Improving modularity score of community detection using memetic algorithms
연구 요약
Community Detection에서 Memetic Algorithm은 GA 기반의 다른 방법들보다 안정성과 강력함 측면에서 더 우수하다.
Community Detection
네트워크에서 연관성이 높은 노드들을 그룹화하는 작업이다. 이때 그룹화의 척도는 Modularity라고 하며, Modularity를 최대화하는 것은 NP-Hard 문제이다.
Metaheuristic Algorithms 사용 이유
기존의 Girvan-Newman 알고리즘은 많은 컴퓨터 자원을 소모하고, Clauset, Newman, Moore 알고리즘은 지역 최적값에 쉽게 빠지는 경향이 있어 Metaheuristic Algorithms에 주목하게 된다. 또한, GA 기반 방법은 글로벌 옵티멈에 도달하는 데 시간이 오래 걸리고, 조기 수렴의 위험이 있다. 특히, 문제가 다중 봉우리(Multi-peak)일 경우 더욱 그러하다. 또한 글로벌 옵티멈 근처를 빠르게 찾는 데 능숙하지만, 수렴 영역 내에서 정확한 로컬 옵티멈을 찾는 데는 상당히 오랜 시간이 소요된다. 이때, Local search를 활용한 하이브리드 접근법은 GA가 유리한 영역으로 유도한 솔루션을 개선하는 데 도움을 주어 전역 최적값에 수렴하는 과정을 가속화할 수 있다.
Modularity Q 공식
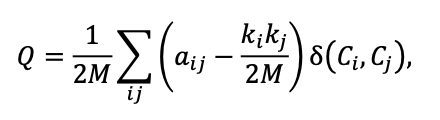
Memetic Algorithm
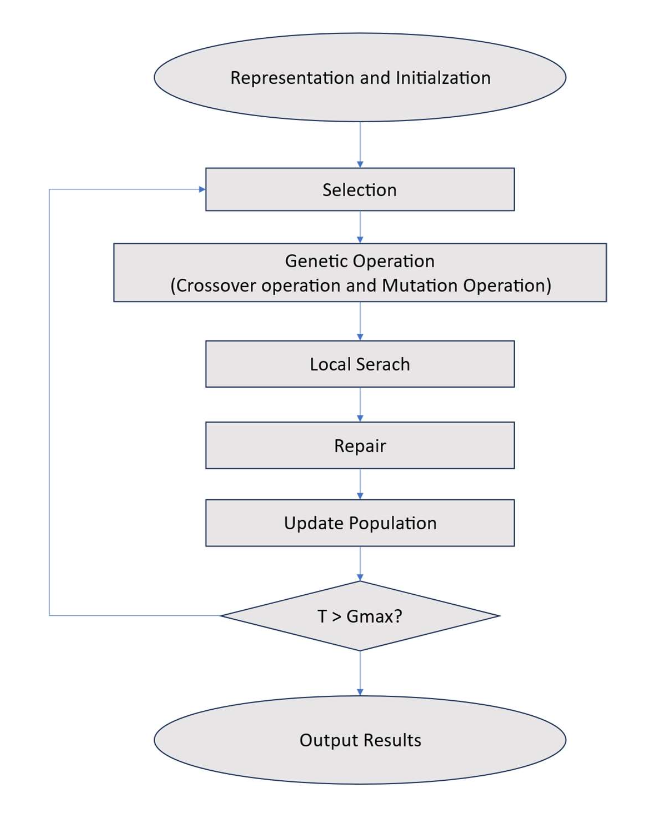
Selection: Tournament selection(일부 뽑아서 가장 좋은 개체 선택)
Crossover: Uniform crossover(각각의 유전자 랜덤하게 교차)
Mutation: Random Resetting(랜덤 유전자 다른 라벨로 변경)
Repair: 빠진 라벨 추가
Local search: Stochastic hill climbing(SHC)
SHC Algorithm
Hill Climbing : 언덕을 오르듯 현재 상태에서 더 좋은 이웃 상태로 이동하는 방식.
