
coordinator한테 회신이 올때까지 기다릴거야 ...
단일 노드 트랜잭션의 원자성, 그리고 그 한계
단일 노드 트랜잭션의 원자성
현대의 데이터베이스 시스템은 단일 노드에서 실행되는 트랜잭션에 대해 원자성(Atomicity) 을 보장한다.
단일 노드에서 실행되는 트랜잭션은 대개 스토리지 엔진 수준에서 다음과 같은 방식으로 원자성이 보장된다.
- 쓰기 작업은 WAL(Write-Ahead Logging)에 먼저 기록된다.
- 로그에 모든 변경 사항을 기록한 후, 커밋 레코드(commit record)를 로그에 추가한다.
- 이 커밋 레코드가 디스크에 영구히 기록되는 순간, 해당 트랜잭션은 커밋된 것으로 간주된다.
- 그 이전에 시스템이 장애로 인해 종료되면, 해당 트랜잭션은 복구 과정에서 undo(rollback)된다.
- 반대로 커밋 레코드가 쓰여진 이후에는 시스템이 죽더라도, 재시작 시 redo 로 복구된다.
즉, 디스크의 커밋 레코드 쓰기 완료 시점이 트랜잭션의 생사(Commit/Abort)를 가르는 결정적인 분기점이다.
분산 트랜잭션의 원자성
하지만, 다중 노드 환경에서 단순히 모든 노드에게 commit 요청을 보내고 각 노드에서 독립적으로 트랜잭션을 commit하는 것만으로는 원자성 보장을 위반하기 쉽다.
다중 노드 환경에서는 트랜잭션에 참여한 모든 노드간의 일관성 또한 보장되어야 하기 때문이다.
다음과 같은 이유로 다중 노드 간의 일관성이 보장되지 않을 수 있다.
- 각 노드들은 독립적인 WAL과 디스크를 갖는다.
- 한번 commit된 트랜잭션은 소급적으로 abort할 수 없다.
(commit 이후, 해당 데이터에 의존하는 트랜잭션이 생길 수 있기 때문)
가령, 일부 commit 요청이 네트워크에서 손실되어 타임아웃으로 abort 되었으나, 다른 commit 요청들은 성공적으로 전달되어 commit 되는 경우에 일관성이 깨지게 된다.
따라서, 다중 노드 환경에서 원자성을 보장하려면 각 노드들은 트랜잭션에 참여하는 모든 노드가 commit될 것이라고 확신할 때만 commit되어야 한다.
이러한 한계를 극복하기 위해, 분산 트랜잭션 환경에서 가장 흔히 사용되는 방법이 Two-phase commit (2PC) 프로토콜이다.
Two-phase commit (2PC)
Two-phase commit(2PC)는 여러 노드에 걸친 트랜잭션의 원자성을 보장하는 분산 알고리즘이다.
2PC는 단일 노드 Transaction에 존재하지 않는 coordinator(트랜잭션 관리자)라는 컴포넌트를 사용한다.
그리고, 트랜잭션에 참여하는 데이터베이스 노드들을 participant(참여자)라고 부른다.
2PC의 동작 흐름
2PC는 이름에서도 확인할 수 있듯이 총 2단계에 걸쳐 트랜잭션을 처리한다.
