서울 열린데이터광장에서 서울시 노인 교통사고 현황 통계 공공데이터를 받아왔다.
파일을 세개로 나눠서 받아왔기 때문에 하나씩 열어서 merge로 합쳐주었다.
- 필요한 패키지와 폰트를 로드해 주었다.
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
font_path = "C:\windows\Fonts\Malgun.ttf"
font = font_manager.FontProperties(fname = font_path).get_name()
rc('font', family=font)- 각 파일을 불러왔다.
accidentdata1 = pd.read_csv('../data/노인 교통사고 추이/2007~2011노인 보행 교통사고(서울).csv')
accidentdata2 = pd.read_csv('../data/노인 교통사고 추이/2012~2016노인 보행 교통사고(서울).csv')
accidentdata3 = pd.read_csv('../data/노인 교통사고 추이/2017~2020노인 보행 교통사고(서울).csv')- merge로 합쳐준 후 csv파일로 저장하였다.
accidentdata = pd.merge(accidentdata1, accidentdata2, on = '시군구')
accidentdata = pd.merge(accidentdata, accidentdata3, on = '시군구')
accidentdata.to_csv('./data/accident.csv', encoding = 'euc-kr', index = False)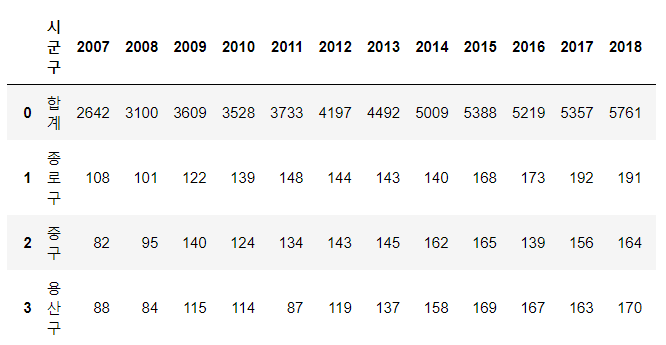
- 시군구와 합계만 가져와서 데이터프레임으로 만들어 주었다.
data = accidentdata.loc[0]
adata = pd.DataFrame(data)
adata.columns = ['합계']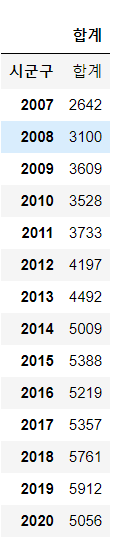
- 시군구 데이터를 인덱스를 바꿔주고 컬럼이름을 바꿔주었다.
adata.reset_index(inplace=True)
adata.drop(0, inplace=True)
adata.rename(columns={'index':'년도'}, inplace =True)
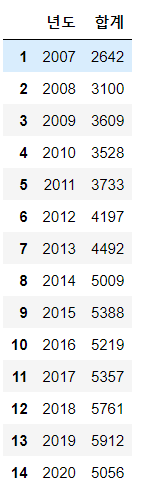
- 모든 데이터를 int형식으로 만들어주었다.
adata = adata.apply(pd.to_numeric)
adata.info()
- 전처리한 데이터를 csv파일로 저장해 주었다.
adata.to_csv('../data/전체 사고대비 노인사고/노인보행교통사고.csv', encoding = 'euc-kr')- 그래프로 나타내었다.
ax = adata.plot(x='년도', y='합계',figsize=(14,7), rot=0, color='r')
plt.title('노인 교통사고 추이', size = 15)
plt.xlabel('년도', fontsize = 15)
plt.ylabel('합계', fontsize = 15)
for temp in ax.patches:
ax.annotate('%d'%temp.get_height(),(temp.get_x()+temp.get_width()/2 , temp.get_height()) , ha = 'center' , va='bottom')
plt.show()
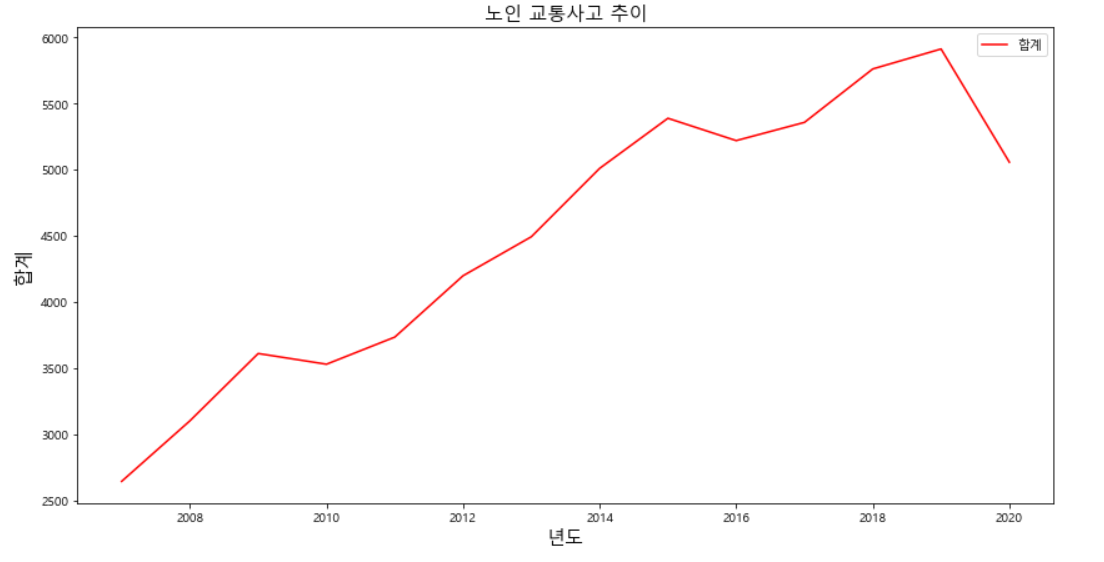
- 분석결과
노인 교통사고는 매년 증가하고있다.
출처
서울시 노인 교통사고 현황 통계(https://data.seoul.go.kr/dataList/10777/S/2/datasetView.do)

smilegate