📌 BasisFormer: Attention-based Time Series Forecasting with Learnable and Interpretable Basis
📝 저자 : Zelin Ni, Hang Yu, Shizhan Liu, Jianguo Li, Weiyao Lin
📅 발행 연도 : Submitted on 31 Oct 2023 (v1), last revised 18 Jan 2024 (this version, v2)
🔗 논문 링크 : https://arxiv.org/abs/2310.20496
1. Introduction (서론)
🔸 연구 배경 및 필요성
시계열 데이터는 금융, 헬스케어, 에너지, 교통 등 다양한 분야에서 중요한 역할을 하며, 이를 예측하는 모델은 산업적으로도 큰 가치를 가진다. 최근 Transformer 기반 시계열 모델들이 발전했지만, 기존 모델들은 다음과 같은 한계를 가지고 있다.
1️⃣ 기저(Basis) 문제
기존 시계열 예측 모델들은 주로 고정된 기저 함수(Fourier, Legendre 등) 를 사용하여 시계열 패턴을 표현한다. 하지만, 이러한 사전 정의된 기저는 특정 데이터셋에 최적화되지 않아 일반화 성능이 낮을 수 있다는 문제점을 가지고 있다.
2️⃣ 기저와 시계열 간의 유연한 관계 부족
Transformer 기반 모델들은 고정된 임베딩(embedding)을 사용하여 시계열과 기저 간의 관계를 조정하는 데 한계가 있다. 즉, 데이터별로 적절한 기저를 선택하는 능력이 부족하다는 것이다.
🏆 연구 목표
- 학습 가능한 기저를 활용해 시계열 패턴을 해석 가능하게 모델링
- 자기지도학습(Self-Supervised Learning)을 통해 최적의 기저를 자동으로 학습
- Transformer 기반 구조를 활용하면서도 기존 모델 대비 더 나은 성능과 해석 가능성 제공
2. Related Work (관련 연구)
기존 시계열 모델과 비교
기존 시계열 예측 모델들은 크게 통계적 방법, RNN/LSTM 기반 모델, Transformer 기반 모델로 나눌 수 있다.
| 모델 유형 | 주요 기법 | 한계점 |
|---|---|---|
| 통계적 모델 | ARIMA, ETS | 비선형 패턴을 학습하기 어려움 |
| RNN 기반 | LSTM, GRU | 긴 시퀀스 학습 시 장기 의존성 문제 발생 |
| Transformer 기반 | FEDformer, Autoformer, N-HiTS | 고정된 기저를 사용하여 데이터 적응력이 낮음 |
❗ BasisFormer는 Transformer 기반 모델의 한계를 해결하면서도, 기존 모델보다 높은 성능과 해석 가능성을 제공한다.
3. Methodology (기법 소개: BasisFormer 모델)
🔸 BasisFormer의 핵심 아이디어
기저(Basis)를 학습하는 새로운 시계열 모델로, Transformer의 강력한 성능을 유지하면서도 시계열 데이터에 적합한 기저를 자동으로 학습하도록 설계되었다.
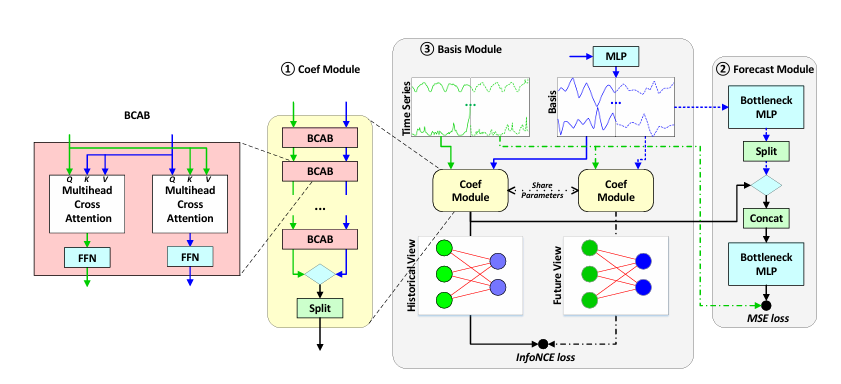
🔸 모델 구조
BasisFormer는 3가지 주요 모듈로 구성되어 있다.