Stochastic hill climbing: 기본적인 Hill Climbing에서 확률적인 요소를 더한 방식.
import random
def SHC(offspring):
idx = random.randrange(len(offspring))
neighbor = offspring[:]
current_modularity = Q(offspring)
change = []
for label in range(num_label):
neighbor[idx] = label
delta_modularity = Q[neighbor] - current_modularity
change.append(delta_modularity)
max_idx = change.index(max(change))
offspring[idx] = max_idx현재 offspring(개체)에서 랜덤하게 선택한 유전자를 모든 라벨로 변경해보며 가장 좋은 라벨로 교체한다.
결과

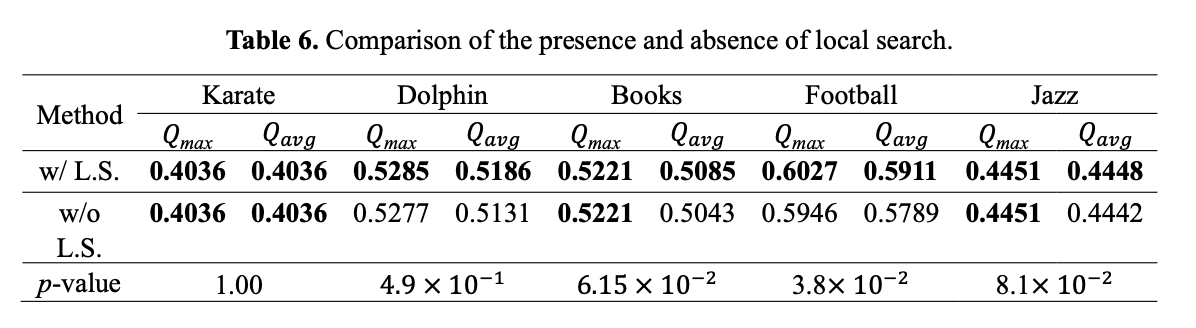
기존의 다른 알고리즘들과 비교했을 때, 몇몇 데이터 셋에서는 최대 최적값에서 약간 떨어지기도 했지만, 다른 데이터 셋에서는 가장 우수한 결과를 보였다.
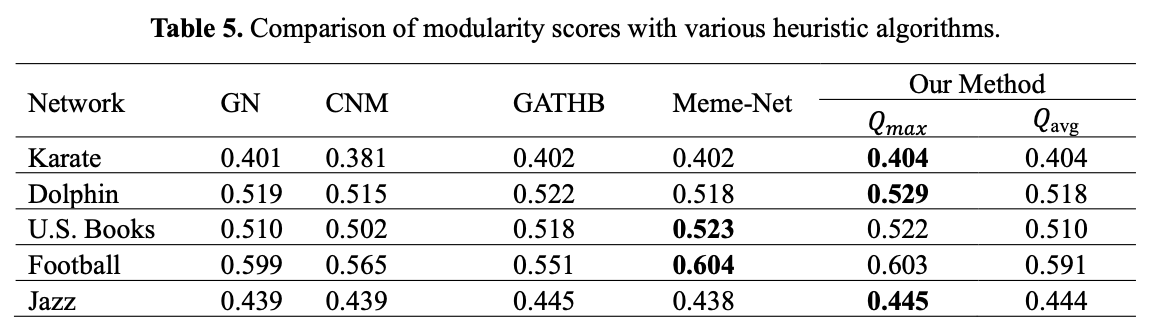
local search를 적용한 경우와 적용하지 않은 경우를 비교한 결과, local search가 최적값을 찾는 데 도움을 줄 뿐만 아니라 안정성 측면에서도 유리하며, 최적값에 더 빠르게 도달하는 성과를 보였다. 이러한 성과는 복잡한 네트워크에서 더욱 두드러졌다.
논문 출처
https://www.aimspress.com/article/doi/10.3934/math.2024997
코드
https://github.com/taeseokyang/A-Memetic-Algorithm-for-Community-Detection-in-Networks

파이팅!!