
Modeling
센서의 두 종류
Proprioceptive sensor
Exteroceptive sensor
Motion model
Proprioceptive sensor로 부터 얻을 수 있는 model로 현재 위치와 관련된 state를 추정할 수 있는 model이며, 다음과 같은 형태로 나타난다.
위 식은 현재 frame의 상태()는 이전 frame 상태()와 현재 frame의 control 혹은 odometry 정보()에 노이즈()가 포함된 것으로 표현된다.
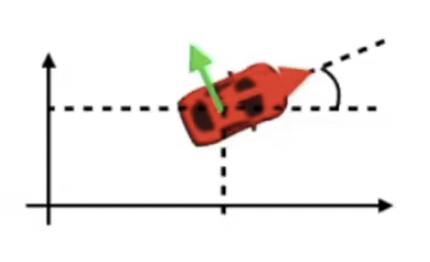
평면 위에 놓인 자동차는 위 식과 같은 형태로 modeling이 가능하다. 현재 차량의 위치()와 차량의 각도()로 정의될 수 있다.
Observation model
Exteroceptive sensor 센서로 얻은 정보로 부터 robot이 존재하는 상대적인 위치를 정의하는 방법이다. 다음과 같은 형태로 표현된다.
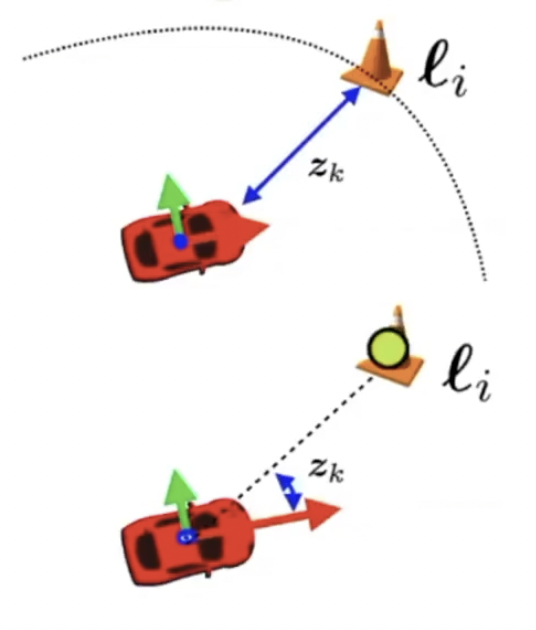
robot의 현재 state와 landmark에 위치에 관한 state를 입력으로 상대적인 위치를 표현한다.
SLAM state
위는 robot의 state를 표현한 것이다.
위는 SLAM의 state를 표현한 것이다.
SLAM state에는 하나의 Motion state와 다수의 landmark state가 포함된 형태이다. 이때 발생하는 noise를 잘 분석해서 최적의 robot state와 landmark position을 계산하는 것이 목적이 된다. 하지만 motion과 observation에는 noise가 포함되어 있어 시간이 지날수록 Uncertainty가 증가하게 되는 문제가 있다.
누적되는 uncertainty는 loop closure를 통해 개선이 가능하다.
Least squares
Least square를 최적화 문제를 푸는 방법 중 하나로 오차를 제곱의 형태로 사용하는 방법이다. 이 경우 큰 오류를 더 크게 작용하게 되며, 이를 줄이를 방향으로 최적화 하게된다. 또한 over-determined system, 즉 미지수의 개수보다 방정식의 개수가 더 많은 경우에 사용될 수 있다. 특히 SLAM의 경우 항상 over-determined의 문제를 갖는다.
