0519_Kubernetes_Runtime Command : crictl / DaemonSet / Jobs, CronJob / Service, Endpoint / Kubelet as a Service, Static Pod (노드 추가 필요)
Kubernetes

k8s의 기본 컨테이너 런타임
컨테이너 런타임 : 컨테이너를 어떻게 설치(실행)할 것인가
위치 : ~/kubespray/inventory/mycluster/group_vars/k8s_cluster
$ grep containerd k8s-cluster.yml
## docker for docker, crio for cri-o and containerd for containerd. ➜ 3가지 중 선택 가능
## Default: containerd
container_manager: containerd ✔️ # Docker 설치되어있지 x ➜ containerd로만 제어k8s는 기본적으로 Containerd와 Cri-o 2가지만 지원
요즘은 Docker도 Containerd 라이브러리를 사용하기 때문에 k8s가 Doker를 지원하지 않아도 문제 x
$ systemctl status containerd
...
/usr/local/bin/containerd-shim-`runc`-v2
... /usr/local/bin/containerd-shim-runc-v2 ➜ container 생성 담당
k8s 기본 런타임 명령어 : crictl
Docker 명령어처럼 활용 가능
관리자 권한 필요 (sudo -i)
# crictl [ps, images, pull httpd, rmi docker.io/library/httpd, exec -it 컨테이너 ID bash ...] ⚠️ 필독!
이 메세지 아래에서 진행되는 실습은 node1 (controll plane)만 제대로 생성되어있고,
node2 (worker node)가 제대로 생성되지 않은 상태로 진행하였기 때문에
worker node까지 제대로 생성하고 난 후라면 아래 표기 된 정보보다 더 정확한 정보 확인 가능
DaemonSet (데몬셋, DS)
모든 노드 가 파드의 사본(template)을 실행하도록 함
클러스터 전체 에 파드를 띄울 떄 사용하는 컨트롤러
🌟 무조건 한 노드에 1개 씩 ➜ 분산 보장
➜ 노드가 늘어나면 그 노드에 파드 배치 / 노드가 줄어들면 해당 노드에서 제거
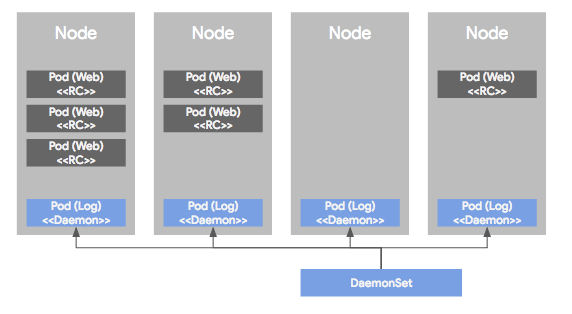
🎈 Replicaset과 Daemonset의 차이
RS은 노드가 여러 개 있어도 파드를 각 노드에 1개씩 자동으로 배치할 수 x
➜ sched로 파드를 어디에 배치하면 좋을지 파악하여 가장 최선의 배치 진행
(각 노드마다 파드를 고르게 분산해야하는 의무 x)
➜ sched를 조정해서 원하는대로 배치할 수는 있지만, RS 자체에서 할 수는 x
ex. RS가 파드 3개로 설정되어있고 노드도 3개로 되어있을 때
RS는 노드 3개 중 1개를 잃으면 다른 노드에 파드를 새로 생성시켜 갯수 맞춤
DS는 복제본이 x ➜ 노드가 클러스터에서 제거되면 해당 노드에 있던 파드는 가비지(garbage)로 수집
➕가비지 컬렉터 ➜ 메모리 누수 방지
메모리 누수 : 메모리 할당하고 해제하지 않아 계속해서 메모리가 쌓이는 것
데몬셋의 주 용도 : Agent
데몬셋은 노드에서 실행되는 어플리케이션 보조 / 인프라 유지, 보수, 관리하기 위한 어플리케이션 관리
- 모든 노드에서 클러스터 스토리지 데몬 실행
- 모든 노드에서 로그 수집 데몬 실행
- 모든 노드에서 노드 모니터링 데몬 실행 (프로메테우스)
➜ Workload는 기본적으로 스토리지(디스크) 파드 보유
k8s가 연결할 수 있는 컨테이너 스토리지 인터페이스 (CSI) 를 통해 접근
➜ Rook, Ceph 사용
스토리지를 관리할 애플리케이션 필요 ➜ 데몬셋이 관리
kube-proxy는 클러스터 내 모든 노드에 설치되어있어야하므로 ds로 관리 (dns, calico도 마찬가지)
$ kubectl get ds -n kube-system
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
