지난 포스팅에서는 Docker를 이용해 Airflow를 설치하고 airflow-code-editor plugin을 설치했다. 이제 DAG를 작성해보자. DAG를 작성하는 문법은 여러가지가 있고, 이 포스팅은 DAG를 작성하며 시행착오를 겪은 과정을 적고 있기 때문에 깔끔하게 정리되었기보다는 과정 중간중간에 겪었던 오류와 그 해결책에 대해서 작성한다.
DAG 작성하기
1. 필요한 모듈을 import하자.
Operator와 데이터 전처리에 필요한 모듈 등을 import 한다.
import airflow
from airflow import DAG
from airflow.operators.mysql_operator import MySqlOperator
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
import pandas as pd2. Default Argument 작성하기.
Default argument 작성을 통해 DAG내 operator에 모두 같은 설정을 적용할 수 있다. onwer, start_date, end_date, depends_on_past, email, email_on_failure, email_on_retry, retries, retry_delay 등 여러 옵션을 설정할 수 있는데 이 중 start_date는 반드시 지정해줘야한다.
init_args = { # init_args는 임의로 지정해준 이름이므로 다른 이름으로 입력해도 된다.
'owner' : 'airflow',
'start_date' : datetime(2022, 7, 4)
}-
Airflow의 시간은 UTC기준이다. 따라서 한국의 시간과는 9시간 차이가 나므로 추가 설정이 필요하다. 방법은 3가지.
- 환경변수AIRFLOW__CORE__DEFAULT_TIMEZONE를Asia/Seoul로 설정해준다.
-airflow.cfg파일에서default_timezone = utc부분을default_timezone = Asia/Seoul으로 바꿔준다.
- DAG파일에서pendulum패키지를 이용해 시간을 변경한다. 아래와 같이 사용하면 된다.import pendulum from datetime import datetime local_tz = pendulum.timezone("Asia/Seoul") init_args = { 'start_date' : datetime(2020, 2, 28, 2, tzinfo=local_tz) }
3. DAG를 선언하기.
DAG를 선언하는 3가지 문법도 차차 알아두자.
init_dag = DAG(
dag_id = 'homework_220707', # dag 이름
default_args = init_args, # 어떤 default arguments를 사용할 것인지
schedule_interval = '@once' # 스케줄링 빈도 설정
)4. MySqlOperator 사용하기.
DB에 저장된 테이블을 불러오기 위해 MySqlOperator를 작성하기로 했다. 먼저 UI 내에서 Mysql을 연결하자. Airflow UI -> Admin -> Connection -> +버튼을 누르면 아래와 같은 화면이 나오는데 DB 연결 정보를 입력하고 Test를 눌러 연결이 잘 되는지 확인한다.
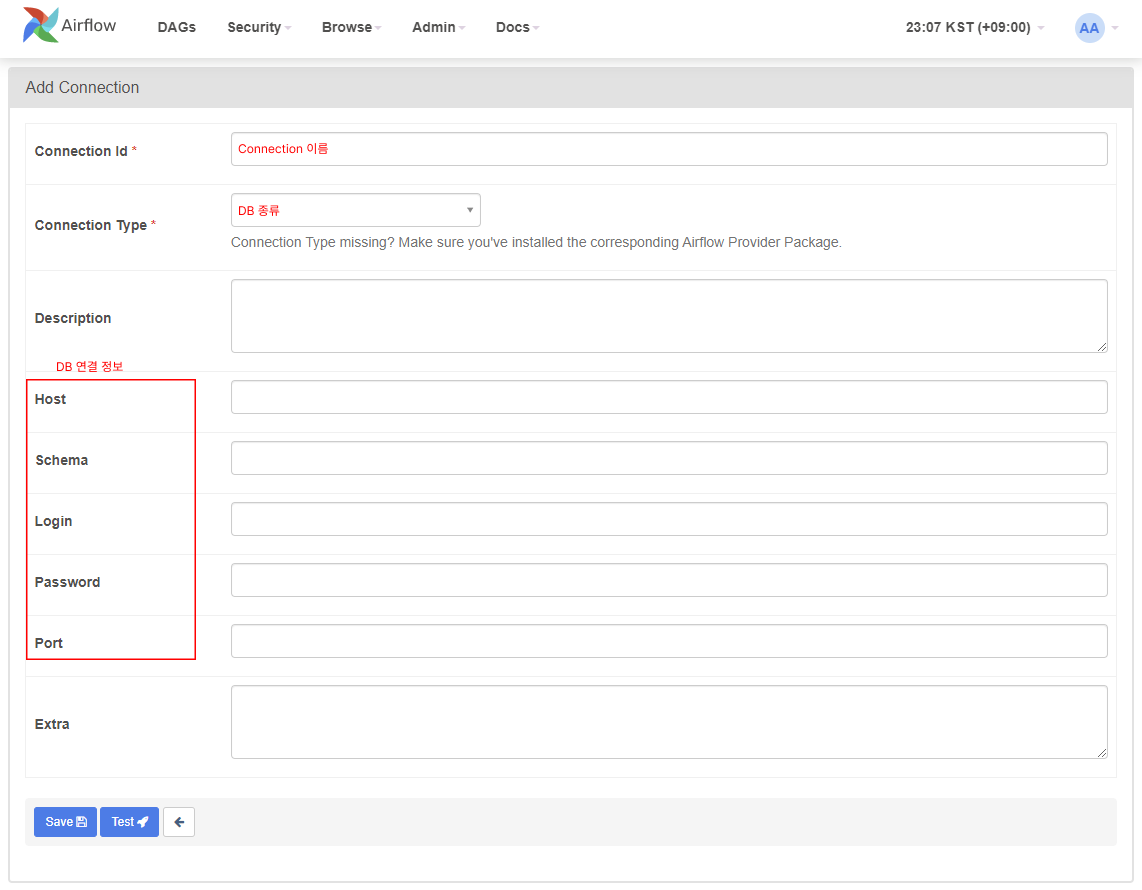 여기서 입력했던
여기서 입력했던 Connection ID를 MySqlOperator 내에 작성한다.
