개요
Spring Batch는 일반적으로 대용량의 데이터를 처리할 때 이용한다.
예를 들어, 1일 1회 외부 api를 통해 대량의 데이터를 받아 일괄처리를 해야 하는 경우.
매일 생성 기간이 일정 이상 지난 오래된 데이터를 일괄 정리하는 경우 등.
하지만 단순 대량 처리를 할 뿐이라면 꼭 Spring Batch를 사용할 필요는 없다.
Batch Framework가 대량 처리를 특출나게 빠르게 해준다거나 하는 건 아니기 때문.
Spring Batch가 유용한 이유는 따로 있다.
예를 들어, 약 100만 건의 데이터를 일괄처리한다고 해보자.
90만 건 째를 처리하다가 오류가 발생해 처리 작업이 중단되었다.
그래서 해당 오류의 발생 원인을 찾아서 해결했다.
이제 어떻게 해야 할까?
같은 작업을 다시 한번 지시하면 될까?
90만 이전까지는 이전과 동일한 데이터로 덮어 씌워지고, 90만부터는 수정을 하게 하면 되나?
DB의 수정 결과는 의도한 것과 동일한 상태가 되겠지만, 너무 비효율적이라고 생각이 된다.
그러면 코드를 살짝 수정해서 90만번 째 데이터부터 작업을 시작하게끔 하면 되나?
중복 작업을 하지 않으므로, 이전보다는 나아보인다.
하지만 오류가 많이 발생한다면? 90만에 1번, 90만 5천에 1번, 91만에 1번...이런 식으로 한 10개 쯤 발생한다면?
그때마다 코드를 수정할 건가?
발상을 바꿔보자.
만약 실행 결과(완료/중단 등)와 마지막 종료 위치 등을 추적하고 기록한다면 어떨까?
90만 건 째에서 중단이 되었다면, 그걸 기록하는 것이다.
작업ID: 230115상태: 중단종료 위치: 900000
대충 이런 느낌으로.
그리고 동일 작업ID로 작업 명령이 내려졌을 시, 상태: 완료가 존재하지 않는다면 마지막 종료 위치부터 작업을 재실행하게끔 설계를 하는 것이다.
그러면 재실행 시 중복 작업도 없어지고, 매번 코드를 메뉴얼하게 수정하는 불편함도 사라진다.
이런 기능을 기본적으로 제공해주는 것이 바로 배치 어플리케이션이고,
배치 어플리케이션의 작성에 편의를 부여해주는 여러 모듈이 있는데, 그 중 Spring 진영에 속해있는 녀석이 Spring Batch이다.
배치 어플리케이션의 요구사항
배치 어플리케이션은 특정한 용도로 쓰이는 경우가 많기 때문에 여러모로 신경써야 할 것들이 있다.
- 자동화: 몇몇 예외를 제외하고는 유저와 상호 작용 없이 동작해야 한다
- 대용량 데이터 처리: 대용량의 데이터를 처리 할 수 있어야 한다.
- 성능: 정해진 시간 안에 작업을 처리해야 하고, 동시에 실행되는 다른 어플리케이션을 방해해서는 안된다.
- 신뢰성: 실행 결과에 대한 기록이 남아야 하고, 잘못된 부분에 대해서는 로깅, 알림 등으로 추적 가능해야 한다.
Spring Batch Architecture
하이 레벨에서의 Spring Batch는 다음의 구조를 갖는다.
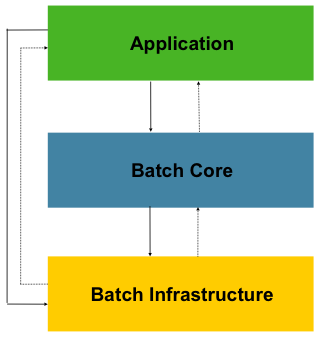
Application Layer: Batch Job과 Custom code가 여기 들어간다.
Batch Core: Batch Job의 실행과 제어에 필요한 핵심 런타임 클래스들이 들어간다. JobLauncher Job Step의 구현도 여기 포함된다.
Batch Infrastructure: Application과 Core framework에 의해 사용되는 reader writer service 등이 들어간다.