calico-node 1 1 1 1 1 kubernetes.io/os=linux 42h
kube-proxy✔️ 1 1 1 1 1 kubernetes.io/os=linux 42h
nodelocaldns 1 1 1 1 1 kubernetes.io/os=linux 42hDS spec 확인
$ kubectl explain ds.spec.selector
$ kubectl explain ds.spec.template➜ ds.spec에는 Replicasets라는 필드가 없음 ➜ 복제본이 아님 을 의미
🎈 DaemonSet 실습
myweb-ds
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: myweb-ds
spec:
selector:
matchExpressions:
- key: app
operator: In
values:
- myweb
- key: env
operator: Exists
template:
metadata:
labels:
app: myweb
env: dev
spec:
containers:
- name: myweb
image: ghcr.io/c1t1d0s7/go-myweb
ports:
- containerPort: 8080
protocol: TCP💡 yaml 파일에서의 label 선언 및 일치
➜ pod에 사용하는 spec.template.metadata의 label과
metadata 필드에 사용하는 label은 관습적으로 일치시켜주는 편 (필수 x)
➜ Selector의 matchlavels와 spec.template.metadata의 labels는 맞춰줘야 함
DS 생성
$ kubectl create -f myweb-ds.yamlNode 개수와 DS 개수의 관계
Worker Node or Control Plane
터미널 1
DS 수 추가 / 감소하는 것 실시간 확인
$ watch kubectl get ds터미널 2
$ ansible-playbook -i inventory/mycluster/inventory.ini remove-node.yml -b --extra-vars="node=node3" --extra-vars reset_nodes=true노드 추가
https://kubespray.io/#/
➜ 추가할 노드를 인벤토리에 미리 명시 해놓아야 함
$ ansible-playbook -i inventory/mycluster/inventory.ini scale.yml -b📌 현재 제거할 worker node가 존재하지 않으므로
해당 실습은 node2, node2 제대로 생성 완료 후 다시 진행해서 필기할 예정
Jobs
Daemon과는 다르게 시작과 끝 이 있는 애플리케이션 관리 (Batch 작업)
파드가 성공적으로 종료될 때가지 계속해서 파드 실행 재시도
➜ 어플리케이션이 종료되어야 파드가 종료 됨
- Stateful : RC / RS / DS / Deployment / Statefulset
Statefuless: Jobs / CronJobs
대량의 데이터를 다루는 작업이나 시간이 오래 걸리는 작업을 주로 다룸
➜ 학습은 시작이 있고 종료가 있음 (MLOps-Kubeflow에 많이 사용)
🎈 배치(batch)
$ kubectl api-resources | grep batch
cronjobs cj batch/v1 true CronJob
jobs batch/v1 true JobJob spec 확인
$ kubectl explain jobs.spec
$ kubectl explain jobs.spec.template🎈 Job 실습
mypi.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: mypi
spec:
template:
spec:
containers:
- image: perl
name: mypi
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy : OnFailure ✔️perl : python과 같은 스크립트 language
pod.spec.containers.command == job.spec.template.spec.containers.command ➜ Entrypoint 대체