o_data = MySqlOperator(
task_id = 'import_table',
mysql_conn_id = 'connect_mysql', # Connection ID
sql = ['SELECT * FROM DBNAME.DBTABLE;'],
dag = init_dag
)5. '.wslconfig' 파일 수정하기
작성한 DAG파일이 계속 실패하길래 log를 살펴봤는데 MySqlOperator에서 INFO - Task exited with return code Negsignal.SIGKILL 라는 오류가 발생했다. 이는 충분한 resource가 없기 때문이라고 하는데 내가 불러온 테이블이 행 수가 조금 많은 테이블이었으므로.. 사실 이 정도 크기의 테이블도 불러오기 어려운가? 싶었지만 아무튼. docker를 사용중인 사람들은 docker에서 resource 조정을 해주면 된다. Docker Setting > Resources > ADVANCED 에서 조정할 수 있다.
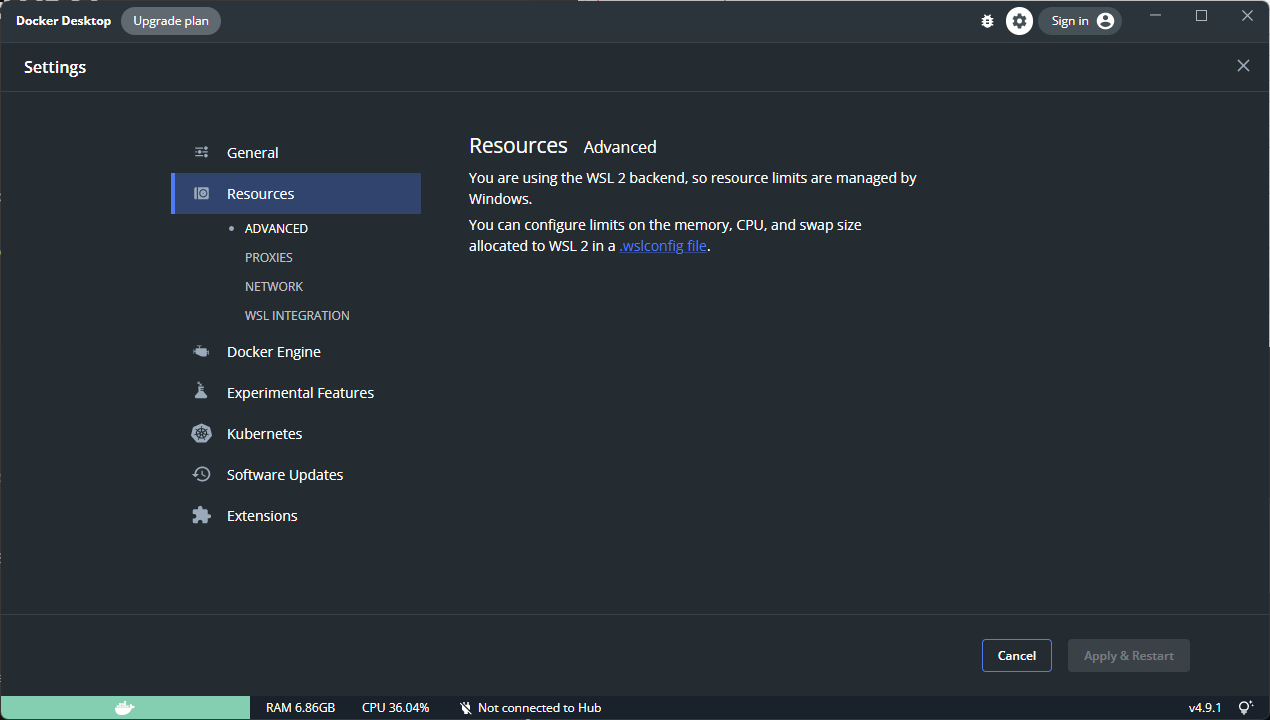 하지만 나는 WSL2를 사용중인데 WSL2를 사용할 경우 리소스를 Docker가 아닌 윈도우에서 조정하는 듯 하다. 그래서
하지만 나는 WSL2를 사용중인데 WSL2를 사용할 경우 리소스를 Docker가 아닌 윈도우에서 조정하는 듯 하다. 그래서 .wslconfig 파일을 생성해 직접 설정해야한다.