Batch Reference Architecture
아래는 Spring Batch 뿐만 아니라, COBOL C C# 등의 다양한 언어로 작성되기도 했던 Batch Processing의 전형적인 구조를 나타낸다.
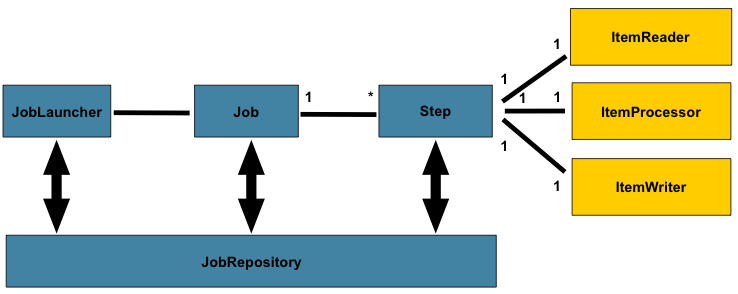
Job은 1개 이상의 Step으로 구성될 수 있으며,
각 Step은 1개 씩의 ItemReader ItemProcessor ItemWriter를 갖는다.
Job은 JobLauncher를 통해 런칭되어야 하며,
현재 실행 중인 프로세스에 대한 메타 데이터는 JobRepository에 저장된다.
Batch Components
Batch의 구조는 대강 알았으니, 구성요소들에 대해서 알아보자.
Job
해당 배치 프로세스 전체를 캡슐화하는 일종의 Entity이다.
보다 쉽게 설명하자면 정산, 외부 api 데이터 업데이트 등 Batch Process를 통해 수행하고자 하는 일을 말한다.
어떠한 Job에 대한 정의는 XML/Java Configuration 파일을 통해 할 수 있다.
Spring Batch에서의 Job은 간단히 Step 인스턴스들을 담고 있는 컨테이너이다.
포함된 Step들의 순서를 정의하고, 재시작 여부를 결정하거나 한다.
그러므로 실질적인 업무 처리는 Step 내에서 이루어진다.
JobInstance / JobParameters
JobInstance는 Job에 대한 논리적 작업 단위이다.
예를 들어, 일일 결산이라는 Job에 대한 JobInstance는 하루 1개씩 생성되야 할 것이다.
내일도, 모레도 동일한 Job이 실행되겠지만, 그에 대한 Instance는 하루에 하나.
왜? 일일 결산이니까.
그럼 어제의 JobInstance와 오늘의 JobInstance, 내일의 JobInstance는 어떻게 구분하느냐.
각 Job Instance에 고유성을 부여해주는 것이 JobParameters이다.
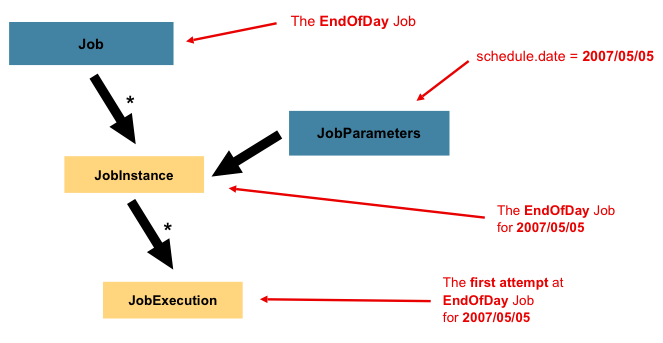
JobParameters는 Job을 처리하기 위해 필요한 패러미터들이다.
Job은 그저 Configuration을 통해 정의한 할 일의 명세서 따위에 불과하기 때문에 실질적인 실행을 위해서는 JobInstance를 생성해 실행해야 하는데, JobParameters는 해당 Job을 처리하기 위해 필요한 패러미터이기 때문에 Instance를 만들 때 주입되게 된다. 그렇기에 각 JobInstance는 각각의 JobParameters를 가지고 있고, 이를 통해 고유성을 부여받게 된다. 다시 말해, 동일한 JobParameters를 가지고 있는 2개의 JobInstance는 있을 수 없다. 이 둘은 1:1 관계이기 때문이다.
JobParameter로 사용 가능한 타입은 Long Double String Date 이다.
