
OCT 3주차 (10/13 ~ 10/17 회고)
📍 전체 목차
Ch1. Vector, 행렬, 배열
Ch2. Data 저장
Ch3. 데이터 랭글링 (Data Wrangling)
Ch4. 수치형 Data 다루기
Ch5. 범주형 Data 다루기
Ch6. Text 다루기 (예고)💡 머신러닝 기초 회고 개요
데이터를 다루려면,
→ 행렬(Matrix) 은 “보관소”
→ 자유자재로 다룰 수 있어야 함!
🧩 Ch1. Vector, Matrix(행렬), 배열(from NumPy)
🔹 벡터 = 단순히 하나의 차원을 가진 배열
vector_row = np.array([1, 2, 3])
vector_column = np.array([[1], [2], [3]])
→ 배열은 Vector로 표현할 수 있다.
🔹 행렬 (Matrix) = 2차원 numpy 배열
matrix = np.array([[1, 2, 3],
[1, 2, 3]])🔹 희소행렬 (Sparse Matrix) = 대부분 원소가 0인 행렬을 효율적으로 저장하는 방법
from scipy import sparse
matrix = np.array([[0, 0, 1],
[0, 1, 0],
[3, 0, 3]])
matrix_sparse = sparse.csr_matrix(matrix) (0,1) 0
(2,1) 3
역변환:
matrix_sparse.toarray()
🔹 NumPy 배열 생성 함수들
np.zeros(shape=5) # 0으로 채운 배열 -> 실수값 출력
np.ones(shape=5) # 1로 채운 배열 -> 실수값 출력
np.full(shape=(3, 3), fill_value=1) # 지정값으로 채움 -> 정수값 출력
🔹 인덱싱 / 슬라이싱
vector[::-1] # 벡터의 원소 순서 뒤집기
matrix[:, 1:2] # 모든 행 & 두번째 열 선택→ 내가 헷갈리는 인덱싱
📘 Fancy Indexing : 인덱스 리스트만 전달
matrix[[0, 2]] → 1, 3번째 행만 선택
array([[0, 0, 1],
[3, 0, 3]]matrix[[0, 2], [1, 3]] → (0,1), (2,0) 위치 원소 선택
= 괄호 안쪽 첫 번째 인덱스는 행, 두 번째 인데스는 열
⚙️ 벡터 연산
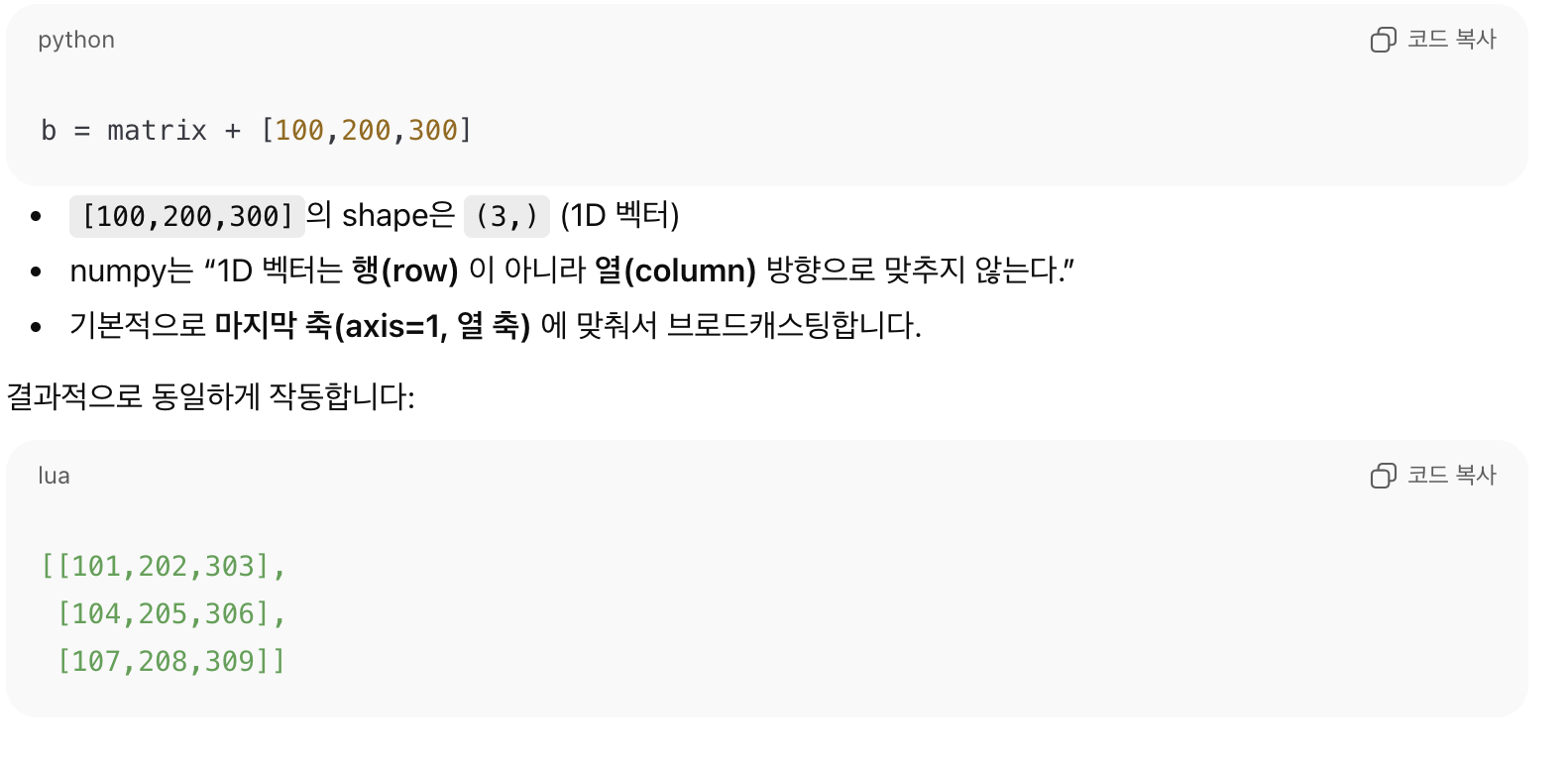
🔹 Broadcasting : 서로 다른 크기의 배열끼리 연산(+,-,*,/) 을 가능하게 해주는 규칙
NumPy의 핵심 기능: 자동으로 크기 맞춰 연산 수행
1️⃣ 예시: (1,3) shape 배열

2️⃣ 예시: 1차원 vector
🔹 축(axis) 개념
💡 “axis가 고정되는 축” 을 뜻합니다.
axis=0이면 “행을 따라 계산하라 (세로로 내려가라)”
axis=1이면 “열을 따라 계산하라 (가로로 가라)”
