📌 Lost in Sequence: Do Large Language Models Understand Sequential Recommendation?
📝 저자 : Sein Kim, Hongseok Kang, Kibum Kim, Jiwan Kim, Donghyun Kim, Minchul Yang, Kwangjin Oh, Julian McAuley, Chanyoung Park
📅 발행 연도 : Submitted on 19 Feb 2025 (v1), last revised (this version, v4)
🔗 논문 링크 : https://arxiv.org/abs/2502.13909
Abstract
이 논문에서는 LLM 기반 추천 시스템(LLM4Rec)이 순차적 추천(Sequential Recommendation) 시나리오에서 사용자의 아이템 상호작용 시퀀스에 내재된 순서 정보를 실제로 이해하는지를 실험적으로 검증한다.
기존 LLM4Rec 모델들(TALLRec, LLaRA, CoLLM, A-LLMRec 등)은 순차적 추천 태스크를 위해 설계되었음에도 불구하고,
- 학습 시퀀스를 랜덤으로 셔플해도 성능 변화가 거의 없음
- 추론 시에도 셔플된 시퀀스에 대해 성능 저하가 미미함
- 사용자 표현(user representation)이 셔플 전후로 매우 유사함
등의 문제가 발견되었다.
TALLRec(Tuning LLMs as An Effective and Lightweight LLM-based Recommender)(Bao et al., 2023)
: LLM을 추천 태스크에 적응시키기 위해 LoRA 기반 파인튜닝을 수행한 초기 모델이다. 아이템의 텍스트 정보(제목 등)만 활용하며, 사용자에게 "이 아이템을 좋아할까? YES/NO"를 묻는 이진 분류 방식으로 추천을 수행한다. 텍스트에만 의존하기 때문에 상호작용이 풍부한 warm 시나리오에서 상대적으로 약한 성능을 보인다.
LLaRA(Large Language-Recommendation Assistant)(Liao et al., 2024)
: 아이템의 텍스트 임베딩과 CF-SRec(Collaborative Filtering-based Sequential Recommender)(SASRec 등)의 아이템 임베딩을 결합하여 LLM 프롬프트에 제공하는 모델이다. LoRA로 LLM을 파인튜닝하며, 추천할 아이템의 제목을 직접 생성(Next Item Title Generation)하는 방식을 사용한다. 텍스트 + 협업 필터링 정보를 동시에 활용하려는 시도이다.
CoLLM(Collaborative LLM)(Zhang et al., 2023)
: CF-SRec에서 추출한 사용자 표현(user representation)을 LLM 프롬프트에 직접 삽입하여 협업 필터링 지식을 LLM에 주입하는 모델이다. TALLRec처럼 "이 아이템을 좋아할까?"에 대한 이진 분류(YES/NO) 방식으로 동작하며, LoRA로 LLM을 파인튜닝한다.
A-LLMRec(Aligning LLM-based Recommender)(Kim et al., 2024)
: CF-SRec의 아이템 임베딩과 사용자 표현을 모두 LLM 프롬프트에 통합하되, 아이템 설명(description)까지 잠재 공간에 포함시켜 더 풍부한 정보를 활용하는 모델이다. 기존 모델들과 달리 LLM 자체를 파인튜닝하지 않고, 프로젝션 레이어(MLP)만 학습하여 LLM과 CF-SRec을 정렬(align)한다. Warm/Cold 시나리오 모두에서 강건한 성능을 보인다.
이를 해결하기 위해, 사전 학습된 CF 기반 순차 추천 모델(CF-SRec)로부터 순차적 지식을 LLM에 증류(distillation)하는 LLM-SRec을 제안한다.
❗ LLM이 텍스트 이해는 잘 하지만, 아이템 상호작용의 "순서"는 제대로 파악하지 못한다는 점을 실증적으로 밝히고, 이를 해결하는 경량 프레임워크를 제안한 연구
1. Introduction
기존 LLM4Rec의 한계
LLM은 뛰어난 텍스트 이해 능력과 문맥 인식 능력 덕분에 추천 시스템에서 유망한 도구로 부상했다. 기존 연구들은 다양한 방식으로 LLM을 추천에 활용하고자 했다.
