머신러닝이란
정의
- 데이터를 기반으로 최적의 모델을 계산하여 완성합니다.
- 이를 활용해 새로운 데이터를 예측하거나 분류할 수 있게 하는 방법입니다.
모델이란?
- 모델은 수식이다.
- 모델은 입력 데이터와 출력 데이터 관계를 수식으로 표현한 함수!
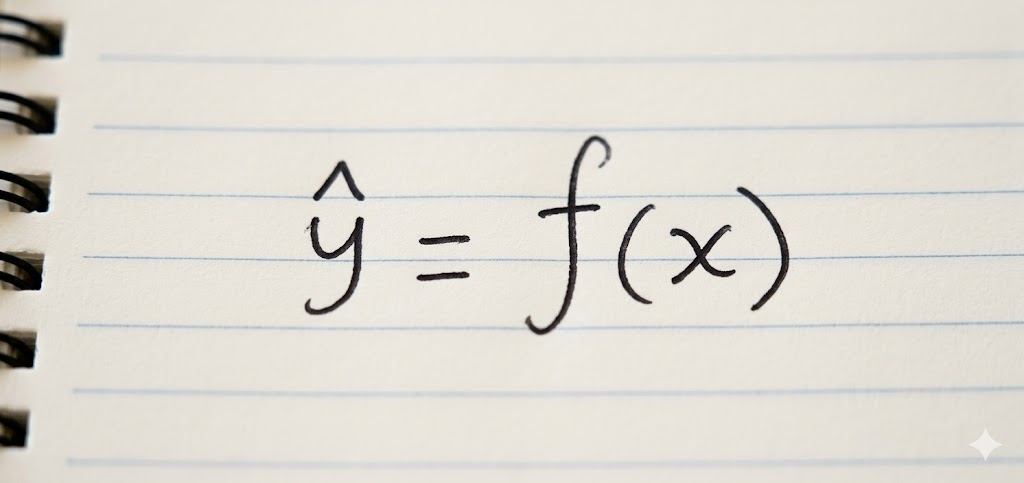
- x : 입력값
- f : 모델
- y hat : 모델 예측 결과값
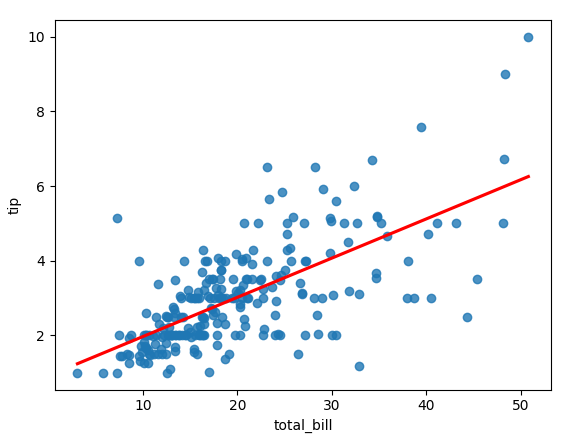
- 위의 그래프를 아래처럼 간단한 코드로 구현할 수 있다.
import seaborn as sns
import matplotlib.pyplot as plt
# 예시 데이터 : 팁스
tips = sns.load_dataset("tips")
# 모델 에시 (선형 회귀 모델)
# reg plot은 추세선을 그려주는 기능을 가지고 있습니다.
sns.regplot(x="total_bill", y="tip", data=tips, ci=None, line_kws={"color": "red"})
print()seaborn : 파이썬의 대표적인 데이터 시각화 라이브러리
-
특히 데이터 간의 관계나 통계적 분포를 보여줄 때 빛을 발함.
- 회귀 그래프 (regplot): 데이터의 경향성을 보여주는 직선을 함께 그려줌.
- 히트맵 (heatmap): 데이터의 밀도나 상관계수를 색상으로 표현함. (보통 격자 모양)
- 카테고리별 분포 (boxplot, violinplot): 그룹별로 데이터가 어떻게 퍼져있는지 보여줌.
- 관계 그래프 (pairplot): 여러 변수 간의 상관관계를 한꺼번에 표처럼 보여줌.
