
렌더링 동작원리 node 간단 설명.
브라우저 동작원리를 기본적으로 알고 계신 분이라면 렌더링 되는 과정에서 파싱을 통해 DOM Tree가 구축이 된다. ( 이후에 렌더트리가 구축 👉🏻 배치 👉 그리기 를 통해 화면에 보여진다.)
작성한 HTML 마크업을 '브라우저가 이해할 수 있는 객체 구조'로 변환하는데 이것이 DOM
브라우저 동작원리
DOM : HTML 마크업이 각각의 노드로 변환된다.
DOM문서는 node의 계층 구조로 이루어져 있다.
이미지로 살펴보자.
계층 구조
HTML 파일 안에 작성된 문자열이 각각의 노드로 변환 되는 것을 보여준다.
( 주석도 노드로 변환된다. )
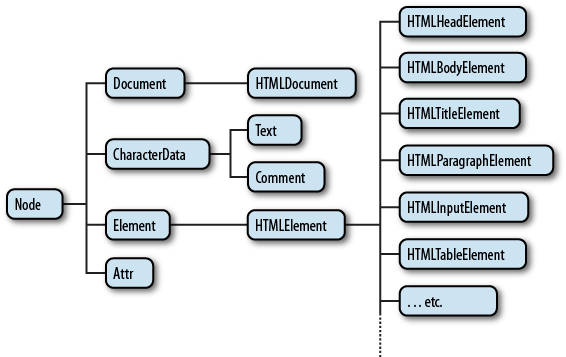
node vs element
위 이미지를 보면 element는 node의 유형 중 하나의 타입이다.
결국, node는 element의 상위 개념이다.
element는 html 문서에서
<div></div>이러한 모든 태그를 사용해서 작성된 node라고 설명할 수 있겠다.
node
하나의 HTML 문서가 있다.
<!DOCTYPE HTML>
<html>
<body>
사슴에 관한 진실.
<ol>
<li>사슴은 똑똑합니다.</li>
<!-- comment -->
<li>그리고 잔꾀를 잘 부리죠!</li>
</ol>
</body>
</html>이 문서의 node구조를 한번 보자.
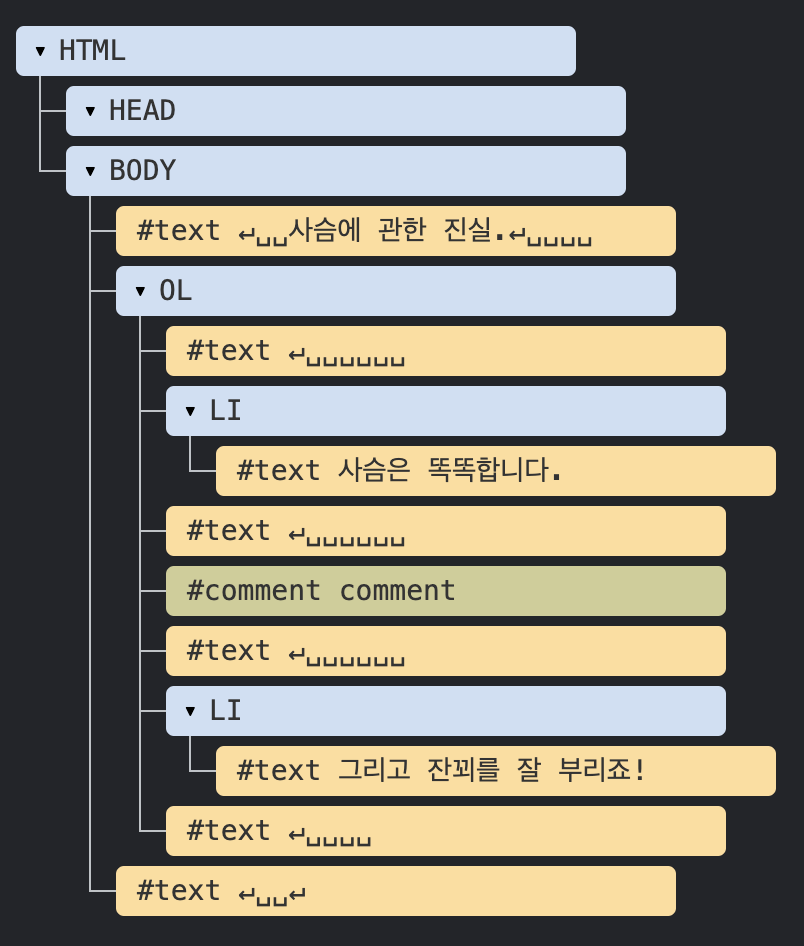
node는 주석, 태그, 텍스트 등.. 모두 포함된걸 볼 수 가 있다.
nodeType 속성을 이용해 구분할 수 있다.
nodeType은 node의 type을 상수로 리턴합니다.
| 유형 | 리턴 상수 값 | 설명 |
|---|---|---|
| Node.ELEMENT_NODE | 1 | <div></div> or <p></p> |
| Node.TEXT_NODE | 3 | text |
| Node.CDATA_SECTION_NODE | 4 | <!CDATA[[...]] > |
| Node.PROCESSING_INSTRUCTION_NODE | 7 | <?xml-stylesheet... ?> |
| Node.COMMENT_NODE | 8 | <!-- comment --> 주석 |
| Node.DOCUMENT_NODE | 9 | document |
| Node.DOCUMENT_TYPE_NODE | 10 | DocumentType node <!DOCTYPE html> |
| Node.DOCUMENT_FRAGMENT_NODE | 11 | DoucumentFragment node |
타입을 확인 할 수 있다.
element
위에 설명한 듯이 결론은,
element는 node의 한 종류이다.
element는 <html> <head> <title> <body> <br/>와 같이 element만 찾는다.
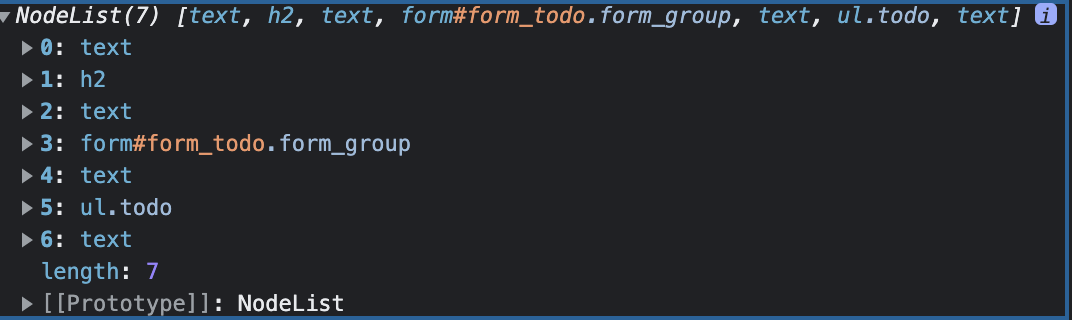
Javascript에서 DOM을 탐색하고, 조작할 때에는 주로 element를 조작하는 경우가 많다.
element를 탐색할 때에는 주석이나 텍스트 등..을 제외한 element만 탐색할 수 있다.
이렇게 같이 비교를 한다면 둘의 차이를 발견 할 수 있다.
- element

- node
끝으로..
다음 블로그는 이 블로그와 관련이 아주 있는 부모, 자식, 형제 노드 찾는 방법을 올려보겠다.
참고 사이트
모던 자바스크립트