- TALLRec : LoRA 기반 LLM 파인튜닝으로 추천 태스크에 적응
- LLaRA, CoLLM : CF-SRec의 아이템 임베딩을 텍스트 임베딩과 결합
- A-LLMRec : 아이템 설명까지 잠재 공간에 통합
그러나, 이 모델들이 순차적 추천 시나리오에서 학습·평가됨에도 불구하고, 시퀀스 내 순서 정보를 실제로 이해하는지는 간과되어 왔다.
핵심 발견 : LLM4Rec은 순서를 모른다
저자들은 두 가지 핵심 실험을 통해 충격적인 결과를 도출한다.
1) 셔플된 시퀀스로 학습/추론
- 시퀀스의 아이템 순서를 랜덤으로 셔플하면 순차적 의존성이 파괴됨
- 그럼에도 LLM4Rec 모델들의 성능은 거의 변하지 않음 ← 순서 정보를 활용하지 못한다는 증거
- 반면, SASRec(CF-SRec)은 셔플 시 성능이 크게 하락 ← 순서를 제대로 활용하고 있다는 증거
2) 표현 유사도(Representation Similarity)
- 원본 시퀀스와 셔플 시퀀스에서 추출한 사용자 표현의 코사인 유사도를 측정
- LLM4Rec 모델들은 유사도가 매우 높음 ← 시퀀스 변화에 둔감
- SASRec은 유사도가 상대적으로 낮음 ← 시퀀스 변화에 민감하게 반응
❗ LLM4Rec 모델들은 순차적 추천을 한다고 하면서도, 실제로는 순서 정보를 거의 활용하지 못하고 있었다.
LLM-SRec의 핵심 아이디어
위 발견에 기반하여 LLM-SRec을 제안한다.
- 사전 학습된 CF-SRec(예: SASRec)에서 추출한 사용자 표현을 LLM에 증류
- CF-SRec도, LLM도 파인튜닝하지 않음 → 경량 MLP만 학습
- 기존 LLM4Rec 대비 학습/추론 효율성이 크게 향상
2. Do Existing LLM4Rec Models Understand Sequences?
2.1 Preliminaries
순차적 추천의 정의 (CF-SRec)
- 사용자 집합 U, 아이템 집합 I가 주어짐
- 사용자 u의 아이템 상호작용 시퀀스 Sᵤ = (i₁⁽ᵘ⁾, ..., iₙᵤ⁽ᵘ⁾)
- 목표 : p(iₙᵤ₊₁⁽ᵘ⁾ | Sᵤ) → 다음에 상호작용할 아이템을 예측
LLM4Rec의 두 가지 접근법
| 접근법 | 설명 |
|---|---|
| Next Item Title Generation (생성적 접근) | 사용자 시퀀스와 후보 아이템 목록을 프롬프트로 제공 → LLM이 추천 아이템의 제목을 생성 |
| Next Item Retrieval (검색적 접근) | LLM에서 사용자 표현과 아이템 임베딩을 추출 → 내적 유사도로 후보 중 가장 유사한 아이템을 검색 |
기존 LLM4Rec 모델들은 보통 하나의 접근법만 사용하지만, 이 논문에서는 두 가지 접근법 모두에 대해 분석을 수행한다.
2.2 Evaluation Protocol
- Leave-last-out 방식 사용
- 마지막 아이템 → 테스트 데이터
- 끝에서 두 번째 아이템 → 검증 데이터
- 나머지 → 학습 데이터
- Title Generation : 1 positive + 19 negative 후보
- Item Retrieval : 1 positive + 99 negative 후보
2.3 Preliminary Analysis
2.3.1 Shuffled Training
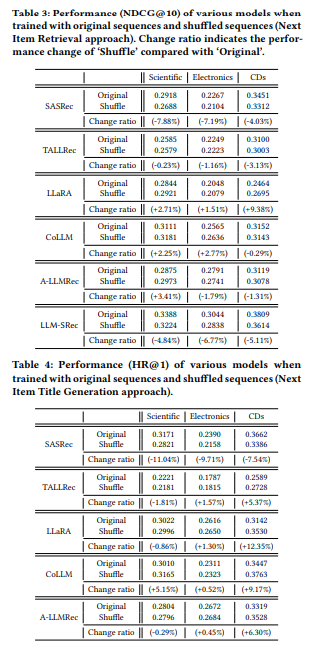
가설 : 순서 정보를 이해하는 모델이라면, 셔플된 시퀀스로 학습 시 원본 테스트에서 성능이 하락해야 한다.