C:\Users\<UserName>에 .wslconfig 파일을 생성하자. 아래 형식으로 입력하면 된다. 공식 링크에서 다양한 옵션을 확인할 수 있다. white space외에 #이나 주석 같은 게 들어갈 경우 제대로 작동이 안되는 경우도 있다고 하는데, 참고하길 바란다.
[wsl2]
memory=8GB
processors=2
swap=1GB파일을 생성했으면 cmd에서 wsl --shutdown 명령어로 wsl을 종료시킨다. 명령어를 통해 wsl을 재실행시켜도 좋고, docker에서 wsl이 필요하다고 restart하겠냐는 창이 뜨길래 restart시켰다.
6. PythonOperator 작성하기.
조금 당황스러웠던 게, Airflow에서는 task간에 어떤 값을 전달하려면 XCom 기능을 사용해야하는데 XCom은 Python에서 자주 사용하는 Dataframe을 지원하지 않는다는 것이었다. XCom은 task간 통신을 위한 메모 정도의 목적으로 설계되었기 때문에 대용량 데이터 전송 등의 용도로는 적합하지 않다. (XCom의 default max size는 48KB다) XCom은 원래 Airflow가 사용하는 Metadata database를 저장소로 사용하는데 Dataframe 같은 대용량 데이터를 주고 받게 되면 Database에 해당 데이터를 저장하고 조회한다. 즉, 용량과 속도 면에서도 비효율적인 방식인 것.
여기서 필자의 Airflow에 대한 오해가 하나 해소된다. Airflow는 데이터를 전처리하는 툴이 아니다. Airflow는 데이터 파이프라인의 순서와 실행을 조율하는 스케줄러, 즉 오케스트레이터이고 데이터 전처리는 Spark 같은 프레임워크가 하는 일이다. Spark를 사용하는 방법은 나중에 알아보기로 하고 이 포스팅에서는 간단한 DAG 작성을 해보는 것이 목표이므로 앞에서 MySqlOperator로 불러온 데이터를 사용하는 대신 PythonOperator 자체에서 Mysql을 연결하여 데이터를 불러오고 전처리하는 과정을 하나의 task로 작성하는 방식으로 진행한다.
# //로 감싸진 값들은 사용자 설정에 따라 다르게 입력해주면 된다.
def func1(**context):
# DB 접속 정보
conn = pymysql.connect(host='/host/'
, user='/user/'
, password='/password/'
, port = /port/
, charset='utf8')
cursor = conn.cursor(pymysql.cursors.DictCursor)
sql = "SELECT * FROM DBNAME.DBTABLE;"
cursor.execute(sql)
data = cursor.fetchall()
df = pd.DataFrame(data)
# 전처리 과정 생략
# dictionary 형태로 전달하기 위해 dictionary로
dct = df.to_dict()그래도 '저는 Airflow에서 dataframe을 전달하는 과정이 필요해요!' 하는 분들은 Custom XCom Backend를 사용하시면 된다. 앞에서 Airflow가 기본적으로 Metadata database를 사용한다고 했는데 XCom을 커스텀하여 Metadata DB대신 AWS의 S3를 저장소로 이용하는 것이다. 물론 Azure와 같은 다른 서비스를 이용할 수도 있다. 이 포스팅에서는 다루지 않을 내용이라 다른 링크를 참고하시길 바란다. (AWS S3를 사용하는 방법, Azure를 사용하는 방법)
7. XCom으로 Task에서 Task로 값 전달하기
위에서 XCom은 대용량 데이터 전송에는 부적합하다고 했는데 그럼에도 불구하고 간단한 값을 전달해야할 필요가 있으므로 Xcom을 이용하여 Task1에서 Task2로 값을 전달해보자.
먼저 airflow.cfg 파일을 수정해준다. x-airflow-common: > environment: 영역에 다음 코드를 넣어준다.
