Algorithm
1.Greedy Algorithm
탐욕스러운, 욕심이 많은문제 해결 과정에서 결정 순간마다 눈앞에 보이는 최선의 선택을 함선택을 번복하지 않음지역 최적해를 추구함부분적으로는 최적해를 구한다고 할 수 있지만 전체적으로도 최적해를 구했다고는 장담할 수 없음빠른 시간 내에 근사해를 제공8원을 거슬러 줄 때,
2.스택

어원 : 쌓는다먼저 입력한 데이터를 제일 나중에 꺼낼 수 있는 자료구조선입후출. FILO(First in last out)
3.배열, ArrayList
인덱스와 값을 일대일 대응해 관리하는 자료구조데이터를 저장할 수 있는 모든 공간은 인덱스와 일대일 대응어떤 위치에 있는 데이터든 한 번에 접근 가능크기가 동적으로 변하는 배열ArrayList의 생성자의 맥변수로 컬렉션을 넘기면, 매개변수로 넘긴 컬렉션에 담긴 데이터로
4.큐
줄을 서다먼저 들어간 데이터가 먼저 나오는 자료 구조맛집에서 줄을 선 순서대로 식당에 입장하는 것과 유사선입선출FIFO(First in first out)add 연산 : add() / offer()poll 연산 : poll()일반적인 코딩 테스트에서는 LinkedLis
5.해시맵
key, value 쌍으로 데이터를 보관하는 자료 구조key는 중복될 수 없으며, value는 중복될 수 있음키와 값을 매핑하는 과정이 코테에서의 핵심위 코드에서 hashMap.put("ABC", 15)로 동일한 key 값에 새로운 value를 넣으면 값이 10에서 1
6.깊이 우선 탐색(DFS)
Depth-first search(DFS) 시작 노드부터 탐색을 시작하여 간선을 따라 최대 깊이 노드까지 이동하며 차례대로 방문 최대 깊이 노드까지 방문한 다음에는 이전에 방문한 노드를 거슬러 올라가며 해당 노드와 연결된 노드 중 방문하지 않은 노드의 최대 깊이까지 차
