0. relational data medel
set
- 서로 다른 elements를 가지는 collection
- 하나의 set에서 elements의 순서는 중요치 않음
- eg. {1,3,11,4,7,}
relation in mathmatics
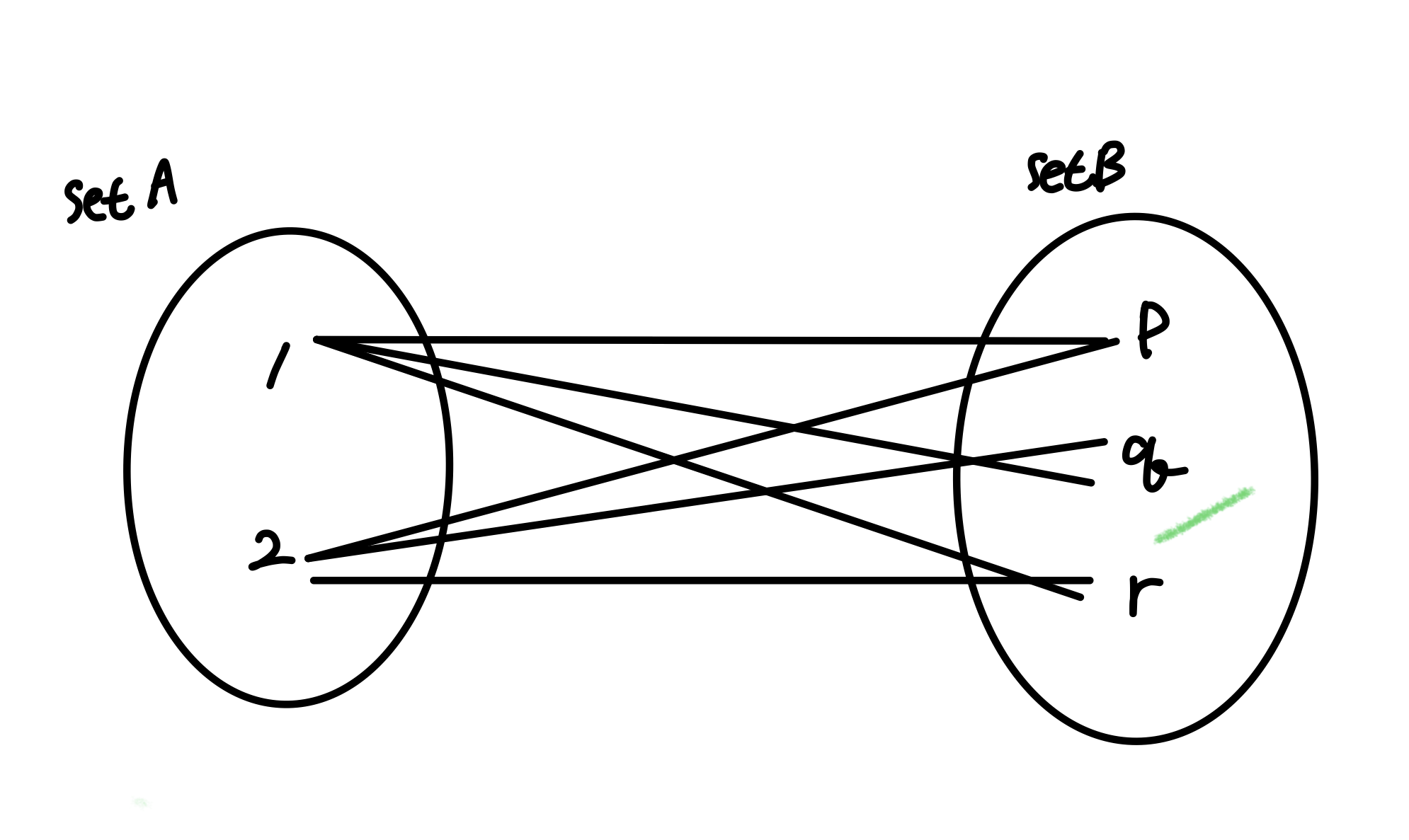
cartesian product A X B = {(a,b) ㅣ a ∈ A and b ∈ B}
= 모든 pair의 집합 = (1,p) (1,q) (1,r) (2,p) (2,q) (2,r)
binary relation = set 2ea
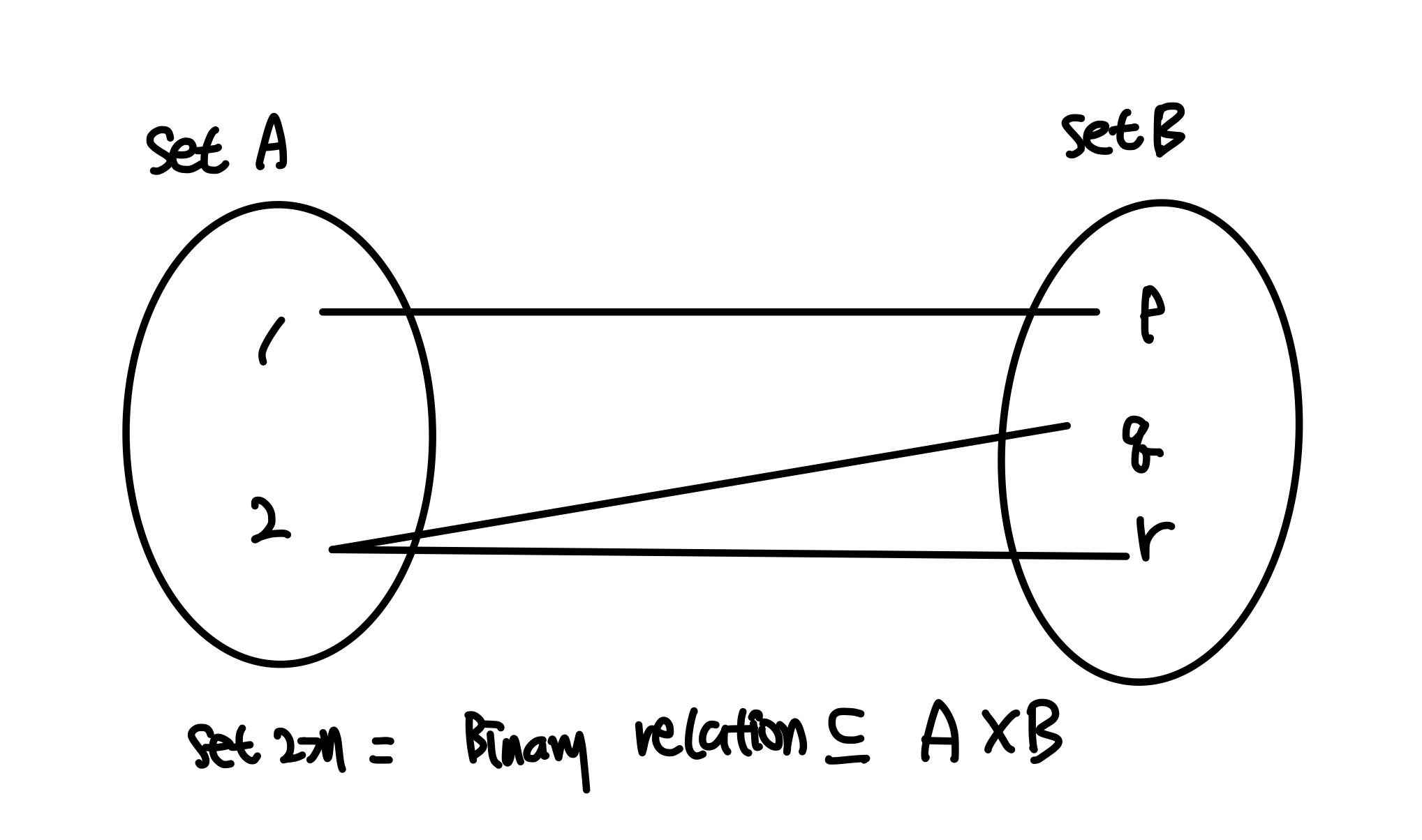
= 3개 pair은 A,B에 대한 Cartesian product의 부분집합
set n ea
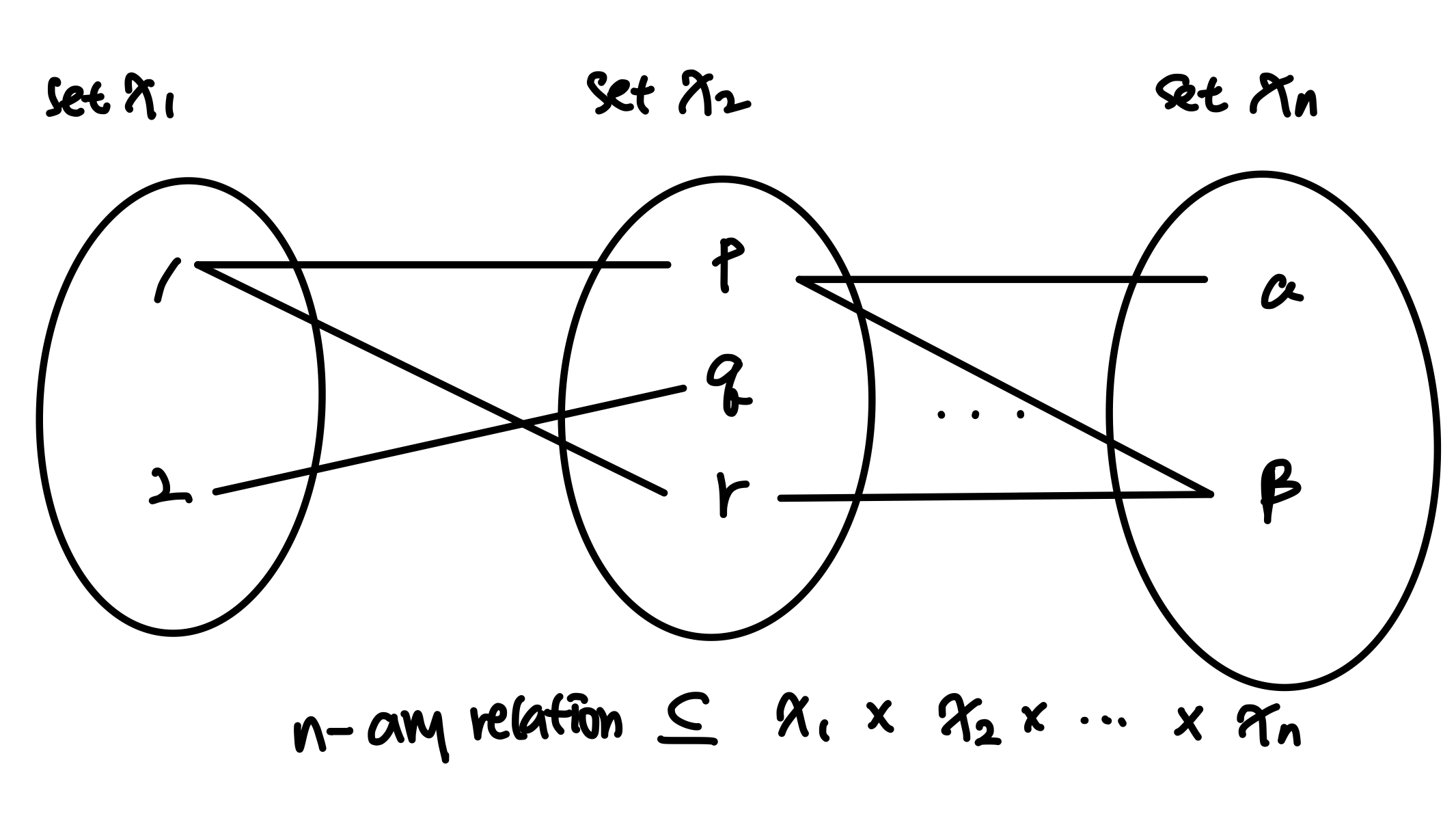
= n개의 집합에 대한 Cartesian product의 부분집합
relaiton in mathematics & relational data model
relational data model
eg. student relation
Domain 정의
student_ids : 학번집합, 7자리 integer 정수