최적화한? 방정식에서 정확한 해를 찾지 못하는 경우, 가장 작은 오차를 갖는 해를 찾는 방법
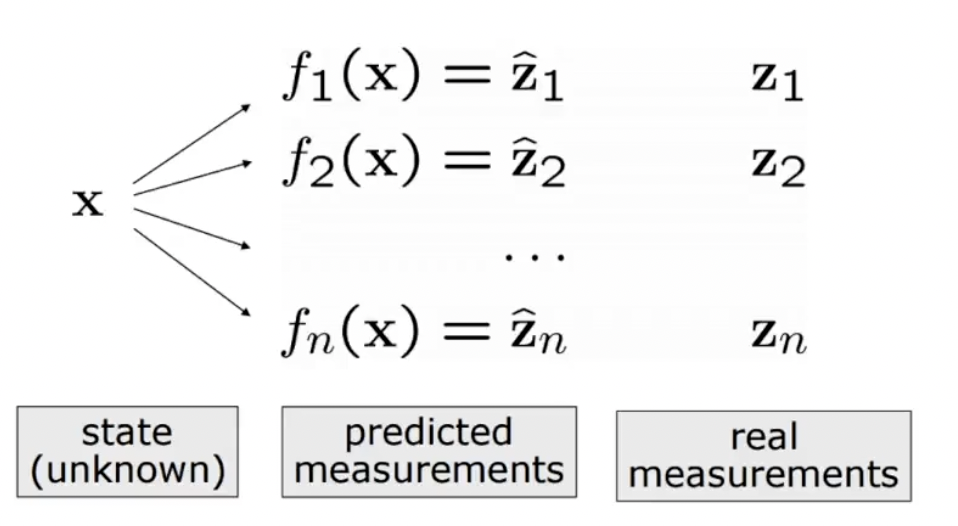
하나의 state를 추정하기 위한 과정을 표현한 그림이다. real measurements()는 sensor 혹은 feature로 들어온 정보들로 부터 수집된 데이터를 의미하고, predicted measurements()는 현재 추정한 상태(State, )를 기준으로 예측한 sensor 혹은 feature 정보들을 의미한다.
센서의 noise 혹은 modeling error(i.g. 3d ray, etc... )가 존재하기 때문에 예측과 실제 measurements 값에는 오차가 존재한다. 여기서 나타나는 오차를 error로 정의되며, least square에서는 error의 차의 제곱이 최소가 되는 해를 찾는 과정이라고 할 수 있다.
Maximum-a-posteriori(MAP) estimation in SLAM
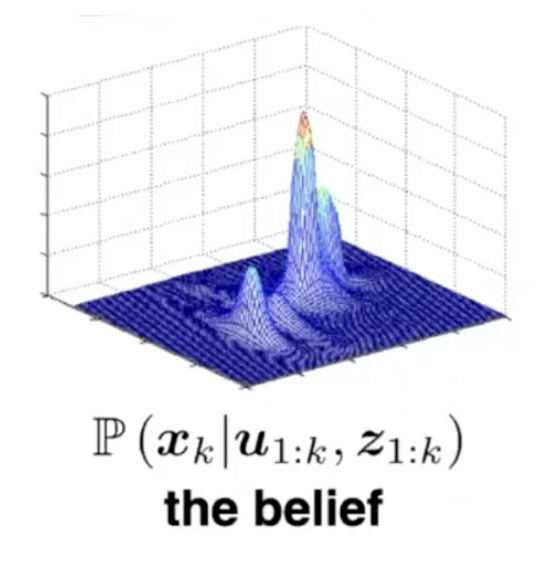
최대 사후 확률을 찾는 방법으로 센서로부터 들어온 데이터는 어떤 사건이 이미 나타난 상태를 측정한 데이터이기 때문에 이를 사후 확률로써 사용할 수 있다. SLAM의 경우 motion model과 observation model의 확률 분포를 찾고, 확률 분포를 정확하게 표현하는 state를 찾는 것이 목표가 된다.
가장 최적의 robot의 pose와 landmark의 위치를 추론하고자 할 때, noise로 부터 안정적인 추론을 하기 위한 방법 중 하나이다.
Least square를 통해 최적화하는 방법이다. 이때, motion model과 observation model을 동시에 joint optimization한다.
