파일 시스템
- 연관되는 데이터들을 모조리 비트로 관리하기에는 너무 큰 오버헤드 때문에 등장
- 데이터들을 묶어 블록 단위로 관리 (보통 4kb)
- 블록마다 고유 번호를 부여
- 사용자가 각 블록들을 하나하나 세세히 관리하기에는 어려움
- 연관된 블록들의 집합체인 추상적이고 논리적인 객체의 필요성 대두
=> 사용자는 파일을 관리하고 파일 내부에서 각 블록을 관리.
파일 저장 방식
- 연속 저장 : 연속적인 공간에 하나의 파일을 저장 (외부 단편화, 파일 크기 변경 문제 발생)
- 블록 체인 : 블록을 링크드 리스트로 연결해 각 블록이 다음 블록의 주소를 가리킴.
- 인덱스 블록 기법 : 각 블록의 위치 정보를 가지고 있는 인덱스 블록을 만들어 전체 블록을 관리
주요 파일 시스템
- Windows : FAT, FAT32, NTFS => 블록 위치를 FAT이라는 자료 구조에 기록.
- Linux (UNIX-ish) : ext2, ext3, ext4 => 인덱스 블록 기법인 inode방식 사용.
Inode 파일 시스템
하나의 디스크는 여러 개의 파티션으로 나뉠 수 있다. 각 파티션 내에는 하나의 super 블록, 해당 파티션 내의 모든 inode 블록들을 담고 있는 ilist, 실제 데이터들을 가지고 있는 data 블록들과 디렉토리를 나타내는 directory 블록들이 있다.
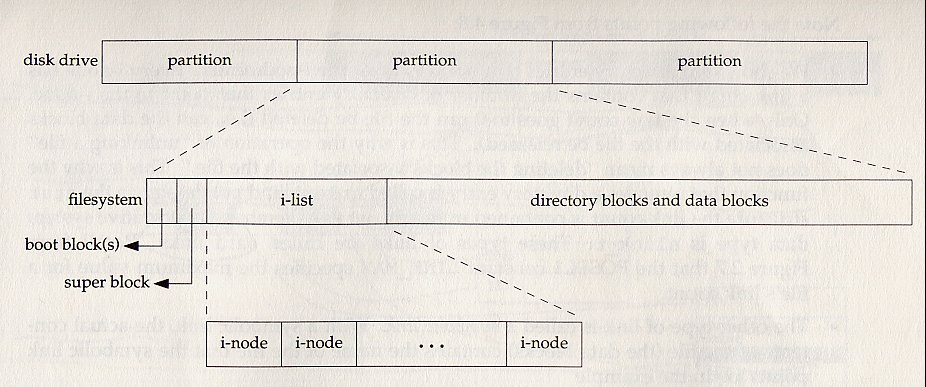
-
super 블록 : 파일 시스템 및 파티션 관련 정보가 들어가며 inode들을 관리하는 블록이기에 그에 대한 내용들을 보관하고 있다. 상세 내용은 아래와 같다.