AIRFLOW__CORE__ENABLE_XCOM_PICKLING: 'true' 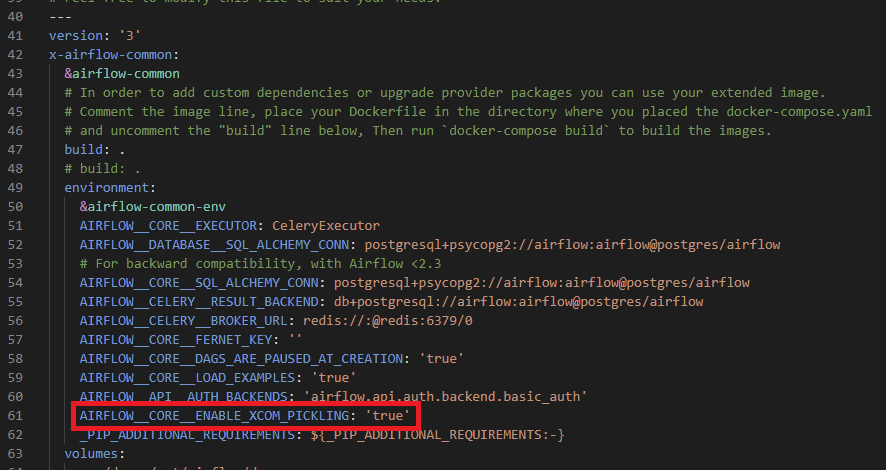
아래 코드에서는 Task1에서 DB에 연결해서 받아온 dataframe 데이터를 전처리하여 dict형태로 Task2에 건네준다. 그리고 Task2에서 dataframe의 col1 열을 그대로 print하는 과정이다.
Task1에서는 xcom_push()로 값을 전달해주고 Task2에서는 xcom_pull()로 값을 받는다. 이 때, task1에서 xcom_push()를 쓰지 않고 함수의 return을 사용해도 된다. xcom_pull()은 다음과 같은 형태로 사용하면 된다.
# task2에 xcom_pull() 작성
context['task_instance'].xcom_pull(task_ids='task1_id')작성한 task1, task2는 다음과 같다. Xcom으로 값 전달을 위해서는 task1 Operator, task2 Operator 양쪽에 provide_context=True 옵션이 필요하다.
def func1(**context):
# DB 접속 정보
conn = pymysql.connect(host='/host/'
, user='/user/'
, password='/password/'
, port = /port/
, charset='utf8')
cursor = conn.cursor(pymysql.cursors.DictCursor)
sql = "SELECT * FROM DBNAME.DBTABLE;"
cursor.execute(sql)
data = cursor.fetchall()
df = pd.DataFrame(data)
...
# 전처리 과정 생략
...
dct = df.to_dict()
return dct
def func2(**context):
response = context['task_instance'].xcom_pull(task_ids = 'task1_id') #task_instance 대신 ti로 축약하여 써도 된다.
print(response['col1'])
task1 = PythonOperator(
task_id = 'task1_id',
python_callable=func1,
provide_context=True,
dag = init_dag
)
task2 = PythonOperator(
task_id = 'task2_id',
python_callable = func2,
provide_context = True,
dag = init_dag
)8. Dependency 설정하기.
작성한 Task, 즉 Operator의 순서를 정해주는 작업이다. Operator안에서 task_id 옵션으로 입력해주었던 값을 이용해서 다음과 같이 작성한다.
task1 >> task2최종 코드
PythonOperator에서 DB연결하여 테이블을 불러왔으므로 4, 5번은 제외되었다.
import airflow
from airflow import DAG
from airflow.operators.mysql_operator import MySqlOperator
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
import pandas as pd
init_args = {
'owner' : 'airflow',
'start_date' : datetime(2022, 7, 4)
}
init_dag = DAG(
dag_id = 'homework_220707',
default_args = init_args,
schedule_interval = '@once'
)
def func1(**context):
conn = pymysql.connect(host='/host/'
, user='/user/'
, password='/password/'
, port = /port/
, charset='utf8')
cursor = conn.cursor(pymysql.cursors.DictCursor)
sql = "SELECT * FROM DBNAME.DBTABLE;"
cursor.execute(sql)
data = cursor.fetchall()
df = pd.DataFrame(data)
...
# 전처리 과정 생략
...
dct = df.to_dict()
return dct
def func2(**context):
response = context['task_instance'].xcom_pull(task_ids = 'task1_id')
print(response['col1'])
task1 = PythonOperator(
task_id = 'task1_id',
python_callable=func1,
provide_context=True,
dag = init_dag
)
task2 = PythonOperator(
task_id = 'task2_id',
python_callable = func2,
provide_context = True,
dag = init_dag
)
task1 >> task2끝!