np.max(matrix, axis=0) # 각 열의 최댓값
np.max(matrix, axis=1) # 각 행의 최댓값
🔹 평균, 분산, 표준편차
np.mean(matrix)
np.var(matrix)
np.std(matrix, ddof=1) # 표준편차, 자유도 조정 가능
🔹 배열 구조 변경
matrix.reshape(2, 6) # 2x6 형태로 변경
matrix.reshape(-1) = matrix.ravel() # 1차원으로 평탄화

⬆️ (1,9) shape의 2차원 배열임
🔹 행렬 전치(Transpose)
matrix = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
matrix.T
또는:
matrix.transpose()
- matrix.T와 .transpose()는 거의 동일
(다만, 여러 축이 있는 배열의 경우.transpose(axes)로 지정 가능)
🔹 벡터 전치 시 주의
:1차원 벡터에는 전치가 적용되지 않음 → 2D로 바꿔야 함
np.array([[1,2,3,4,5,6]]).T
📏 행렬 평탄화 & 변형
matrix.flatten() # 평탄화 (복사본)
matrix.reshape(-1) # 평탄화 (뷰)
대각선 요소 추출: np.diag(matrix)
⚡ Dot Product (내적)
| 비교 항목 | np.dot() | np.matmul() / @ |
|---|---|---|
| 1D 벡터 연산 | 내적 (스칼라) | ❌ 지원 안 함 |
| 2D 행렬 곱 | ✅ 동일 | ✅ 동일 |
| 3D 이상 (배치 연산) | ❌ 비직관적 결과 | ✅ 각 배치별 행렬 곱 |
| 브로드캐스팅 | ❌ 없음 | ✅ 지원 |
| 추천도 | 구버전 호환용 | ✅ 권장 (Python 3.5+ 표준) |

행렬의 곱(일반적 개념) vs 내적(1차원 배열인 벡터 사이의 곱 = 결과: 스칼라)
| 구분 | 내적 (dot product) | 행렬 곱 (matrix multiplication) |
|---|---|---|
| 입력 | 두 벡터 (1D) | 두 행렬 (2D 이상) |
| 결과 | 스칼라(숫자 하나) | 새로운 행렬 |
| 관계 | 행렬 곱의 “한 셀”을 만드는 연산 | 여러 내적의 집합 |
| 예시 | [1,2,3]·[4,5,6] = 32 | A(2×3)×B(3×2) = C(2×2) |
🎲 난수 생성 및 제어
np.random.seed(0) # 랜덤 고정하여 초기값 지정
np.random.random(3) # 0~1 사이 float 3개 생성
np.random.randint(0, 11, 3) # 0~10 사이 정수 3개 생성
np.random.normal(0.0, 1.0, 3) # 평균=0, 표준편차=1 정규분포를 따르는 float 3개 생성
