
자바에서의 Mutli Thread 이슈들
비동기 상황에서의 자바의 메모리 구조
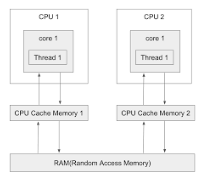
자바의 메모리 구조는 위의 그림과 같이, CPU - RAM 아키텍처 기반으로 이루어진다.
- CPU 가 작업을 처기하기 위해 필요한 데이터를 RAM 에서 읽어들여서 CPU Cache Memory 에 복제한다.
- 작업을 처리한 뒤, 변경된 CPU Cache Memory 의 데이터를 RAM 에 덮어씌운다(RAM 쓰기작업)
이때, CPU 가 여러개일 경우, 각 CPU 별 Cache Memory 에 저장된 데이터가 달라 문제가 발생할 수 있다.
gitFlow 를 통한 Github Branch 관리에서 feature/a 를 develop 브랜치에 Merge 했더니, feature/b 를 develop 브랜치에 Merge 할떄는 Conflict 가 나는것처럼 말이다.
이러한 문제는 가시성 문제 와 동시 접근 문제 두가지로 나뉜다.
가시성 문제
하나의 스레드에서 공유자원(변수, 객체 등)을 수정한 결과가 다른 스레드에게 보이지 않는 경우 발생하는 문제이다.
사실 동시접근 문제와 헷갈리다가 아래의 코드를 보고 바로 이해가 갔다
public class Solution {
private static volatile boolean stopRequested; //무조건 메인 메모리에서 가져온다.
public static void main(String[] args) throws InterruptedException {
Thread background = new Thread(() -> {
for (int i = 0; !stopRequested ; i++); //(N)
System.out.println("background 쓰레드가 종료되었습니다!");
});
background.start(); //(A)
TimeUnit.SECONDS.sleep(1);
stopRequested = true; //(B)
System.out.println("main 쓰레드가 종료되었습니다!");
}
}코드를 보면 (A) 이후 (B) 가 실행되기 전까지 i 에 1씩 더하다가
(B) 가 실행된 이후(약 1초 후)에는 while 문을 빠져나오고, 프로그램이 종료될 것 같아보인다.
즉 다음과 같은 output 을 예상할 수 있다
//main 쓰레드는 1초가 지난 후, 바로 출력하는 반면,
//background 쓰레드는 1초가 지난 후 for 문의 조건식을 검사하기 떄문에
//background 쓰레드가 더 늦게 종료된다.
main 쓰레드가 종료되었습니다!
background 쓰레드가 종료되었습니다! 하지만, 정작 코드를 실행시켜보면 몇분이 지나도 프로그램은 종료되지 않는다
main 쓰레드가 종료되었습니다!
//프로그램이 계속해서 돌아간다.바로 이전에 말한 가시성 문제 때문이다.
- background Thread 는 Main Thread 와는 다른 CPU 의 캐시메모리에 메인 메모리에 존재하는 stopRequested 공유자원을 복제한다.
- 이후,
(N)의 조건식과 증감식을 반복하여 실행한다. - 1초 이후, Main Thread에서 stopRequested 를 true 로 바꾼다.
- 하지만, background Thread 에서는 Main Thread 와 다른 CPU Cache Memory 에 있는 stopRequested 를 참조하기 때문에 Main Thread 에서 일어난 변경을 알아채지 못한다.
이렇듯, 공유자원을 CPU Cache Memory 에서 복제해서 사용하기 때문에 타 쓰레드에서의 변경을 알아차리지 못하는 것 이다.
여기서 background Thread 는 참조변수 명이 background 인 쓰레드를 말하는 것 이다.
동시 접근 문제
여러 스레드에서 공유자원(변수, 객체 등)을 동시에 접근하였을 때, 연산이 가장 늦게 끝난 결과값으로 덮어씌워진다.
public class Problem {
private static int t;
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
new Thread(() -> {
for (int j = 0; j < 1000; j++)
System.out.println(t++);
}).start();
}
}
}코드를 보면 1부터 100000 까지 출력할 것 같아 보인다.
즉 다음과 같은 output 을 예상할 수 있다
1
2
3
//중략
99999
100000하지만, 코드를 실행시켜보면 99995, 99997 같이 10만 언저리에서 프로그램이 종료되게 된다.
또한, 같은 숫자가 2번 이상 반복되어 출력되기도 한다.
동시 접근 문제 가 발생하기 떄문이다.