human_names : 사람 이름 집합, 문자열
university_gardes : 대학교 학년 집합 {1,2,3,4}
major_names : 대학교 전공 이름 집합
phone_numbers : 핸드폰 번호 집합
phone_numbers : 비상 핸드폰 번호 집합각 도메인마다 attribute name 설정 : for 목적, 역할 구분
주요 개념
- domain : Set of atomic values (=더이상 나눠질 수 없는 값)
- domain name
- attribute : domain이 Relation에서 맡은 역할이름
- tuple : 각 attribute의 값으로 이루어진 리스트, 일부 값은 Null 일 수 있다
- Relation : set of tuples
- relation name : relation의 이름
1. 키(Key)의 개념
- DB에서 튜플을 고유하게 식별할 수 있도록 하는 속성 혹은 속성 집합
- 데이터를 검색하거나 정렬할 때 기준이 되는 유일하게 구분되는 속성
- 수퍼키(Super key), 후보키(Candidate key), 기본키(Primary key), 외래키(Foreign key) etc
1-1 이상(anomaly)현상
- 데이터가 중복 저장되면 릴레이션 조작 시 예기치 못한 현상 발생
2. 키의 종류
2-1 수퍼키 (Super key)
- 릴레이션에서 같은 튜플이 발생하지 않는 키를 구성할 때, 속성의 집합으로 구성하는 것을 말함
- 릴레이션을 구성하는 모든 튜플에 대해 유일성(유일하게 식별)은 만족시키지만, 최소성(식별시 꼭 필요한 속성으로만 구성)은 만족시키지 못함
eg.
Player(id, name, team_id, back_number, birth_date)의 superkey는
{id, name, team_id, back_number}2-2 후보키 (Candidate key) = minimal superkey
- 한 attribute라도 제거하면 unique하게 tuples를 식별할 수 없는 super key
- 릴레이션을 구성하는 속성들 중, 튜플을 유일하게 식별하기 위해 사용하는 속성들의 부분집합, 즉 기본키로 사용할 수 있는 속성
- 수퍼키와 공통점 : 릴레이션에 있는 각 튜플을 고유하게 식별할 수 있어야함
- 수퍼키와 차이점 : 최소한의 속성으로 구성된 유일성을 갖는 속성
eg.
