카프카 간보기
세미나 발표를 위해 이곳저곳 헤집다가
발견한 유튭 자료를 정리하고 발표 형식으로 바꾸었다
내가 이해가 안되는 부분들은 이렇게 작은 박스에 내 생각과 결론을 찾아 적었다
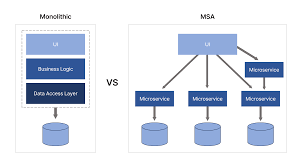
1. monolithic vs MSA
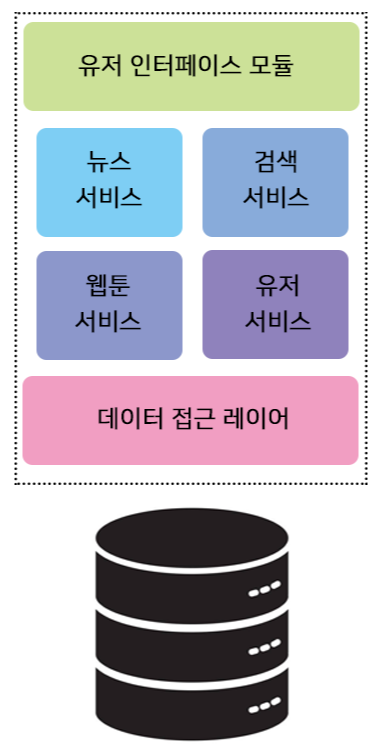
과거 서버들은 하나로 구성돼있는 단일구조였다.
그 구조들은 monolithic이라고 부른다.
이 구조는 하나의 서버에 하나의 데이터베이스를 연결해
모든 서비스를 처리하는 구조이다.
개발 초기에는 관리와 배포가 간단하고
단일 애플리케이션으로 모든걸 처리하기 때문에 인프라 복잡도와 비용이 낮다
하지만 서비스가 커질수록 문제가 생긴다
- 확장과 배포의 단점
- 서비스가 커지면 커질수록 애플리케이션 전체를 확장해야한다.
- 트래픽은 계속 하나의 서버로 들어오므로 특정 기능만 확장하기가 어렵다
- 기술 스택의 제한성
- 기술 스택을 통일시키는건 간단하지만, 새로운 기술 도입은 어렵다.
- 자바에서 의존성을 추가했을때 충돌하게 되는 경우가 이 예시에 해당된다
- 복잡성 증가
- 전체 구조를 이해해야만 안전하게 코드를 수정할 수 있기 때문에 개발자의 진입 장벽이 높아진다.
- 예를들어 대규모 서비스를 유지보수하기 위해 신입 개발자를 투입할 경우 단순한 기능 수정조차 전체 시스템 구조를 파악하는 데 많은 시간이 소요된다.
카프카란 무엇인가
고성능 분산 이벤트 스트리밍 플렛폼
기본 구조
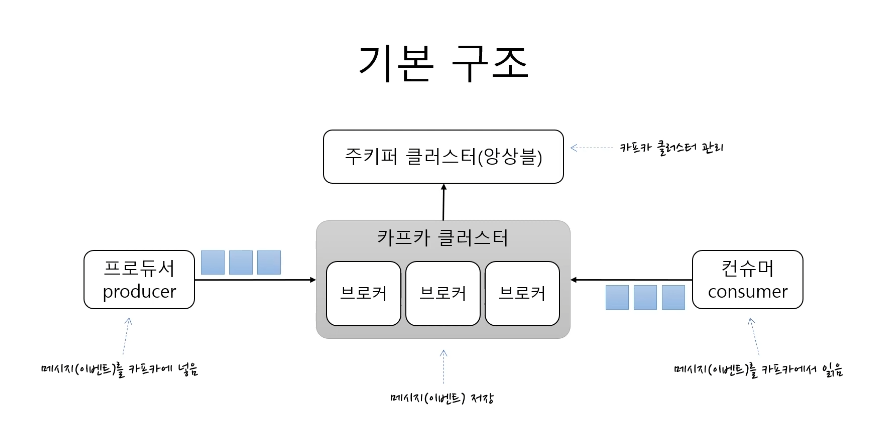
4개의 구성요소
- 카프카 클러스터
- 주키퍼 클러스터(앙상블)
- 프로듀서
- 컨슈머
카프카 클러스터
메시지를 저장하는 저장소
- 여러개의 브로커를 갖고 있음 각각의 서버라고 보면 됨
- 브로커들이 메시지를 나눠서 저장함
- 장애가 나면 대체도 함
주키퍼 클러스터
카프카 클러스터를 관리하는 역할
- 주키퍼 내부에 카프카 클러스터에 대한 정보를 갖고있음
프로듀서
메세지를 카프카에 넣는 역할
컨슈머
메세지를 카프카에서 읽음
토픽과 파티션
토픽 : 메세지를 구분하는 논리적 단위
파티션 : 메세지를 저장하는 물리적 파일
- 한 개의 토픽은 한 개 이상의 파티션으로 구성됨
- 토픽은 폴더라고 보면 됨
- 파티션은 데이터가 실제로 저장되는 장소
파티션과 오프셋, 메시지 순서
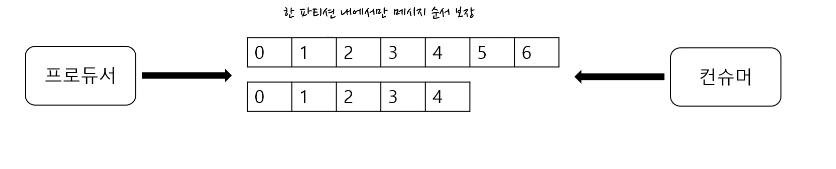
파티션은 추가만 가능한(append-only) 파일
- 각 메세지 저장 위치를 오프셋(offset) 이라고 함