1️⃣ 계수 계산 모듈 (Coef Module)
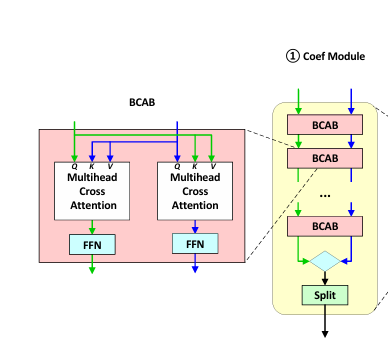
- Bidirectional Cross-Attention Block(BCAB)을 활용하여 시계열 데이터와 기저 간의 유사도를 계산
Bidirectional Cross-Attention Block (BCAB)
◾ 시계열 데이터의 장기 의존성을 효과적으로 학습하기 위해 사용되는 모듈
◾ 기존 Transformer 구조의 Self-Attention은 한 시퀀스 내의 요소들 간의 관계를 학습하는 반면, Cross-Attention은 서로 다른 두 시퀀스 간의 관계를 학습하는 데 초점
1. Bidirectional (양방향)
단순히 하나의 시퀀스를 대상으로 Attention을 수행하는 것이 아니라, 두 개의 입력을 동시에 고려하여 정보를 주고받는다.
2. Cross-Attention (교차 주의 메커니즘)
Query를 통해 한 시퀀스의 정보를 기준으로 하고, Key & Value를 통해 다른 시퀀스에서 정보를 가져온다. 즉, 상호작용을 통해 더 의미 있는 특징을 추출하게 된다.
3. BCAB는 시계열 예측에 적합한 구조
단순히 한 방향으로 정보를 학습하는 것이 아니라, 양방향에서 정보를 주고받으며 정교한 패턴을 학습할 수 있다. 또한, 시계열 데이터에서 흔히 발생하는 긴 범위(long-range) 의존성을 잘 반영한다.
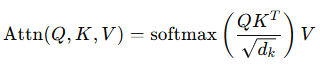
-
데이터에 따라 적절한 기저를 선택할 수 있도록 학습
-
기존 Transformer 모델이 가진 고정 임베딩 문제를 해결
고정된 위치 임베딩(Fixed Positional Encoding)의 문제
: Transformer는 입력 순서를 고려하지 않는 구조(Self-Attention) 때문에, 위치 정보를 추가적으로 인코딩해야 하는 문제가 존재한다.
1. 데이터 길이가 달라지면 일반화가 어렵다.
2. 추론 시, 학습하지 않은 길이의 데이터에 적용할 수 없다.
3. 고정적인 패턴이므로 데이터의 변화에 적응하지 못한다.
💡 데이터 기반의 학습 가능한 위치 임베딩(Learnable Positional Encoding)을 사용하여 데이터의 특성에 맞게 위치 정보를 최적화할 수 있도록 하였고, Bidirectional Cross-Attention Block (BCAB)을 활용하여 위치 정보를 더 효과적으로 반영함으로써 위 문제들을 해결하였다.
2️⃣ 예측 모듈 (Forecast Module)
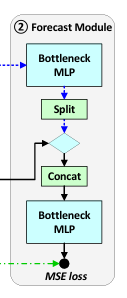
Bottleneck MLP
: 입력 → 저차원 병목층(Bottleneck Layer) → 다시 확장 → 출력
즉, 차원을 한 번 줄였다가 다시 확장하는 구조이다. 이를 통해 중요한 특징만 추출하고, 불필요한 정보는 필터링하는 효과가 있다.