결과 :
- SASRec : 셔플 학습 시 성능이 예상대로 크게 하락
- LLM4Rec 모델들 : 성능 변화가 거의 없거나, 오히려 향상되는 경우도 존재
- 일부 경우 랜덤 셔플이 단기 co-occurrence 패턴을 우연히 생성할 수 있음
- LLM은 장기 의존성(long-term dependency) 포착에 약함
→ LLM4Rec 모델들은 학습 단계에서 순차적 정보를 제대로 활용하지 못한다.
2.3.2 Shuffled Inference
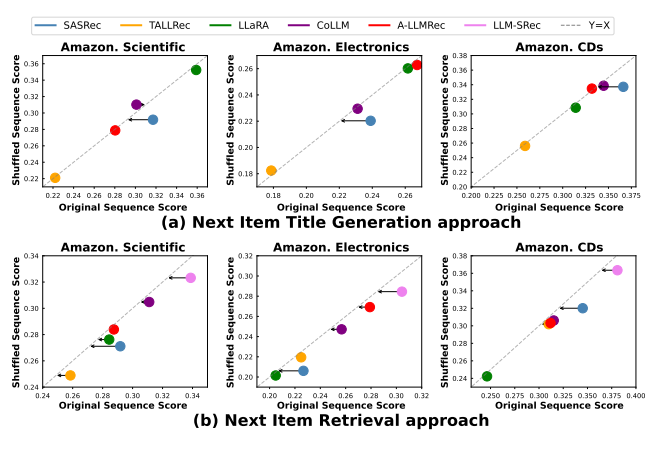
가설 : 원본 시퀀스로 학습된 모델이라면, 추론 시 셔플된 시퀀스에 대해 성능이 하락해야 한다.
결과 :
- SASRec : 성능이 크게 하락
- LLM4Rec 모델들 : y=x 선 근처에 위치 = 성능 변화 거의 없음
- CoLLM, A-LLMRec도 CF-SRec의 사용자 표현을 활용하지만, 여전히 순차 정보 포착 실패
→ LLM4Rec 모델들은 추론 단계에서도 순차적 정보를 활용하지 못한다.
2.3.3 Representation Similarity
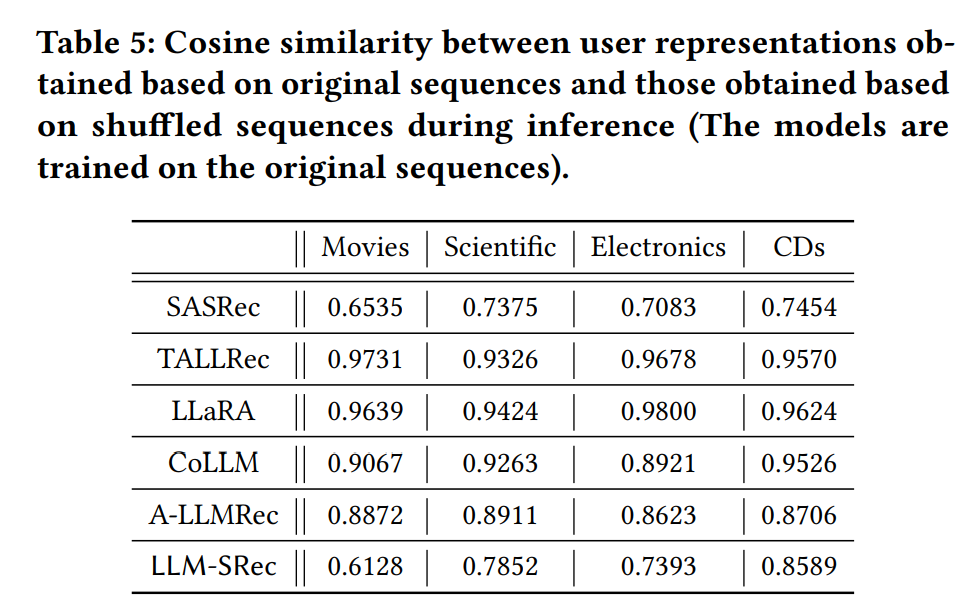
가설 : 순차 정보를 잘 포착하는 모델이라면, 시퀀스가 바뀔 때 사용자 표현도 크게 변해야 한다.