Matplotlib이 도화지와 붓이라면, Seaborn은 이미 완성된 멋진 템플릿 세트와 같다
AI & 기계학습 방법론1 - 선형 회귀
선형 회귀 이해하기
- 선형 회귀는 '추세선'을 찾아내는 머신러닝 모델
- 선형 회귀 모델 : feature의 추세선 or 추세면
- ex. 사람이 대상이면 '키,나이,몸무게' 등의 값이 feature
=
- : 추세선을 만드는 규칙(함수)
- : 그 규칙으로 계산해본 예측값
"데이터의 흐름을 직선(추세선)으로 표현했더니, 그 직선이 곧 미래를 예측하는 공식(선형회귀모델)이 되었다."는 의미!
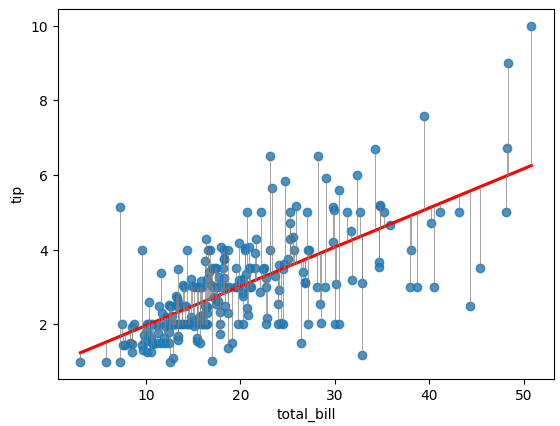
- 각 점별로 오차의 합이 최소가 되는 직선을 찾으면, 최고의 추세선이라고 볼 수 있음
# 2중 for문으로 Grid Search
for a in a_values:
for b in b_values:
#예측하기
y_hat = a * X + b # 직선 방정식으로 y 예측 값들 한꺼번에 계산
error = np.sum(np.abs(y - y_hat)) # Error 계산 = 오차의 합
if error < min_error:
min_error = error
best_a, best_b = a, b- 2중 for문으로 최소 오차의 합을 구하는 방법을 Grid Search라고 하는데, 실무에서 잘 사용하지 않는다
MAE (Mean Absolute Error)
- 오차의 합은 데이터의 양이 많아지면 값이 커진다는 점에서 한계가 있다.
- 반면, 오차의 평균은 데이터가 많던 적던, 예측 모델과 실제 값들의 차이를 수치로 잘 설명할 수 있다.
# error = np.sum(np.abs(y - y_hat)) # Error = 오차의 합
error = np.mean(np.abs(y - y_hat)) # Error = 오차의 평균 <--- 이 부분이 달라졌어요!- 만든 모델이 실제 값과 얼만큼 차이가 있는지를 더 잘 표현할 수 있다.
MSE (Mean Square Error)
- 가장 많이 사용하는 방법!
- 오차가 크게 발생하면, 아주 큰 에러가 발생했다!!고 강조하기 위해서 MSE 방법을 이용할 수 있다.
- 오차에 제곱을 하는 방법
error = np.mean(np.abs(y - y_hat) ** 2) - 회귀선 찾는 코드
# 우리가 찾은 회귀선 (빨간색)
x_line = np.linspace(0, 50, 100)
y_line = best_a * x_line + best_b우리가 회귀 분석을 할 때, 모델이 얼마나 틀렸는지 계산하는 도구가 MSE(평균제곱오차)이고, 그 MSE 값을 가장 작게 만드는(최소화하는) 구체적인 계산 방식이 바로 최소제곱법이다.