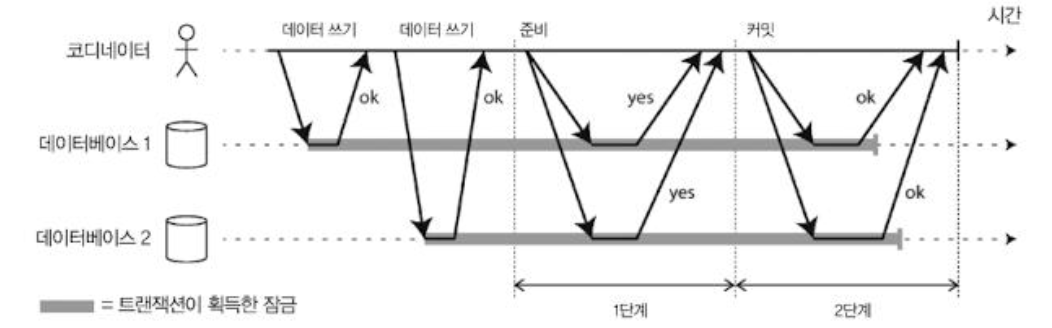
1. 트랜잭션 시작
- 애플리케이션은 coordinator에게 분산 트랜잭션을 시작하기 위해, 고유한 Transaction ID를 요청한다.(이 Transaction ID는 전역적으로 유일하다.)
- 각 참여 노드에서 이 Transaction ID를 붙여, 단일 노드 트랜잭션을 시작한다.
- 이 단계에서 문제가 발생하면, coordinator 또는 participant 중 하나가 abort할 수 있다.
2. Prepare 요청 (1단계)
- 애플리케이션이 커밋할 준비가 되면, coordinator는 모든 participant에 전역 Transaction ID로 태깅된 커밋 준비 요청 메시지를 보낸다.
- 커밋 준비 요청이 실패하거나 타임아웃되면 cooridinator는 모든 participant에게 abort 요청을 보낸다.
- 각 participant는 디스크에 필요한 데이터를 기록하고, 충돌이나 제약 조건 위반을 확인하여, 트랜잭션을 정상적으로 커밋 가능함을 보장할 수 있으면 “Yes”로 응답한다.
- "Yes"로 응답한 후에는 스스로 abort할 수 없다.
3. 최종 결정 및 기록
- coordinator는 모든 participant에게서 “Yes”를 받으면 커밋 결정을 내린다.
- 이 결정은 디스크의 트랜잭션 로그에 기록되며, 이는 커밋 포인트(commit point)가 된다.
- 만약 하나라도 “No”라고 하면 즉시 Abort를 결정한다.
4. 커밋 or 어보트 요청 (2단계)
- coordinator는 참여 노드에 최종 커밋 혹은 어보트 명령을 보낸다.
- 이 요청이 실패하거나 응답이 오지 않으면, coordinator는 성공할 때까지 무한 재시도한다.
- participant는 coordinator로부터 커밋 요청을 받으면 즉시 트랜잭션을 완료한다.
- 도중에 한 participant가 죽었다면, 해당 participant가 복구될 때 commit된다.
- 이미 “Yes”라고 답했기 때문에 커밋을 거부할 수 없다.
이 프로토콜은 2PC의 원자성을 보장하기 위한 2가지 "돌아갈 수 없는 지점"이 있다.
- participant가 "Yes"에 투표하는 순간
- 이 순간 abort 할 권리를 포기하고, 스스로 abort할 수 없게 된다.
- coordinator가 결정을 내리는 순간
- coordinator의 결정은 변경할 수 없다.
2PC의 구조적 한계
Coordinator의 장애로 인한 Blocking 상태
2PC 과정에서 특정 컴포넌트에 문제가 발생했을 때 어떻게 동작하는 지를 정리해보면 다음과 같다.
✅ 1. participant에 문제 발생
- 이 경우, coordinator는 abort 요청을 보낸다.
- 만약, 이 abort 요청이 실패하면, 무한히 재시도 한다.
✅ 2. 투표 이전 coordinator에 문제 발생
- participant가 스스로 abort한다.
⚠️ 3. 투표 이후 coordinator에 문제 발생
- participant는 coordinator의 회신을 계속해서 기다린다.
- 이 상태에 있는 participant의 트랜잭션을
in doubt또는uncertain상태라고 한다.
즉, 투표 이후 coordinator에 장애가 발생할 경우 전체 시스템이 blocking 된다.