결과 :
- SASRec : 낮은 코사인 유사도 → 시퀀스 변화에 민감
- LLM4Rec 모델들 : 매우 높은 코사인 유사도 → 시퀀스 변화가 표현에 거의 영향 없음
- CoLLM, A-LLMRec은 CF-SRec의 사용자 표현을 프롬프트에 포함하여 상대적으로 낮은 유사도를 보이나, 여전히 SASRec보다 높음
→ LLM4Rec이 CF-SRec의 사용자 표현을 단순히 프롬프트에 주입하는 것만으로는 순차 정보를 충분히 반영할 수 없다. 더 효과적인 증류 방식이 필요하다.
3. Methodology: LLM-SRec
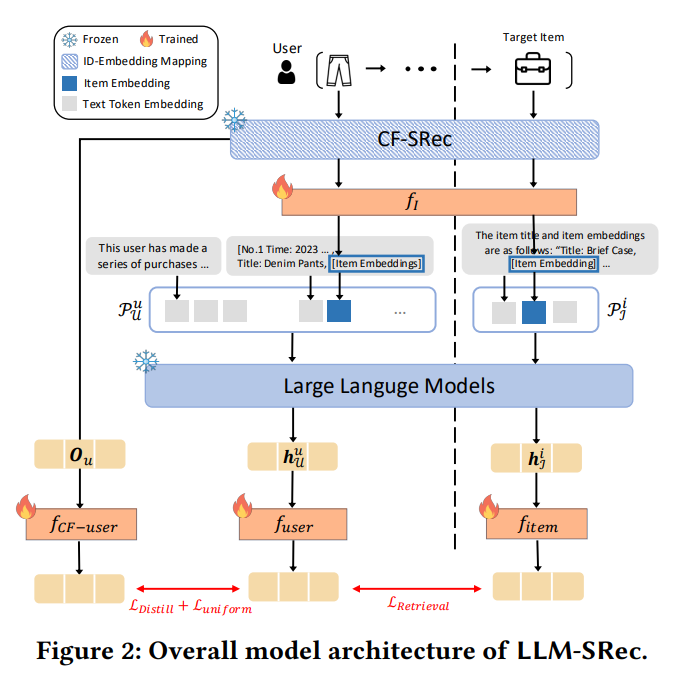
LLM-SRec은 Next Item Retrieval 접근법을 채택한다.
Next Item Title Generation 접근법은 후보 아이템 수 제한, 후보 아이템의 위치 편향(position bias) 등 잘 알려진 단점이 존재한다.
3.1 Distilling Sequential Information
핵심 아이디어 : CF-SRec에서 추출한 사용자 표현을 LLM의 사용자 표현에 증류(distillation)
- CF-SRec의 사용자 표현 : Oᵤ = CF-SRec(Sᵤ) (사전 학습 후 고정)
- LLM의 사용자 표현 : hᵤ ([UserOut] 토큰의 last hidden state)
- 증류 손실(Distillation Loss) :
ℒ_Distill = MSE(f_CF-user(Oᵤ), f_user(hᵤ))
- f_CF-user와 f_user는 각각 2-layer MLP로, CF-SRec 표현과 LLM 표현을 동일한 차원의 공간으로 매핑
- CF-SRec과 LLM 모두 파인튜닝 없이, MLP만 학습하는 구조
❗ 기존 CoLLM, A-LLMRec은 CF-SRec의 사용자 표현을 프롬프트에 직접 삽입했으나 실패함 → LLM-SRec은 MSE 기반 증류로 표현 공간 자체를 정렬하는 것이 핵심 차이
3.2 Preventing Over-smoothing
단순 MSE 손실만 적용하면 과도한 평활화(over-smoothing) 문제가 발생할 수 있다. 즉, 서로 다른 사용자의 표현이 지나치게 유사해지는 현상.
이를 방지하기 위해 균일성 손실(Uniformity Loss)을 도입한다.