-
학습된 기저와 유사도를 활용하여 미래 데이터를 예측
-
기존 Transformer 모델 대비 더 높은 정확도와 해석 가능성 제공
3️⃣ 기저 학습 모듈 (Basis Module)
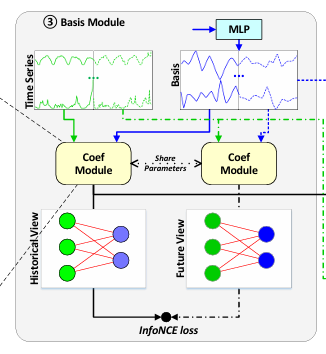
-
자기지도학습(Self-Supervised Learning) 방식으로 데이터에서 학습 가능한 기저(basis) 를 자동으로 추출
자기지도학습 (Self-Supervised Learning)
: 데이터 자체에서 학습 신호(레이블)를 생성하여 지도학습(Supervised Learning)처럼 학습하는 기법
즉, 라벨이 없는 데이터(Unlabeled Data)를 활용하면서도, 지도학습처럼 학습이 가능하도록 만드는 방법을 말한다.학습 방식 필요 데이터 특징 지도학습 (Supervised Learning) 입력(𝑋) + 정답(𝑌) 필요 라벨이 필요하지만 성능이 좋음 비지도학습 (Unsupervised Learning) 입력(𝑋)만 필요 패턴을 찾지만 정답이 없음 자기지도학습 (Self-Supervised Learning) 입력(𝑋)만 필요 (라벨 없이 학습 가능) 입력 데이터에서 라벨을 생성하여 학습
-
대조학습(Contrastive Learning) 기법을 활용하여 다른 시점의 시계열 데이터를 서로 비교하며 의미 있는 기저를 학습
InfoNCE(Info Noise Contrastive Estimation) Loss
: Contrastive Learning에서 널리 사용되는 손실 함수
1. Anchor(기준 샘플)와 Positive(유사한 샘플)을 가깝게 만든다.
2. Anchor와 Negative(무작위 샘플)은 멀어지도록 학습시킨다.
3. Softmax 기반 확률 모델링을 사용해, Positive 샘플이 선택될 확률을 최대화한다.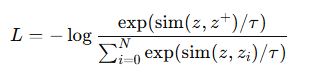
z : Anchor의 표현 벡터
z+ : Positive 샘플의 표현 벡터
zi : Negative 샘플들의 표현 벡터
sim(a,b) : 두 벡터 간 유사도 (보통 cosine similarity 사용)
τ : Temperature Parameter (Softmax 스케일링)
N : Negative 샘플 개수
- 기존의 사전 정의된 기저보다 데이터에 맞게 최적화 가능
👍 기존 Transformer 모델들은 고정된 기저를 사용했다면, BasisFormer는 데이터에 따라 유연하게 기저를 학습할 수 있도록 설계되었다 !
4. Experiments (실험 결과 분석)
🔸 실험 데이터셋
BasisFormer는 6가지 대규모 시계열 데이터셋에서 평가되었다.
1. ETT
2. Electricity
3. Exchange
4. Traffic
5. Weather
6. Illness
🔸 성능 비교 (MSE 기준, 작을수록 좋음)
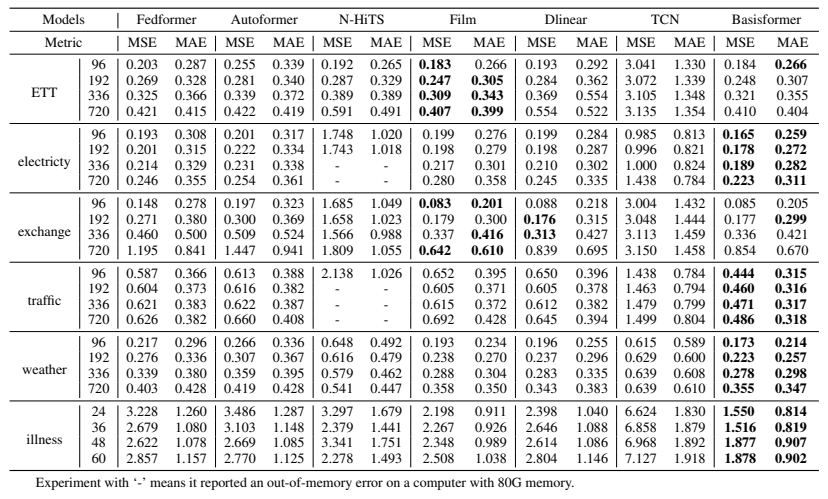
❗ BasisFormer가 대부분의 데이터셋에서 기존 Transformer 기반 모델보다 높은 성능을 기록 !