모든 JobParameter가 JobInstance의 고유성에 관여하는 것은 아니다. 기본값은 '관여한다'이지만 설정을 통해 바꿀 수 있다.
또한 JobParameters의 사용을 위해서는 JobScope나 StepScope를 함께 사용해야 하는데, Parameter의 생성은 Scope의 생성시점에 함께 이루어지기 때문이다.
JobExecution
실질적인 실행 시도이다. 하나의 시도는 성공/실패의 결과를 가지게 된다.
하지만 JobExecution에 연관된 JobInstance는 해당 시도가 성공하지 않으면 완료된 것으로 간주되지 않는다.
일일 결산의 예를 다시 보자.
업무 중 '일일 결산' (Job)이 있어, '오늘의 일일 결산' (JobInstance)을 '진행했다' (JobExecution).
그런데 실패를 해서 재시도 (JobExecution)를 했다. 이걸 내부적으로 어떻게 이해해야 하는가?
-> 동일한 JobInstance가 새로운 JobExecution을 생성했다.
Step / StepExecution
Job은 Step의 묶음이라고 말한 바 있다.
일일 결산을 한다고 하면, 우선 당일의 거래 내역을 모두 읽고, 적절한 처리를 해 결산 데이터를 만든 다음, 이를 저장하던지 아니면 해당 정보가 필요한 다른 서버에 보낼 것이다.
이 하나하나의 단계가 하나하나의 Step이다.
StepExecution은 JobExecution의 Step 버전이라고 할 수 있는데, 여러 개의 Step이 순차적으로 동작하다 보니 특징이 하나 있다.
바로 StepExecution은 해당 Step이 실제로 실행될 때 생성된다는 것이다.
예를 들어 1-1, 1-2 Step이 있는데 1-1의 실행 중에 실패했다고 하자.
Step은 순차적으로 실행되는데 1-1이 실패했으니 1-2도 자연스레 실패하게 된다.
하지만 이때, 1-2의 StepExecution은 생성되지 않았다는 소리이다.
왜? 애초에 실행이 되지 않았으니까.
ItemReader / ItemWriter
DB, File 등의 Data source로부터 데이터를 읽어오거나 쓸 수 있는 컴포넌트이다.
이용하는 Driver, I/O 방식 등에 따라 여러가지로 나뉘는데 간단히 정리하자면,
File, DB, XML를 대상으로 I/O를 한다.
자세한 목록이 궁금하면 여기를 살펴보자.
ItemReader와 ItemWrite의 기본 Interface 구조는 다음과 같다.
public interface ItemReader<T> {
T read() throws Exception, UnexpectedInputException, ParseException,
NonTransientResourceException;
}
public interface ItemWriter<T> {
void write(Chunk<? extends T> items) throws Exception;
}ItemProcessor
Reader Writer가 입출력 담당이라고 하면, Processor는 처리 담당이다. Reader와 Writer 사이에서 연결점 역할을 하며 필요한 가공/처리를 한다.
입력/가공/출력이 분리되어 있기에 비즈니스 로직을 삽입하기 유리하고, 입출력의 형식이 다른 경우 어댑터의 역할을 수행하기에도 좋다.
경우에 따라서는 Processor가 존재하지 않기도 하다.
ItemStream
데이터의 입출력에는 각각 ItemReader와 ItemWriter를 쓴다. 서로 사용 목적은 다르지만, 공통적인 부분이 있다.
바로 데이터의 입출력이 있기 전에 데이터 소스와의 채널이 open되어야 한다는 점, 끝나면 close되어야 한다는 점, 그리고 진행 상태를 유지해야 한다는 점들이다.
이러한 기능들은 ItemStream을 통해 제공된다.
public interface ItemStream {
void open(ExecutionContext executionContext) throws ItemStreamException;
void update(ExecutionContext executionContext) throws ItemStreamException;
void close() throws ItemStreamException;
}ExecutionContext를 이용해 진행 상태를 연속적으로 저장, 재오픈 시에 ExecutionContext 안에 진행 상태에 대한 정보(e.g. LINES_READ_COUNT=10000)가 있다면 처음부분이 아니라 해당 부분부터 입출력이 시작된다.