ℒ_Uniform : 서로 다른 사용자의 표현이 정규화된 특징 공간(hypersphere)에서 균일하게 분포하도록 촉진
최종 목적 함수
ℒ_Total = ℒ_Retrieval + ℒ_Distill + ℒ_Uniform
LLM-SRec의 학습 효율성 :
- CF-SRec : 추가 학습 없음 (frozen)
- LLM : 추가 학습 없음 (frozen)
- 학습 대상 : 소수의 MLP 레이어 (f_I, f_user, f_CF-user, f_item) + 2개의 LLM 토큰 ([UserOut], [ItemOut])
→ LoRA 기반 파인튜닝이 필요한 기존 LLM4Rec 모델들 대비 학습/추론 시간이 대폭 단축됨
4. Experiments
실험 설정
- 데이터셋 : Amazon 리뷰 데이터셋 4종 (Movies, Scientific, Electronics, CDs)
- 5-core 필터링 적용 (최소 5개 상호작용)
- 백본 LLM : LLaMA 3.2 (3B-Instruct) (전 모델 공통)
- CF-SRec : SASRec (CoLLM, LLaRA, A-LLMRec, LLM-SRec 공통)
- 평가 지표 : NDCG@N, HR@N (N=10, 20)
- 베이스라인 :
- CF-SRec : GRU4Rec, BERT4Rec, NextItNet, SASRec
- LM-based : CTRL, RECFORMER
- LLM4Rec : TALLRec, LLaRA, CoLLM, A-LLMRec
4.1 Recommendation Performance Comparison
4.1.1 Overall Performance
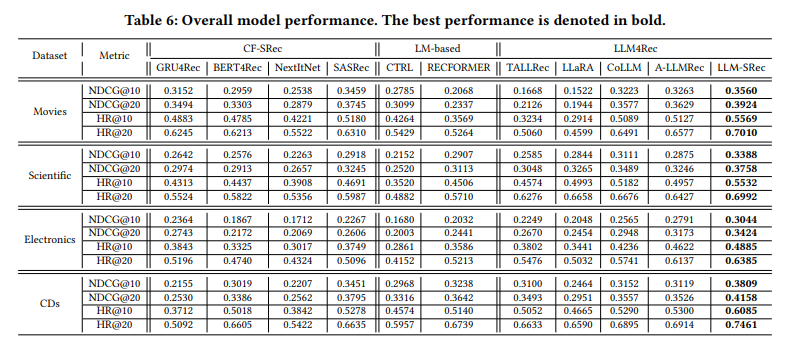
- LLM-SRec이 모든 데이터셋에서 기존 LLM4Rec 모델들을 일관되게 상회
- LLM-SRec은 CF-SRec 및 LM-based 모델들도 능가
- CF-SRec를 활용하는 LLM4Rec 모델(LLaRA, CoLLM, A-LLMRec)은 TALLRec보다 낫지만, SASRec과 비슷한 수준에 그침
→ CF 지식을 단순히 프롬프트에 넣는 것만으로는 한계가 있으며, 증류를 통한 순차 정보 통합이 핵심
4.1.2 Transition & Non-Transition Sequences
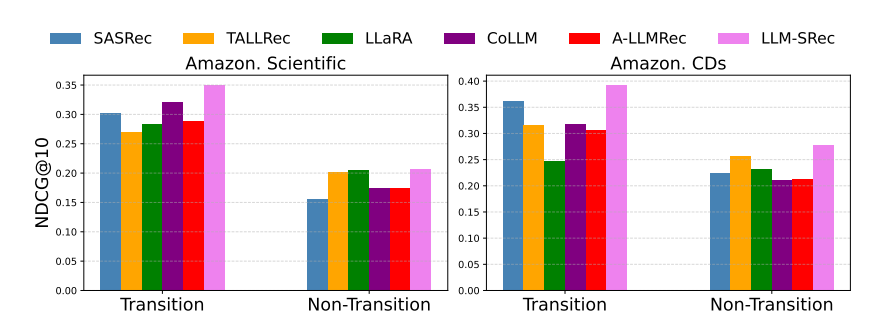
