1. 인스턴스를 3대 생성하고 보안그룹 지정
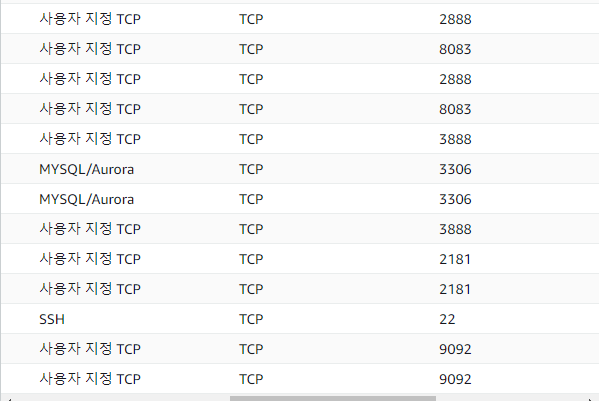
추후에 mysql도 연결해야해서 3306 열었습니다.
여기서부터는 3대의 인스턴스에서 해줘야 합니다.
2. openjdk 설치
sudo apt-get update
sudo apt-get install openjdk-11-jdk
3. zookeeper 설치
cd ~
wget https://mirror.navercorp.com/apache/zookeeper/zookeeper-3.6.3/apache- zookeeper-3.6.3-bin.tar.gz
tar xvf apache-zookeeper-3.6.3-bin.tar.gz
ln -s apache-zookeeper-3.6.3-bin zookeeper
4.zookeeper 설정
cd ~
mkdir -p ./data
여기는 인스턴스마다 다르다. 자기가 원하는 순서로 1 2 3을 지정하면 된다.
1번 서버
echo 1 > ./data/myid2번 서버
echo 2 > ./data/myid3번 서버
echo 3 > ./data/myid
서버 3대 모두 동일하게
cd ~
cd zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
중간의 dataDir부분 변경
dataDir=/home/ubuntu/data
그 다음 clientPort 밑에
server.1=1번서버_private_ip:2888:3888
server.2=2번서버_private_ip:2888:3888
server.3=3번서버_private_ip:2888:3888
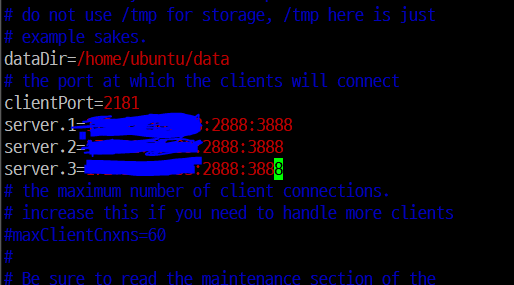
wq를 입력하고 나오기
5. zookeeper 실행
cd ~
cd zookeeper/bin
./zkServer.sh start
확인은?
./zkServer.sh status
중지
./zkServer.sh stop
6. kafka 설치
이건 본인이 원하는 버전을 다운 받고 압축을 푼다. ln을 이용하여 심볼릭 링크를 지정해주면 편함
7. kafka 설치
cd ~
vim ~/.bashrc
맨 밑에 입력
export KAFKA_HEAP_OPTS="-Xmx400m -Xms400m"
why? 주키퍼 메모리 사용량이 512m이다. 따라서 여유가 512이기 때문에 카프카는 400m를 준다. 기본 1gb
wq를 입력하고 나오고
source ~/.bashrc
echo $KAFKA_HEAP_OPTS -> 확인
8. kafka 설정
cd ~
cd kafka
cd config
vim server.properties
처음의 broker.id를 아까 주키퍼에서 설정한 번호로 해준다. 1번 서버는 =1...
log.dirs=/home/ec2-user/kafka/kafka-logs
zookeeper.connect=localhost:2181 -> 이 부분을 3개의 클러스터 서버1ip:2181,서버2ip:2181,서버3ip:2181/test-kafka 이렇게 변경
9. kafka 실행
cd ~
cd kafka
./bin/kafka-server-start.sh -daemon ./config/server.properties
netstat -ntlp | grep 9092 -> 확인

주키퍼 및 카프카를 3대로 클러스터 구성해야 하는건가요?