이것이 coordinator가 commit/abort 요청을 보내기 전에 트랜잭션 로그에 자신의 결정을 써야하는 이유다.
coordinator는 복구되면, 트랜잭션 로그의 커밋 포인트를 읽어 in doubt 상태를 해결하고, 로그에 남아있지 않은 트랜잭션들은 abort된다.
이러한 blocking 상황에서 트랜잭션들은 in doubt 상태에 있는 내내 획득한 Lock을 잡고 있게 되어, 애플리케이션의 가용성을 크게 저하시키는 원인이 된다.
Coordinator의 트랜잭션 로그 손실 상황
Coordinator의 장애로 인한 Blocking 상태에서 Coordinator의 트랜잭션 로그가 일부 손실되었을 경우에 추가적인 문제가 발생한다.
Coordinator는 복구된 이후 트랜잭션 로그를 기반으로 in doubt 상태의 트랜잭션들을 해소하려는 상황에서 트랜잭션 로그가 손실되었다면, 해소되지 못한 in doubt 상태의 트랜잭션들은 자동으로 해소될 수 없어 Lock을 유지한 채 영원히 데이터베이스에 남는다.
2PC는 원자성을 보장하기 위해, in doubt 상태를 유지해야 한다.
따라서, 이러한 Orphaned 트랜잭션들은 데이터베이스 서버를 재부팅하더라도 해소되지 않는다.
낮은 성능
또한, 2PC 방식은 다음과 같은 이유로 낮은 성능을 보여준다.
1. 동기 통신 비용
- coordinator와 participant간의 총 2번의 왕복 통신이 필요하다.
2. 디스크 I/O 오버헤드
- 모든 participant와 coordinator는 각 단계마다 트랜잭션 로그를 디스크에 기록해야 한다.
- 특히 coordinator는 커밋 로그를 디스크에 flush해야 트랜잭션이 커밋된다.
3. 확장성 부족
- participant 수가 많아질수록 네트워크 지연, 메시지 수, 디스크 기록 횟수가 증가한다.
- 전체 커밋 지연이 가장 느린 참여자에 의해 결정된다.
2PC의 한계 보완 방법
2PC 시스템들은 이러한 2PC의 문제점을 완화하기 위해, 다음과 같은 보완 방법들을 제공한다.
Heuristic decision
participant가 투표 이후 coordinator의 응답을 기다리던 중, 일정 시간이 지나도 회신이 없고 coordinator가 장애 상태로 판단되는 경우, 자체적으로 commit 또는 abort를 결정하는 방식이다.
이 방식은 원자성을 완전히 보장하지 못하며, 데이터 불일치가 발생할 수 있다.
하지만 장기간 Lock을 유지하는 상황을 해소할 수 있기 때문에 일부 XA 기반 시스템에서는 옵션으로 제공된다.
보통 heuristic commit은 피하고, heuristic abort만 허용하는 경우가 많다.
commit은 한번 수행되면 되돌릴 수 없는 작업이기에 나중에 abort였음을 알게 되어도 되돌릴 수 없는 반면, abort는 나중에 commit이었음을 알게되면 트랜잭션을 재수행할 수 있기 때문이다.
Coordinator 이중화
Coordinator의 장애로 인한 Blocking 문제를 완화하기 위해, coordinator의 상태를 다른 노드에 복제하여 이중화하는 방식이다.
- 각 coordinator들이 같은 트랜잭션 로그를 공유해야 하므로, 공유 저장소를 활용하거나 트랜잭션 로그를 각 노드에 함께 복제하는 방법을 사용한다.
- 한번에 하나의 coordinator만 결정을 내려야 하므로, 합의 알고리즘을 통한 리더 선출이 필요하다.
이 방식은 이후 살펴볼 2PC의 대안 기술인 합의 기반 commit과의 경계에 걸쳐 있으며, 단순한 2PC 시스템보다 구현 복잡도가 높다.
2PC의 대안 기술
보완 방식이 아닌, 아예 2PC를 대체할 수 있는 구조도 존재한다.