📂 Ch2. 데이터 저장 (Data Storage)
2.1 샘플 데이터 불러오기
from sklearn import datasets
→ 사이킷런 라이브러리 이용
→ ex. load_iris load_digits
또는 직접 생성:
from sklearn.datasets import make_regression :선형 회귀
from sklearn.datasets import make_classification: 분류
from sklearn.datasets import make_blobs: 군집
→ 알고리즘에 적용할 dataset 직접 생성
2.2 CSV 파일 → DataFrame 형태로
import pandas as pd
dataframe = pd.read_csv(url) #csv는 값들이 콤마로 구분됨 → sep 매개변수에 파일이 사용하는 구분자 지정 가능
pd.read_csv(url, skiprows = range(1,11), nrows=5) # 1~10번째 행 건너뛰고, 다음 1개 행 읽기2.3 Excel 파일 읽기
pd.read_excel(url, sheet_name=0, header=0)- sheet_name 매개변수로 엑셀의 몇 번째 시트 가져올건지 지정 가능
- header 매개변수로 몇 번째 row가 제목인지 지정 가능
🔧
pip install openpyxl필요
2.4 JSON 파일 읽기
pd.read_json(url, orient='columns')
- orient 매개변수는 JSON 파일이 어떻게 구성되었는지 지정
ex) 'columns'는 JSON 파일이 {열:{인덱스:값, ...},...} 구조를 가질 것으로 기대
📘 JSON 정규화:
from pandas import json_normalize
2.5 Parquet 파일 읽기
pd.read_parquet(url)🔧
pip install pyarrow필요
2.6 SQL DB 불러오기
import pymysql
conn = pymysql.connect(host='localhost', user='root')🧹 Ch3. 데이터 랭글링 (Data Wrangling)
데이터 정제하고, 사용 가능한 컬럼으로 변환하는 과정!
3.1 여러 소스에서 DF 생성
다양한 포맷 → DataFrame으로 변환
3.2 데이터 정보 확인
dataframe.head()
dataframe.shape
dataframe.describe()
dataframe.info()
3.3 행/열 선택 from 스라이싱
1. .iloc = 데이터 프레임 위치를 참조[인덱스 기반]
dataframe.iloc[0:3, [1, 2]]
2. .loc = 데이터프레임 인덱스가 레이블(ex. 문자열) 일 때 사용
# 인덱스를 설정합니다.
dataframe = dataframe.set_index(dataframe['Name'])