perl 이미지 정보 확인
$ sudo -i
# crictl pull perl🌟 재시작 정책(restartPolicy) 을 선언하지 않았을 때
우리가 원하는 것 : 연산이 끝나면 어플리케이션이 끝이 나는 것
but 파드의 재시작 정책은 기본이 always ➜ 오류 발생
$ kubectl create -f mypi.yaml
The Job "mypi" is invalid: spec.template.spec.restartPolicy: Required value: valid values: "OnFailure", "Never"Job 생성
$ kubectl create -f mypi.yaml생성 확인
$ watch kubectl get job,po kube-node1: Thu May 19 01:56:56 2022
NAME COMPLETIONS DURATION AGE
job.batch/mypi 0/1 41s 42s ✔️
NAME READY STATUS RESTARTS AGE
pod/mypi--1-wzrp8 0/1 ContainerCreating 0 41s ✔️
pod/myweb-ds-ldpmj 1/1 Running 0 40m
pod/myweb-rc-cfvnv 1/1 Running 1 (150m ago) 14h
pod/myweb-rc-kv795 1/1 Running 1 (150m ago) 14h
⬇️
NAME COMPLETIONS DURATION AGE
job.batch/mypi 1/1 2m50s 3m57s ✔️
NAME READY STATUS RESTARTS AGE
pod/mypi--1-wzrp8 0/1 Completed 0 3m56s ✔️
pod/myweb-ds-ldpmj 1/1 Running 0 44m
pod/myweb-rc-cfvnv 1/1 Running 1 (154m ago) 14h
pod/myweb-rc-kv795 1/1 Running 1 (154m ago) 14hJob의 로그 확인
$ kubectl logs mypi--1-wzrp8 # 연산Job 컨트롤러의 Label
$ kubectl get job,po -o wide --show-labels# job
NAME COMPLETIONS DURATION AGE CONTAINERS IMAGES SELECTOR LABELS
job.batch/mypi 1/1 2m50s 41m mypi perl controller-uid=5c2156e5-f2aa-4c71-9517-d89bf50de0a4 controller-uid=5c2156e5-f2aa-4c71-9517-d89bf50de0a4,job-name=mypi
# pod
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
pod/mypi--1-wzrp8 0/1 Completed 0 41m 10.233.90.52 node1 <none> <none> controller-uid=5c2156e5-f2aa-4c71-9517-d89bf50de0a4,job-name=mypiyaml 파일에서 Pod template 의 label / Job 컨트롤러의 label selector 지정 x
➜ 잘못 된 매핑으로 기존의 파드를 종료하지 않게 하기 위함
Job / Cron Job은 시작을 하면 끝이 나는 것을 보장하기 때문에 (stateful)
Selector를 사용하게 되면 Job 컨트롤러가 동일한 label을 가진 Stateless 파드를
잘못 매핑하여 다른 어플리케이션을 죽이려고 할 가능성 존재
Job 컨트롤러에 의해 실행 완료된 파드의 종료
Job이 끝났는데 파드 계속 남아있음
해당 파드의 로그는 삭제되지 않고 etcd에 저장
➜ etcd DB is getting full
사용자에게 삭제 선택권 부여
➜ 완료한 Job에 대한 로그가 필요 없으면 반드시 삭제하기
외부에 로그 서버 필수
➜ 로그를 외부 서버에 따로 저장하면 Job을 삭제해도 아무 문제 x
$ kubectl get job,poNAME COMPLETIONS DURATION AGE
job.batch/mypi 1/1 2m50s 41m