- 프로듀서가 넣은 메세지는 파티션의 맨 뒤에 추가
- 컨슈머는 오프셋 기준으로 메시지를 순서대로 읽음
- 메세지는 삭제되지 않음 (설정에 따라 일정 시간이 지난뒤 삭제)
여러 파티션과 프로듀서
- 프로듀서는 라운드 로빈 또는 키로 파티션 선택
- 같은 키를 갖는 메세지는 같은 파티션에 저장됨 -> 같은 키는 순서를 유지
-
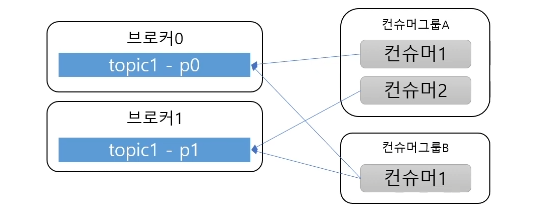
컨슈머는 컨슈머 그룹에 속함
-
한 개 파티션은 컨슈머 그룹의 한 개 컨슈머만 연결 가능
- 컨슈머 그룹에 속한 컨슈머들은 한 파티션을 공유할 수 없음
- 한 컨슈머그룹 기준으로 파티션의 메시지는 순서대로 처리함
이해가 안된부분
Q.왜 그룹은 파티션을 공유하지 않는가 ?
A.예를 들어서
로그인 처리 그룹A가 있고
그룹 안에는 처리담당1,2가 있다고 가정해보자
처리담당 1은 브로커 0의 토픽1-파티션1 을 담당하고
처리담당 2는 브로커 0의 토픽1-파티션2 를 담당하면 분산처리가 가능하므로
같은 그룹끼리는 한개의 파티션을 공유하지 않는다
성능
파티션 파일은 OS 페이지 캐시 사용
- 파티션에 대한 FILE IO를 메모리단에서 처리함
일반적으로는
[어플리케이션 -> OS -> 디스크] 과정을 거쳐 저장한다
근데 카프카가 메시지를 저장할때는 OS의 빈 공간에 먼저 기록하고 나중에 처리함
읽을때도 마찬가지로 OS캐시를 먼저 보고 처리하므로 속도가 빠르다
Zero Copy
- 디스크 버퍼에서 네트워크 버퍼로 직접 복사함
일반적인 데이터 전송 과정
디스크 -> 커널 영역 -> 유저영역 -> 커널영역-> 네트워크 버퍼
카프카는 OS의 sendfile 시스템 콜을 이용
디스크 -> 커널 -> 네트워크 영역
CPU가 데이터를 유저영역으로 복사하지 않으므로 일이 줄어듦 그래서 Zero Copy
- 브로커가 하는 일이 비교적 단순함
- 메시지 필터, 메시지 재전송과 같은 일은 브로커가 안하고 프로듀서, 컨슈머가 직접 함
- 브로커는 컨슈머와 파티션 간 매핑 관리만 해줌
- 배치처리
- 프로듀서 : 일정 크기만큼 메시지를 모아서 전송 가능
- 컨슈머 : 최소 크기만큼 메시지를 모아서 조회 가능
- 수평 확장이 용이함
- 브로커 , 파티션 추가가 쉬움
- 컨슈머가 느림 -> 컨슈머 추가
리플리카 - 복제
리플리카 : 파티션의 복제본
- 복제수 만큼 파티션의 복제본이 각 브로커에 생김
리더와 팔로워로 구성 - 프로듀서와 컨슈머는 리더를 통해서만 메시지 처리
- 팔로워는 리더로부터 복제함
장애 대응- 리더가 속한 브로커 장애시 다른 팔로워가 리더가 됨