# 행을 확인합니다.
dataframe.loc['Allison', ['Age', 'Sex']]3.4 조건부 선택
dataframe[(dataframe['sex']=='female') & (dataframe['age']>=65)]
3.5 정렬
dataframe.sort_values(by=['Age'], ascending=False)
3.6 값 치환
dataframe['sex'].replace(['female','male'], ['woman','man'])
3.7 열 이름 바꾸기
dataframe.rename(columns={'pclass':'passenger_class','sex':'gender'})
3.8 통계치 계산
min, max, sum, mean, count, var, std, kurt(첨도), skew(왜도), mode
-
kurt(첨도): 확률 분포의 뾰족한 정도를 나타냄
-
Skew (왜도):
- 0이면 대칭- 음수면 왼쪽 꼬리
- 양수면 오른쪽 꼬리
3.9 고유값 확인
dataframe['sex'].unique()
dataframe['sex'].value_counts()
결측치 포함 시: dropna=False → 기본값은 true 임
3.10 결측치 처리
- 판다스: 자체적으로 NaN 구현 x
⬇️ - Numpy: np.nan으로 NaN 구현
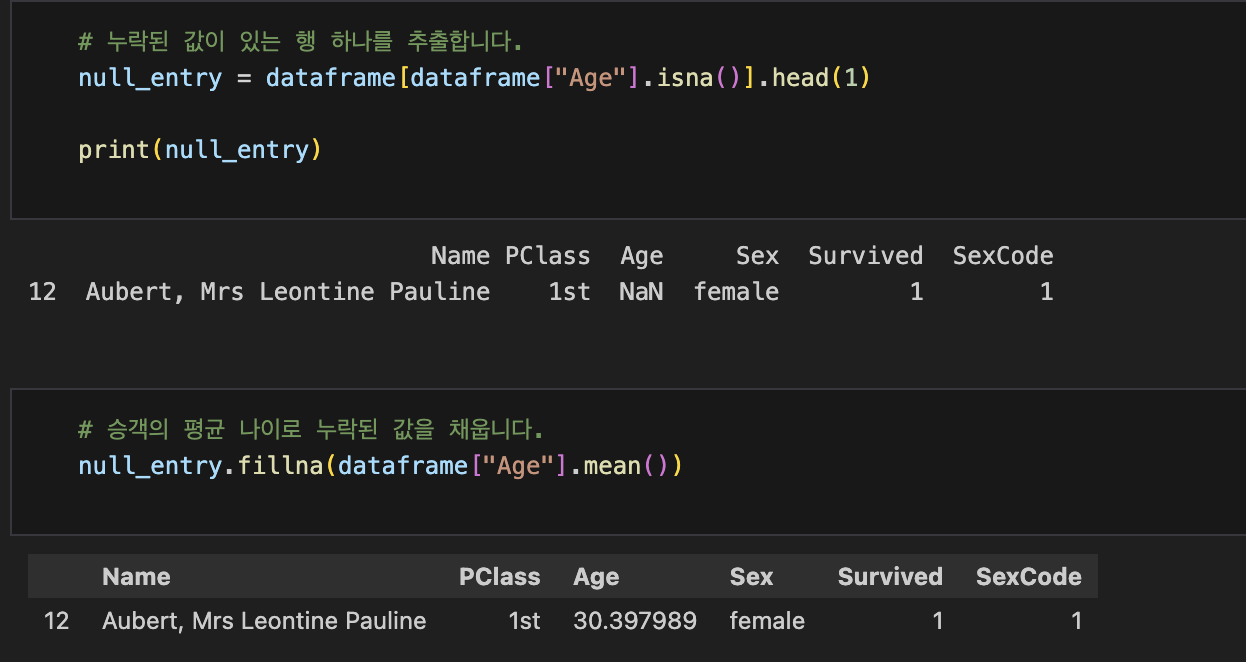
## 누락된 값을 선택하고 두 개의 행을 출력합니다.
dataframe[dataframe['Age'].isnull()].head(2)
# NaN으로 값을 바꿉니다.
dataframe['Sex'] = dataframe['Sex'].replace('male', np.nan)dataframe.isna()
dataframe.fillna()
3.11 열 삭제
dataframe.drop(['Age','Sex'], axis=1)
3.12 행 삭제
조건 필터링 후 drop: dataframe[dataframe['sex']=='male']
3.13 중복 행 제거
dataframe.drop_duplicates(subset=['sex'], keep='last')
→ 기본적으로 모든 열이 완벽히 동일한 행만 삭제
→ subset 매개변수를 사용하면 일부 열만 대상으로 중복 행 삭제
→ keep 매개변수는 남길 행을 의미
dataframe.duplicated(): 메서드는 행이 중복되었는지를 알려주는 불리언 시리즈를 반환
3.14 그룹핑(Grouping)
groupby 메서드는 통계계산과 같이 각 그룹에 필요로 하는 연산이 필요
dataframe.groupby(['sex','survived'])['name'].count()
#1st 열 그룹핑 후 2nd 열 그룹핑 가능
dataframe.groupby(['sex'])['age'].mean()3.15 시계열 리샘플링
dataframe.resample('W').sum() # 주 단위
dataframe.resample('M').count() # 월 단위
dataframe.resample('2W').mean() # 2주 단위3.16 열단위 통계 (Aggregation)
dataframe.agg('min') #각 열의 최솟값
dataframe.agg({'Age':['mean'], 'SexCode':['min','max']})
#age 열의 평균/ sexcode 열의 minmax 를 뱉어냄✳️ 그룹별 집계 예시:
dataframe.groupby(['Pclass','Survived']).agg({'Survived':['count']})groupby() : 데이터를 그룹으로 묶어 통계 계산
agg() : 집계 함수 지정 (평균, 합계, 최솟값 등)
📈 Ch4. 수치형 데이터 다루기 (Sklearn)
4.1 Scaling
수치형 특성이 두 값의 범위 안에 놓이도록 스케일링
MinMaxScaler: 0–1 범위. NN/거리기반에서 추천.- 언제: 신경망(NN → 입력이 0~1로 안정되면 학습이 빠르고 안정적)/ 거리(KNN, SVM, K-means) 기반 모델, 입력 범위를
0–1(또는 -1–1)로 맞추고 싶을 때. - 주의: 훈련 세트로만
fit하고, 훈련/검증/테스트는transform만 해야 데이터 누수 방지.