NAME READY STATUS RESTARTS AGE
pod/mypi--1-wzrp8 0/1 Completed 0 41m ✔️Job 컨트롤러의 필드
Job 컨트롤러의 spec의 필드 확인
$ kubectl explain job.spec🎈 Job spec 필드
- activeDeadlineSeconds
Job 컨트롤러에서 생성한 파드가 너무 오래 실행되는 것을 방지 ➜ 특정 시간에 종료시킬 수 있음
(필요시 사용 ➜ 작업이 끝나는 것이 중요하면 지정 x)
- backoffLimit
Job과 Cron Job 빼고는 back-off이 필드가 설정 x
(다른 오브젝트들은 계속적으로 재시작해야하기 때문)
Default : 6번
- ttlSecondsAfterFinished 🌟
파드가 종료 되고 [지정시간] 후에 종료 및 삭제
단위 : 초 (second)
mypi-tsaf.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: mypi
spec:
template:
spec:
containers:
- image: perl
name: mypi
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy : OnFailure
ttlSecondsAfterFinished: 10 ✔️➜ 파드가 종료 되고 10초 후에 종료 및 삭제
- completions
작업 완료 횟수
해당 과정을 몇 번의 실행➜완료 이후 끝낼 것인가
mypi-comp.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: mypi
spec:
completions: 3 ✔️
template:
spec:
containers:
- image: perl
name: mypi
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy : OnFailure ➜ 해당 과정을 3번 실행하고 완료되어야 끝남
Job 생성
$ kubectl create -f mypi-comp.yaml진행 확인
$ kubectl get po --watch NAME READY STATUS RESTARTS AGE
mypi--1-mnxlj 0/1 ContainerCreating 0 9s
mypi--1-mnxlj 1/1 Running 0 11s
mypi--1-mnxlj 0/1 Completed 0 18s
mypi--1-87xps 0/1 Pending 0 0s
mypi--1-87xps 0/1 Pending 0 0s
mypi--1-87xps 0/1 ContainerCreating 0 0s
mypi--1-mnxlj 0/1 Completed 0 23s
mypi--1-87xps 0/1 ContainerCreating 0 8s
mypi--1-87xps 1/1 Running 0 16s
mypi--1-87xps 0/1 Completed 0 28s
...생성 및 실행 완료 확인
$ watch kubectl get job,po kube-node1: Thu May 19 02:55:40 2022
NAME COMPLETIONS DURATION AGE
job.batch/mypi 3/3 87s 3m36s
NAME READY STATUS RESTARTS AGE
pod/mypi--1-87xps 0/1 Completed 0 3m18s
pod/mypi--1-dk9jz 0/1 Completed 0 2m50s
pod/mypi--1-mnxlj 0/1 Completed 0 3m36s- parallelism
병렬처리 개수
한 번에 더 많은 데이터를 처리할 수 있음
➜ 어플리케이션 자체가 병렬처리로 구현이 가능하도록 구현이 되어있어야 가능
mypi-para.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: mypi
spec:
completions: 3
parallelism: 3 # 이 파트 수정
template:
spec:
containers:
- image: perl
name: mypi
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy : OnFailureJob 및 생성 Job Pod 확인