- Least Squares(최소제곱법) : 잔차제곱합(RSS)를 최소화하는 계수를 찾는 방법으로, 데이터와 회귀선 간의 차이를 최소화하는 원리
- Residual(잔차)=실제값 - 예측값. 모델이 설명하지 못한 부분으로, 모델 적합도를 판단하는 지표
단순선형회귀와 다중선형회귀
- 단순선형회귀 : TV 광고 -> 매출 한 가지 관계만 고려
- 다중 선형 회귀 : TV광고, Radio 광고비, 가격, 계절 등 복수 요인을 함께 고려하여 매출 설명
정규 방정식
- 선형 회귀에서 비용 함수인 MSE를 최소화하는 최적의 파라미터를 찾기 위한 공식. 복잡한 반복계산 없이 행렬 연산 한 번으로 정답을 바로 구할 수 있음.
import numpy as np
import seaborn as sns
# 데이터 불러오기
tips = sns.load_dataset("tips")
X = tips["total_bill"].values.reshape(-1,1) # 세로로 긴 행렬 (n,1) 형태로 변경
Y = tips["tip"].values.reshape(-1,1) # 세로로 긴 행렬인 (n,1) 형태로 변경
# X 행렬에 앞에 [1] 추가
X_b = np.c_[np.ones((X.shape[0], 1)), X] # [[1, x1], [1, x2], [1, x3]....]
# 정규방정식 계산: [b, a] = (X^T·X)^(-1)·X^T·Y
b, a = np.linalg.inv(X_b.T @ X_b) @ (X_b.T) @ (Y)
print("절편 b:", b)
print("기울기 a:", a)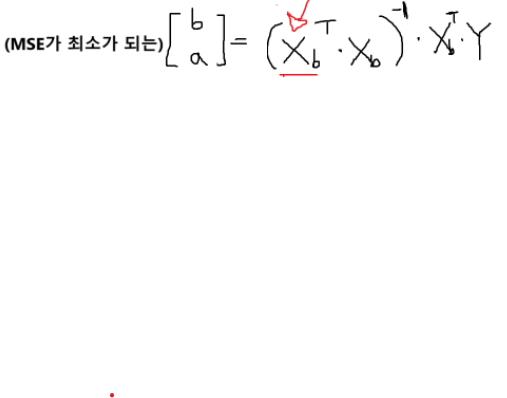
B.T 로 전치행렬을 구하고, np.linalg.inv(A) 로 역행렬을 구할 수 있다.

- 하지만, 정규방정식에는 역행렬이 들어가는데, 이 역행렬은 계산하는데 되게 느리고 때로는 구할 수 없을 때도 있다.
따라서 정규방정식의 대안으로 Gradient Descent 방법을 사용한다
경사 하강법 Gradiend Descent (GD)
목적 : 전체 데이터를 확인하지 않고, 최소한의 데이터만 살펴보는 방법으로 a=7일 때 최솟값인 것을 찾기!
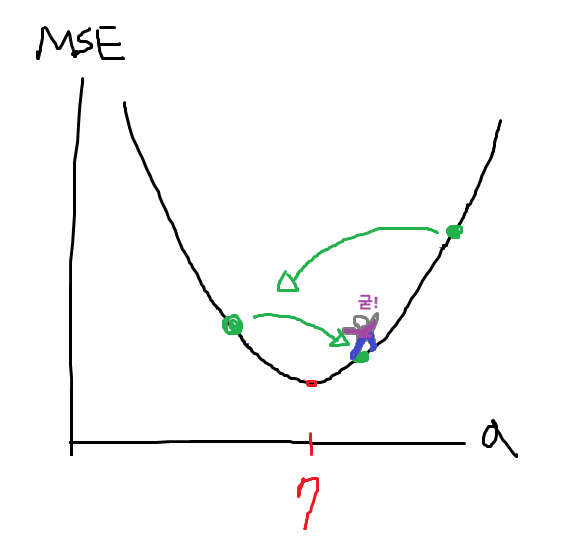
- 곡선의 의미 : 손실함수
- 데이터 준비 및 초기화
- 처음에는 아무런 정보가 없기 때문에 무작위로 선을 하나 긋고 시작
X = tips["total_bill"].values # 입력값 (원인)
y = tips["tip"].values # 결과값 (예측 목표)