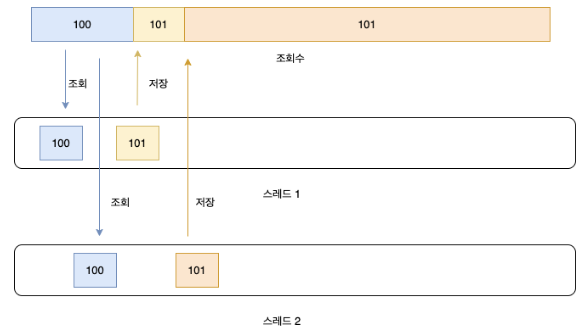
아래의 그림처럼 여러 쓰레드 (현재 100개) 에서 공유자원에 동시에 접근하기 때문에, 연산 속도가 빠른 쓰레드에서의 변경값이, 연산속도가 느린 쓰레드에서의 변경값으로 덮어씌워지는 것 이다.
동시 접근 문제 - 원자성
| Java 에서의 명령 | CPU 가 수행하는 명령 |
|---|---|
| i++ | i 를 Main Memory로부터 읽어 Cache Memory에 옮겨온다 |
| Cache Memory의 값에 1을 더한다. | |
| 더한 값을 다시 Cache Memory 에 넣는다. | |
| Cache Memory 에 저장된 값을 Main Memory 에 반영한다. |
위의 표와 같이, i++ 이라는 명령을 입력할 경우, CPU 에서는 총 4가지의 작업이 수행된다.
그렇다면 만약 여러 쓰레드에서 동시에 i++ 이라는 연산을 수행할 경우 어떻게 될까?
| AThread 에서의 명령 | BThread 에서의 명령 | CPU가 수행하는 명령 |
|---|---|---|
| i++ | i 를 Main Memory로부터 읽어 Cache Memory에 옮겨온다 | |
| 수행중 | Cache Memory의 값에 1을 더한다. | |
| i++ | i 를 Main Memory로부터 읽어 Cache Memory에 옮겨온다 | |
| 수행중 | 더한 값을 다시 Cache Memory 에 넣는다. | |
| 수행중 | Cache Memory의 값에 1을 더한다. | |
| 수행중 | 더한 값을 다시 Cache Memory 에 넣는다. | |
| 수행중 | Cache Memory 에 저장된 값을 Main Memory 에 반영한다. | |
| 수행중 | Cache Memory 에 저장된 값을 Main Memory 에 반영한다. |
다음과 같이 동시 접근 이슈 가 발생하게 된다.
해당 연산에서 동시 접근 이슈가 발생한 이유는 A 쓰레드의 명령이 수행되고 있는 도중 B 쓰레드의 명령이 수행되었기 떄문 이다.
그런데 만약 CPU 가 수행하는 명령이 i 에 1을 더한다 하나였다면 어떨까?
| AThread 에서의 명령 | BThread 에서의 명령 | CThread 에서의 명령 | CPU가 수행하는 명령 |
|---|---|---|---|
| i++ | i 에 1을 더한다 | ||
| i++ | i 에 1을 더한다 | ||
| i++ | i 에 1을 더한다 |
하나의 명령이 수행되고 있는 와중, 다른 쓰레드의 명령이 실행되지 않고 있다. (명령의 최소단위이기 때문에)
이렇듯, 하나의 명령이 수행되는동안 다른 쓰레드의 명령이 보류되는(?) 특성을 원자성이라고 하고, 이를 통해 동시접근 문제를 해결할 수 있다.
자바에서는 이러한 공유자원에 대한 비동기이슈를 해결할 방법들을 제공한다.
JVM 키워드를 통한 비동기 이슈 해결
synchronized
multi thread 환경에서 동일한 자원에 대한 동시 접근을 막는 방식
synchronized 키워드를 붙인 자원은 동시에 접근할 수 없다.
만약 여러 쓰레드에서 해당 자원에 동시에 접근할 경우, 가장 처음 접근한 쓰레드가 작업을 끝낼 때 까지, 자원에 lock 을 걸어서, 다른 쓰레드에서의 접근을 완전 차단한다.
따라서, 가시성 문제를 해결할 수 있으며, 원자성을 보장(한 연산이 수행할때 다른 연산에 간섭받지 않음)하기에 동시 접근 문제 또한 해결할 수 있다.
이러한 synchronized 키워드를 사용하는 방법은 syncrhronized 메서드와 synchronized 블록 두가지 방식이 있다.
- synchronized 메서드
해당 메서드에 오직 하나의 Thread 만 접근 가능하게 한다. 즉, doSomething 메서드는 같은 시간에 하나의 쓰레드에서만 실행할 수 있다.public synchronized void doSomething() {}
- synchronized 블록
해당 블록 내에 있는 구문은 하나의 Thread 에서만 접근 가능하다 기존 synchronized 메서드를 사용하면 메서드 접근 자체를 하나의 쓰레드에서만 가능하게 막아버리기에 성능이 많이 저하되는데 synchronized 블록을 써서, 동기화가 필요한 로직에만 lock 을 걸도록 하면 성능저하를 줄일 수 있다.synchronized(object) { //doSomthing that need sunchronized }
synchronize 의 문제점
하지만, synchronized 키워드를 남용할 경우 lock 이 걸리는 쓰레드가 많아지고, synchronized 메서드 혹은 로직에 대한 병목현상 이 발생하기 쉬워, 아래에 나오는 volatile 이나 Atomic 을 주로 사용하는 추세이다.
volatile
오로지 Main! Main Memory!