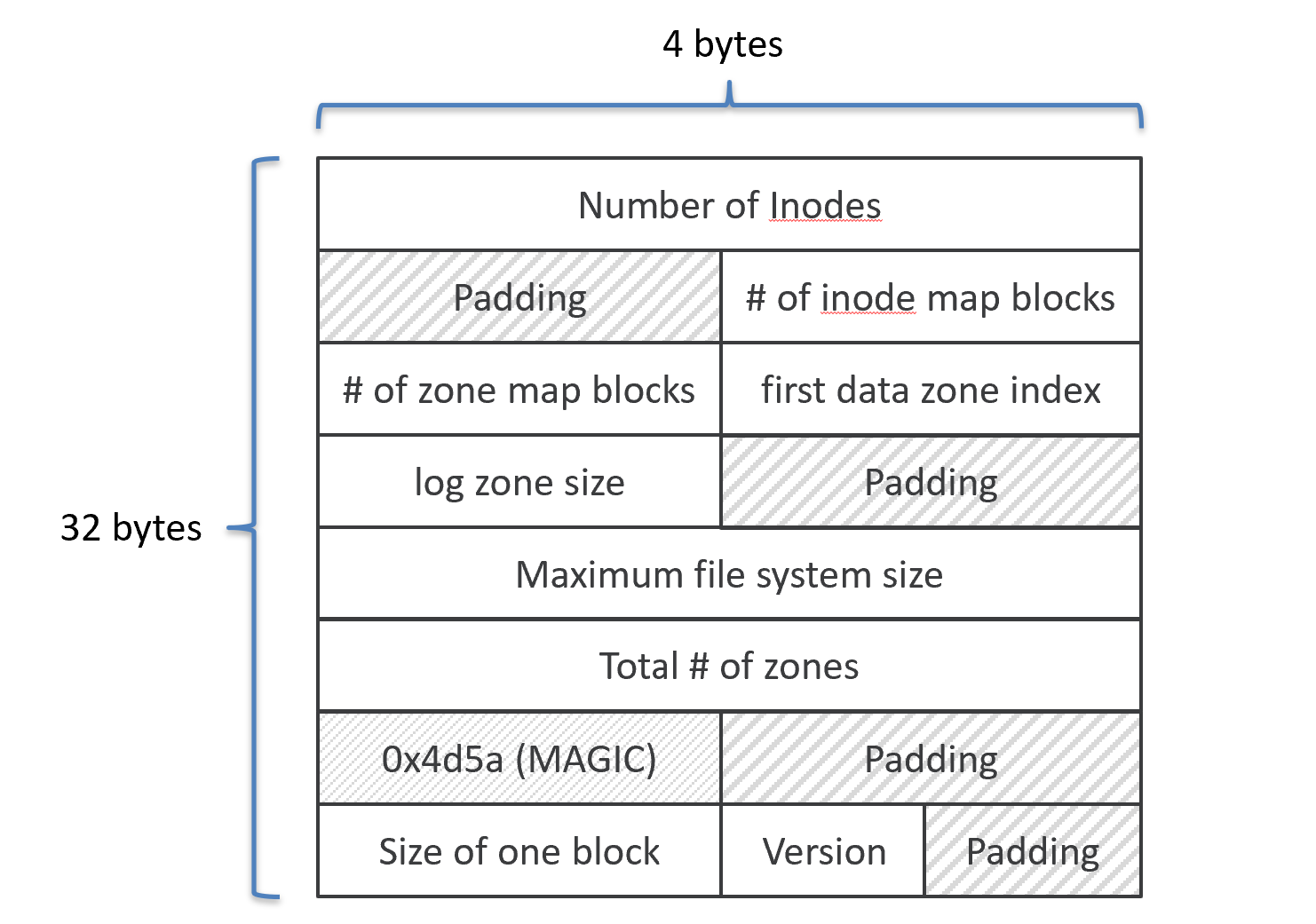
-
inode 블록 : Index node의 준말이며 권한, 소유자, 크기 등 파일에 대한 메타데이터와 해당 파일을 구성하는 실제 데이터가 있는 블록들의 위치를 보관한다.
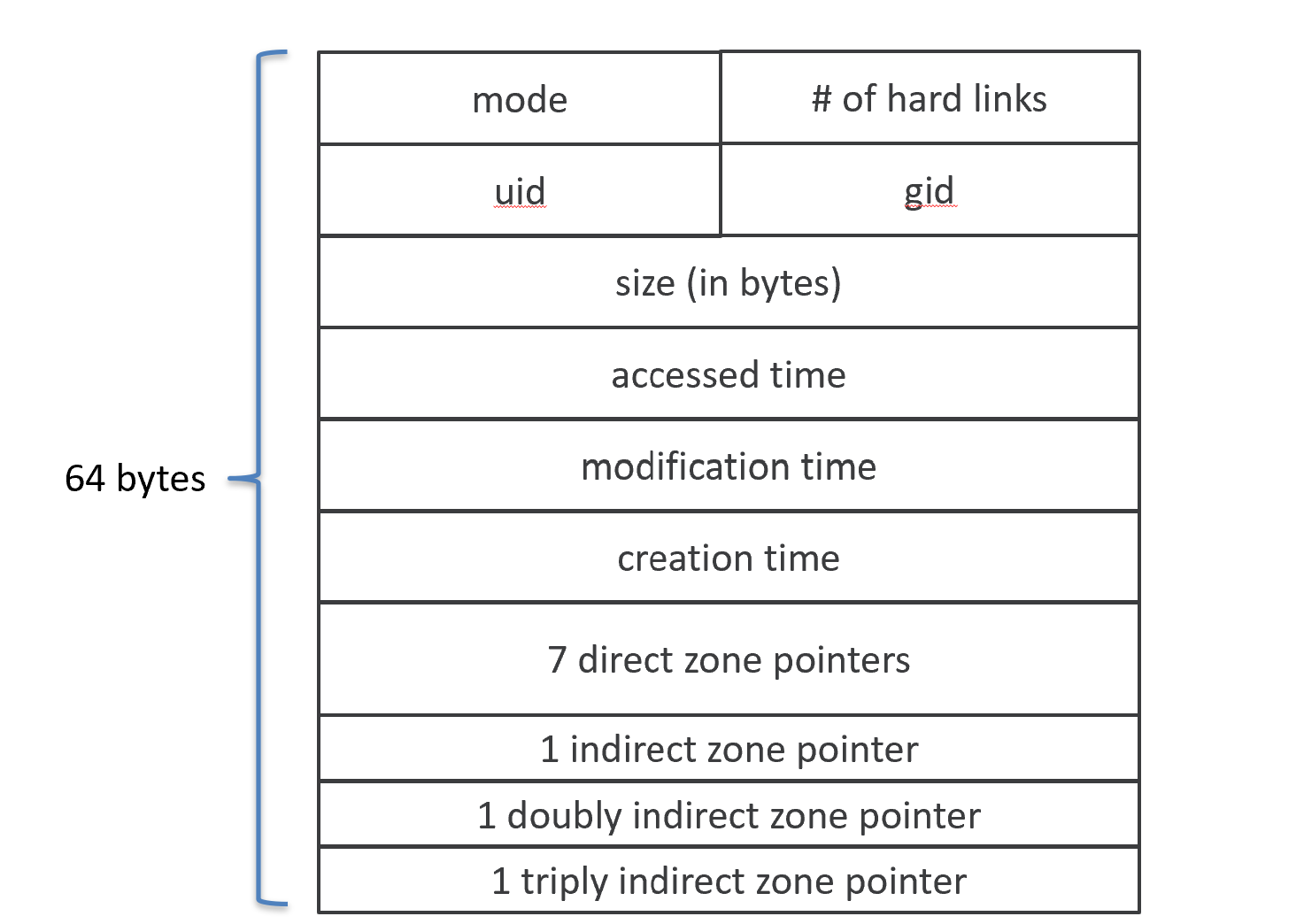
-
data 블록 : 실제 데이터
Direct pointer & Indirect pointer
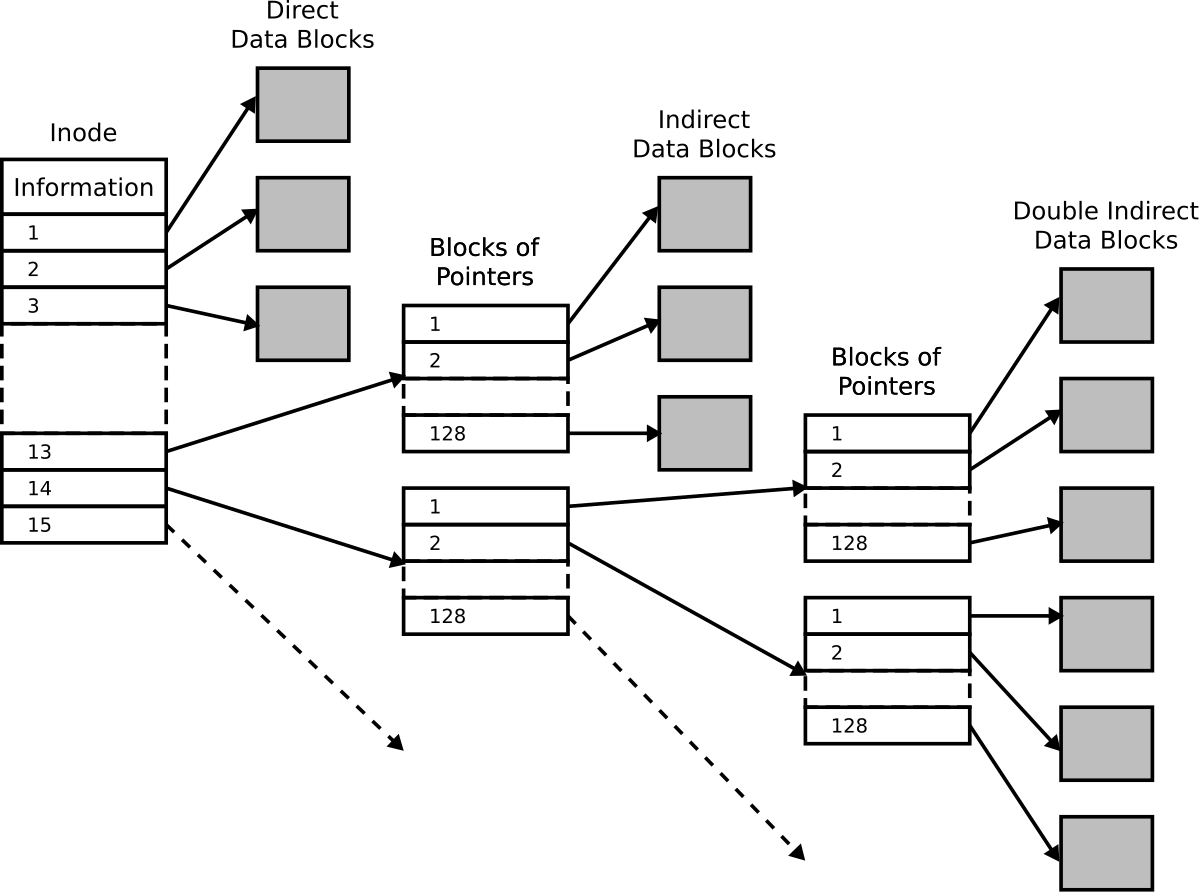
Inode 블록 내에 실제 데이터 블록들의 주소부는 크게 direct/indirect 방식으로 나뉘어있는데, direct 방식은 해당 주소를 찾아가면 바로 실제 데이터 블록이 나온다. 