(fit 메서드를 사용해 특성의 최솟값과 최댓값을 계산한 다음 transform 메서드로 특성의 스케일을 조정)
- 언제: 신경망(NN → 입력이 0~1로 안정되면 학습이 빠르고 안정적)/ 거리(KNN, SVM, K-means) 기반 모델, 입력 범위를
from sklearn.preprocessing import MinMaxScaler
import numpy as np
X = np.array([[-500.5], [-100.1], [0], [100.1], [900.9]])
scaler = MinMaxScaler(feature_range=(0, 1)).fit(X[:3]) # train에만 fit
X_train = scaler.transform(X[:3])
X_test = scaler.transform(X[3:])
-
StandardScaler: 평균0·표준편차1.(가장 기본)-
언제: 선형모델/로지스틱, PCA 등에서 기본값처럼 먼저 시도.
-
팁: 이상치가 많으면 평균/표준편차가 흔들린다 → 아래 RobustScaler 고려.
from sklearn.preprocessing import StandardScaler, RobustScaler X_std = StandardScaler().fit_transform(X) X_rob = RobustScaler().fit_transform(X) # 중앙값/IQR 기반, 이상치에 강함 -
-
Robust/Quantile: 이상치 많거나 분포 왜곡 시.- 언제: 분포가 틀어져 있거나 이상치 영향 최소화하고 싶을 때(0~1 균등 분포에 가깝게).
Scaler 기준 특징 언제 쓰면 좋을까 StandardScaler 평균 0, 표준편차 1 가장 기본. 데이터가 정규분포(종 모양)에 가까울 때 로지스틱 회귀, 선형 회귀, PCA 등 대부분의 선형 모델 RobustScaler 중앙값(median)과 IQR(사분위 범위) 이상치(outlier)에 강함 이상치가 섞여 있는 데이터 QuantileTransformer 분위수(percentile)로 재조정 데이터 분포를 균등하게 펴줌 (0~1 사이로 매끈하게) 분포가 한쪽으로 치우친(skewed) 경우, 이상치 많을 때
- 언제: 분포가 틀어져 있거나 이상치 영향 최소화하고 싶을 때(0~1 균등 분포에 가깝게).
4.2 Normalization
-
포인트: 스케일링이 “열(특성) 단위” 라면, 정규화는 “행(샘플) 단위” 길이(=L2 norm)를 1로 만듦.
즉, “한 데이터 샘플이 벡터로 봤을 때, 그 벡터의 전체 길이를 1로 맞춰주는 것.”샘플 원본 벡터 길이 정규화 후 A [3, 4] √(3²+4²)=5 [0.6, 0.8] B [6, 8] 10 [0.6, 0.8] 결과적으로 A와 B는 같은 방향을 가진 벡터가 됨 -
텍스트 분류/코사인 유사도등에서 자주 사용.

| 구분 | 핵심 포인트 |
|---|---|
| Scaling | 특성(feature) 단위로 크기(단위)를 맞춤 |
| Normalization | 샘플(행) 단위로 벡터의 길이를 1로 맞춤 |
| 이유 | 코사인 유사도처럼 방향 중심 비교 시 중요 |
| 활용 분야 | 텍스트 임베딩, 추천 시스템, 문장/이미지 벡터 비교 등 |
from sklearn.preprocessing import Normalizer
import numpy as np
features = np.array([[0.5, 0.5], [1.1, 3.4], [1.5, 20.2]])
l2_norm = Normalizer(norm="l2").transform(features) # 기본
l1_norm = Normalizer(norm="l1").transform(features) # 합=1
max_norm = Normalizer(norm="max").transform(features) # 행 최대값으로 나눔
4.3 Polynomial & Interaction
-
언제: 비선형성을 간단히 주입하고 싶을 때 (예: 나이², x1·x2 등).