사용자를 순차적 전환 점수(t-score)에 따라 분류:
- Transition Set (상위 50%) : 순차 정보가 풍부한 사용자
- Non-Transition Set (하위 50%) : 순차 정보가 빈약한 사용자
결과 :
- LLM-SRec은 특히 Transition Set에서 성능 차이가 더 큼 → 순차 정보를 효과적으로 활용
- Non-Transition Set에서는 기존 LLM4Rec과의 성능 차이가 줄어듦 → 기존 모델들이 순차 의존성 포착에 실패함을 재확인
4.1.3 Warm/Cold Scenarios
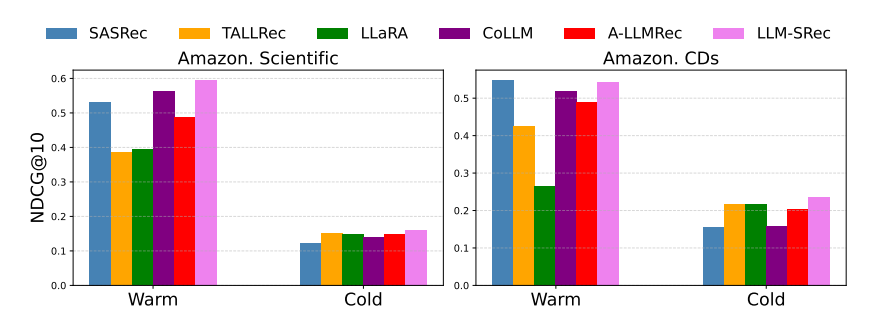
- Warm 아이템 (상호작용 상위 35%) : LLM-SRec이 일관되게 우수
- Cold 아이템 (상호작용 하위 35%) : LLM-SRec이 LLM의 사전 학습 지식과 텍스트 이해력을 잘 활용하여 우수한 성능
- SASRec은 cold 아이템에서 특히 취약 (상호작용 데이터에만 의존)
4.1.4 Cross-domain Scenarios
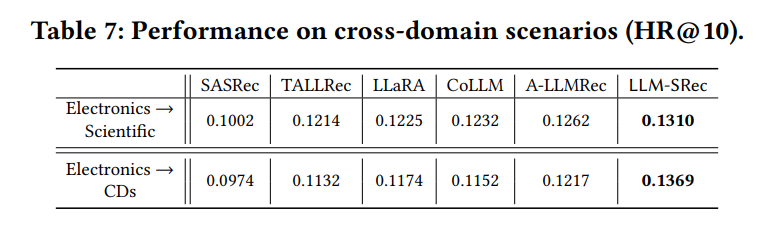
- Electronics로 학습 → Scientific, CDs에서 평가
- LLM-SRec이 cross-domain에서도 일관되게 최고 성능
- 텍스트 이해력 + 순차 정보의 결합이 미인 아이템에 대한 일반화를 가능하게 함
4.2 Ablation Studies
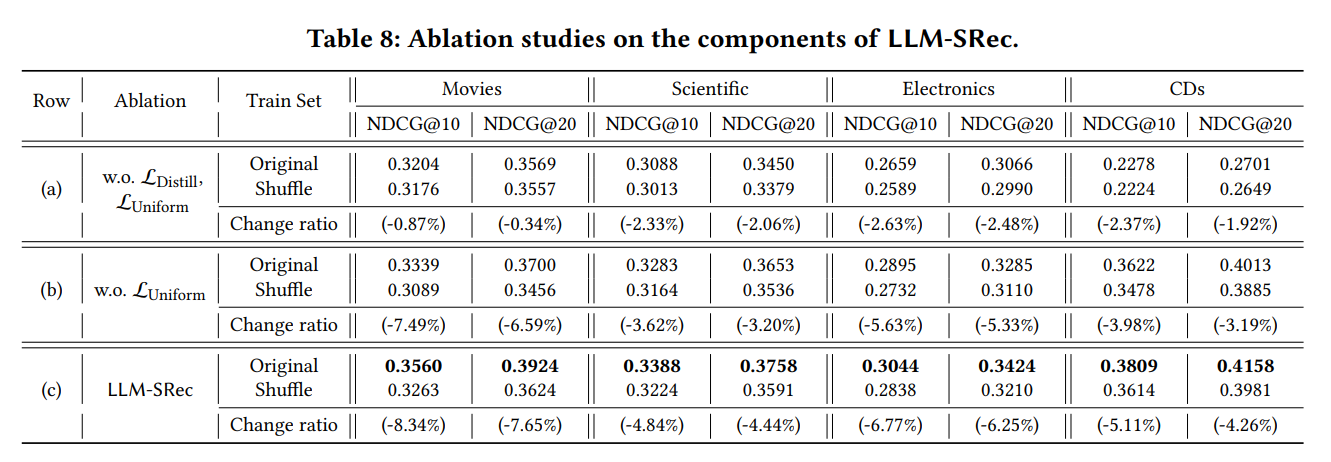
| 구성 | 설명 | 결과 |
|---|---|---|
| (a) ℒ_Retrieval만 | 증류·균일성 손실 없음 | 원본 시퀀스에서 최저 성능, 셔플 시 성능 하락 미미 (순서 이해 X) |
| (b) ℒ_Retrieval + ℒ_Distill | 균일성 손실 없음 | over-smoothing으로 성능 저하, 하지만 셔플 시 성능 크게 하락 (순서 이해 O) |
| (c) Full LLM-SRec | 모든 손실 포함 | 원본에서 최고 성능, 셔플 시 성능 하락 가장 큼 (순서 이해 가장 우수) |
→ ℒ_Distill이 순서 이해 능력을 부여하고, ℒ_Uniform이 over-smoothing을 방지하여 최종 성능을 극대화
4.3 Model Analysis
4.3.1 Train/Inference Efficiency