# 기울기(a)와 절편(b)을 아무 숫자나(랜덤) 넣고 시작합니다.
a = np.random.randn()
b = np.random.randn()- 하이퍼파라미터 설정
lr: Learning Rate (학습률) - 한 번에 얼마나 크게 움직일지 결정하는 '보폭'epochs: 이 과정을 몇 번 반복할지
- 핵심 로직 (학습) - Gradient Descent
for epoch in range(epochs):
y_hat = a * X + b # 1. 현재 가진 a, b로 예측값을 만듦
error = y_hat - y # 2. 실제 정답과 얼마나 차이나는지 오차 계산
# 3. 오차를 줄이기 위해 어느 방향으로 가야 할지(기울기) 계산
grad_a = np.mean(error * X)
grad_b = np.mean(error)
# 4. 계산된 방향으로 조금씩 업데이트 (점프!)
a -= lr * grad_a
b -= lr * grad_b1)grad_b = np.mean(error) : 절편의 수정 방향
- 절편 b는 그래프를 위아래로 움직이는 역할
- 오차가
+: 예측이 높으니 b를 낮춰야 함
- 오차가
2) grad_a = np.mean(error * X) : 기울기의 수정 방향
- 기울기 a는 선의 각도를 조절한다.
- X 값이 큰 데이터에서 발생한 오차는 기울기에 더 큰 영향을 주기 때문에 X를 곱함.
- X가 양수일 때 오차가
+라면 기울기를 낮춰야함
3) Grad ?
- gradient = 경사 -> 이 값이 0에 가까워진다는 것은 더 이상 수정할 필요가 없는 최적의 지점에 도달한다는 뜻.
더 똑똑한 GD => 아담
- 위의 GD에서는 lr만큼 무지성 점프를 했는데, 이는 좋은 a,b를 못찾을 수 있는 문제를 발생시키기도 한다. 이를 Local Maximum에 갇혔다고 표현한다.
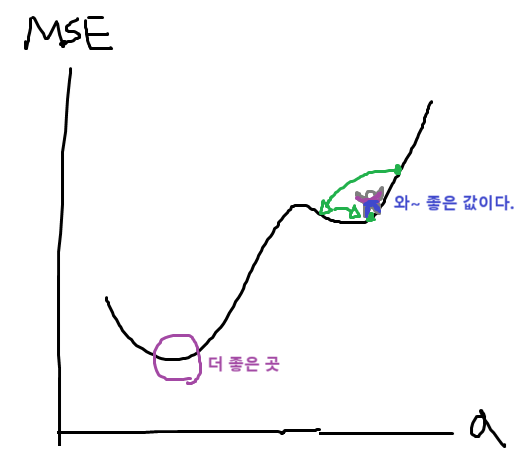
아담 아이디어 (Adam Optimizer)
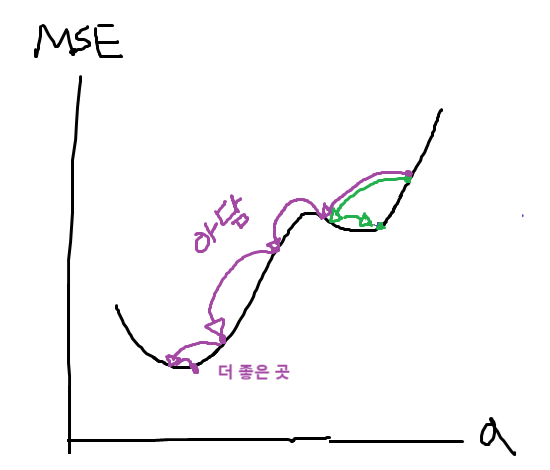
선형 회귀(Linear Regression) 정리
- 선형 회귀 모델 : 추세선 수식을 만드는 것
- 수식이 만들어지면 새로운 값에 대해 예측할 수 있고, 이를 머신러닝이라고 한다.
로지스틱 회귀 (Logistic Regression)
- 회귀 : 수를 예측한다는 뜻.
- 로지스틱 회귀는 실제로는 분류 기법으로, 입력 값이 두 범주 중 한 범주에 속할 확률을 예측하는 기법이다.
