JVM (Java Virtual Machine)
Java는 OS에 독립적으로 동작한다.
즉, 하나의 Java 프로그램은 Windows, Mac, Linux 등에서 모두 돌아간다는 뜻이다.
각 OS가 통일되지 않은 각각의 시스템콜을 가지고 있다는 걸 생각해보면 이건 퍽 놀라운 일이다.
이는 .java 파일이 바로 기계어(binary code)로 변환되어 실행되는 것이 아니라,
컴파일러를 통해 .class 파일 (byte code)로 한번 변환된 후,
JVM을 통해 기계어로 변환되어 실행되기 때문이다.
그렇기 때문에 Java로 작성된 프로그램의 실행을 위해서는 JVM이 필수이다.
JDK vs JRE
간단한 것 먼저 짚고 넘어가자.
JDK는 Java Development Kit. 즉, 자바 개발 도구모음집이다.
개발자가 아니라면 딱히 필요하지 않다.
그리고 JDK는 JRE를 포함하고 있다. 그러니 JDK를 설치했다면 JRE를 따로 설치할 필요는 없다.
JRE는 Java Runtime Environment. 즉, 자바 실행 환경이다.
간단히 말해 JVM + Java class library 등을 가지고 있다.
개발자가 아니면 JRE만 설치하면 된다.
JVM Structure
JVM의 구조를 아래 그림과 함께 알아보자.
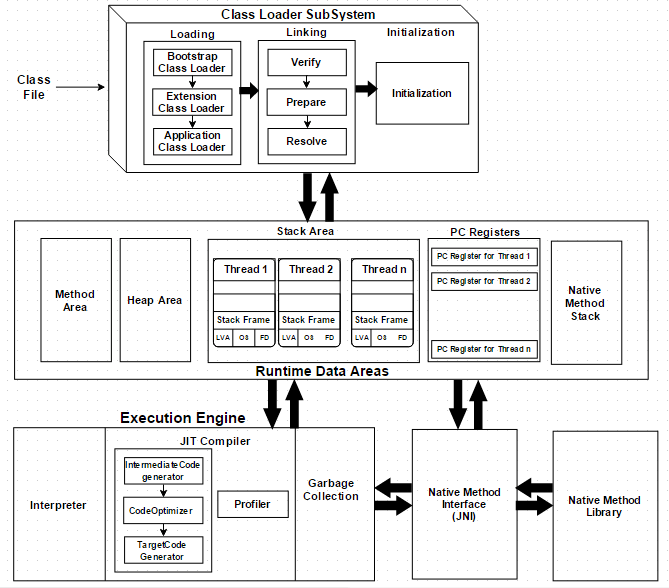
JVM이 읽는 것은 .class 파일이므로 javac 명령어를 통해 .java 파일이 .class 파일로 변환되었다고 가정한다.
-
JVM이 동작하면 먼저 클래스 로더를 통해 .class 파일이 읽어진다.
-
읽어진 정보들과 Native Method Interface/Libraries와의 협동을 통해 Execution Engine이 바이트 코드를 바이너리 코드로 변환해 실행한다.
위의 단계들로 java 프로그램은 실행이 된다.
그러면 이제, 각 파트가 무엇을 하는 지 알아보자.
Class Loader
클래스 로더는 .class파일을 읽어들여 (Loading) 검증하고 (Linking) 전역 변수 등을 초기화한다 (Initialzation).
읽어진 핵심 정보 (클래스, 필드, 메소드, 인터페이스 등)을 JVM Memory의 Method Area에 배치한다.
각 세부단계의 실행은 다음과 같다.
Loading
상위 CL은 하위 CL에 올라온 클래스 목록을 볼 수 없다.
3가지 CL을 통틀어 하나의 클래스는 하나만 존재해야 한다.
- Bootstrap Class Loader : 가장 필수가 되는 Library class들을 load (e.g.) rt.jar
- Extension Class Loader : Bootstrap 다음으로 중요한 classes를 load (e.g.)$JAVAHONE/jre/lib/ext/*.jar
- Application Class Loader : 개발자가 작성한 클래스 파일을 load (classpath에 위치)
- ACL이 로딩 요청 받아서 상위로, 또 상위로 위임. 위쪽에서 찾기 실패 시 하위로 요청 패스. 결국 못 찾으면 ClassNotFound Exception 발생.