반면, indirect 방식은 해당 주소를 찾아가면 실제 데이터 블록의 주소를 가지고 있는 리스트가 나오고, 해당 리스트의 각 요소들이 각각 하나의 실제 데이터 블록을 가리킨다. Double indirect 방식이라면 리스트를 2번 거치고 실제 데이터 블록을 찾아가게 된다.
왜 이렇게 하는가?
파일의 크기가 커짐에 따라 Inode의 실데이터 블록 주소부도 무작정, 무한정 커지게 한다면 파일 크기에 따라 Inode 블록크기가 제각각이 되어 그 관리를 위해 추가적인 데이터를 또다시 필요로 하게 된다. 제한된 크기의 Inode 블록 안에 최대한의 정보를 욱여넣을 때 indirect 방식을 사용한다면 Inode 블록 외부에 연관된 리스트를 만들어 두는 것으로 간단히 해결할 수 있다. 물론, 이것도 무한정 커지는 파일 크기에 대한 완벽한 해결책은 될 수 없기 때문에 모든 파일 시스템은 maximum file size를 가진다. 예를 들어, FAT32구조에서는 파일을 2GB 밑으로 잘라넣으라고 하는 말이 그래서 나오는 말이다.
Directory Entry (dentry)
사용자의 탐색 위치는 디렉토리(폴더) 기반으로 이루어지는데 반해, Super block에도, Inode block에도, Data block에도 어떤 폴더 내에 어떤 파일이 있는 지에 대한 정보는 존재하지 않는다. 그래서 이를 따로 관리하는 녀석이 있는데, 그게 Directory Entry이다.
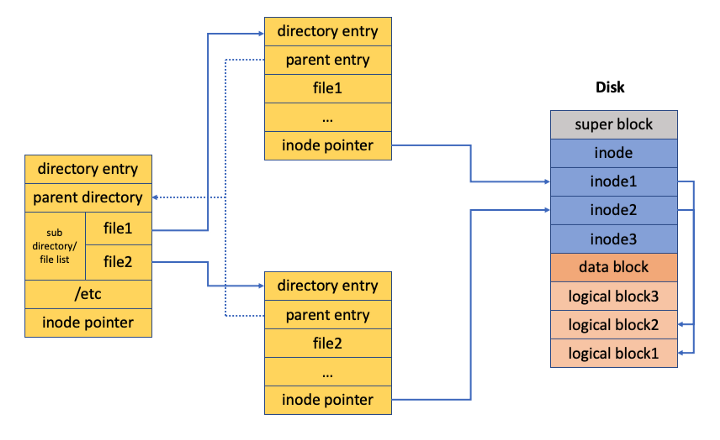
Dentry에는 파일 이름, inode 포인터, 다른 디렉토리 항목 등이 저장된다. inode와는 다르게 메모리 내에 존재하며 커널에 의해 유지/관리 되므로 directory entry cache라고도 한다.