$ watch kubectl get job,po 💡 completion 횟수
≥parallelism 횟수
- suspend
일시 중지
$ kubectl edit job mypivi 편집기 로 suspend 부분을 true 로 바꿔주면 일시중지 가능
➕ vi 에디터를 강제종료 하면 파일
이름 앞에 . 뒤에 .swap이 붙은 파일을 볼 수 있을 것
어떻게 할 것인지 정해주면 됨 (삭제, 수정 ...)
CronJob
ex. 택배 위치 확인 사이트에서 확인하는 정보와 실제 택배의 위치가 다른 이유
➜ 택배 회사가 택배 위치정보를 배치 작업을 통하여 동기화 시키기 때문
Cronjob의 API 버전 확인
$ kubectl explain cj --api-version=batch/v1beta1--api-version : api 버전까지 확인 가능
CronJob의 spec 필드 확인
$ kubectl explain cj.spec
$ kubectl explain cj.spec.jobTemplate
$ kubectl explain cj.spec.suspend
$ kubectl explain cj.spec.schedule 🌟🎈 CronJob 실습
mypi-cj.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: mypi-cj
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: mypi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: OnFailure터미널 1
CronJob 생성
$ kubectl create -f mypi-cj.yaml터미널 2
모니터링
$ watch -n1 -d kubectl get cj,po kube-node1: Thu May 19 05:34:18 2022
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob.batch/mypi-cj * * * * * False 1 19s 4m2s
NAME READY STATUS RESTARTS AGE
pod/mypi-cj-27548971--1-xd8zl 0/1 Completed 0 3m19s
pod/mypi-cj-27548972--1-4q4kw 0/1 Completed 0 2m13s
pod/mypi-cj-27548973--1-5rx4q 0/1 Completed 0 78s
pod/mypi-cj-27548974--1-shmk9 1/1 Running 0 18s-n[n초]: n초마다 업데이트 확인
-d : 업데이트 시 변경사항 확인
🎈 CronJob spec 필드
-
successfulJobsHistoryLimit
히스토리제한
➜ 파드 갯수 무한정 증가 x
➜ Default : 3개
CronJob은 기본적으로 4개의 job만 가짐
(현재 실행되고 있는 것까지 합쳐서 4개)
Running 되는 파드가 여러 개면 확인(get) 시 보여지는 pod는 4개 이상일 수 있음
제일 오래 된 job은 삭제 됨
-
concurrencyPolicy
어플리케이션동시 작업허용 여부
(어플리케이션의 data 성질에 따라 충돌 발생할 수도 있음)
➜ Default : allow
♢ Allow : 허용
♢ Forbid : 금지 ➜ 실행 중인 작업이 끝나야 다음 작업 실행 (그 전까지는 실행 안되고 대기)
♢ Replace : 변경 ➜ job 실행 중 replace 할 작업이 생성되는 경우, 실행 중이었던 Job 파드를 죽이고 replace 할 파드 실행
sleep-cj.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: sleep-cj
spec:
schedule: "* * * * *" # 1분에 1번씩 실행되는 스케줄
jobTemplate:
spec:
template:
spec:
containers:
- name: sleep
image: ubuntu
command: ["sleep", "80"]
restartPolicy: OnFailure
concurrencyPolicy: Forbid ✔️1분마다 Job 실행 ➜ 1분이 지나면 다음 Job 파드 실행 대기 ➜ 이전 작업 끝나면 실행