Linking
- Verification : 클래스 파일이 올바른 지 검증
- Preparation : 클래스, 인터페이스에 필요한 static field 메모리 할당 및 기본값 초기화
- Resolution : Symbolic Reference 값을 Method Area의 Direct Reference (메모리 주소) 값으로 변환
Initialization
멀티 쓰레드로 동작하기 때문에 동시성 고려
- Loading, Linking 후에 Class 파일의 코드를 읽음
- 클래스와 인터페이스의 값들을 지정한 값으로 초기화 (기본값 초기화는 linking)
Method Area (= PermGen = Metaspace = Non-Heap)
메소드 에어리어는 모든 클래스의 메타 정보 (클래스 이름, 필드 변수명, 메소드 이름, 열거형 등)이 저장되는 곳이다. JVM 내에 하나만 존재하며 여러 클래스들 사이에서 공유된다.
Method Area는 PermGen(java 7까지) Metaspace(java 8 이후)의 일부이다.
PermGen은 뭐고, Metaspace는 또 뭘까?
간단한 그림 한 장으로 알아보자.
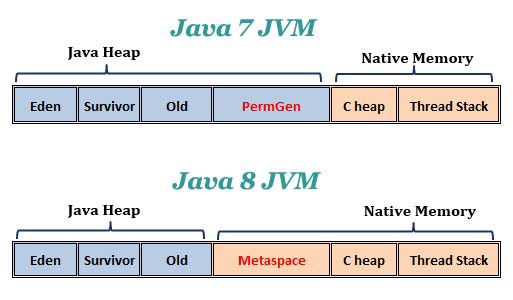
그냥 이름이 바뀐거다.
Interned String과 static variable, static method 등은 PermGen이라고 하는 기억공간에 저장이 따로 되는데, Java 8부터 이 공간의 이름이 Metaspace로 변경되었고, Heap 영역에서 Native Memory 영역으로 위치가 변하였다.
이게 무엇을 뜻하느냐? JVM이 아닌 OS에 의해 관리된다는 소리다.
다시 말해 가용영역 크기가 엄청나게 증가했다는 것이다.
그렇기 때문에 java.lang.OutOfMemoryError: PermGen space와 같은 에러는 이제는 볼 수 없는 과거의 유물이 되었다.
동시에 과거에는 PermGen에 static variable, static method 등이 클래스 메타 정보와 함께 저장이 되었는데, 변경 이후부터는 오직 클래스 메타 정보만을 저장하고, static member들은 Heap에서 관리된다.
Heap
Java로 구성된 배열이나 객체의 인스턴스 (Class 정보를 통해 new로 생성되는 객체) 정보와 static 변수, 메소드들의 정보가 저장되는 공간이다.
모든 Java stack 영역에서 참조되어, Thread 간 공유된다.
해당 영역이 모두 차면 OutOfMemoryException이 발생한다.
추가적인 특징은 다음과 같다.
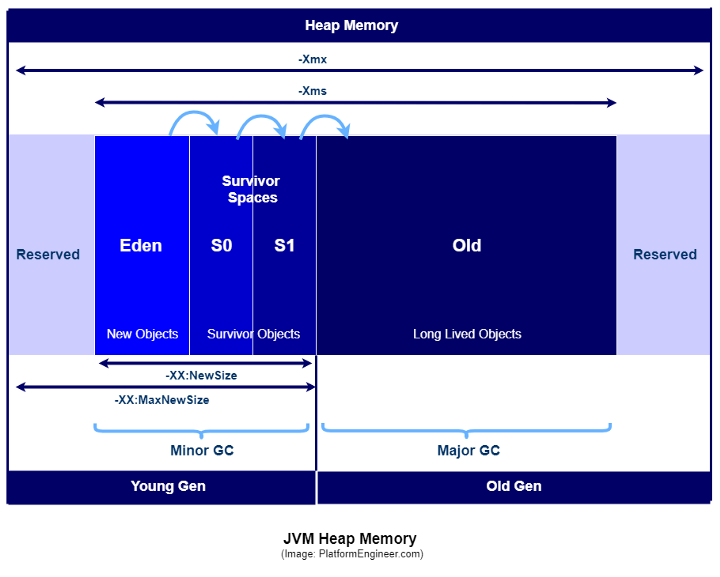
- 내부적으로 Eden 영역, Survival 영역, Tenured 영역으로 나뉜다.
- Eden + Survival을 묶어 Young Generation이며 Minor GC영역이다.