Link
파일의 내용을 그대로 긁어다가 붙여넣는 복사와는 다르게 파일의 접근 경로를 추가하는 방법을 link라고 한다. linking 파일이 목표 inode에 직접/간접적으로 접근하는가에 따라 2종류로 나뉜다.
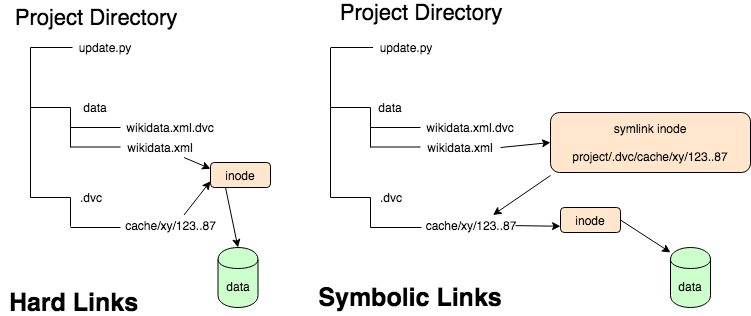
Hard link
Link 파일이 원본 파일이 가리키고 있던 inode를 그대로 가리킨다. 결국 동일한 데이터를 가리키는 것이기에 원본이던 Link이던 한 쪽으로 수정하면 다른 쪽으로 확인해봐도 수정된 데이터가 보인다. 최종 데이터에 접근 할 수 있는 경로 자체가 늘어난 것이므로 원본 파일을 삭제해도 여전히 데이터에 접근 할 수 있다. 백업 등의 용도로 사용된다.
Soft link (Symbolic link)
데이터에 대한 접근 경로 자체를 추가하는 Hard link와는 다르게 접근 경로는 여전히 하나이지만, 그 접근 경로로 접근하는 경로를 추가하는 것이 soft link이다. 바로가기 생성을 생각하면 이해가 빠르다. 역시 최종적으로는 같은 데이터에 접근하므로 한 쪽을 수정하면 다른 한 쪽도 수정되지만, 이 경우 원본 파일을 삭제하면 linking file입장에서는 최종 데이터로 갈 수 있는 접근로가 사라진 것이므로 최종 데이터로의 접근이 불가하다. 바로가기 생성 용도로 사용된다.
UNIX 계열 OS에서의 파일
- 보통 읽고/쓰기에 사용하는 파일 뿐만 아니라 디바이스 등을 포함해 모든 것은 파일이라는 원칙.
- 동일한 시스템 콜을 사용해서 다양한 파일 시스템 지원 가능.
- How? read/write 시스템 콜 호출 시, 각 기기 및 파일 시스템에 따라 실질적인 처리를 담당하는 함수를 내부에서 호출하는 방식으로 구현.
특수 파일
모든 것을 파일로 다루기에 I/O 디바이스마저 파일로 취급되고 조작이 이루어진다. 이 디바이스 파일을 특수 파일로 취급하며 크게 block device와 character device로 나뉜다.
- Block device는 HDD, SSD, CD/DVD와 같이 블록 또는 섹터 등 정해진 단위로 데이터를 전송하며, I/O 송수신 속도가 높다.
- Character device는 키보드, 마우스 등으로 byte 단위로 데이터를 전송하며, I/O 송수신 속도가 낮다.
References
File Systems: https://web.eecs.utk.edu/~smarz1/courses/cosc361/notes/llfs/
File Systems: https://www.csie.ntu.edu.tw/~pangfeng/System%20Programming/Lecture_Note_2.htm
Linux — File System Deep Dive: https://medium.com/geekculture/linux-file-system-deep-dive-fff99c738187