ExecutionContext
key/value 형태로 제공되는 데이터 콜렉션으로 JobExecution 혹은 StepExecution 범위에서 영속적으로 저장되었으면 하는 데이터를 저장하고 읽을 수 있다.
프레임워크에 의해 유지 및 관리되고, 중간중간의 커밋 때 주기적으로 저장된다.
Job 내지는 Step이 각종 이유로 실패했다고 해도 상태 정보를 유지할 수 있기 때문에, 바로 위에서 예로 든 최근에 중단된 라인부터 읽기/쓰기 재시작 따위의 일이 가능해진다.
JobLauncher
Job과 JobParameters를 패러미터로 해서 Job을 실행한다.
주어진 패러미터를 이용해 JobRepository로부터 유효한 JobExecution을 획득해서 Job을 실행한다.
public interface JobLauncher {
public JobExecution run(Job job, JobParameters jobParameters)
throws JobExecutionAlreadyRunningException, JobRestartException,
JobInstanceAlreadyCompleteException, JobParametersInvalidException;
}Chunk-oriented Processing
Step의 실행 방식 중 하나이다.
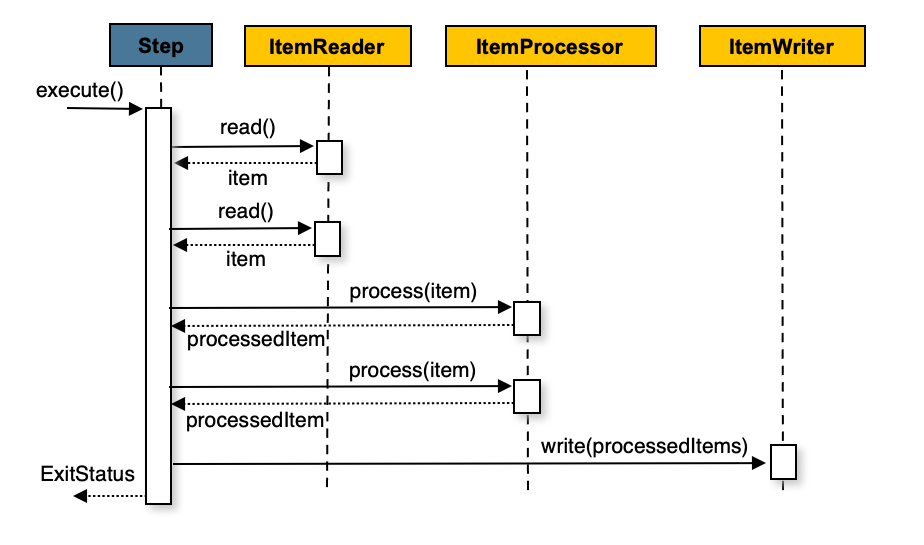
N번의 read, N번의 process, 1번의 write라는 여러 개의 task를 하나의 step에서 실행한다.
맨땅에서 step을 설계하는 거라면, 기본적으로 이 방식이 가장 효율적이다.
TaskletStep
Step의 또 다른 실행 방식이다.
외부에 배치 처리를 위한 메소드나 프로시저가 이미 존재하고, 그걸 단순히 call하는 것이 필요할 뿐이라면 Tasklet을 사용하는 것이 좋다.
Tasklet은 인터페이스이며 execute라는 단 하나의 메소드만을 가지고 있다.
이 친구는 RepeatStatus.FINISHED응답이 나오거나 예외가 발생하기까지 TaskletStep에 의해 계속해서 호출된다.
실습
여기까지 Spring Batch의 구성 요소들에 대해 간단히 알아봤다.
모든 구성 요소를 다뤘다고 하기에는 어폐가 있지만, 적어도 배치 처리를 하기 위한, Spring Batch를 다루기 위한 아주아주 기본적인 용어와 개념에 대해서는 다룬 것 같다.
이제부터는 실습을 통해 실질적인 구현을 어떻게 하는지 알아보...려고 했으나 글이 너무 길어진 관계로 다음 편으로 미루겠다.
References
- Spring Batch - Reference Documentation: https://docs.spring.io/spring-batch/docs/current/reference/html/index-single.html
- Spring Batch 가이드 - https://jojoldu.tistory.com/324