PLAYER(id, name, team_id, back_number, birth_date)의 candidate key는
{id}
{tean_id + back_number} 각각 유니크하게 식별할 수 없음2-3 기본키 (Primary key : PK)
- relation에서 tuples를 unique하게 식별하기 위해 선택된 candidate key
- 한 릴레이션에서 특정 튜플을 유일하게 구별할 수있는 속성
- 제약조건1) Not Null = 무결성 = Null값 가질 수 없음
제약조건2) Not duplication = 동일 중복값 가질 수 없음
제약조건3) Unique = 고유성 - cf. Null 값? 아무것도 없는 특수한 데이터
eg. PLAYER (id, name, team_id, back_number, birth_date)의 primary key는
{id}를 가지고 tuple를 식별하겠다 하면 {id}=primary key
{team_id, back_num}의 조합으로 tuple들을 식별하겠다 하면 {team_id, back_num}=primary key
But 보통 PK 선택할때는 attribute 숫자가 적은걸로 고름
So 이 값에서 ~~primary key = {id}~~2-4 대체키 (Alternate key) = 보조키 = Unique key
- primary key가 아닌 candidate keys
- 후보키가 둘 이상일 때 기본키로 선택되지 않은 나머지 후보키
eg. 사원번호를 기본키로 정의했다면 주민번호가 대체키 - Correlation of key
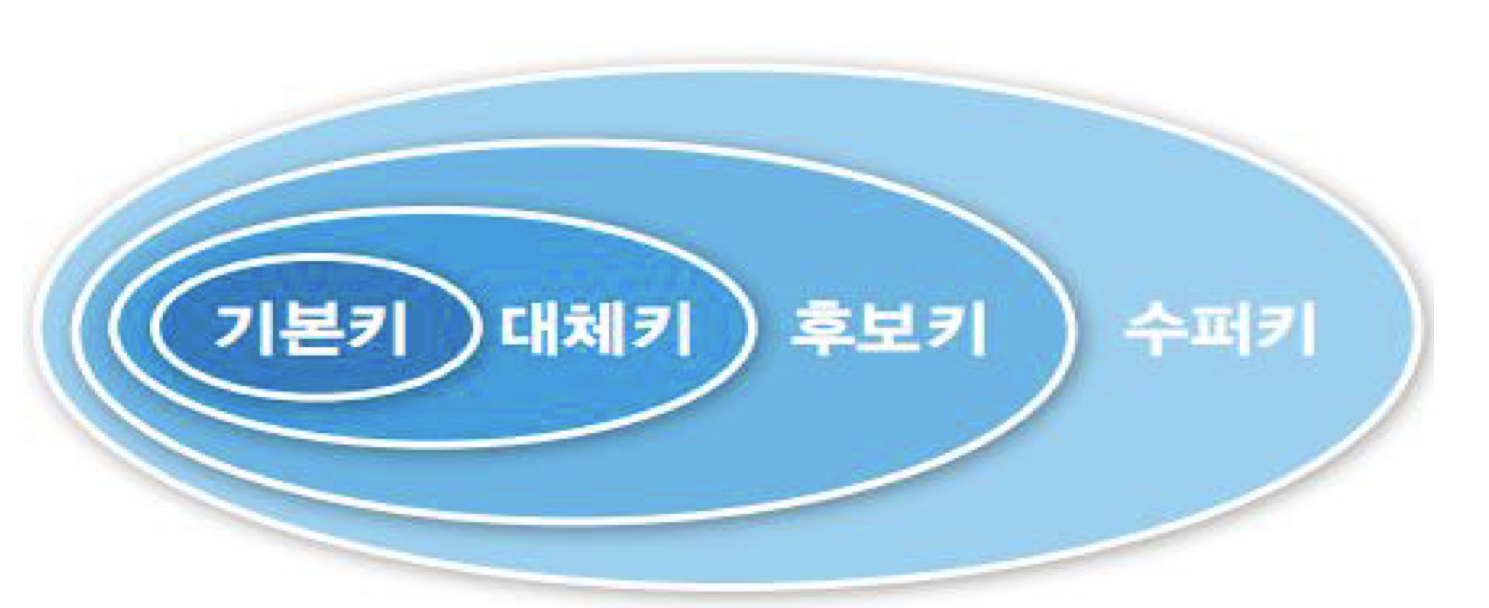
2-5 복합키 (Composite primary key)
- 하나의 칼럼이 후보키의 역할을 하지 못함
- 두 개 이상의 칼럼이 합쳐져야 후보키의 역할 하는 경우
2-6 외래키 (Foreign key)
- 다른 relation의 PK를 참조하는 attribute set
- 상호 관련 있는 테이블들 사이에 데이터 일관성을 보장해주는 수단
- 두개의 테이블을 연결해주는 다리역할
- 한 테이블의 컬럼이 다른 테이블의 기본키 참조하는 경우 사용
eg. PLAYER (id=PK, , name, team_id, back_num, birth_date)와 TEAM(id, name, manager)가 있을 때 foreign keysms PLAYER의 {team_id}외래키는 한 테이블의 컬럼이 다른 테이블의 기본키를 참조하는 경우 사용