선형 회귀/로지스틱 회귀 등 선형 모델은 기본적으로 "직선/평면"만 학습
그러나 실제 데이터는 굽은 모양(곡선), 변수 간 상호작용이 흔함 → 다항 & 교차항 추가언제 쓰면 좋은가
- 선형 모델(선형회귀, 로지스틱, 선형 SVM)을 쓰고 싶은데 관계가 곡선/상호작용일 때
- 해석성을 유지하면서 비선형성을 조금만 추가하고 싶을 때
- 데이터가 많지 않고 트리/딥러닝까지는 과하다고 느껴질 때
- 국소적 곡률을 반영하고 싶지만 스플라인/핸드메이드 변환이 번거로울 때
언제 굳이 안 써도 되나
- 트리 계열(의사결정나무, 랜덤포레스트, 그레이디언트부스팅)은 자동으로 비선형/상호작용을 학습
- 커널 SVM/가우시안프로세스/딥러닝을 쓰는 경우도 모델 자체가 비선형이어서 안 써도 됨
- 고차원 희소데이터(텍스트 BoW 등)에서 무분별한 교차항은 차원 폭발 위험
-
주의: 차수/특성 수가 늘면 차원의 저주 →
- 특성 수 폭증
- 과적합 (overfitting) 위험 급증
- 계산, 메모리 비용 증가 + 해석 어려움
해결 팁:
- 규제(Regularization): Ridge/Lasso/ElasticNet
- 부분만 확장: 중요한 열만 다항화, degree를 낮게, interaction_only 사용
- 교차검증으로 적정 복잡도 선택
- 표준화(Scaling)로 수치 안정화
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
X = np.array([[2, 3], [2, 3], [2, 3]])
poly = PolynomialFeatures(degree=2, include_bias=False).fit_transform(X) # 제곱+교차항
inter = PolynomialFeatures(degree=2, interaction_only=True, include_bias=False).fit_transform(X) # 교차항만
4.4 Custom/ColumnTransformer
-
열별 서로 다른 변환을 깔끔하게 파이프라인.
🧱 1️⃣ 단순히 새 열 추가하는 방법의 한계물론 아래처럼 직접 처리
df["f1_plus_10"] = df["f1"] + 10 df["f2_plus_100"] = df["f2"] + 100이렇게 했을 때 문제점👇

⚙️ 2️⃣ ColumnTransformer의 역할
ColumnTransformer는 “열마다 다른 전처리기를 묶어서 하나의 통합 변환기” 로 만들어주는 도구 여러 개의 전처리 과정을 “하나의 변환기로 합쳐서”
Pipeline 안에서 fit → transform이 자동으로 돌아가게 해줌
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import FunctionTransformer, StandardScaler, OneHotEncoder
import pandas as pd
import numpy as np
df = pd.DataFrame({
"age": [20, 30, 40],
"income": [2000, 3000, 4000],
"city": ["A", "B", "A"]
})
def add_ten(x): return x + 10
def log_transform(x): return np.log(x)
ct = ColumnTransformer([
("age_plus_10", FunctionTransformer(add_ten), ["age"]),
("income_log", FunctionTransformer(log_transform), ["income"]),
("city_onehot", OneHotEncoder(), ["city"])
])
X_transformed = ct.fit_transform(df)이제 이 변환기를 하나의 객체처럼 모델 파이프라인에 연결하기 👇
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
pipe = Pipeline([
("preprocess", ct),
("model", LinearRegression())
])
pipe.fit(df, y)✅ 장점 요약:
-
fit() / transform()체계 내에서 자동 관리 -
훈련·검증·테스트 데이터에 일관된 변환 적용
-
열마다 다른 변환 지정 가능
-
모델 학습 파이프라인에 바로 통합 가능
-
GridSearchCV/cross_val_score등과 완벽 호환
4.5 Outlier
-
5-1. 감지
통계적 타원 가정(EllipticEnvelope) 또는 IQR 규칙(1.5×IQR)로 간단 감지.from sklearn.covariance import EllipticEnvelope detector = EllipticEnvelope(contamination=0.1).fit(features) labels = detector.predict(features) # 1:정상, -1:이상치import numpy as np x = features[:,0] q1, q3 = np.percentile(x, [25, 75]) iqr = q3 - q1 out_idx = np.where((x < q1 - 1.5*iqr) | (x > q3 + 1.5*iqr)) -
5-2. 다루기
전략 3가지: (1) 삭제(최후의 수단), (2) 플래그로 포함(이상치 여부 이진 특성), (3) 변환(로그 등).
import numpy as np, pandas as pd
houses = pd.DataFrame({
"Price":[534433,392333,293222,4322032],
"Bathrooms":[2,3.5,2,116],
"Square_Feet":[1500,2500,1500,48000]
})
houses["Outlier"] = (houses["Bathrooms"] >= 20).astype(int) # 이상치 플래그
houses["Log_Sqft"] = np.log(houses["Square_Feet"]) # 변환으로 영향 완화
4.6 Discretization
-
언제: 연속형을 구간으로 나눠 범주형처럼 다루고 싶을 때(의사결정트리/규칙 기반 해석 편의).