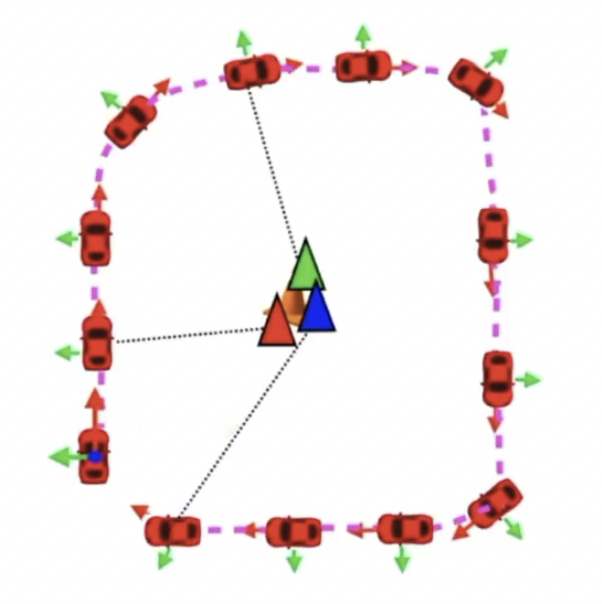
motion과 observation model을 동시에 최적화하기 때문에 보다 좋은 예측이 가능하다.
동시에 여러 파라미터를 한번에 최적화 하는 방법을 joint optimization이라고 한다. 여기서는 motion과 observation을 동시에 최적화한다.
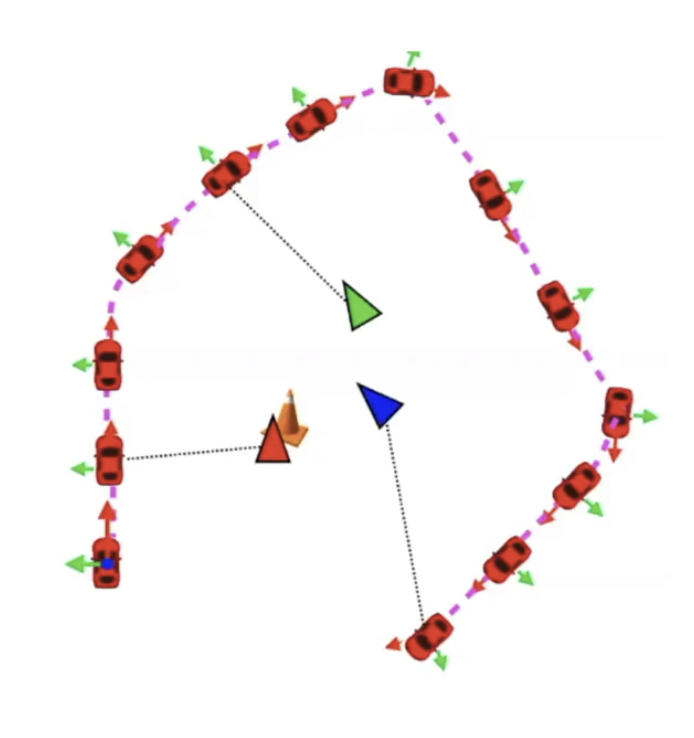
motion model만 최적화한 경우에 위 그림처럼 observation이 부정확하게 예측된다.
Graph-baesd SLAM
Incremental SLAM (i.g. Online SLAM)

주로 Particle filter나 Extended kalman filter와 같이 filter를 기반으로 한 알고리즘이 이에 해당한다. 가장 최종 state만 추론하며, Markov chain assumption을 기본 전제로 하기 때문에 이전 state들의 정보는 지속적으로 새로운 state에 포함된다. 때문에 이전에 사용된 state만 주어지면 새로운 state에 대한 추론이 가능하다. 빠르고, 최신 정보만 다루기 때문에 실시간 정보를 다루기에 용이하다.
