Visualization 시각화
using Matplotlib, Seaborn
본격적으로 데이터와 AI를 다루기 전에, 데이터를 적절한 방법으로 시각화하여 분석하는 과정이 필요하다.
따라서, matplotlib 와 seaborn 라이브러리를 활용하여, 데이터를 시각화 하는 방법에 대해 학습했다.
✔️ matplotlib 와 seaborn 설치하기
우선, matplotlib 와 seaborn 각각을 사용하기 위해서는, pip 명령어를 통해 설치하는 과정이 필요하다.
▪️ matplotlib install
pip install -U pip
pip install -U matplotlib▪️ seaborm install
pip install seaborn✔️ matplotlib 와 seaborn 의 사용
Python 의 import를 통해 사용하고, as를 통해, 각각 plt과 sns로 줄여 사용한다.
import matplotlib.pyplot as plt
import seaborn as sns✔️ matplotlib 기본 사용
▪️ plot 그리기
import matplotlib.pyplot as plt
x = [0,1,2,3,4,5]
y = [123,1,59,40,10,100]
# line plot
plt.plot(x,y)
plt.show()
# bar plot
plt.bar(x,y)
plt.show()
# scatter plot
plt.scatter(x,y)
plt.show()▪️ 여러개의 plot 그리기
subplots()을 이용하여 여러개의 plot을 그릴 수 있다.
fig, axs = plt.subplots(a, b)
: a x b 행렬 형태의 subplots을 만든다.
axs[i][j].plot(x,y)
: 각 subplot에 plot을 그려 넣는다.
import matplotlib.pyplot as plt
x = [0, 1, 2, 3, 4, 5]
y = [123, 1, 59, 40, 10, 100]
fig, axs = plt.subplots(2, 3, figsize=(10, 4))
axs[0][0].plot(x, y)
axs[0][2].bar(x, y)
axs[1][1].scatter(x, y)
plt.show()💻 결과
▪️ title, x,y label 달기
import matplotlib.pyplot as plt
x = ["Tom","Amy","Jim","Bill","Pegi"]
y = [8,23,52,37,64]
plt.bar(x, y)
# font
font = {'color': 'gray', 'size':14}
# title
plt.title("Sales Performance")
# x축 label
plt.xlabel("Salesperson", font, labelpad=15)
# y축 label
plt.ylabel("Revenue (1000 $)", font, labelpad=15)
plt.show()💻 결과

✔️ seaborn 기본 사용
▪️ plot 그리기
kernel density plot
import matplotlib.pyplot as plt
import seaborn as sns
# 내장 데이터셋 가져오기
tips = sns.load_dataset("tips")
# kernel density plot
sns.kdeplot(data=tips, x="total_bill")
plt.show()💻 결과

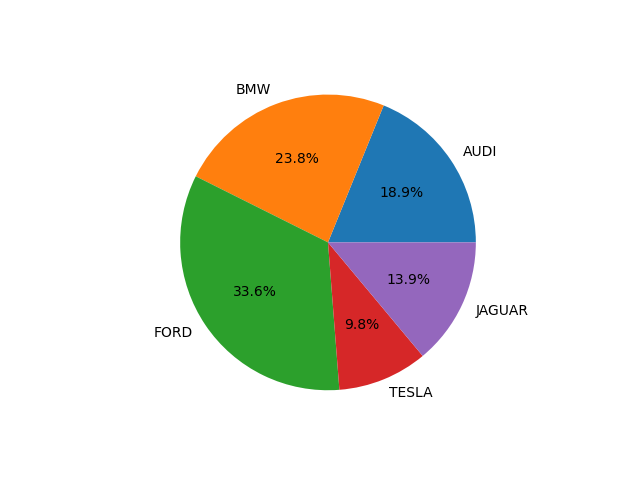
pie chart
import matplotlib.pyplot as plt
import seaborn as sns
cars = ['AUDI', 'BMW', 'FORD', 'TESLA', 'JAGUAR']
data = [23,29,41,12,17]
# pie chart plot
plt.pie(data ,labels=cars, autopct='%.1f%%')
plt.show()💻 결과
✔️ Titanic Data 분석
Titanic Data (train.csv) : https://www.kaggle.com/competitions/titanic/data
타이타닉호 탑승객들의 탑승 Class에 따라, 생존률이 어떻게 나타나는 지를 분석한다.
import matplotlib.pyplot as plt
import pandas as pd
# Read data from CSV file
df = pd.read_csv('train.csv')
# Initialize x and y variables
x = []
y = []
# Loop through each class and calculate survival rate
for i in range(1,4):
number_of_passengers = len(df[df['Pclass'] == i])
number_of_survivers = len(df[(df['Pclass'] == i) & (df['Survived'] == 1)])
x.append(i)
y.append(number_of_survivers / number_of_passengers * 100)
# Plot bar chart
plt.bar(x, y)
# Set y-axis limit
plt.ylim(0,100)
# Set x-axis tick labels
plt.xticks([1, 2, 3], ['1st Class', '2nd Class', '3rd Class'])
# Add text annotation on each bar
for i, v in enumerate(y):
plt.text(x[i], v + 2, str(round(v, 2)) + '%', ha='center')
# Display the plot
plt.show()💻 결과

1st Class 승객들의 생존률은 62.96%로 나타난 반면, 3rd Class 승객들의 생존률은 그의 절반 이하인 24.24%로 나타난 씁쓸한(?) 결과를 얻을 수 있었다.