터미널 1
$ kubectl create -f sleep-cj.yaml 터미널 2
$ watch -n1 -d kubectl get cj,po NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob.batch/sleep-cj * * * * * False 1 60s 9m5s
NAME READY STATUS RESTARTS AGE
pod/nettool 1/1 Running 2 (28m ago) 3h43m
pod/sleep-cj-27549270--1-2gdkv 0/1 Completed 0 7m
pod/sleep-cj-27549273--1-f4nw6 0/1 Completed 0 4m30s
pod/sleep-cj-27549275--1-6kksf 0/1 Completed 0 2m27s
pod/sleep-cj-27549277--1-wq7wz 0/1 ContainerCreating 0 45s🌟Cron Job은 100회 이상의 실패가 누적되면 중단
시스템에 문제가 발생해서 실패를 할 수도 있지만, forbid 상태에서 파드가 실행되면 실패로 간주
➜ forbid라고 셋팅한 순간, 다음으로 실행하려고 스케줄링된 파드가 실행 중 ➜ 이 실행은 실패로 간주
- startingDeadlineSeconds
스케줄된 시간을 놓친 경우 job의 deadline을 초 단위로 나타냄
job 생성 완료 예상 시각과 현재 시각의 차이를 측정
시각 차이가 설정한 값보다 커지면 job은 실패로 간주하여 시작하지 x
(원래 job은 무기한)
Service (서비스)
파드 집합에서 실행중인 애플리케이션을 네트워크 서비스(외부)로 노출
파드에게 고유한 IP 주소와 파드 집합에 대한 단일 DNS 명을 부여하고, 파드들 사이에서 LB 역할을 수행
IP는 파드마다 1개 부여
컨테이너마다 부여되는 것 x / 파드 내 컨테이너 갯수 상관 x
파드마다 IP가 1개이기 때문에 파드 내의 컨테이너가 어떤 애플리케이션이 수행되고있는 컨테이너인지 알 수 X ➜ 이 때 서비스 사용
pod는 서비스의 selector 에 의해 선택 됨 ➜ 파드에 정의 된 label 을 통하여 selecting
서비스에는 DNS 이름이 부여 됨 (예측 가능)
클라이언트는 해당 DNS 이름을 가지고 서비스에 접근해서 서비스의 로드밸런서 기능을 사용
Coredns ➜ 서비스에 DNS명을 붙이기 위한 kube-dns Add-On
➜ 클러스터 내에서만 사용되는 내부용 DNS
Add-On이지만 kubeadm시 필수로 설치 됨
외부 DNS와는 관계 x ➜ 따로 구성 (AWS Route53 등)
🌟 Type
종류 : ExternalName / ClusterIP / NodePort / LoadBalancer
Default : ClusterIP
- 클러스터 외부 접속 : NodePort / LoadBalancer
- 클러스터 내부 접속 :
ClusterIP- 외부도 내부도 x : ExternalName
Cluster IP 타입의 Service
🎈 ClusterIP
서비스 생성 요청 시 클러스터에 고유한 Cluster IP 지정 가능
$ kubectl describe svc myweb-svc Name: myweb-svc
Namespace: default
Labels: <none>
Annotations: <none>
Selector: app=web
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.233.9.55
IPs: 10.233.9.55
Port: <unset> 80/TCP
TargetPort: 8080/TCP
Endpoints: 10.233.90.128:8080,10.233.90.129:8080,10.233.90.130:8080 ✔️
Session Affinity: None
Events: <none>서비스의 백앤드에 RS를 생성하면 Endpoints 필드가 활성화 ➜ RS에 의해 생성 된 파드의 갯수만큼 Endpoint 생성
Endpoint는 label로 Selecting한 파드 정보를 가지고 있음