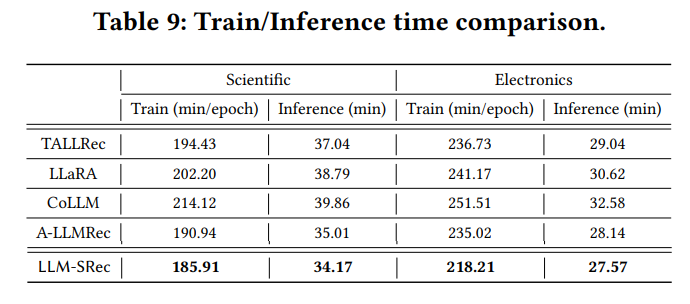
- LLM-SRec이 모든 LLM4Rec 베이스라인 대비 학습·추론 시간이 크게 단축됨
- LoRA 기반 파인튜닝이 필요한 TALLRec, LLaRA, CoLLM은 오버헤드가 큼
- A-LLMRec도 2단계 학습 + 긴 프롬프트로 인해 비효율적
→ LLM-SRec은 MLP만 학습하므로 실제 서비스 환경에 적용 가능한 수준의 효율성을 달성
4.3.2 LLM 크기의 영향
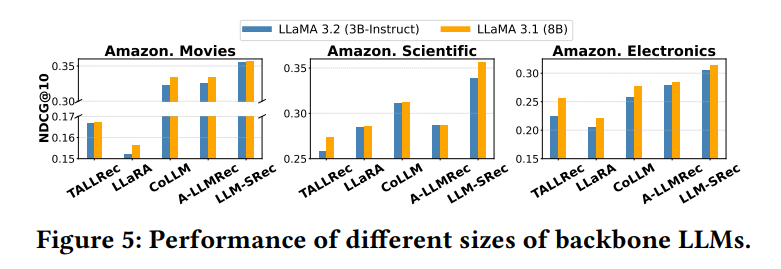
- 백본을 LLaMA 3.1 (8B)으로 교체하면 전반적 성능 향상
- 놀랍게도, 작은 LLM(3B)의 LLM-SRec이 큰 LLM(8B)의 기존 LLM4Rec 모델들을 상회
→ 단순히 LLM 크기를 키우는 것보다, 순차 정보를 증류하는 것이 더 효과적임을 시사
4.3.3 Case Study
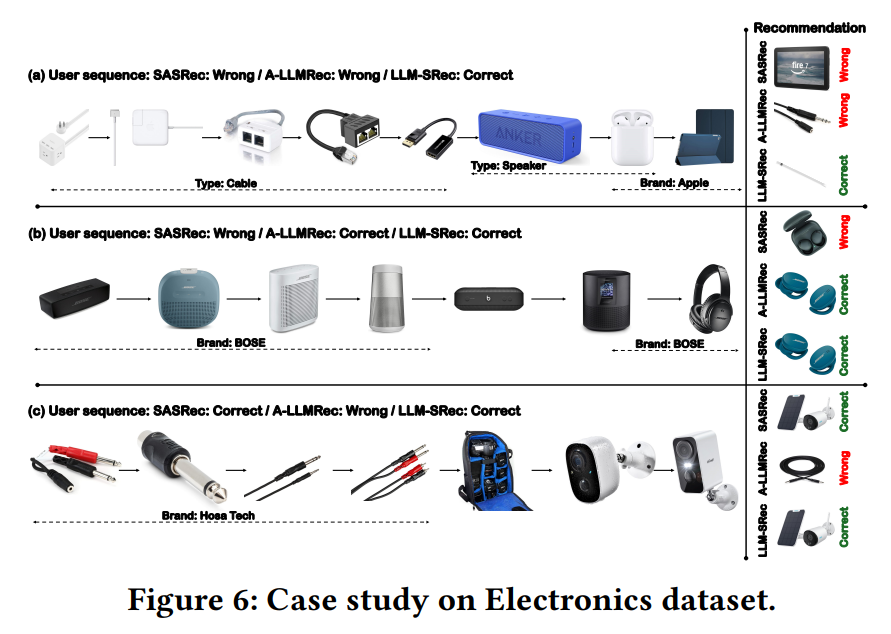
Electronics 데이터셋에서의 정성적 분석:
| 케이스 | 설명 |
|---|---|
| (a) | 사용자 선호가 "케이블" → "Apple" 브랜드로 변화. LLM-SRec만 "Apple Pencil" 정확 추천. SASRec은 변화 포착했으나 텍스트 정보 부족, A-LLMRec은 순서 무시하고 "Audio Cable" 추천 |
| (b) | "BOSE" 브랜드 선호 사용자. LLM-SRec과 A-LLMRec 모두 텍스트 지식으로 "BOSE" 이어버드 추천 성공. SASRec은 텍스트 정보 없이 실패 |
| (c) | 선호가 "Hosa Tech 케이블" → "보안 카메라"로 변화. LLM-SRec과 SASRec은 변화 포착, A-LLMRec은 여전히 "Hosa Tech" 추천 |
→ 텍스트 정보와 순차 정보를 모두 활용하는 LLM-SRec이 가장 정확하고 자연스러운 추천을 수행
5. Related Work
Sequential Recommender Systems
- 초기 : Matrix Factorization + Markov Chain으로 시간적 역학 모델링
- 신경망 기반 발전 :
- GRU4Rec : 순환 신경망(RNN) 활용
- Caser, NextItNet : 합성곱 신경망(CNN) 활용