5. Ablation Study (세부 실험 분석)
- 실험 1 : 학습 가능한 기저 vs 고정된 기저
기존 Fourier, Sine/Cosine 기저 대비 5~10% 성능 향상
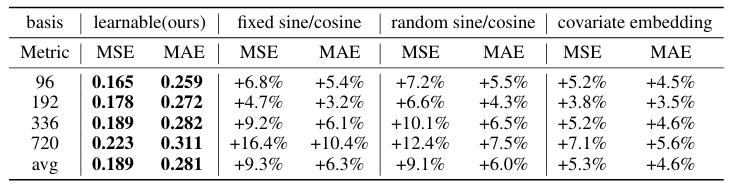
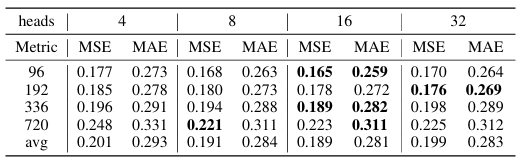
- 실험 2 : 다중 헤드 개수 영향 분석
16개 헤드 사용 시 최고 성능
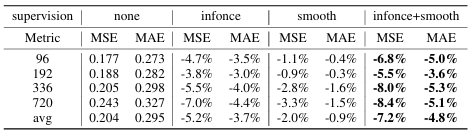
- 실험 3 : 대조 학습(Contrastive Learning) 적용 효과
InfoNCE Loss(Info Noise Contrastive Estimation) 적용 시 7.2% 성능 향상
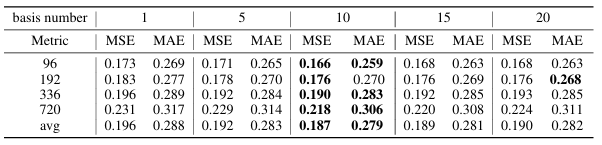
- 실험 4 : 기저 개수의 영향
너무 많으면 비슷한 기저가 학습되는 문제 발생
6. Conclusion (결론 및 향후 연구 방향)
🔸 결론
- 기존 시계열 모델이 가진 고정 기저 문제를 해결하는 새로운 접근 방식 제안
- 자기지도학습을 통해 데이터 효율성을 극대화
- 다양한 데이터셋에서 강력한 성능 입증
- 해석 가능성(Interpretability) 향상 → 실제 산업 응용 가능성 증가
🔸 향후 연구 방향
- 학습 가능한 기저 개념을 다른 Transformer 모델과 결합하는 연구 가능
- 금융, 헬스케어 등 도메인 특화 모델로 발전 가능
- 기존 시계열 모델을 개선하는 범용적 기법으로 확장 가능
💭 My Thoughts
- 시계열에 대해서 데이터 분석 · AI 프로젝트를 진행하면서 성능 향상에 어려움을 겪었던 경험이 있어서 해당 논문을 리뷰하기로 결정했던 것인데, 다음에 시계열 프로젝트를 진행할 때는 해당 논문의 BasisFormer를 사용해보면 좋을 것 같다.
- 또한, 프로젝트를 진행하면서 분석하는 데이터의 특성에 걸맞는 모델이 어떤 것인지에 대한 고민이 많았었는데, 해당 모델을 사용하게 된다면 이러한 고민이 해소될 것이라고 본다.