-
간단 2분할은
Binarizer, 다구간은np.digitize또는KBinsDiscretizer(quantile·uniform).
import numpy as np
from sklearn.preprocessing import Binarizer, KBinsDiscretizer
age = np.array([[6],[12],[20],[36],[65]])
bin_age = Binarizer(threshold=18).fit_transform(age) # 0/1
kb = KBinsDiscretizer(n_bins=4, encode="onehot-dense", strategy="quantile")
age_oh = kb.fit_transform(age) # 구간 원-핫
edges = kb.bin_edges_ # 경계 확인
4.7 Missing
- 8-1. 삭제
대부분의 모델은 NaN 미지원 → 삭제는 간단하지만 정보 손실/편향 가능. (MCAR/MAR/MNAR 구분 고려) - 8-2. 대체(Imputation)
KNNImputer: 소규모 데이터에서 이웃 기반으로 더 정확한 경우 많음(대신 계산량 큼).
SimpleImputer: 평균/중앙값/최빈값으로 빠르게 채움(대규모에 적합).
팁: 결측치를 채운 사실을 나타내는 플래그 특성을 추가하자.
from sklearn.impute import KNNImputer, SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_blobs
import numpy as np
X, _ = make_blobs(n_samples=1000, n_features=2, random_state=1)
X = StandardScaler().fit_transform(X)
true_val = X[0,0]; X[0,0] = np.nan
X_knn = KNNImputer(n_neighbors=5).fit_transform(X) # 정교하지만 느릴 수 있음
X_mean = SimpleImputer(strategy="mean").fit_transform(X) # 빠르고 단순📈 Ch5. 범주형 데이터 다루기 (Sklearn)
머신러닝 모델은 수치형 데이터만 이해할 수 있기 때문에,
문자열(텍스트)로 된 범주형 데이터를 숫자로 변환(인코딩) 해야 합니다.
1️⃣ 범주형 데이터란?
| 구분 | 설명 | 예시 |
|---|---|---|
| 명목형(Nominal) | 순서가 없는 범주 | 성별, 국가명, 브랜드명 |
| 순서형(Ordinal) | 순서가 있는 범주 | 만족도(낮음-보통-높음), 등급(A-B-C) |
범주형 데이터를 숫자로 변환할 때는 순서 유무에 따라 다른 인코딩 방법을 써야 합니다.
2️⃣ 순서가 없는 범주형 데이터 인코딩하기
(1) LabelBinarizer — 단일 클래스 원-핫 인코딩
import numpy as np
from sklearn.preprocessing import LabelBinarizer
feature = np.array([["Texas"], ["California"], ["Texas"], ["Delaware"]])
one_hot = LabelBinarizer()
encoded = one_hot.fit_transform(feature)
print(encoded)
print(one_hot.classes_) # ['California' 'Delaware' 'Texas']
- 각 클래스가 하나의 이진 열(column) 로 변환
- 클래스 간 순서 개념을 만들지 않음
- 원-핫 인코딩 결과의 합은 1 (소속된 클래스 하나만 1)
(2) MultiLabelBinarizer — 다중 클래스 원-핫 인코딩
from sklearn.preprocessing import MultiLabelBinarizer
multi_feature = [("Texas", "Florida"), ("California", "Alabama"), ("Texas", "Florida")]
multi_hot = MultiLabelBinarizer()
multi_encoded = multi_hot.fit_transform(multi_feature)
print(multi_hot.classes_)한 샘플에 여러 클래스가 있을 때 (["Comedy", "Romance"] 등) 사용
(3) Pandas get_dummies — 간편한 더미 인코딩
import pandas as pd
pd.get_dummies(["Texas", "California", "Texas", "Delaware"])데이터프레임에 바로 적용 가능
drop_first=True로 다중공선성(선형 의존성) 방지
(4) OneHotEncoder — 가장 일반적이고 강력한 방식
from sklearn.preprocessing import OneHotEncoder
import numpy as np
feature = np.array([["Texas", 1], ["California", 1], ["Texas", 3]])
encoder = OneHotEncoder(sparse_output=False)
encoded = encoder.fit_transform(feature)
print(encoder.categories_) # 각 열의 클래스 목록
- 문자열과 숫자 모두 처리 가능
- sparse_output=False → 밀집 행렬 반환
- 여러 열 중 특정 열만 인코딩하려면 → ColumnTransformer로 지정
3️⃣ 순서가 있는 범주형 데이터 인코딩하기
(예: Low < Medium < High)
(1) 단순 매핑 (replace)
import pandas as pd
df = pd.DataFrame({"Score": ["Low", "Medium", "High"]})
mapper = {"Low": 1, "Medium": 2, "High": 3}
df["Score_num"] = df["Score"].replace(mapper)수동 매핑은 간단하지만,
클래스 간 간격이 균등하다고 가정하기 때문에 주의 필요.