- SASRec, BERT4Rec : 어텐션 메커니즘 기반, 더 관련성 높은 상호작용에 집중 → 우수한 성능
- 핵심 : 사용자 행동 역학의 효과적 모델링이 추천 정확도 향상의 관건
LLM-based Recommender Systems
- LLM의 추론 능력과 텍스트 이해력을 활용한 추천 시스템 연구 확대
- TALLRec : LLM의 언어 모델링 능력과 추천 태스크 간 갭을 인식 → PEFT로 적응
- LLaRA, CoLLM : CF-SRec의 아이템 임베딩과 텍스트 임베딩 결합 → CF 지식 활용
- A-LLMRec : 아이템 설명을 잠재 공간에 통합 → 다양한 시나리오에서 강건한 성능
→ 그러나 기존 방법들은 사용자 상호작용 시퀀스의 동적 선호 변화를 포착하는 데 실패함 (Sec. 2.3에서 입증)
6. Conclusion
- LLM4Rec 모델들의 근본적 한계인 "순차적 패턴을 포착하지 못함"을 실험적으로 입증
- LLM-SRec : CF-SRec으로부터 순차적 지식을 증류하여 LLM에 순서 이해 능력을 부여하는 간단하면서도 효과적인 프레임워크
- CF-SRec, LM-based, LLM4Rec 모든 베이스라인 상회
- CF-SRec도, LLM도 파인튜닝하지 않아 높은 학습·추론 효율성 달성
- 소수의 경량 MLP만 학습하므로 실제 서비스 환경에 적용 가능
💭 My Thoughts
- 추천 시스템 분야에서 LLM을 활용하려는 시도가 이렇게 다양한 방향으로 전개되고 있다는 점이 인상 깊었다. TALLRec, LLaRA, CoLLM, A-LLMRec 각각의 접근 방식을 비교하며 읽다 보니, 단순히 "LLM을 갖다 쓰면 되겠지"가 아니라 텍스트 정보와 협업 필터링 지식을 어떻게 결합할 것인가에 대한 고민이 계속 진화하고 있음을 느꼈다.
- "LLM이 순서를 이해하지 못한다"는 발견이 꽤 직관적이면서도 충격적이었다. 시퀀스를 셔플해도 성능이 안 떨어진다는 건, 결국 LLM이 아이템 "제목"의 텍스트적 유사성에만 의존하고 있고, "어떤 순서로 봤느냐"라는 맥락은 무시하고 있다는 뜻이기 때문이다.
- 그리고 실무적으로 보면, LLM을 파인튜닝하지 않아도 된다는 점은 매우 매력적이다. 추천 시스템에서 LLM 파인튜닝의 비용은 막대한데, 경량 MLP만으로 SOTA를 달성할 수 있다면 실제 서비스 적용의 문턱이 크게 낮아질 것이다.


멋진 포스트.