변수를 Main Memory 에만 저장하겠다는 뜻을 가진 키워드 이다.
volatile 키워드를 붙인 자원은 read 나 write 작업이, CPU Cache Memory 가 아닌 Main Memory 에서 이루어진다.
volatile 이 해결할 수 없는 이슈
volatile 은 하나의 thread 만이, write 를 하고, 나머지 thread 는 read 를 한다는 전제 하에, 비동기 이슈를 해결할 수 있다. 이유는 다음과 같다.
- volatile 키워드를 사용하면 자원을 저장하는 메모리는 하나가 된다. 즉 같은 공유자원에 대해 각 메모리별로 다른값을 가질 경우 는 사라진다.
- 하지만, 여러 쓰레드에서 Main Memory 에 있는 공유자원에 동시에 접근 할수는 있다. 따라서 동시에 접근하여, 여러 쓰레드에서 수정이 발생할 경우, 기존 동시접근 문제처럼 연산이 느린 쓰레드의 계산값으로 덮어씌워질 수 있기 떄문 이다.
요약하자면, volatile 키워드로 가시성 문제 는 해결할 수 있으나 동시접근 문제 는 해결할 수 없기 때문이다.
JDK 객체를 통한 비동기 이슈 해결
Atomic 변수
자바에서 lambda 식을 사용해보았다면, AtomicInteger 같이 이름에 Atomic 이 붙은 객체들을 사용해본 기억이 있을 것 이다. 이러한 것들을 Atomic 변수 라고 한다.
Atomic 변수는 원자성을 보장하는 변수라는 의미로, 기존에 원자성을 보장하였던 synchronized 키워드의 성능 저하 문제 를 해결하기위해 고안된 방법이다.
Atomic 변수의 경우 CAS (Compare And Swap)알고리즘을 통해 동작한다.
CAS 알고리즘이란 현재 쓰레드가 존재하는 CPU 의 CacheMemory 와 MainMemory 에 저장된 값을 비교하여, 일치하는 경우 새로운 값으로 교체하고, 일치하지 않을 경우 기존 교체가 실패되고, 이에 대해 계속 재시도를 하는 방식이다.
- 즉, CPU가 MainMemory 의 자원을 CPU Cache Memory 로 가져와 연산을 수행하는 동안,
- 다른 쓰레드에서 연산이 수행되어 MainMemory 의 자원이 바뀌었을 경우,
- 기존 연산을 실패처리하고, 새로 바뀐 MainMemory 값으로 재수행하는 방식이다.
- 아래는 Atomic Integer 에서의 incrementAndGet() 의 동작방식이다.
public class AtomicInteger extends Number implements java.io.Serializable {
private volatile int value;
public final int incrementAndGet() {
int current;
int next;
do {
current = get(); //MainMemory 에있는 현재값을 가져온다
next = current + 1; //연산을 수행한다. 해당메서드의 기능은 기존값에 1을 추가하고 추가된 값을 반환하는것이므로 현재값에 + 1 을 해준다.
} while (!compareAndSet(current, next)); //연산이 실패처리되지 않을때까지 반복한다.
return next; //연산이 성공하면 기존값에 1을 추가한 값을 반환한다.
}
//next = current + 1 의 연산을 수행하는동안
//MainMemory 의 값이 바뀌어 current 와 다른 값을 가질경우,
//false 를 반환한다.
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
}코드를 보면 volatile 키워드가 쓰인것을 볼 수 있다.
원래 volatile 의 경우, synchronized 키워드와는 달리 동시 접근 문제를 해결하지 못한다. 즉, 원자성을 보장하지 못한다.
따라서, CAS 알고리즘을 통해 원자성을 보장하도록 만든 비동기 방식이 Atomic변수이다.
따라서, Atomic 변수는 synchronized 키워드처럼 동시접근 문제와 가시성 문제 모두 해결할 수 있다
원자성을 보장하는 volatile, synchronized 보다 성능이 좋다 라는식으로 이해하면 편하다

안녕하세요! 포스팅 잘 읽었습니다. 다름이 아니라 가시성 문제쪽 코드에 volatile 키워드를 붙이셨는데 아래에 실제 동작에 Background 쓰레드가 종료되지 않는다고 작성되어 있더라구요. 근데 설명하신 동작과 코드가 상이한 것 같아서 댓글을 남깁니다 :)