딥러닝
1.DyGIE++ 관계 추출 모델
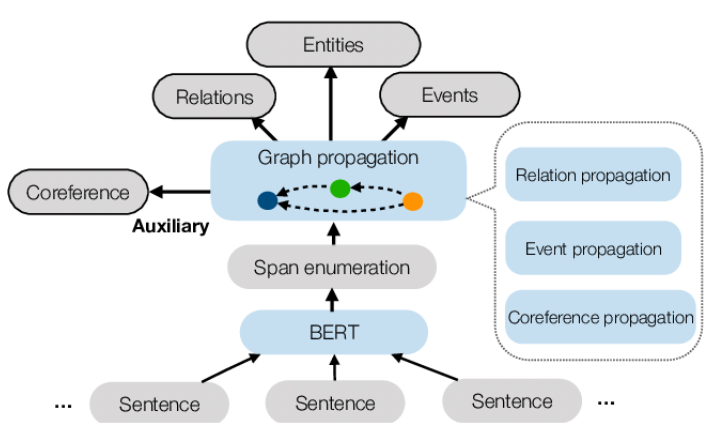
1. 개요 > https://github.com/dwadden/dygiepp 모델 이름 : DyGIE++ (Dynamic Graph-based Information Extraction Plus Plus) 베이스 모델 : BERT / ELMo 등 Pre-trained
2025년 5월 15일
2.Korean-Sentence-Embedding 모델

1. 개요 > https://huggingface.co/BM-K/KoSimCSE-roberta-multitask 모델 이름 : BM-K/KoSimCSE-roberta-multitask 베이스 모델 : KoRoBerta 언어 : 한국어 특화 (Korean-only) 종
2025년 5월 1일
3.강화학습 - PPO 알고리즘
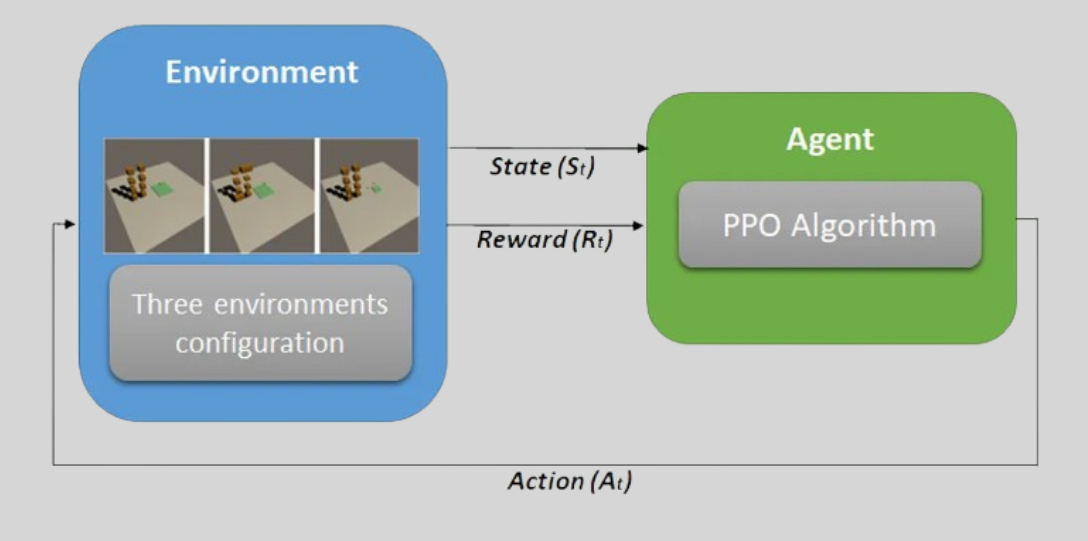
1. PPO란? PPO는 Proximal Policy Optimization의 약자로, 정책 기반(policy-based) 강화학습 알고리즘이다. 이는 기존의 TRPO(Trust Region Policy Optimization) 알고리즘의 안정성과 DQN(Deep Q
2025년 6월 1일