
REDIS(REmote Dictionary Server)
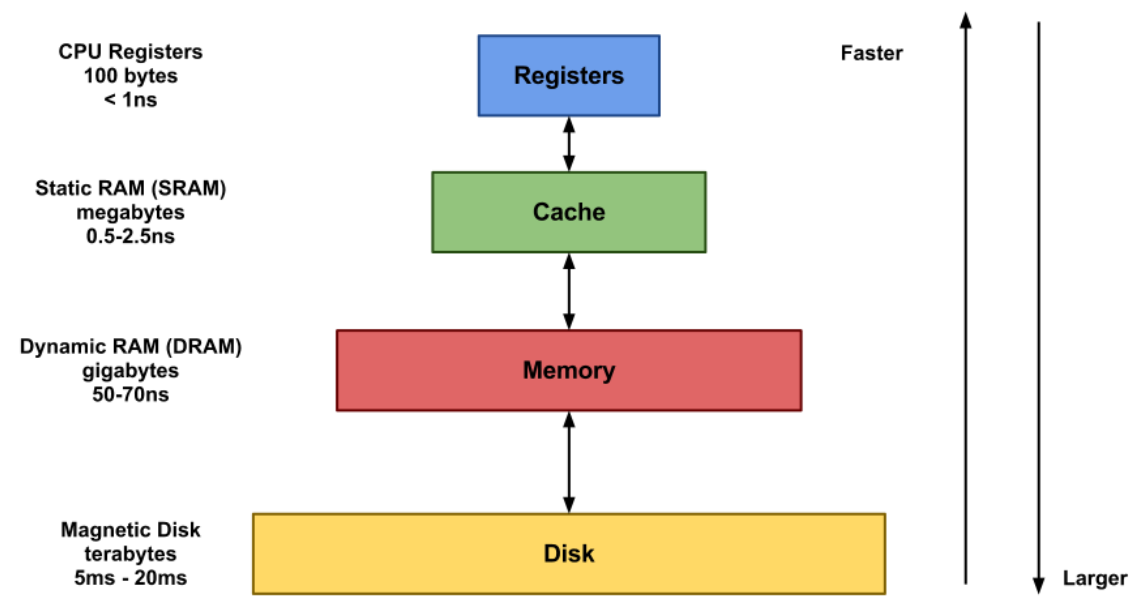
In Memory 데이터베이스
데이터를 Disk에 저장하는 것이 아니라, Memory에 저장했다가 요청이 있을 때, Memory에 있는 데이터를 빠르게 돌려주는 방식의 데이터베이스
- 장점 : Memory가 Disk보다 빠르기 때문에, 고속으로 데이터를 제공할 수 있다.
- 단점 : Memory의 비용이 Disk에 비해 비싸기 때문에, 많은 용량을 사용하기 어렵다.
Key Value Data Store
- key를 바탕으로 데이터를 저장하는 방식
- key는 중복될 수 없다.
- 중복된 key에 데이터를 입력하면 업데이트가 된다. (upsert 의 개념)
- 기본적으로 hash를 통해 검색 → 검색 속도가 빠르다.
사용 사례
- 캐싱 : 자주 사용하는 데이터를 가까운 곳에 저장하는 개념
- 세션 관리
- 세션 : 네트워크에서 정보를 저장하여 사용자를 구별하기 위한 공간
- 세션을 DB에 저장해두고, 읽어오는 속도를 향상시키기 위해 redis로 캐시하여 사용한다.
- pub/sub (구독과 게시)
- 순위표 등
싱글스레드 기반
멀티스레드가 빠른데 왜 싱글스레드 기반을 사용할까?
-> 멀티스레드를 활용할 경우 생길 수 있는 문제점을 줄이기 위해
- 멀티스레드를 활용할 경우 생기는 문제점
- Mutual Exclusion
- Synchronized
- Dead Lock 등
백업 방식
- RDB (Redis DataBase)
- 스냅샷(데이터 전체의 복사본)을 이용하는 방법
- 장점 : 간단하다. 복원할 때, 스냅샷만 복사해서 붙여넣으면 되기 때문
- 단점 : 스냅샷 이전 중간 지점의 데이터로는 복원할 수 없다.
- AOF (Append Only File)
- 변경된 작업을 저장해서 복원 (로그를 보관)
- 장점 : 복원을 할 때, 데이터 유실량이 거의 없다.
- 단점 : 용량이 커지고 시간이 오래 걸린다.
- 일반적으로 둘 다 사용, 일 단위로 스냅샷을 찍고, 일 단위로 로그를 기록한다.
기타
- BSD 라이선스(오픈 소스)
- C언어로 만들어져 있으며, 여러가지 프로그래밍 언어를 지원
- 퍼블릭 클라우드에서도 유사한 서비스를 지원
- ex) AWS, Elastic Cache
- 클러스터 기능을 제공 - 확장이 가능
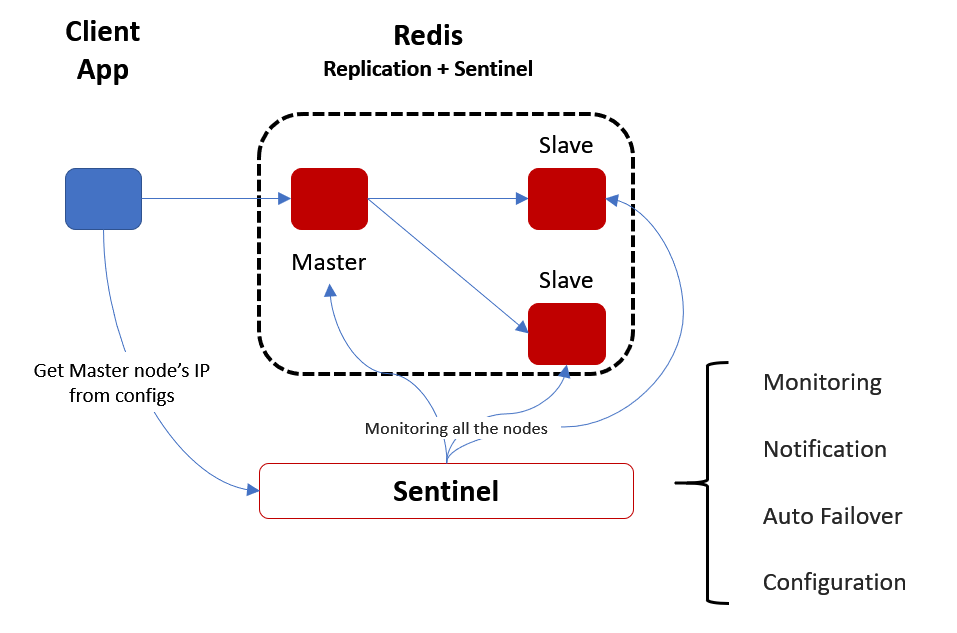
Redis Sentinel Architecture
- 실제 구현을 할 때는 Master 와 Replica 서버를 만들어서 Master에 작업을 수행하고 Master에 변경이 생기면 Replica 서버에 복제하는 방식으로 구현
- Master 에 장애가 발생하면, Replica 서버가 Master 가 되도록 해서 장애에 대비한다.
📌 참고 자료
- IT깡패 블로그 : Redis
https://ggangpae1.tistory.com/617