이들은 일반적으로 2PC의 원자성 보장 수준보다는 가용성, 복원성, 확장성을 우선시하며, 경우에 따라 일관성 모델을 다르게 선택한다.
Three-phase commit (3PC)
2PC의 blocking 문제를 해결하기 위해 Non-Blocking을 지향하는 프로토콜로, 기존 2PC에 PreCommit 단계가 추가되어 총 3단계로 구성된다.
PreCommit 단계
모든 participant에게 "Yes"를 응답받은 coordinator는 각 participant들에게 PreCommit(Prepare to commit) 메시지를 전송한다.
PreCommit 메시지를 받은 participant들은 다음과 같은 행동을 취하며, 이 상태의 participant를 잠정 커밋(prepared) 상태라고 부른다.
- 로컬 트랜잭션을 디스크에 로그로 기록
- 자신이 commit해야 한다는 사실을 저장
- coordinator에게 ACK 응답을 전송
이후 coordinator에 장애 발생 시 자신과 다른 participant들의 상태를 확인하여 DoCommit 결정을 하게 된다.
3PC는 네트워크 지연이 유한하고 예측 가능하며 노드의 응답 시간도 유한함을 전제로 설계되었다.
하지만, 실제 운영 상황에서는 지연이 유한하지 않고, 응답 노드의 생사 여부를 정확히 판단할 수 없다. (장애 감지에 주로 사용되는 타임아웃은 노드가 죽은 것인지 네트워크 지연인지 구분하지 못한다.)
따라서, 실제 시스템에서는 잘 쓰이지는 않는다.
합의 기반 commit (Paxos/Raft 기반)
Raft나 Multi-Paxos와 같은 합의 알고리즘을 사용하여, 트랜잭션 커밋 여부를 합의로 결정하는 방식이다.
- 리더를 통한 단일 순서 브로드캐스트 방식으로 커밋 로그를 전파한다.
- 분산 로그 시스템(Kafka 등), 분산 데이터베이스(Spanner, CockroachDB 등)에서 사용한다.
합의 알고리즘은 coordinator 자체의 장애 감지와 교체(리더 선출)를 포함하기 때문에, 2PC보다 장애 복원력이 뛰어나며 non-blocking 처리가 가능하다.
단점은 구현 복잡도와 높은 네트워크 트래픽이다.
SAGA 패턴
긴 트랜잭션을 여러 개의 보상 가능한 지역 트랜잭션으로 분해하여 처리하는 방식이다.
- 각 단계의 트랜잭션이 성공하면 다음 단계로 넘어가고, 실패 시 이전 단계들을 보상(undo) 트랜잭션으로 되돌린다.
- 보상 트랜잭션의 존재를 전제로 하며, 완전한 원자성을 보장하지 않는다
주로 비즈니스 트랜잭션에서 사용되며, 데이터베이스보다는 애플리케이션 레벨에서 처리.
분산 시스템(MSA)에서 많이 사용되는 실용적 대안이다.
Outbox 패턴
로컬 트랜잭션 내에서 변경사항과 이벤트를 함께 기록하고, 이후 별도 프로세스에서 메시지 브로커(Kafka 등)에 전송하는 방식
- 메시지 전송과 DB 변경을 동일 트랜잭션에 포함시켜 일관성을 확보한다.
- DB에 저장된 outbox 테이블을 polling하는 별도 컴포넌트 필요하다.
완벽한 원자성은 아니나, 실제 운영 환경에서 신뢰성 있게 사용되는 패턴.
MSA 환경에서 이벤트 기반 아키텍처를 구현할 때 널리 사용된다.
Reference
Martin Kleppmann, Designing Data-Intensive Applications, O'Reilly Media, 2017.
How Uber Migrated Financial Data from DynamoDB to Docstore
MSA 환경에서 데이터 관리를 위한 필수사항- 고가용성과 데이터 동기화