(2) OrdinalEncoder — 순서형 데이터 전용
from sklearn.preprocessing import OrdinalEncoder
import numpy as np
features = np.array([["Low", 10], ["High", 50], ["Medium", 3]])
encoder = OrdinalEncoder()
encoded = encoder.fit_transform(features)
print(encoder.categories_)순서를 가진 범주를 자동으로 숫자로 변환
특정 열만 적용하려면 ColumnTransformer로 관리
4️⃣ 딕셔너리 형태 인코딩하기
✅ DictVectorizer
from sklearn.feature_extraction import DictVectorizer
data_dict = [{"Red": 2, "Blue": 4}, {"Red": 4, "Blue": 3}, {"Red": 1, "Yellow": 2}]
vec = DictVectorizer(sparse=False)
features = vec.fit_transform(data_dict)
print(vec.get_feature_names_out()) # ['Blue', 'Red', 'Yellow']sparse=False → 밀집 행렬로 출력
자연어 처리에서 단어 빈도(counts) 를 벡터로 바꿀 때 자주 사용
5️⃣ 범주형 결측치 대체하기
(1) KNN으로 예측하여 대체
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
X = np.array([[0, 2.1, 1.4], [1, 1.1, 1.3], [0, 1.2, 1.2], [1, -0.2, -1.1]])
X_nan = np.array([[np.nan, 0.8, 1.3]])
clf = KNeighborsClassifier(3, weights="distance").fit(X[:,1:], X[:,0])
pred = clf.predict(X_nan[:,1:])(2) 최빈값으로 대체
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="most_frequent")
imputer.fit_transform(X)KNN은 정확하지만 느리고, SimpleImputer는 빠르지만 단순.
6️⃣ 불균형 클래스 다루기
| 전략 | 설명 |
|---|---|
| 데이터 수집 | 제일 이상적이지만 현실적으로 어려움 |
| 평가지표 변경 | Accuracy 대신 Recall, F1, AUC 등 사용 |
| 가중치 조정 | class_weight 매개변수 (ex: balanced) |
| 다운샘플링 | 다수 클래스 샘플을 줄임 |
| 업샘플링 | 소수 클래스를 복제하여 늘림 |
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(class_weight="balanced")7️⃣ 핵심 요약
| 주제 | 핵심 포인트 |
|---|---|
| 명목형 인코딩 | 순서 없음 → OneHotEncoder / LabelBinarizer |
| 순서형 인코딩 | 순서 있음 → OrdinalEncoder / 수동 매핑 |
| 딕셔너리 데이터 | DictVectorizer로 빠른 변환 |
| 결측치 처리 | KNN 또는 최빈값으로 대체 |
| 불균형 클래스 | class_weight 조정, 샘플링 전략 |
☁️ 이번주 정리: 행렬과 배열의 개념부터 수치형/범주형 데이터에 따라 어떤 방식으로 전처리 해야하는지 체계적으로 쭉 정리하는 시간을 가진 것 같아서 좋았다. "데이터 전처리" 라는 카테고리로 봤을 땐 후루룩 넘길 수 있는 내용들이지만, 세부적으로 봤을 땐 내용이 상당히 방대해서 하나씩 살펴보며 정리하기 벅찼고 수업도 빨랐다 😧
이번 주차에 정리한 내용을 바탕으로 다음 프로젝트시 참고하여 더 체계적으로 데이터를 처리할 수 있을 듯하다 ❤︎