이진분류 문제의 예시
- 키워드를 넣으면, 스팸 메일인지 아닌지 확률을 알려주는 모델
- 공부시간을 넣으면, 합격인지 아닌지 확률을 알려주는 모델
예시
<주어진 데이터>
공부 시간에 따른 시험 합격 여부
-
2시간 공부 한 A 학생 : 불합격
-
3시간 공부 한 B 한색 : 불합격
-
4시간 공부 한 C 학생 : 합격
-
3시간 공부 한 D 학생 : 불합격
-
5시간 공부 한 E 학생 : 합격
-
1시간 공부 한 F 학생 : 불합격
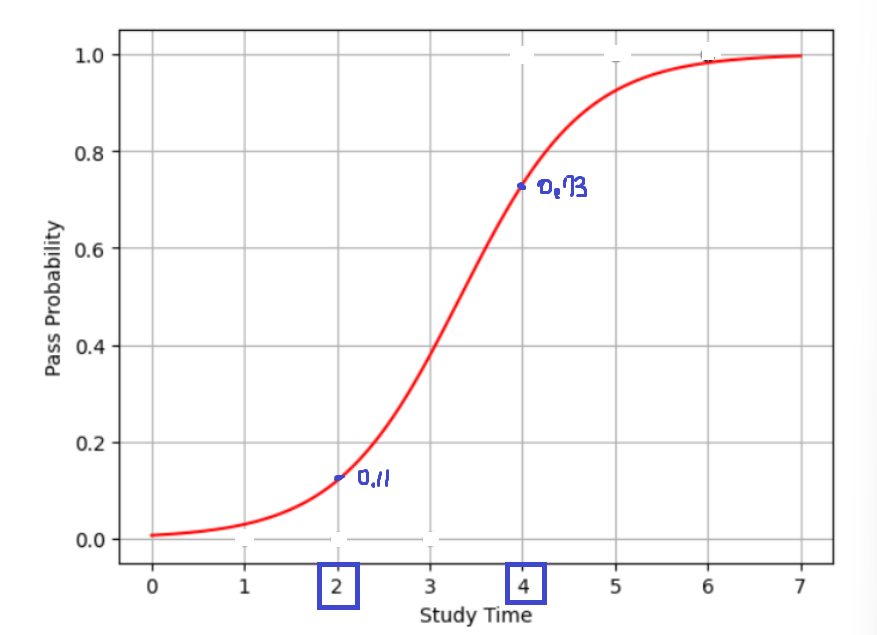
-
2시간 공부한 학생의 합격 확률 : 11%
- 모델이 완성도면 공부 시간에 따라 합격과 불합격 확률을 구할 수 있으며, 이를 이진 분류 모델이라고 한다.
로지스틱 회귀 수식
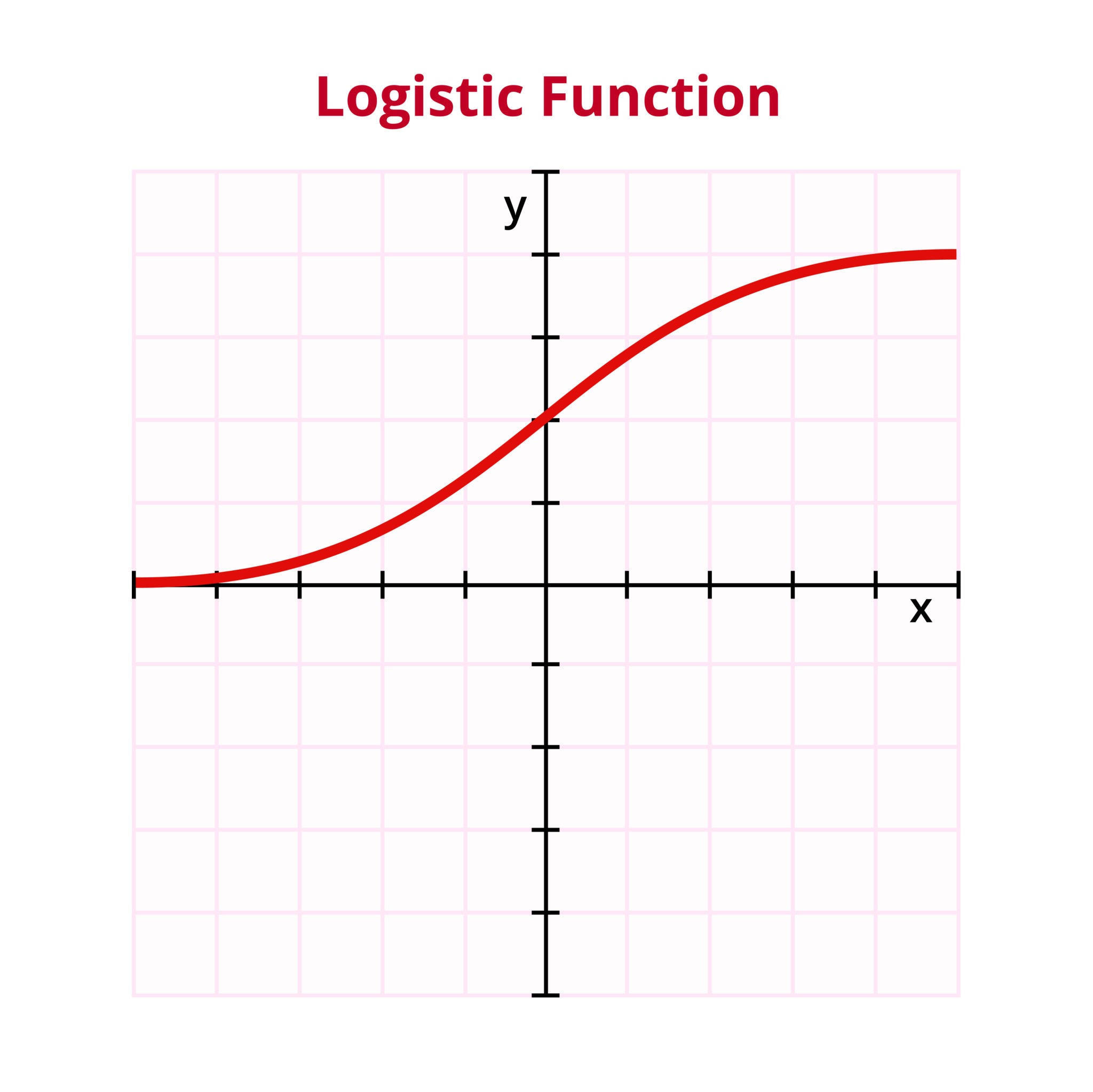
- 시그모이드(Sigmoid) 함수라고 한다.
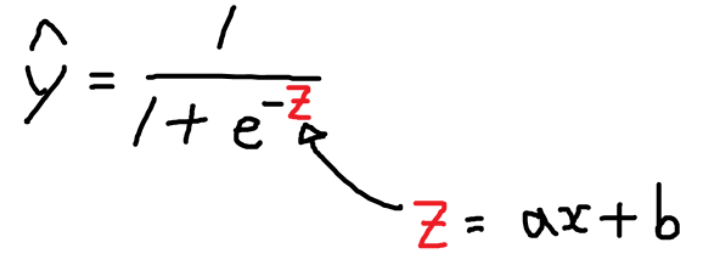
import numpy as np
import matplotlib.pyplot as plt
# 시그모이드 함수 정의
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 학습 완료된 파라미터 결과 (a, b)
a = 1.5
b = -5
# 모델을 이쁘게 그려보기 위한 X 값
X = np.linspace(0, 7, 200)
# 모델 예측 값
y_hat = sigmoid(a * X + b) # z = ax + b
plt.plot(X, y_hat, color="red")
plt.xlabel("Study Time")
plt.ylabel("Pass Probability")
plt.grid(True)
print()-
sigmoid(z)함수: S자 곡선의 마법
-
학습을 통해 알아야 하는 값 = a b
- 선형 회귀문제는 y = ax + b 에서 a, b를 알아내서 추세선을 만들어 내는 문제.