파드가 삭제되면 해당 파드에 부여되어있던 Endpoint 삭제 ➜ 새로 생성 된 파드의 Endpoint로 변경
백앤드가 바뀌면 알아서 Endpoint가 알아채고 값 변경 (VM에서는 불가능한 기능)
Endpoint
➜ 오브젝트 리소스
$ kubectl get endpoints(ep)서비스의 이름과 동일 한 엔드포인트 생성
🎈 Ports
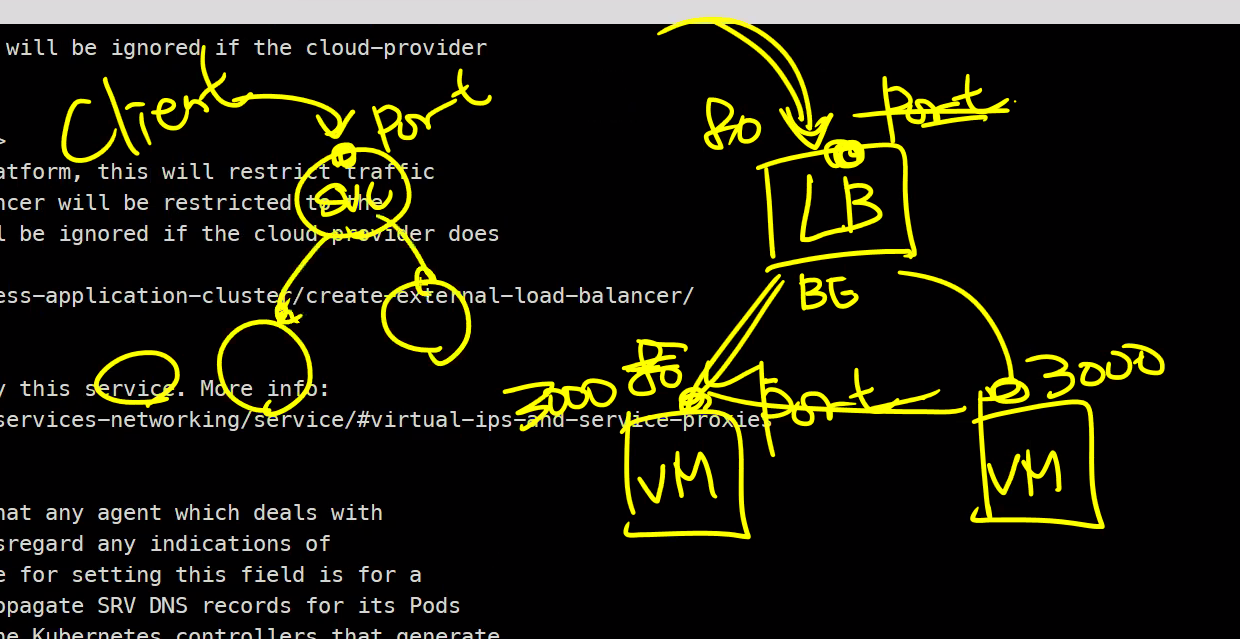
필드
- protocol
- targetPort : svc에 연결 될
파드의 포트 - ...
🎈Service 실습
myweb-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: myweb-svc
spec:
selector:
app: web
ports:
- port: 80 ✔️
targetPort: 8080 ✔️서비스의 포트와 파드의 포트 번호는 달라도 상관 x
(LB와 VM의 포트가 달라도 상관 없었던 것과 동일한 이유)
포트 번호는 yaml 파일 선언 시 리스트 형태
myweb-rs.yaml
LB를 진행할 Replicaset을 서비스의 백앤드로 생성
label로 Selecting 될 수 있도록 myweb-svc.yaml 파일에서 선언한 Selector의 label과 동일한 label 추가
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myweb-rs
spec:
replicas: 3
selector:
matchLabels:
app: web
env: dev
template:
metadata:
labels:
app: web
env: dev
spec:
containers:
- name: myweb
image: ghcr.io/c1t1d0s7/go-myweb
ports:
- containerPort: 8080
protocol: TCPRS, 파드, 서비스 생성 정보 확인
$ kubectl get rs,po,svc NAME DESIRED CURRENT READY AGE
replicaset.apps/myweb-rs 3 3 3 43s
NAME READY STATUS RESTARTS AGE
pod/myweb-rs-76scn 1/1 Running 0 41s
pod/myweb-rs-8vccc 1/1 Running 0 41s
pod/myweb-rs-hsqc9 1/1 Running 0 41s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.233.0.1 <none> 443/TCP 2d
service/myweb-svc ClusterIP ✔️10.233.9.55 <none> 80/TCP 15s➜ Cluster IP는 Kubernetes 서비스 대역에서 할당
생성된 파드에 부여 된 IP 확인
$ kubectl get po -o wideNAME READY STATUS RESTARTS AGE IP ✔️ NODE NOMINATED NODE READINESS GATES
myweb-rs-76scn 1/1 Running 0 8m19s 10.233.90.74 node1 <none> <none>
myweb-rs-8vccc 1/1 Running 0 8m19s 10.233.90.73 node1 <none> <none>
myweb-rs-hsqc9 1/1 Running 0 8m19s 10.233.90.75 node1 <none> <none>🎈 클라이언트 - 서비스 - 파드 구조
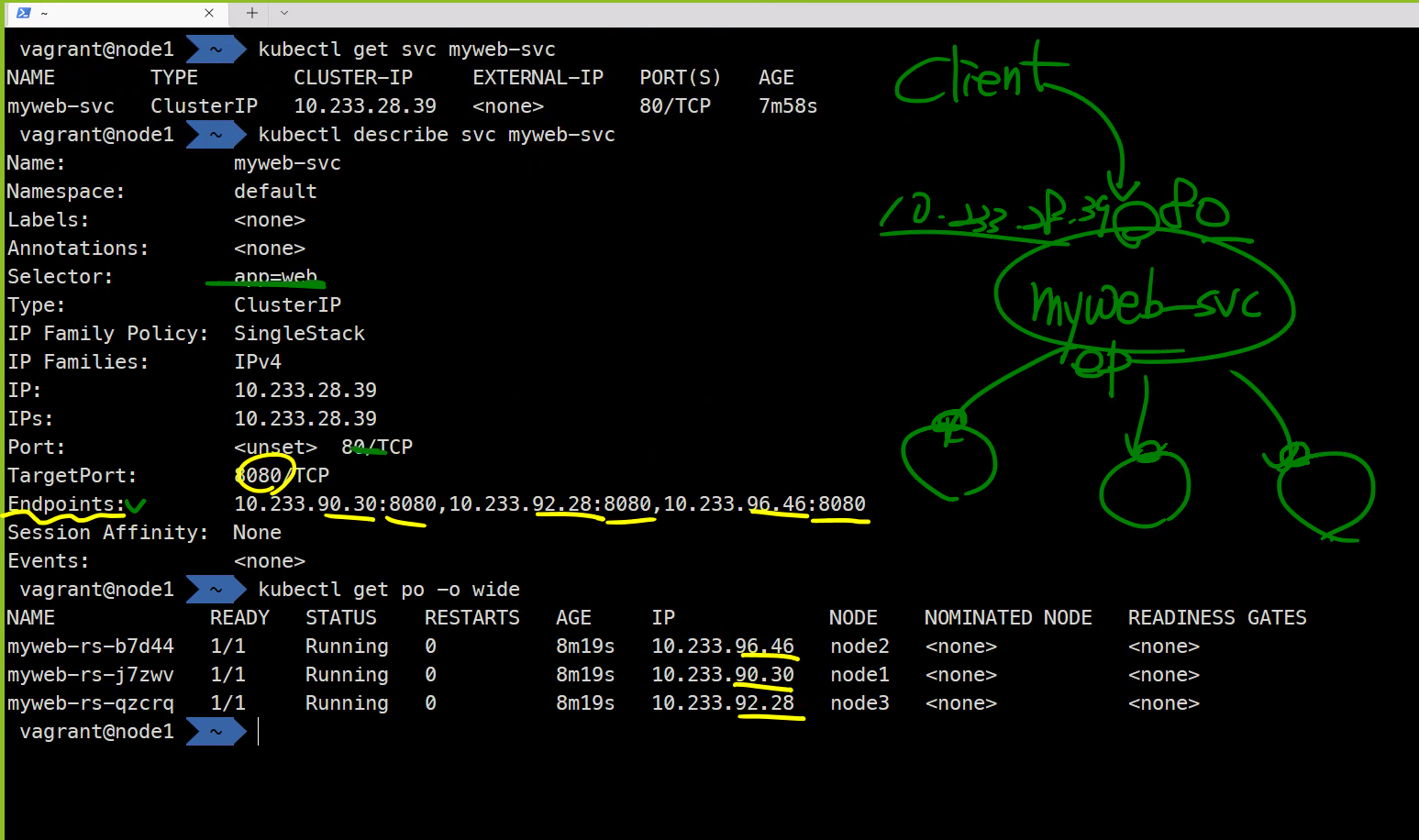
🎈 파드의 엔드 포인트 확인
파드 하나 띄움
$ kubectl run client -it --image ubuntu bash# apt update; apt install curl # curl 명령어 설치Cluster IP curl을 통해 파드의 데이터 실행
# curl 10.233.9.55 10.233.9.55 == Cluster IP
서비스의 로드밸런싱 기능 확인
root@client:/# curl 10.233.9.55
Hello World!
myweb-rs-hsqc9 ✔️
root@client:/# curl 10.233.9.55
Hello World!