- Eden 영역이 가득차면 Minor GC가 수행되며, 살아있어야 하는 객체들은 Survival 영역으로 넘어간다.
- Minor GC 중에 Survial 영역에 있는 객체들 또한 확인되며, S0 or S1 중 한 쪽으로 모조리 이동한다. 그렇기 때문에 S0, S1 둘 중 하나는 항상 빈 공간이다.
- 여러 번의 GC에서 살아남은 객체들은 Old Generation 영역으로 넘어간다.
- Tenured 영역이 Old Generation이고 Major GC영역이다.
- Tenured 영역이 가득 차면 Major GC가 수행되며, 이 GC 과정은 영역의 덩치가 크기에 오래 걸린다.
PC Register
Thread별로 동시에 동작할 수 있도록 메모리 주소를 저장한다.
Stack Area
Java의 메소드나 호출될 때 사용되는 메모리 공간이며, 변수, 오퍼레이션, reference 정보 등이 저장된다.
스레드마다 하나씩 배정되는 메모리 영역이다.
Native Method Stack
Java가 아닌 다른 언어 (C, C++ 등)으로 작성된 메소드들의 정보가 저장되는 곳이다.
Native Method Interface / Library
Native Method Library는 Java가 아닌 언어에 대한 라이브러리 정보를 담고 있으며,
Native Method Interface는 이 라이브러리들과 JVM 사이에서 소통 창구 역할을 한다.
Stack vs Heap
차이점을 알아보자.
| 속성 | Stack | Heap |
|---|---|---|
| 사용성 | 호출 될 때만 스레드의 실행 중에 사용 | 어플리케이션 전체에서 실행시간 내내 사용함 |
| Threadsafe | O | X (동기화 처리 필요) |
| 크기 | 제한된 크기, 보통 Heap보다 작음 | 유저 설정 or 기본값에 따름. OS로부터의 제한은 없음 |
| 저장대상 | privitive 변수와 객체의 참조 변수 | new 커맨드로 생성된 객체 |
| 생명주기 | 현 메소드가 끝날 때까지 | 어플리케이션이 죽을 때까지 |
| 속도 | 상대적으로 빠름 | 상대적으로 느림 |
| Alloc/Dealloc | 메소드가 호출되고 결과를 반환 할 때 자동으로 됨 | 객체가 생성될 때 할당되고 GC에 의해 해제됨 |
Execution Engine
Interpreter
Python 등에도 있는 그 인터프리터와 같은 기능으로, 바이트코드를 한 줄 씩 읽어서 실행한다. 그렇기 때문에 실행 시간이 길어지면 길어질수록 느린 것이 특징이다.
JIT Compiler
인터프리터가 너무 느려서 나온 보완책이다.
유사한 바이트코드를 기계어로 번환한다. 이 과정은 인터프리터와 같지만, 변환된 기계어를 저장한다는 점이 다르다. 이렇게 저장된 기계어는 동일 코드가 호출될 때마다 제공되어 추가의 변환시간을 필요로 하지 않게 된다.
그렇기 때문에 JIT Compiler는 반복 호출되는 바이트코드 부분이 많으면 많을 수록 효율이 올라간다.
그러면 얼마나 호출되는지 확인하는 것은 뭐가 어떻게 하느냐?
Hotspot Compiler가 바로 그 역할을 한다. 이 친구는 우선 순위가 높은 코드가 낮은 코드보다 먼저 컴파일되도록 Java 코드를 식별하고 우선 순위를 지정한다. 그 후, 우선 순위에 따라 JIT Compiler가 설정 된 기준을 넘어가는 코드들을 변환하고, 이후에 인터프리터가 남은 코드를 변환한다.
기계어로 변환된 코드는 Non-Heap 안의 또 다른 저장 공간인 Code Cache에 담겨져 추가적인 변환없이 빠르게 실행될 수 있게 된다.
GC
https://velog.io/@yaaloo/Java-Garbage-Collector
References
- What is JVM? https://usemynotes.com/what-is-jvm-jit/
- The JVM Architecture Explained: https://dzone.com/articles/jvm-architecture-explained
- Understanding Java Memory Model: https://medium.com/platform-engineer/understanding-java-memory-model-1d0863f6d973
- JVM Storage for Static Members: https://www.baeldung.com/jvm-static-storage
- Introduction of JNI: https://docs.oracle.com/javase/7/docs/technotes/guides/jni/spec/intro.html