7.정렬
탐색을 위하여 정렬이 꼭 필요함탐색할 데이터가 정렬되어 있지 않다면 순차 탐색 말고 다른 알고리즘을 사용할 수 없지만, 정렬되어 있다면 이진탐색 이라는 알고리즘을 사용할 수 있음특징 : 특정 값을 선택하였을 때, 왼쪽 값은 선택된 값보다 항상 작거나 같고 오른쪽 값은
8.너비 우선 탐색(BFS)
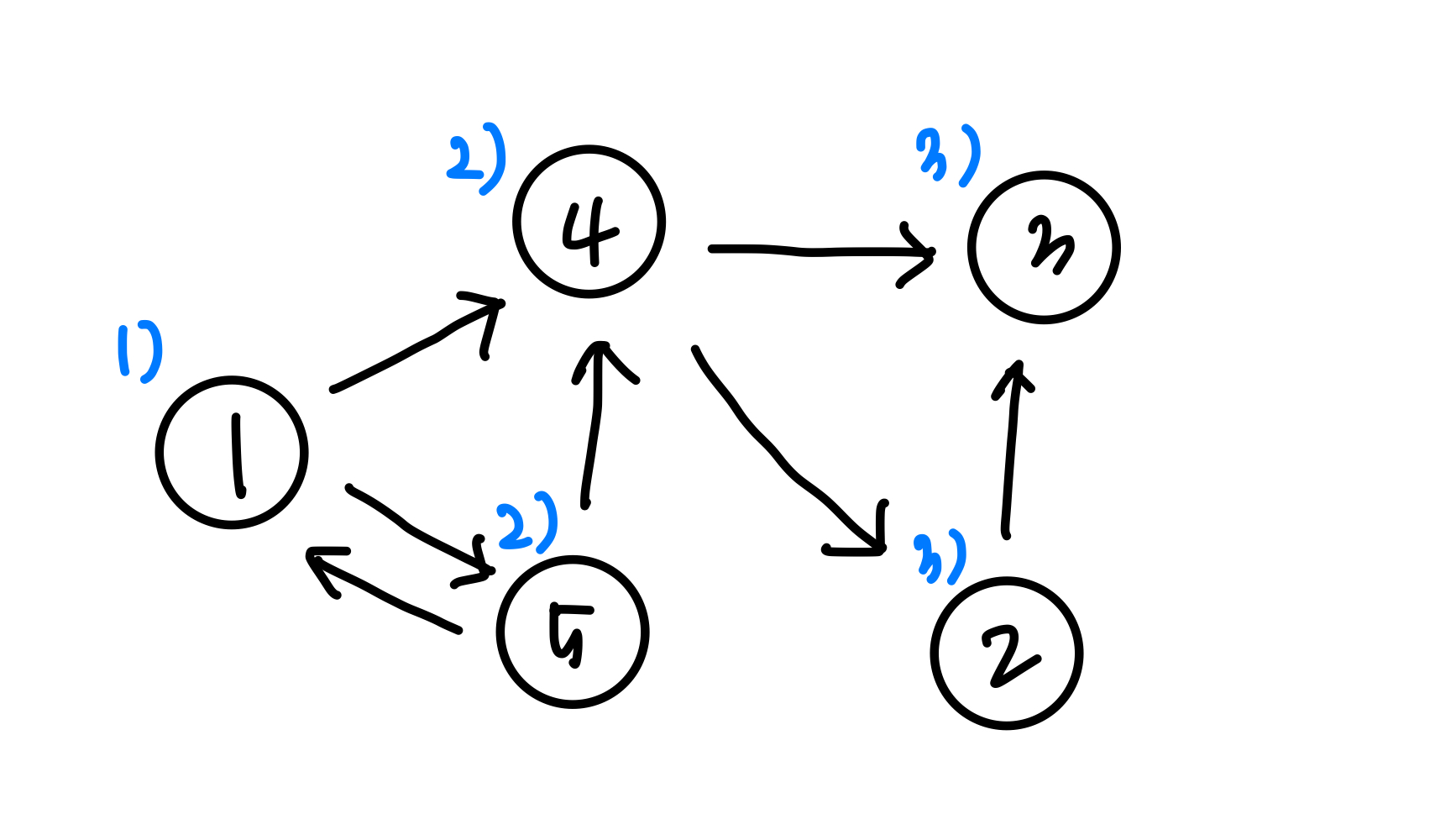
시작 노드와 거리가 가장 가까운 노드를 우선하여 방문하는 방식의 알고리즘거리 : 시작 노드와 목표 노드까지의 차수(간선 가중치의 합 X)먼저 발견한 노드를 방문하는 것 -> Queue 사용시작 노드를 정하고, 큐에 시작 노드를 add + 방문 처리 -> 큐에 있는 노드
9.다익스트라 알고리즘(Dijkstra Algorithm)
가중치가 있는 그래프의 최단 경로를 구하는 문제는 대부분 이 알고리즘을 사용각 단계에서 가장 좋은 것을 선택하는 전략을 가진 Greedy 알고리즘과 원리가 같음. but dijkstra 알고리즘은 한 번 방문한 노드는 다시 방문하지 않음 -> 음의 가중치가 있는 그래프
10.벨만-포드 알고리즘(Bellman-ford)
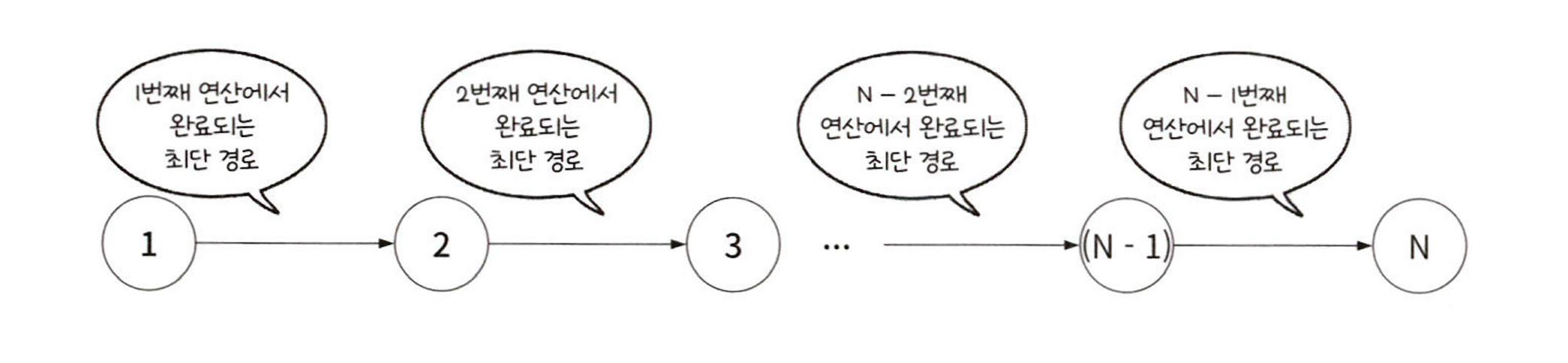
노드에서 노드까지의 최소 비용을 구함매 단계마다 모든 간선의 가중치를 다시 확인하여 최소 비용을 갱신하므로 음의 가중치를 가지는 그래프에서도 최단 경로를 구할 수 있음시작 노드를 설정한 다음 시작 노드의 최소 비용은 0, 나머지 노드는 INF로 초기화. 이후 최소 비용