Batch SLAM (i.g. Offline SLAM)
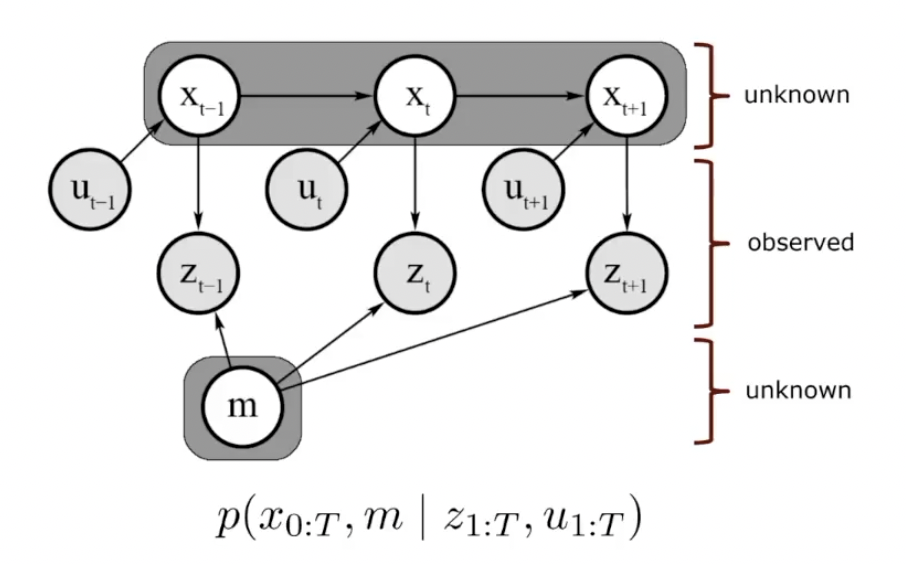
Graph SLAM이 이에 해당한다. 여러 시점에 대한 state를 한번에 추론한다. 동시에 여러 시점에 대한 정보를 독립적인 확률 분포로써 추론하기 때문에 draft error가 작다. 하지만 연산량이 많기 때문에 실시간 처리가 어려웠다. 하지만 현대적인 알고리즘에서는 실시간 처리를 위한 다양한 트릭이 포함되었다.
Incremental SLAM vs. Batch SLAM
Batch SLAM이 Incremental SLAM의 정확도를 얻는데 필요한 시간이 적다는 사실이 알려지면서 최근에는 Graph를 기반으로 한 SLAM이 선호되고 있다.
Factor graph
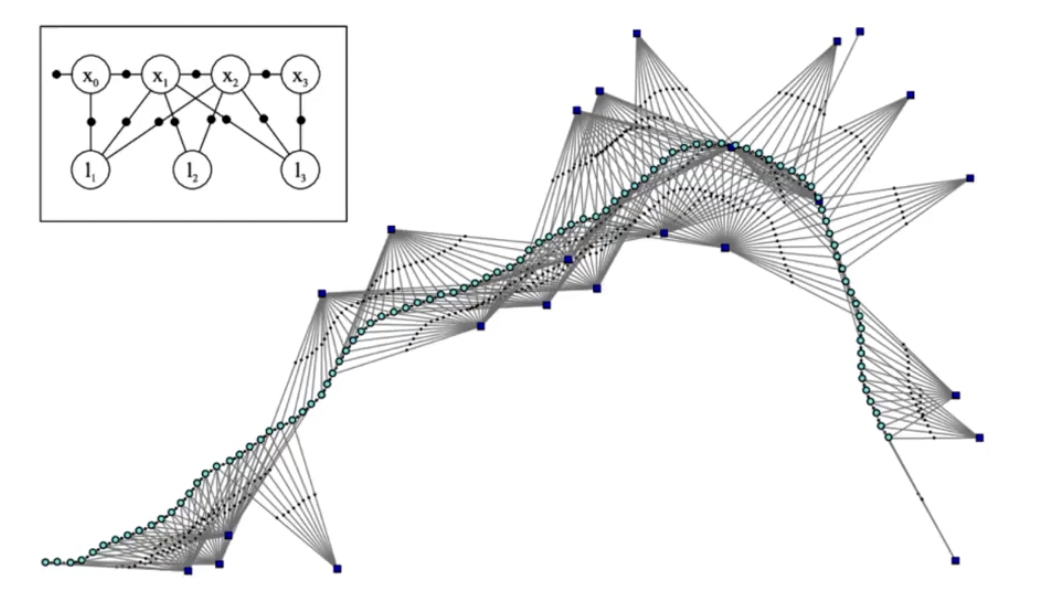
현재 SLAM의 graph를 다루는 방식으로 많이 알려져있다. node에는 robot의 state 그리고 landmark state가 저장되고, edge에는 motion model의 정보나 observation model의 정보가 저장된다. 그리고 edge에 저장되는 내용을 factor라고 한다. node에 저장된 state 정보를 edge의 model을 통해 추론된 정보를 가지고 최적화를 수행한다.
