
구시대의 thread-safe, 신문물의 non-thread-safe

둘 모두 Map 인터페이스를 구현한 클래스이다.
또한 Hashtable 과 HashMap 모두 해시테이블 자료구조를 기반으로 구현되었다.
O(1) 평균 시간 복잡도를 가지고 있다. (모든 경우가아닌 평균인 이유에 대해서는 다음 링크 참조)
Hash 란
데이터를 다루는 기법의 일종으로, 데이터를 효율적으로 관리하기위해 임의의 길이의 데이터를 해시함수를 통해 매핑하여 고정된 길이의 데이터로 변환하는 기법 이다.
자세한 내용은 Hash, Hash함수, Hashing 참조 추후 따로 작성 예정입니다
해시 테이블 자료구조
Key, Value 로 데이터를 저장하는 자료구조의 일종이다.
해시테이블은 키를 해시 함수로 계산하여, 그 값을 배열의 인덱스로 사용한다. 이때, 해시함수에 의해 반환된 데이터의 고유 숫자값을 해시 코드 라고 한다. 즉, Key값을 통해 얻은 해시코드 를 배열의 인덱스로 사용하는 자료구조이다. 이때, 이러한 값들을 저장하는 배열의 한 칸들을 버킷 이라고 한다.
✋잠시만, 해시코드는 int 형이던데, 그렇다면 배열의 길이가 기본적으로 21억이나 되나요?
이러한 메모리 낭비를 방지하기 위해서, 해시함수는 기존 해시코드를 특정값으로 나눈 나머지를 반환하고, 따라서 해당 값을 배열의 인덱스로 저장한다. 이때 특정값을 M이라 해보자.
- 만약 해시코드가 28945147 이고 M 이 100 이라면
해당 값의 인덱스는 28945147 % 100 인 47이 된다. - 그런데, 만약 해시코드가 147 이라면
해당 값의 인덱스 또한 47이 된다.
서로 다른 두 키 간의 값을 저장하는 인덱스가 같아지는데, 이를 해시 충돌 이라고 한다.
해시 충돌
서로다른 문자열이 Hash Function 을 통해 Hash 한 결과가 같은 경우(전술한 경우) 발생한다.
기본적으로 충돌을 줄여주는 좋은 해시함수를 사용하는것이 좋지만, 그럼에도 해시 충돌이 발생할경우, 아래와 같은 방식으로 해결할 수 있다
Separating Chaining
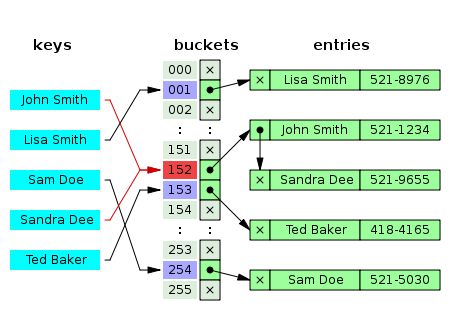
인덱스가 충돌이 날 경우, 해당 인덱스의 값을 리스트 (또는 트리) 형식으로 변경하여 해당 리스트에 충돌하는 두 값을 저장한다.
데이터 탐색시, 키에대한 인덱스가 가르키고있는 리스트를 검색하여 키에대한 데이터를 반환한다.
삭제 또한, 리스트에 존재하는 하나의 값을 삭제한다.
JDK 내부에서 사용하고있는 충돌 처리방식이 바로 Separating Chaining 이다.
다만, 리스트를 사용할 경우, 시간복잡도가 O(N) 이 되므로, Java 8 이후에는 최적화를 위해 O(logN) 의 시간복잡도를 가지는 균형 이진 트리를 함께 사용하고있다
만약 데이터가 6개 이하이면 List 를, 8개 이상이면 Tree 를 사용한다.
Open Addressing

인덱스가 충돌할 경우, 추가적인 메모리 공간을 사용하는것이 아닌, 해시테이블 내의 빈 공간을 사용하는 방법이다. Separate Chaining 방식에 비해 메모리를 덜 사용하지만 데이터가 많아질수록 성능이 떨어진다.
빈 공간을 검색하는 방법에 따라 Linear Probing, Quadratic Probing, Double Hashing 이 있다.
- Linear Probing : 기존 인덱스에 계속 1씩 더해가며 빈 공간을 찾는다.
즉 충돌하는 index 가 n 이면n+1,n+2식으로 검색을 수행한다. - Quadratic Probing : 기존 인덱스에 1^2 를 더하고, 만약 빈공간이 없을경우 2^2를 더한 곳을검색하는 방식이다.
즉, 충돌하는 index 가 n 이면n + 1^2,n + 2^2식으로 검색을 수행한다. - Double Hashing : 해싱한 값에 다른함수로 다시 해싱한 값을 더하여 새 주소를 얻는 방식이다. 즉, 충돌하는 index 가 n 이면,
n + hashA(value),n + hashA(value) + hashB(value)식으로 검색을 수행한다. 사실상, 새로 검색한 값이 빈 공간이 아닐 확률은 거의 없지만, 계속 빈 공간이 아닐경우, 즉 계속 충돌이 일어날 경우, 탐색성능이 위의 두 방법에 비해 현저히 떨어진다.
리사이징
해시테이블의 버킷이 일정 수준 이상으로 찰 경우, 버킷의 개수를 늘려주어야 한다. 이를 리사이징 이라고 한다.
보통 75% 이상 찰 경우, 현재 버킷 수의 2배 만큼 확장하는데, 이 75% (일정수준) 을 로드팩터(load factor) 라고 한다.
리사이징은 더 큰 버킷배열을 새로 만든 뒤, 새로운 배열에 Hash 를 재계산해서 복사해준다.
즉, 리사이징이 많이 될수록 성능이 떨어진다
Hashtable, HashMap and ConcurrentHashMap
둘 다 지금까지 설명한 해시 테이블 자료구조를 구현한 것 이다.
Hashtable 이 HashMap 보다 먼저나왔으며, Hashtable은 현재 지원이 종료(deprecated)되었다
또한 Hashtable 은 동기화를 지원하지만, HashMap 은 동기화를 지원하지 않는다. (thread-safe 여부)
✋잠시만, 그럼 동기화 환경에서는 Hashtable 을 사용해야하지 않나요? 왜 deprecated 되었죠?
이전에 Separating Chaining 방식을 소개할때, 최적화를 위해 Java8 이후에는 리스트와 트리를 혼용한다 라고 하였다. 하지만, Hashtable 은 Java 8 이전에 나온 클래스이다.
즉, 성능이 좋지 않다. (이외의 deprecate 된 이유는 링크 참조)
- 따라서 현재는 비동기 환경에서의 해시 테이블은 ConcurrentHashMap 이라는 Hashtable 의 대체제를 통해 사용할 수 있다. (Vector 를 대체한 CopyOnWriteArrayList 를 떠올리면 편하다)
- 무엇보다, Hashtable 은 비동기를 지원하기위해 성능에 치명적인 synchronized 를 메서드 전체에 붙이는 반면 ConcurrentHashMap 은 쓰기작업중에서도 특정 부분(버킷 등)에 대해서만 synchronized 를 붙여 lock 을 건다.
- 또한, sycronized 이외의 동기화 기법(CAS 등) 도 사용하여 성능을 높였다 (자세한 설명은 링크 참조)