- 로지스틱 회귀문제는 y = sigmoid(ax + b) 에서 a, b 를 알아내서 확률 곡선을 만들어 내는 문제
로지스틱 회귀 문제에 Grid Search 적용하기
- 데이터 준비 (Input & Target)
import numpy as np
import matplotlib.pyplot as plt
# X: 원인 (공부 시간), y: 결과 (0은 불합격, 1은 합격)
X = np.array([1,2,3,4,5,6,2,3,4,5,6,7,1,2,3,4,5,6,7,8,2,3,4,5,6,7,8,9,10])
y = np.array([0,0,0,1,1,1,0,0,1,1,1,1,0,0,0,1,1,1,1,1,0,0,1,1,1,1,1,1,1])- 모델의 핵심 함수 정의
# 시그모이드 함수: 어떤 숫자든 0~1 사이의 '확률'로 바꿔줌
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 로스 함수 (MSE): 실제 정답(y)과 모델의 예측값(y_hat)이 얼마나 다른지 계산
def get_loss(y, y_hat):
return np.sum((y - y_hat)**2)sigmoid(z): 선형 방정식()의 결과값을 0(절대 불합격)과 1(무조건 합격) 사이의 값으로 변환get_loss: 모델이 틀린 정도를 측정. 이 값이 0에 가까울수록 정확한 모델임
- 탐색 범위 설정 (Grid Search 준비)
# a(기울기)는 0~3 사이를 100등분, b(절편)는 -10~10 사이를 100등분해서 준비
a_values = np.linspace(0, 3, 100)
b_values = np.linspace(-10, 10, 100)
best_a, best_b = None, None # 최적의 값을 저장할 변수
min_loss = float("inf") # 최소 오차를 찾기 위해 아주 큰 값으로 초기화- 미리 정해둔 범위 안의 모든 조합을 다 써봄
- 최석의 a, b 찾기 (반복문)
for a in a_values: # 100번 반복
for b in b_values: # 100번 반복 (총 10,000번 실행)
# 1. 현재 a, b 조합으로 예측값(확률) 계산
y_hat = sigmoid(a * X + b)
# 2. 이 조합이 얼마나 틀렸는지(loss) 계산
loss = get_loss(y, y_hat)
# 3. 지금까지 본 것 중 가장 오차가 적다면? "최고의 조합"으로 저장!
if loss < min_loss:
min_loss = loss
best_a, best_b = a, by_hat = sigmoid(a * X + b): 로지스틱 회귀의 핵심!!- 컴퓨터가 1만 번의 S자 곡선을 그리고, 데이터의 점들과 가장 잘 어울리는 곡선을 골라냄
크로스 엔트로피 적용하기
- Loss Function : Error을 구하는 공식
- Loss Function으로 우리가 찾은 방법이 MSE였고, MSE값이 최소가 되는 a,b를 찾는 것이 목표였다.
- MSE : 애매하게 틀린 걸 너무 가볍게 처리하는 것이 문제
- 정답 = 1일 때 MSE로 보면
- 0.9 → 오차: 0.1 → 제곱: 0.01
- 0.6 → 오차: 0.4 → 제곱: 0.16
- 실제로 두 값은 더 크게 차이나야 정상임!
- 정답 = 1일 때 MSE로 보면
- 작은 오차는 작게, 큰 오차는 아주 크게 확대를 해주는 '크로스 엔트로피'라는 Loss Function을 사용!!
- 로지스틱회귀 처럼 분류 문제에서는 Loss Function으로 크로스엔트로피를 가장 많이 사용함.
결론
- 선형 회귀 : '얼마나?' 를 묻는 질문
- "공부 시간이 늘어날수록 시험 점수는 몇 점이 될까?"라는 질문에 대한 답을 찾는 모델
- 데이터들 사이를 관통하는 가장 적절한 '직선'을 찾는 과정으로,우리가 궁금한 결과값이 '연속적인 숫자'일 때 사용함.
- 로지스틱 회귀 : "맞을까?"를 묻는 질문
- "공부 시간이 8시간일 때 합격할 확률이 얼마인가?"라는 질문에 대한 답을 찾는 모델
- 이름은 '회귀'지만 실제로는 '분류(Classification)'를 하기 위해 만들어졌습니다. 우리가 궁금한 결과값이 '예/아니오', '합격/불합격'처럼 '이분법적인 범주'일 때 사용