myweb-rs-76scn ✔️
root@client:/# curl 10.233.9.55
Hello World!
myweb-rs-8vccc ✔️➕ 기존 파드 재접속 -> 초기화 되어있음
$ kubectl exec -it client bash 🎈 새로운 test 파드 생성
$ kubectl run nettool -it --image ghcr.io/c1t1d0s7/network-multitool bash➜ host 명령 설치되어있음
DNS 이름으로 IP 정보 출력
bash-5.1# host www.google.com
www.google.com has address 172.217.175.228
www.google.com has IPv6 address 2404:6800:4004:821::2004CoreDNS 주소 확인
bash-5.1# cat /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local
nameserver 169.254.25.10 ✔️
options ndots:5nameserver 169.254.25.10 ➜ 쿠버네티스의 coredns 주소
서비스 이름 으로 Cluster IP 주소 확인
bash-5.1# host myweb-svc
myweb-svc.default.svc.cluster.local has address 10.233.9.55이름으로 질의 를 하면 해당되는 Ip로 접근 해서 결과 출력
bash-5.1# curl myweb-svc
Hello World!
myweb-rs-hsqc9bash-5.1# curl myweb-svc -v
* Trying 10.233.9.55:80...
* # 해당 이름을 가진 서비스의 ip는 10.233.9.55 이며 해당 포트로 접속한다
* Connected to myweb-svc (10.233.9.55) port 80 (#0)
... -v : 자세한 옵션 출력
➕ kubelet maxPods =
110개
➜ Kubelet당 110개의 노드까지만 생성 가능
Kubelet이 서비스인 이유
!= k8s의 네트워크 역할을 하는 Service
≒ 시스템 서비스
✔️ $ systemctl status kubelet 으로 확인 가능
kubelet.service - Kubernetes Kubelet Server
Loaded: loaded (/etc/systemd/system/kubelet.service; enabled; vendor preset: >
Active: active (running) since Thu 2022-05-19 10:09:08 UTC; 3h 44min ago
Docs: https://github.com/GoogleCloudPlatform/kubernetes
Main PID: 832 (kubelet)
Tasks: 0 (limit: 3458)
Memory: 109.0M
CGroup: /system.slice/kubelet.service
└─832 /usr/local/bin/kubelet --logtostderr=true --v=2 --node-ip=192.1>💡 Kubelet
bootstrapsa Kubernetescontrol-plane node
API Server, Shed, Control Manager 등의 파드가 존재해야 k8s라고 정의 가능
➜ 이 파드들을 생성 시켜 줄 서비스 가 Kubelet
➜ kubelet이 컨테이너면 kublet을 생성해 줄 주체가 없음
운영체제-서비스 부트스트래핑 구조와 비슷
Kubelet은 kubernetes 디렉토리 내의 manifest yaml 파일에 정의 된 클러스터를 부트스트래핑
Static Pod
주요 용도 : 자체 호스팅 Control Plane을 실행
특정 노드의 kubelet 데몬에 의해 직접 관리되는 특수 파드 (API 서버가 컨트롤하지 x)
개별 컨트롤 플레인 컴포넌트를 감독
실패하면 다시 시작
$ kubectl get po -A 실행 시 뒤에 -node1 등의 이름이 붙어있는 것
Static Pod manifest 파일은 /etc/kubernetes/manifests 디렉토리에 존재
kubelet은 시작 시 파드를 만들기 위해 위 디렉토리를 확인 함
➕ manifest file == 구체적인 리소스 설정 파일
➜ 해당 파일을 생성하면 pod가 생성되고 삭제하면 pod도 삭제 됨
추가 Tip
💡여러 파일 한 꺼번에 실행하는 방법
여러 파일 같이 실행
$ kubectl create -f myweb-rs.yaml -f myweb-svc.yaml현재 디렉토리의 모든 파일 실행
$ kubectl create -f .➕오브젝트 별 API 버전 확인 필수
$ kubectl api-versions➕ GitHub에서 (소프트웨어의) 버전 패치 확인 방법
GitHub에서 로그인 ➜ 소프트웨어의 저장소 ➜notification설정
새로운 버전이 나올 때마다메일로 알림 옴--@mention 파트
notification ➜ all activity 절대 하지 말기
커스텀에 release 설정해놓으면 새로운 버전 나왔을 때마다 알 수 있음
➕
esc + .: (이전) 명령어의 마지막 부분을 붙여넣어 줌 -> 마지막으로 옮기기