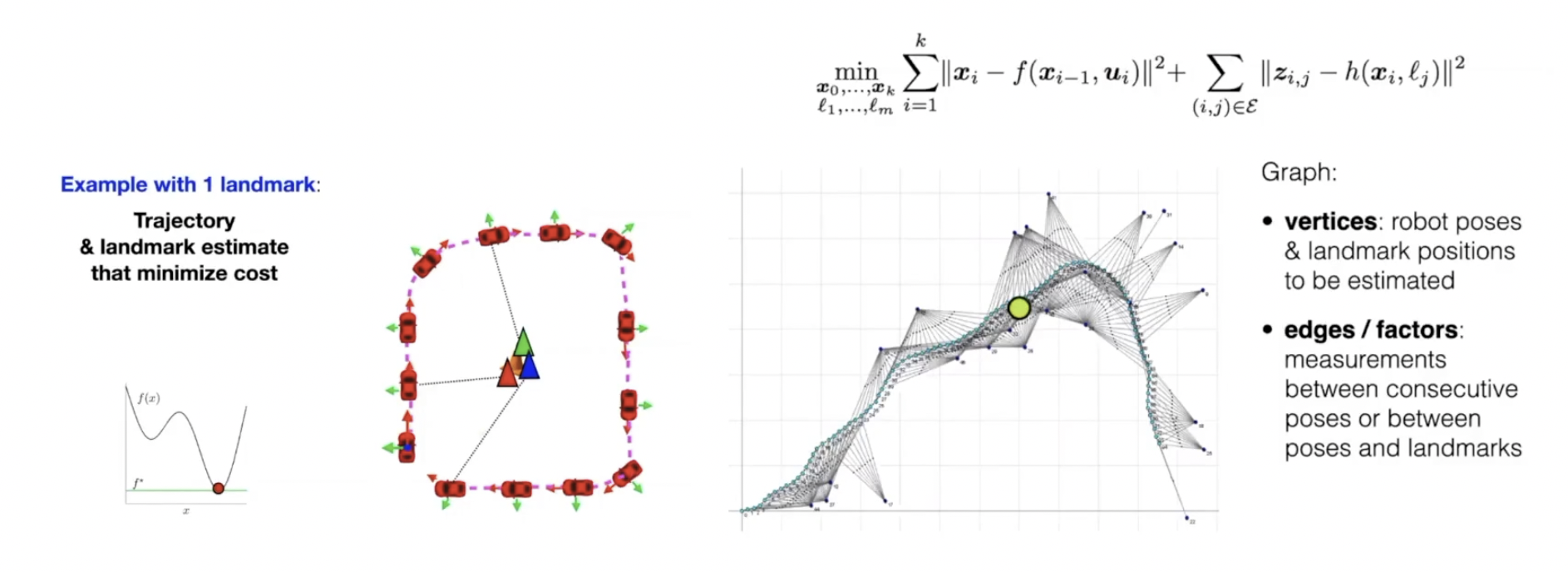
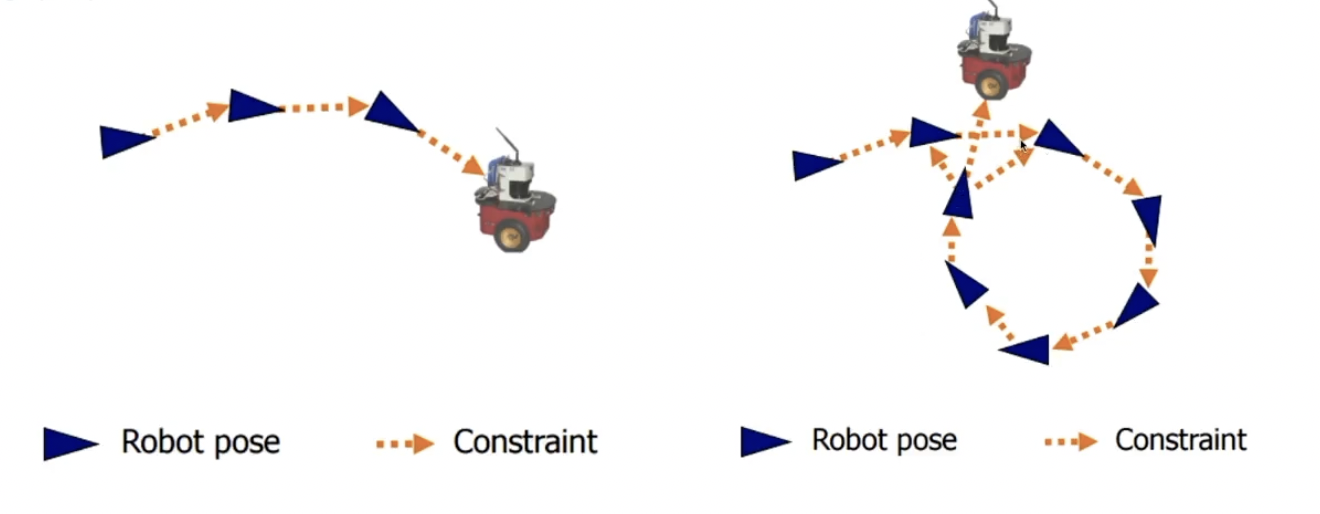
loop closure를 통해 uncertainty를 제거함으로써 실외에서도 VSLAM이 가능하게 되었다.
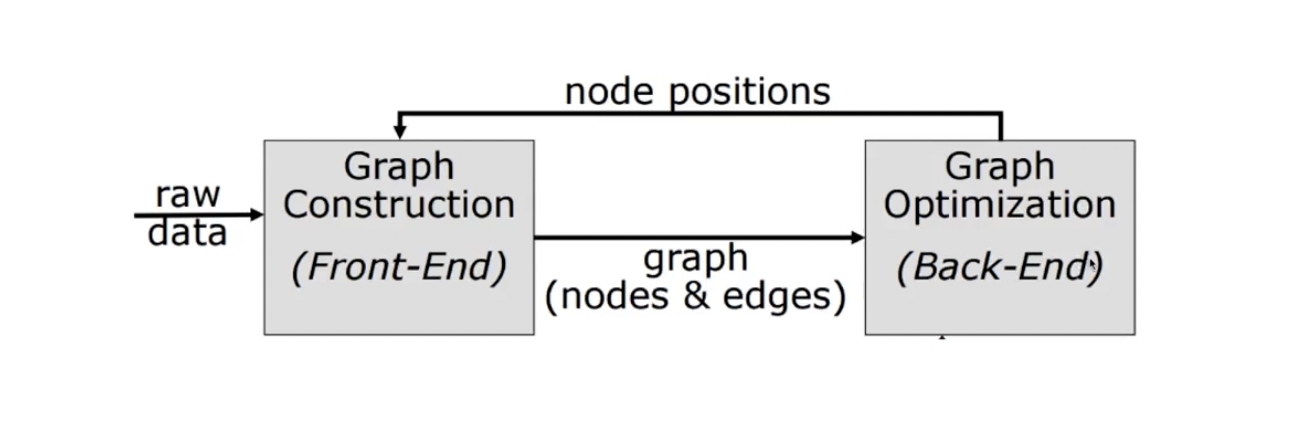
Frontend, Backend로 두 단계에 걸친 pipeline이 생겼다. Frontend에서는 graph에 새로운 node와 edge를 추가해주는 작업, Backend에서는 loop closure나 trigger가 되는 graph 알고리즘이 동작한다.
visual odometry와 visual-slam의 차이: odometry의 경우 draft error를 optimization 할 수 있는 방법이 없는 특징을 가지고 있는 반면에 vslam의 경우 loop closure와 같은 graph optimization이 가능한 차이가 있다.
