있다.
⇒ 만약 모든 나라 언어의 문자 집합과 인코딩 방식이 통일되어 있다면 언어별로 인코딩하는 수고로움을 덜 수 있지 않을까?
유니코드
- 현대 문자를 표현할 때 가장 많이 사용되는 표준 문자 집합.
- EUC-KR보다 훨씬 다양한 한글을 포함하며, 대부분 나라의 문자, 특수문자, 심지어 이모티콘까지 코드로 표현 가능.
- UTF-8, UTF-16, UTF-32
- 유니코드 : 글자에 부여된 값 자체를 인코딩 값으로 삼지 않고, 이 값을 다양한 방법으로 인코딩하는데, UTF-8, UTF-16, UTF-32 는 유니코드 문자에 부여된 값을 인코딩하는 방식이다.
